基于图正则平滑低秩表示的基因表达谱特征选择
2018-04-18杨国亮康乐乐
杨国亮 康乐乐
(江西理工大学电气工程与自动化学院 江西 赣州 341000)
0 引 言
癌症的产生和发展是一个较为复杂的研究领域。癌症的高发态势对人类的生产和生活带来严重影响,因此癌症的防范与治疗成为热门的世界性话题。随着基因表达谱的出现与广泛应用,为癌症的治疗带来新的曙光,同时也得到广大学者的关注和研究。Xu等[1]提出最小生成树(MST)理论的基因表达谱分析方法,把复杂的基因表达谱数据转化成简单的最小生成树。王年等[2]利用基因表达谱数据构造Laplacian矩阵进行分类,提高了算法性能。文献[3]把流形学习和多任务学习应用于基因表达谱数据分类研究中,不仅如此,基因表达谱数据分析在基因工程、新药研制等方面也起到至关重要的作用。但其高维小样本的特点也给肿瘤治疗与研究带来巨大困难。因此,如何有效地降低基因表达谱数据维数,从而进行有效的聚类和识别就成为重中之重。
近年来,基于图的聚类算法在计算机视觉和机器学习等领域中得到广泛应用,例如图像分割[4]、半监督学习[5]和维数约减[6],主要是通过学习一个有判别性的图去描述数据样本点的关系。如何构造合适的图去捕捉数据结构是该类算法的难点。
文献[7]提出了低秩表示LRR(Low Rank Representation),通过求解核范数最小化问题构造低秩图,可以捕获数据的全局结构。文献[8]提出拉氏正则低秩表示LLRR(Laplacian-regularized LRR),有效地捕捉数据局部结构和全局结构,提高数据结构信息表达力。文献[9]提出非负低秩稀疏图NNLRS(Non-Negative Low Rank and Sparse Graph),联合低秩表示和稀疏表示同时捕获数据的全局和局部结构,提高了半监督算法的性能。
上述的低秩表示及其扩展算法都是使用核范数代替秩函数估计矩阵的秩,从而得到最低秩系数矩阵,然而核范数作为秩函数的凸包络,在许多实际问题中并不能准确地估计矩阵的秩[10]。文献[11]使用平滑Schatten-p函数代替秩函数,算法适应性得到有效提高。王斯琪等[12]使用Max极小化模型代替秩函数,在鲁棒主成分问题上得到成功应用。文献[13]提出的对数行列式函数,在子空间聚类问题上提高了算法性能[14]。
本文提出的改进算法是在构建目标函数时,利用对数行列式函数代替核函数,平滑地估计秩函数,准确地得到全局数据结构。在此基础上,又引入流形正则项,充分保护了数据的局部线性结构,然后采用有效的后处理方法重构权重矩阵,最后使用Ncuts得到最终的聚类结果。
1 低秩图
假设存在一个训练数据集X=[x1,x2,…,xn]∈Rd×n,d表示样本维数,n表示样本数。低秩表示的目的是最小化系数矩阵的秩描述子空间流形结构[15]。将X本身作为字典,并且在实际问题中考虑噪声影响,那么低秩表示优化目标函数如公式所示:

(1)
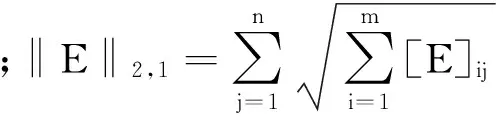
(2)
2 本文的改进算法
2.1 平滑低秩表示
对数行列式函数可以平滑地估计秩函数,更加准确地捕获数据的全局子空间结构,在子空间聚类问题上获得更好的聚类效果[10],函数表达式如下所示:
(3)
式中:Z表示需求解的系数矩阵,δi表示Z的第i个奇异值,使用式(3)代替式(1)中的核范数,得到的函数表达式为:
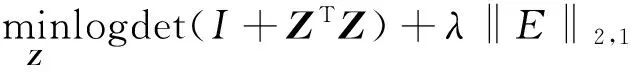
(4)
2.2 图正则平滑低秩表示
2.2.1构建目标函数
流形理论[16]假设,原始数据空间中xi和xj有相近的几何结构,那么它们在流形空间对应的嵌入映射zi和zj也是相近的。这个假设在维数约减[17]、子空间聚类[18]和半监督学习[5]等起到重要的作用。

(5)
为了满足流形假设,最小化下列目标函数:
Tr(ZDZT)-Tr(ZWZT)=Tr(ZLZT)
(6)

在上述的平滑低秩表示中加入流形正则项,就得到图正则平滑低秩表示模型,目标函数如下所示:

