基于备份的RAID1在线重构框架
2018-04-18徐伟
徐 伟
(国家安全生产监督管理总局通信信息中心 北京 100713)
0 引 言
针对RAID在线重构研究,国内外相关研究从预测失效、spare布局、数据布局和重构策略四个方面来探索如何加速RAID在线重构。
预测失效主要使用磁盘自动检测功能,探测出即将不能正常运行的磁盘,在失效前将其复制到spare盘上,从而减少重构时间,提高磁盘阵列可靠性。在大型peer-to-peer的存储系统Oceanstore里也采取了磁盘失效预测技术[1]。但这种方式不能完全准确预测出磁盘失效。文献[2]指出:现有技术只能预告实际磁盘故障的50%,其效果被夸大。
Spare布局分为Dedicated sparing[3]、Parity sparing[4]和Distributed sparing[5-7]这三种方式。Dedicated sparing模式专门用一块磁盘作为空闲盘,当磁盘阵列发生磁盘失效,将失效磁盘上数据完全重构到spare磁盘。Parity sparing将spare磁盘作为第二块parity盘,减少parity组长度。当阵列中某块磁盘失效,两个parity组融合生成一个更大的单一阵列,该阵列只有一个parity组。Distributed sparing将spare空间分布在所有磁盘上,而不是专门用一个磁盘作为spare盘。当阵列中某块磁盘失效,失效磁盘上数据会被重构,并分布于所有磁盘的空闲空间。但当用户负载急剧增加时,磁盘阵列重构性能显著降低,重构时间大幅增加。
通过研究RAID的数据布局来加速重构过程是常用的一种方法。Decluster parity[8-9]通过虚拟逻辑盘构成磁盘阵列,设物理磁盘个数为C,虚拟逻辑盘个数为G,将(G-1)/(C-1)定义为α,C和G确定了parity数据消耗总磁盘空间,α确定了系统的重构性能。当α值越小,重构所需时间则越小,parity数据所占比例越大;当α值越大,重构所需时间则越大,parity数据所占比例越小。可以调节α,从而在重构和parity数据所占比例间取得平衡。但是,当α值很小时,用于parity数据的存储开销将非常大,而且当用户负载很大时,重构所需时间仍然相当大。文献[10]提出了一种新型数据布局方式提高了镜像磁盘阵列重构过程。文献[11]在RAID结构里构建了一个子阵列从而显著加速数据重构过程。文献[12-15]对RAID6编码布局进行研究以便改善RAID6重构性能。文献[16-17]也对磁盘阵列编码布局进行研究,从而改善磁盘阵列重构性能。
重构策略[18]主要由重构对象、重构顺序、重构与服务协作这三个方面组成。
重构对象主要分为面向条带重构、并行条带重构和面向磁盘重构。面向条带重构是按条带来进行重构的,并行条带重构采取多个并行的面向条带重构,面向磁盘重构采取与阵列中磁盘相同个数的进程,一个进程对应一个磁盘。但是,当用户负载较大时,重构所需时间仍然相当长,且对服务性能影响显著。文献[19]描述了基于磁道的重构算法,利用该算法可以重构磁道上丢失数据。
重构顺序主要分为Head-following、Closet active stripe、Multiple reconstruction points和基于局部性的多线程重构。Head-following重构的主要原理:重构磁盘总是从处于低地址的尚未重构单元进行顺序重构。Closest active stripe重构的主要原理:在完成用户请求时,总是从靠近磁头位置的尚未重构单元进行重构。Multiple reconstruction points重构的主要原理:将磁盘分为多个重构段,在完成用户请求时,从当前最近重构点开始重构。基于局部性的多线程重构的主要原理:利用用户负载访问的局部性,优先重构频繁访问的区域[20]。
重构与服务协作方面主要分为用户请求操作、重构速率控制两方面。