(7)
2.2.2求解最优化问题
为了使得目标函数能够交替更新时可分,引入辅助变量J:
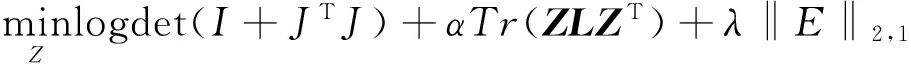
(8)
式(8)的增广拉格朗日函数:
L=logdet(I+JTJ)+αTr(ZLZT)+λ‖E‖2,1+
(9)
式中:Y1和Y2代表拉格朗日乘子,μ>0是惩罚参数。通过固定其中两个变量,可以交替更新参数J、Z、E,然后更新参数Y1、Y2。更新规则如下:
(10)
(11)
(12)
式(10)有一个闭合解:
(13)
式(11)可以转化成标量最小化问题,通过定理1求得它的解。文献[14,19]已经对定理1进行了证明。


(14)
式(12)的解为:
(15)
式中:Ω为l2,1范数最小化运算符[20],假设Y=Ωε(X),则Y的第i列由式(16)获得。
(16)
图正则平滑低秩表示完整求解见算法1。
算法1图正则平滑低秩表示模型求解
输入:数据矩阵X∈Rd×n,参数α>0,λ>0
初始化:Z=J=0,E=0,Y1=Y2=0
While not converged do
1.更新J:如式(11);
2.更新Z:如式(13);
3.更新E:如式(15);
4.更新Y1,Y2:
Y1=Y1+μ(X-XZ-E);
Y2=Y2+μ(Z-J);
5.更新参数μ:
μ=min(ρμ,μmax);
6.检查收敛条件:
‖X-XZ-E‖∞<εand ‖Z-J‖∞<ε;
End while
输出:Z
2.3 构造数据图结构
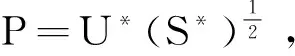
(17)
得到权重矩阵WG后,直接采用Ncuts求得最终的聚类结果。
图正则平滑低秩表示的特征选择算法见算法2。
算法2图正则平滑低秩表示基因表达谱特征选择算法
输入:基因表达谱数据X
1.利用算法1求得系数矩阵Z*;
2.对Z*瘦奇异值分解Z*=U*S*(V*)T;