用户请求操作处理方式分为直读、回写和直写。直读主要原理:如果用户对失效磁盘读请求所涉及数据已经被重构并已经在spare盘上,则直接从spare盘上读取该数据。回写的主要原理:用户对失效磁盘读请求重构出数据,该数据不仅被发送给用户,而且被写到spare盘上。直写的主要原理:用户的写请求直接发送到spare盘上,写入spare盘的相应位置。基于NAND闪存的高新能和可靠的PRAID-6[21]提出一种新型的数据提交方法从而获得与RAID6同样的恢复能力。文献[22-23]通过对磁盘阵列读写方式和数据块聚合来优化磁盘阵列读写性能。
重构速率控制主要在服务性能和重构速率之间寻找平衡点,从而使得服务性能处于用户可承受范围,尽可能提高重构速率[24-25]。文献[26-27]指出可以根据磁头移动轨迹来利用空闲带宽处理后台应用,这也有助于提高重构性能和服务性能。
还有其他方式[28-30]来加速磁盘阵列重构过程。文献[28]通过将热点数据复制到固态硬盘上来加速重构过程。文献[29]在分布式RAID上利用独立GPU加速重构过程。文献[30]利用节点的计算编码能力,传输经过编码的数据块来修复校验盘,减少修复过程中的数据传输量,缩短校验盘的修复时间。
针对RAID在线重构,国内外相关研究主要从预测失效、spare分布、数据分布、重构策略四个方面来提高磁盘阵列服务性能和重构性能。
在对数据存储可靠性有高要求时,RAID1作为一种RAID技术,会被经常采用。但国内外现有研究始终无法解决重负载持续访问情况下,RAID1的重构性能和服务性能急剧恶化这一问题。
而企业存储网络系统多数由生产系统和备份系统构成。生产系统由于直接对外提供服务,因此,其可靠性和可用性非常重要。尤其是大容量磁盘越来越便宜,备份系统越来越多采用磁盘存储备份数据。
因此,本文首次提出了“利用外部存放的备份数据来加速RAID1在线重构”的思想,构建了基于备份的RAID1在线重构框架,从而充分挖掘了闲置磁盘备份的强大IO能力,显著提高了繁忙生产系统内RAID1在线重构的速度。
1 设计思想
基于备份的RAID1在线重构框架的核心思想:当生产系统磁盘阵列RAID1出现磁盘失效时,可以由备份系统虚拟出失效磁盘处于最近备份时间点的历史版本。通过将历史版本恢复至热备盘上,从而使得热备盘成为处于最近备份时间点的版本。最后,利用生产系统虚拟出的当前版本将失效磁盘上自最近一次备份时间点之后已修改数据重构至spare磁盘上。此框架的主要优点为:利用备份系统所提供的稳定恢复带宽,显著降低了应用负载对重构过程的影响。同时,显著减少了磁盘阵列RAID1参入重构,使得磁盘阵列RAID1优先满足用户服务。
重构过程分为两个阶段:版本恢复阶段和版本修复阶段。当生产系统出现磁盘失效时,激活spare磁盘,如图1(a)所示。首先,重构过程进入版本恢复阶段;spare硬盘从生产系统中换出,完全由备份系统将失效磁盘处于最近备份时间点的历史版本恢复至spare磁盘,从而将spare磁盘恢复成失效磁盘处于最近备份时间点的版本,如图1(b)所示。然后重构过程进入版本修复阶段;将spare磁盘重新加入到生产系统磁盘阵列中,利用与失效磁盘构成RAID1的另一块磁盘将spare盘修复为当前版本,从而完成失效磁盘上自最近一次备份时间点之后已修改数据的重构,如图1(c)所示。通过版本恢复阶段和版本修复阶段,完成spare磁盘的数据重构,从而将生产系统恢复到正常运行状态,如图1(d)所示。
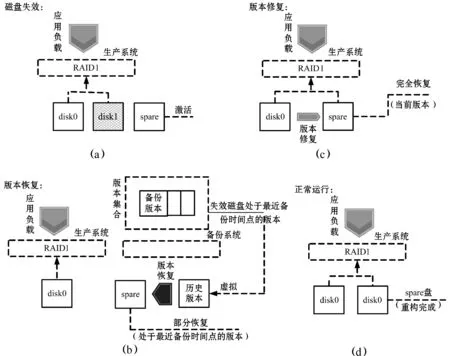
图1 此框架的重构过程
2 设计实现
基于备份的RAID1在线重构框架的原型系统主要由面向数据的磁盘阵列架构、映射管理、恢复管理和重构管理四部分构成,通过这四部分协作,完成磁盘阵列RAID1在线重构过程。
2.1 面向数据的磁盘阵列架构
通过对传统磁盘阵列进行简单改进,我们实现了面向数据的磁盘阵列架构。面向数据的磁盘阵列架构与传统磁盘阵列架构根本差异就是:面向数据的磁盘阵列中未被使用逻辑块上数据一定为零。我们使用一个全局位图记录磁盘阵列中所有逻辑块(数据块)的使用情况,并通过在传统磁盘阵列转发读写请求路径上添加访问位图接口,从而实现了面向数据的磁盘阵列架构。面向数据磁盘阵列必须按照条带分配和释放逻辑单元,以避免引起附加的读写操作。
2.2 映射管理
映射管理主要负责以下三类映射关系的建立和维护:1) 逻辑卷逻辑块与最新备份数据块的映射关系;2) 失效磁盘逻辑块与最新备份数据块的映射关系;3) 失效磁盘上自最近备份时间点之后修改数据块的位置标识。如图2所示。
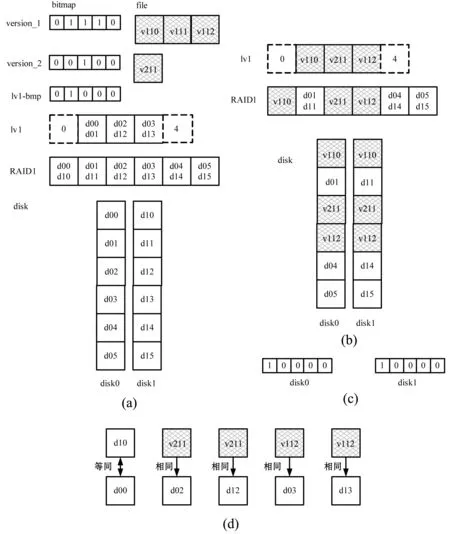
图2 磁盘逻辑块与最新备份数据块的映射关系
图2(a)描述了版本、逻辑卷、磁盘阵列和磁盘之间的映射关系。假设磁盘阵列RAID1由disk0、disk1两块磁盘构成;磁盘上逻辑块、RAID1上chunk、逻辑卷(lv1)空间分配粒度和备份数据块都为4 KB;一个逻辑卷lv1已被创建;逻辑卷lv1做了两次备份,第一次备份版本为version_1,第二次备份版本为version_2;位图lv1-bmp为自最近一次备份时间点之后的差别增量位图,也就是第二次备份时间点之后的差别增量位图。
如图2(a)所示,逻辑卷lv1的第0逻辑块和第4逻辑块未分配实际磁盘逻辑块,逻辑卷lv1第1块映射到磁盘disk0和disk1的第0块(d00和d01),lv1其余逻辑块与磁盘上逻辑块的映射关系不再赘述;逻辑卷lv1的version_1上数据块v110,根据version_1的位图,v110对应lv1的第1块数据(处于version_1时刻),其余版本所保存的数据块与逻辑卷lv1逻辑块的映射关系不再赘述;根据位图lv1-bmp,逻辑卷lv1的第1个逻辑块自最近一次备份时间点之后被修改;磁盘逻辑块d01、d11、d04、d14、d05和d15未被使用,其上数据为零。
图2(a)的映射关系、逻辑卷与磁盘阵列逻辑块的映射关系、以及磁盘阵列与磁盘逻辑块的映射关系,可以计算出任一磁盘逻辑块与最新备份数据块的映射关系。根据图2(a)所描述的映射关系,计算出disk0和disk1这两块磁盘的数据块与备份数据块的映射关系,如图2(b)所示。在图2(b)中,备份数据块v110映射在disk0和disk1的第0块(d00和d10)上,其余不再赘述。
图2(c)描述了各磁盘上自最近一次备份时间点之后修改数据的位置标识(版本修复位图)。在图2(a)中,根据位图lv1-bmp,可知磁盘disk0逻辑块d00和磁盘disk1逻辑块d01数据自最近一次备份之后已被修改。因此,生成了磁盘disk0和disk1自最近一次备份时间点之后修改数据的位置标识。
图2(d)中描述了使用最新数据块来生成各磁盘逻辑块数据。如图2(d)所示,磁盘disk0逻辑块d02数据相同于备份数据块v211,其他不再赘述;由于磁盘disk0逻辑块d00和磁盘disk1逻辑块d01自最近一次备份时间点后被修改,所以磁盘disk1逻辑块d01等同于磁盘disk0逻辑块d00。
2.3 恢复管理
恢复管理构件由多个读线程和一个写线程构成,映射管理构件由一个线程构成。当恢复管理构件进行spare磁盘的恢复操作时,映射管理构件并行生成映射关系和版本修复位图。
恢复管理构件采取多个读线程并发读取备份数据。一个读线程从映射缓冲内顺序取出一个映射关系,对于数据,将相应数据(一块备份数据)读出,存放于数据缓冲相应位置。当某个读线程完成数据读取后,则顺序处理还未读取的数据。
恢复管理构件采用单个写线程将数据顺序写入spare磁盘。恢复管理构件有两个数据缓冲,当读线程读取数据并存放于一个缓冲时,写线程将已放满数据的另一个缓冲中数据写入spare盘中。
2.4 重构管理
在此原型系统中,重构管理构件仅负责版本修复阶段。通过版本修复位图和辅助位图两者合作,重构管理构件实现了版本修复功能。版本修复位图是自最近备份时间点之后修改数据的位置标识,辅助位图上所有位初始为0,两个位图上每一位与磁盘上4 KB逻辑块一一对应。通过版本修复位图和辅助位图之间合作,可以判断逻辑块上数据是否有效。spare磁盘逻辑块上数据被定义了两种状态:
VALID——如果版本修复位图中某位为0或者辅助位图中某位为1,则对应逻辑块上数据有效。
INVALID——如果版本修复位图中某位为1,且辅助位图中相应位为0,则对应逻辑块上数据无效,即逻辑块上数据自最近一次备份时间点之后已被修改。