4.通过式(17)构造图权重矩阵;
5.采用Ncuts得到聚类结果。
输出:聚类准确率
3 实验分析
3.1 数据集
为了验证本文算法的有效性,本文选用3个公共基因表达数据集,分别是DLBCL、NCI、Lung。DLBCL数据集有141个样本,661个基因,是3分类问题;NCI数据集有63个样本,2 308个基因,是4分类问题;Lung数据集有156个样本,675个基因,为2分类问题。
选用的3个基因表达数据集的相关信息汇总如表1所示。
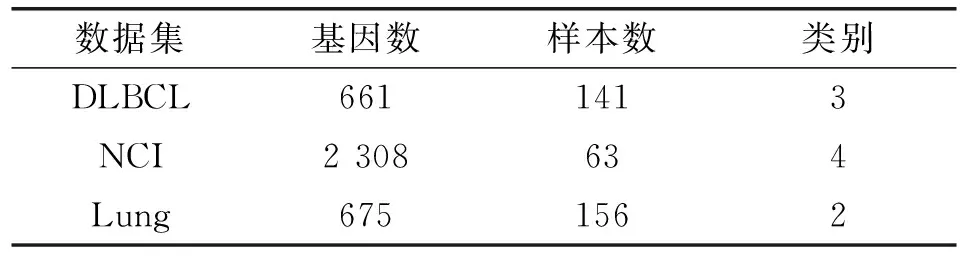
表1 基因数据集
3.2 实验结果
本节将在以上3个基因表达谱数据集上进行聚类实验,并同稀疏子空间聚类SSC[21]、低秩表示LRR[15]、对数行列式估计LDA[19]、图正则低秩表示GLRR[22]进行比较。LDA算法是对LRR进行改进,利用对数行列式代替核范数估计矩阵的秩[10]。GLRR算法是在传统LRR算法中加入流形正则项,更好地捕捉数据全局和局部结构。不同算法在3个数据集的聚类准确率如表2所示。对比图如图1所示。
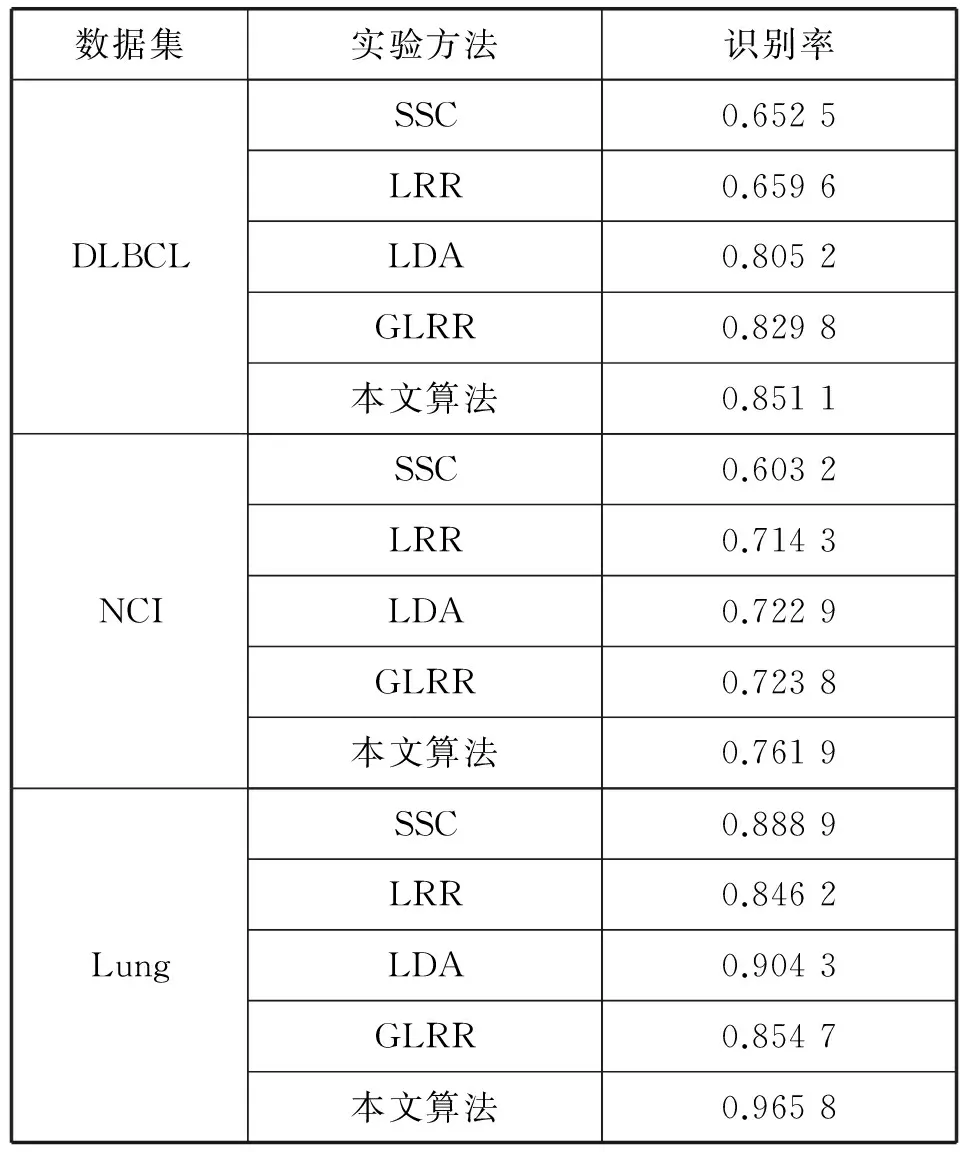
表2 聚类准确率

图1 五种不同方法的实验结果对比图
从表2与图1对比实验结果可以看到:
(1) SSC算法忽略了数据之间的结构属性,所以相比其他算法聚类准确率最低。
(2) LDA和LRR相比较,在3个数据集上的聚类准确率明显提高,最高可提升15%。本文算法与GLRR算法相比较,不同数据集上聚类准确率也有明显提高,但对于不同的数据集提高的程度不一样。例如在Lung数据集上,前者比后者聚类准确率提高9%,而NCI数据集上只有4%,但总体上,提高的聚类准确率平均达到5%以上。由此说明对数行列式相比核函数能够更好地估计秩函数,有效地得到数据最低秩表示。
(3) GLRR和LRR相比较,GLRR算法在LRR基础上加入流形正则项,在不同的数据集上获得的聚类准确率比LRR算法更高。本文算法是在LDA算法基础上也加入图正则项,且在3个数据集上获得更高的聚类准确率,比LDA算法平均高出5%,由此说明了数据局部保持能力的重要性。
(4) 本文算法在LRR算法的基础上进行两方面的改进,分析对比实验结果,在不同的基因表达数据集上均获得最高的聚类准确率,最高可达到96%,平均增长率约为12%,论证了本文算法的有效性。
由以上分析进一步说明,本文算法相比较其他算法,利用对数行列式代替核函数平滑估计秩函数,准确地捕获了数据全局结构。同时在目标函数中加入流形正则项,很好地弥补了低秩表示的缺陷,准确地捕获了数据局部线性结构,提高了数据空间结构信息的表达力。
3.3 参数选择
本文算法包含两个参数,其中α用来平衡流形正则项,λ用来平衡噪声项。本节分析了这两个参数在不同的基因表达谱数据集上对聚类准确率的影响。由图2可以观察到,参数α在0.5~1范围变化时,本文算法分类准确率较高。但是在不同的数据集上,参数α的选择也略有差别,为了实现较高的聚类准确率,参数λ在3个数据集上的选择差异性较大。具体参数设置由图2和图3得到。