在版本修复阶段,版本修复位图和辅助位图协作过程如下:
1) 按照版本修复位图和辅助位图,顺序发出对于无效数据块的重构请求。当所计算出的数据被写入spare磁盘对应逻辑块之后,则将辅助位图上相应位设为1,从而标识对应逻辑块上数据已经有效。
2) 用户读请求发送给RAID1时,先直接读取正常磁盘相应逻辑块上数据;如果spare磁盘对应逻辑块上数据无效,则将其写入spare盘,同时,将辅助位图上相应位设为1,从而标识spare盘被访问逻辑块上数据已经有效。
3) 用户写请求发送给RAID1时,当写请求发送给正常磁盘时,同时发送给spare盘,并将版本修复位图上相应位设为1;写请求完成之后,则将辅助位图上相应位设为1,标识spare盘被访问逻辑块上数据已经有效。
通过面向数据的磁盘阵列架构、映射管理、恢复管理和重构管理四个构件,我们实现了基于备份的RAID1在线重构框架的原型系统。
3 性能评价
本文主要使用面向磁盘重构算法DOR(Disk-Oriented Reconstruction)与基于备份的RAID1在线重构框架进行对比。因为DOR方法是现有重构方法中最有效算法之一,而且已经被实现于许多软RAID1和硬RAID1产品中,并且在许多文献中受到最广泛的研究。
本节的测试配置如下设置:cello99(12-25、10-05)和F1.spc应用模式;对于cello99和F1.spc这两种应用模式,生产系统RAID1单块磁盘容量分别设为92 GB和31 GB;逻辑卷空间分配粒度为32 MB,完全随机分配;生产系统RAID1中1块磁盘失效;4 KB、8 KB和16 KB备份版本集合;每个逻辑卷对应备份版本集合包含了184个版本;备份系统RAID5由6块磁盘构成;恢复管理模块里读线程数目设置为30,写线程数目设置为1。
在本节论述中,4 KB表示为:备份版本集合的备份粒度为4 KB;8 KB、16 KB含义与4 KB类似,不再赘述。
3.1 重构性能
图3描述了基于备份的RAID1在线重构框架的重构性能相对于DOR提高倍数。从图3中,可以得出以下结论:基于备份的RAID1在线重构框架的重构性能相对于DOR有显著改善。在图3中,对于cello99-12-25应用负载(每天修改数据量较小且负载压力较小),此框架的重构性能比DOR提高了4.8至6.4倍;而对于cello99-10-05应用负载(每天修改数据量较小且负载压力较大),此框架的重构性能比DOR提高了15.1至17.8倍;对于F1.spc(每天修改数据量非常大),此框架的重构性能也比DOR提高了3倍左右。
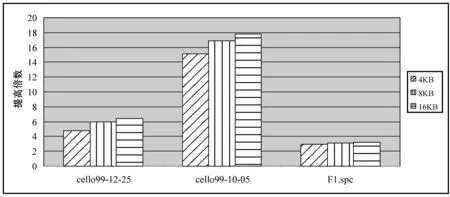
图3 此框架重构性能相对于DOR提高倍数
当RAID1存储空间远大于逻辑卷实际分配空间时,相对于DOR,此框架对重构性能有巨大改善。
3.2 服务性能
图4描述了基于备份的RAID1在线重构框架的总体平均响应时间相对于DOR降低百分比。从图4中,可以得出以下结论:基于备份的RAID1在线重构框架的总体平均响应时间相对于DOR有显著改善。如图4所示,对于cello99-12-25应用负载,此框架的总体平均响应时间比DOR降低28%左右;而对于cello99-10-05应用负载,此框架的总体平均响应时间比DOR降低38%左右;对于F1.spc应用模式,此框架的总体平均响应时间比DOR降低了20%左右。
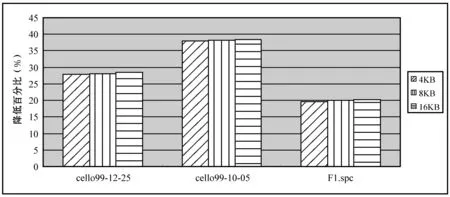
图4 此框架平均响应时间相对于DOR降低百分比
4 代价分析
4.1 磁盘阵列备份映射关系的维护开销
为了在发生磁盘失效时能够尽快建立起所需映射关系,必须维护最新备份数据块与磁盘阵列上逻辑块的映射关系(磁盘阵列备份映射关系)。维护此类映射关系的空间开销和时间开销如表1所示。

表1 磁盘阵列备份映射关系的维护开销
其中,磁盘容量表示为D,单位为TB;磁盘阵列容量表示为R,单位为TB,R与D相等;备份数据块粒度表示为A,单位为KB;映射关系单元占用8个字节;顺序读写性能表示为P,单位为MB/s;映射关系所占空间为(8×R)/A,单位为GB。
1) 空间开销。假设磁盘容量为8 TB,备份数据块为4 KB,生产系统上磁盘阵列存储容量为8 TB;由于备份系统上存储容量一般大于生产系统,假设备份系统上存储容量为8 TB;如表1所示,该映射关系占用16 GB空间,仅占备份系统上存储容量的0.2%;假如备份数据块粒度为64 KB时,仅占备份系统上存储容量的0.012 5%。因此,日常所需维护的映射关系所产生的空间开销可以忽略不计。
2) 时间开销。在备份系统上进行日常维护,日常维护映射关系的算法如下:首先从生产系统里读取逻辑卷和磁盘阵列逻辑块映射关系;读取逻辑卷最新备份版本位图;然后在内存中更新磁盘阵列备份映射关系(顺序排列),每500 MB写回一次;每个逻辑卷依次进行。
测试配置如下设置:生产系统上磁盘阵列RAID1由2块磁盘构成,单块磁盘容量为8 TB;空间分配粒度为32 MB,完全随机分配;4 KB备份版本集合;生产系统RAID1分配了64个128 GB逻辑卷;备份系统为单块磁盘,磁盘容量为8 TB,存放了64个逻辑卷全量备份的备份版本位图,也即每个备份版本位图所有bit位为1,每个备份版本位图为4 MB。最新备份数据块与磁盘阵列逻辑块的映射关系文件为16 GB,也存放在备份系统单块8 TB磁盘上。测试结果显示更新磁盘阵列备份映射关系只需要14.6分钟。而且,在备份系统上通常采用磁盘阵列,则读写性能会更高,磁盘阵列备份映射关系维护时间开销将更少。
4.2 失效磁盘备份映射关系的建立开销
当磁盘阵列发生磁盘失效时,需要建立失效磁盘逻辑块与最新备份数据块的映射关系(失效磁盘备份映射关系),本节主要考察了建立失效磁盘备份映射关系的开销。
测试配置如下设置:生产系统上磁盘阵列RAID1由2块磁盘构成,单块磁盘容量为8 TB;其中,1块磁盘失效;空间分配粒度为32 MB,完全随机分配;4 KB备份版本集合;生产系统RAID1分配了64个128 GB逻辑卷;1个16 GB磁盘阵列备份映射关系文件存放在单块磁盘上。测试结果显示,失效磁盘备份映射关系的建立速度与磁盘阵列备份映射关系读取速度相同,接近单块磁盘顺序读写性能(60 MB/s)。
4.3 相关位图的开销
相对于传统RAID重构方法,该框架增加了全局位图、版本修复位图和辅助位图,所引起的开销如表2所示。在表2中,磁盘容量表示为D,单位为TB;磁盘数为2个;备份数据块粒度表示为A,单位为KB;辅助位图和版本修复位图大小则为D×1 024/(A×8),单位为MB。

表2 位图规模
1) 访问开销。由于全局位图、版本修复位图和辅助位图都存放于内存中,因此,访问这三个位图所产生的开销可以忽略不计。
2) 空间开销。1 TB存储容量一般配置3 GB内存,假设D为1 TB,磁盘数为2,磁盘阵列为RAID1,备份数据块粒度为4 KB;如表2所示,版本修复位图和辅助位图都为32 MB,全局位图为32 MB,仅为系统内存总量3 GB的3.1%。因此,三个位图的空间开销几乎可以忽略不计。
5 结 语
对于RAID1在线重构的研究,国内外现有研究一直解决不了重负载持续访问下磁盘阵列RAID1重构性能急剧恶化的问题。应用负载所访问的磁盘阵列RAID1归于生产系统,日常备份已经成为保证数据可靠性的一种常用手段。
因此,本文提出了“利用外部存放的备份数据来加速RAID1在线重构”的思想,并对此进行了深入研究,构建了基于备份的RAID1在线重构框架。此框架利用备份系统所提供的恢复带宽将处于最近一次备份时间点的版本数据整合至spare盘。然后利用磁盘阵列RAID1所提供的重构带宽将自最近一次备份时间点之后已修改数据重构至spare盘。此框架相对于现有重构方法显著改善了RAID1的重构性能和服务性能。
我们下一步工作将根据RAID6工作原理,构建基于备份的RAID6在线重构框架。
[1] Rhea S, Wells C, Eaton P, et al. Maintenance-free global data storage[J]. IEEE Internet Computing, 2001, 5(5):40-49.