图2 不同数据集上参数α对聚类准确率的影响

图3 不同数据集上参数λ对聚类准确率的影响
4 结 语
本文提出一种图正则平滑低秩表示的特征选择算法,使用对数行列式代替核函数平滑的估计秩函数,准确地得到数据的全局子空间结构;同时利用流形正则项准确地捕获数据的局部线性结构,然后利用全新的方式重构数据的图结构。该算法具有全局一致性和局部保持力,提高数据结构信息的表达力。在3个公共基因表达数据集上的实验结果证明,本文提出的算法有更好的聚类准确率。
[1] Xu Y,Olman V,Xu D.Clustering gene expression data using a graph-theoretic approach:an application of minimum spanning trees[J].Bioinformatics,2002,18(4):536-545.
[2] 王年,庄振华,唐俊,等.基于Fiedler向量的基因表达谱数据分类方法[J].中国生物工程杂志,2010,30(12):82-86.
[3] 田贝贝.基于流形学习和多任务学习的肿瘤基因表达数据分类方法研究[D].武汉科技大学,2015.
[4] Li T,Wu X,Ni B,et al.Weakly-supervised scene parsing with multiple contextual cues[J].Information Sciences An International Journal,2015,323(C):59-72.
[5] Yang S,Feng Z,Ren Y,et al.Semi-supervised classification via kernel low-rank representation graph[J].Knowledge-Based Systems,2014,69(1):150-158.
[6] Pang Y,Wang S,Yuan Y.Learning regularized LDA by clustering[J].IEEE Transactions on Neural Networks & Learning Systems,2014,25(12):2191-2201.
[7] Liu G,Lin Z,Yan S,et al.Robust recovery of subspace structures by low-rank representation[J].Pattern Analysis & Machine Intelligence IEEE Transactions on,2013,35(1):171-184.
[8] Yin M,Gao J,Lin Z.Laplacian Regularized Low-Rank Representation and Its Applications[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2016,38(3):504-517.
[9] Zhang X,Ma Y,Lin Z,et al.Non-negative low rank and sparse graph for semi-supervised learning[C]//Computer Vision and Pattern Recognition.IEEE,2012:2328-2335.
[10] 张涛,唐振民.一种基于非负低秩稀疏图的半监督学习改进算法[J].电子与信息学报,2017,39(4):915-921.
[11] Mohan K,Fazel M.Iterative reweighted algorithms for matrix rank minimization[J].Journal of Machine Learning Research,2012,13(1):3441-3473.
[12] 王斯琪,冯象初,张瑞,等.基于最大范数的低秩稀疏分解模型[J].电子与信息学报,2015,37(11):2601-2607.
[13] Fazel M,Hindi H,Boyd S P.Log-det heuristic for matrix rank minimization with applications to Hankel and Euclidean distance matrices[C]//American Control Conference,2003.Proceedings of the.IEEE,2003,3:2156-2162.
[14] Kang Z,Peng C,Cheng J,et al.LogDet Rank Minimization with Application to Subspace Clustering[J].Computational Intelligence & Neuroscience,2015,2015(1-2):68.
[15] 杨国亮,谢乃俊,王艳芳,等.基于低秩稀疏评分的非监督特征选择[J].计算机工程与科学,2015,37(4):649-656.
[16] Liu Y,Liao Y,Tang L,et al.General subspace constrained non-negative matrix factorization for data representation[J].Neurocomputing,2016,173(P2):224-232.
[17] Zhang Z,Yan S,Zhao M.Similarity preserving low-rank representation for enhanced data representation and effective subspace learning[J].Neural Networks,2014,53(5):81-94.
[18] Liu J,Chen Y,Zhang J,et al.Enhancing Low-Rank Subspace Clustering by Manifold Regularization[J].IEEE Transactions on Image Processing,2014,23(9):4022-4030.
[19] Kang Z,Peng C,Cheng Q.Robust Subspace Clustering via Smoothed Rank Approximation[J].IEEE Signal Processing Letters,2015,22(11):2088-2092.
[20] Liu G,Lin Z,Yu Y.Robust Subspace Segmentation by Low-Rank Representation[C]//International Conference on Machine Learning.DBLP,2010:663-670.
[21] Elhamifar E,Vidal R.Sparse subspace clustering:algorithm,theory,and applications[J].IEEE Transactions on Pattern Analysis & Machine Intelligence,2013,35(11):2765-2781.
[22] He W,Chen J X,Zhang W.Low-rank representation with graph regularization for subspace clustering[J].Soft Computing,2017,21(6):1-13.