[2] Pinheiro E, Weber W D, Barroso L A. Failure Trends in a Large Disk Drive Population[C]//The Proceedings of the 5th USENIX Conference on File and Storage Technologies (FAST’07), 2007:33-48.
[3] Menon J, Mattson D. Comparison of Sparing Alternative for Disk Arrays[C]//Proceedings of the 19th International Symposium on Computer Architecture, 1992, 11: 318-329.
[4] Reddy A L N, Chandy J, Banerjee P. Design and Evaluation of Gracefully Degradable Disk Arrays[J]. Journal of Parallel & Distributed Computing, 1993, 17(1-2):28-40.
[5] Rigby N M, Macdougall A J, Needs P W, et al. Performance analysis of RAIDS disk arrays with a vacationing server model for rebuild mode operation[C]//Tenth International Conference on Data Engineering. IEEE Computer Society, 1994:111-119.
[6] Qin X, Miller E L, Schwarz S J T J E. Evaluation of distributed recovery in large-scale storage systems[C]//IEEE International Symposium on High PERFORMANCE Distributed Computing, 2004. Proceedings. IEEE, 2004:172-181.
[7] Thomasian A. Comment on “RAID5 performance with distributed sparing”[J]. Parallel & Distributed Systems IEEE Transactions on, 2006, 17(4):399-400.
[8] Muntz R, Lui J. Performance Analysis of Disk Arrays Under Failure[C]//Proceedings of the 16th International Conference on Very Large Data Bases, 1990, 3: 162-173.
[9] Watanabe A, Yokota H. Adaptive Overlapped Declustering: A Highly Available Data-Placement Method Balancing Access Load and Space Utilization[C]//International Conference on Data Engineering, 2005. ICDE 2005. Proceedings. IEEE, 2005:828-839.
[10] Luo X, Shu J, Zhao Y. Shifted Element Arrangement in Mirror Disk Arrays for High Data Availability during Reconstruction[C]//International Conference on Parallel Processing. IEEE, 2012:178-188.
[11] Wan J, Wang J, Xie C, et al. S2-RAID: Parallel RAID Architecture for Fast Data Recovery[J]. IEEE Transactions on Parallel and Distributed Systems, 2014, 25(6):1638-1647.
[12] Xie P, Huang J Z, Cao Q, et al. V2-Code: A new non-MDS array code with optimal reconstruction performance for RAID-6[C]//Proceedings of IEEE International Conference on Cluster Computing, 2013,1-8.
[13] Xie P, Huang J Z, Dai E W, et al. An efficient data layout scheme for better I/O balancing in RAID-6 storage systems [J]. Frontiers of Information Technology & Electronic Engineering, 2015 , 16 (5) :335-345.
[14] Fu Y, Shu J, Luo X, et al. Short Code: An Efficient RAID-6 MDS Code for Optimizing Degraded Reads and Partial Stripe Writes[J]. IEEE Transactions on Computers, 2016, 66(1):127-137.
[15] 谢平. RAID-6编码布局及重构优化研究[D].武汉:华中科技大学,2015.
[16] 罗象宏. 磁盘阵列的编码与容错技术研究[D].北京:清华大学,2014.
[17] 万武南 , 杨威. 一种基于双容错RDP码的扩展RAID码[J]. 小型微型计算机系统, 2014 , 35 (11) :2477-2481.
[18] Fu G, Thomasian A, Han C, et al. Rebuild Strategies for Redundant Disk Arrays[C]//Symposium on Mass Storage Systems. 2004:223-226.
[19] Lee J Y B, Lui J C S. Automatic recovery from disk failure in continuous-media servers[J]. Parallel & Distributed Systems IEEE Transactions on, 2002, 13(5):499-515.
[20] Tian L, Feng D, Jiang H, et al. PRO: A Popularity-based Multi-threaded Reconstruction Optimization for RAID-Structured Storage Systems[C]//Usenix Conference on File and Storage Technologies, FAST 2007, February 13-16, 2007, San Jose, Ca, Usa. DBLP, 2007:277-290.
[21] 陈金忠, 姚念民, 蔡绍滨. 基于NAND闪存的高性能和可靠的PRAID-6[J]. 电子学报,2015, 43 (6): 1211-1217.
[22] 王俊杰. 通用磁盘阵列RAID性能分析及优化[D].西安工程大学,2015.
[23] 刘靖宇,谭毓安,薛静锋,等. S-RAID中基于连续数据特征的写优化策略[J]. 计算机学报, 2014 , 37 (3) :721-734.
[24] Bachmat E, Schindler J. Analysis of methods for scheduling low priority disk drive tasks[J]. Acm Sigmetrics Performance Evaluation Review, 2002, 30(1):55-65.
[25] Tian Lei, Jiang Hong, Feng Dan, et al. Implementation and Evaluation of a Popularity-Based Reconstruction Optimization Algorithm in Availability-Oriented Disk Arrays[C]//IEEE Conference on MASS Storage Systems and Technologies. IEEE Computer Society, 2007:233-238.
[26] Lumb C R, Schindler J, Ganger G R, et al. Towards higher disk head utilization:extracting free bandwidth from busy disk drives[C]//4th Symposium on Operating System Design & Implementation, 2000,3:7.
[27] Thereska E, Schindler J, Bucy J, et al. A framework for building unobtrusive disk maintenance applications[C]//Usenix Conference on File and Storage Technologies. USENIX Association, 2004:16-16.
[28] Liu F, Pan W, Xie T, et al. PDB: A Reliability-Driven Data Reconstruction Strategy Based on Popular Data Backup for RAID4 SSD Arrays[M]//Algorithms and Architectures for Parallel Processing. 2013:87-100.
[29] Khasymski A, Rafique M M, Butt A R, et al. On the Use of GPUs in Realizing Cost-Effective Distributed RAID[C]//IEEE, International Symposium on Modeling, Analysis and Simulation of Computer and Telecommunication Systems. IEEE Computer Society, 2012:469-478.
[30] 高玲玲,许胤龙,王英子,等. 基于RAID6编码的校验盘故障修复算法[J]. 计算机应用与软件,2014, 31(6):248-251,302.
