一种结合信赖域算法的混合MIMIC算法
2017-06-08夏桂梅张文林
夏桂梅,张文林
(太原科技大学应用科学学院,山西太原 030024)
一种结合信赖域算法的混合MIMIC算法
夏桂梅,张文林
(太原科技大学应用科学学院,山西太原 030024)
针对分布估计算法在求解问题的过程中局部搜索能力较弱的缺点,引入了信赖域算法,提出了结合信赖域算法的分布估计算法.由于信赖域算法是一种很好的局部快速寻优方法,因此在分布估计算法的基础上,再对每一个粒子分别实施信赖域算法,能够加强算法的局部搜索能力.新算法不仅保持了种群的多样性,而且具备更全面的学习能力,提高了算法的寻优能力,避免早熟收敛的发生.数值试验结果表明:该算法能收敛到满足约束条件的最优解,并且具有很强的搜索能力,为解决非线性约束优化问题提供了一种新的有效途径.
分布估计算法;信赖域算法;MIMIC算法
分布估计算法(Estimation of Distribution Algorithm,简称EDA)是1996年提出的一种基于概率模型的优化算法[1],EDA在进化过程中通过统计方法建立解空间的概率分布模型,然后对模型进行采样得到新一代群体,如此反复进行,直至实现种群的进化.它不涉及在传统算法中出现的交叉变异等操作步骤,减少了参数设置,简化了计算过程,因而可解决一些传统算法难以解决的优化问题.根据变量之间的相关性,将分布估计算法分成下列三类:变量之间相互独立的分布估计算法、双变量相关的分布估计算法,以及多个变量相关的分布估计算法[2].然而,EDA在后期进化过程中速度很慢,且每一次的进化改变也很小,究其原因在于EDA在构建概率模型过程中,对空间内解分布过于依靠,多次迭代后,种群多样性减少,这些情况说明EDA的局部搜索能力较弱.鉴于EDA的此缺陷,在种群的进化过程中加入局部搜索能力很高的信赖域算法[3],提出一种结合信赖域算法的分布估计算法.新算法是在原分布估计算法基础上加入信赖域算法,在每次迭代过程中,粒子在进行完分布估计算法步骤后再对每一个粒子实施信赖域算法,寻找更优个体,这样,新算法不仅利用了分布估计算法全局搜索能力强的优点,且利用了信赖域算法局部搜索能力强的优点,同时保持了种群多样性,因而具备更全面的学习能力,提高了算法的寻优能力.
1 结合信赖域算法的混合MIMIC算法
1.1 罚函数法
罚函数法[4]的思想是将约束优化问题通过构造一个增广目标函数转化为无约束优化问题,从而利用有关的无约束问题来研究约束极值问题.经常采用的方法是在原来的目标函数上加上一个由约束函数组成的一个“惩罚项”来迫使迭代点逼近可行域.
罚函数的定义为:

其中,f(x)为约束优化问题中的目标函数,h(k)是随着迭代次数在变化的动态罚值,k是种群的迭代次数,H(x)是多段映射惩罚因子,其定义如下:

其中qi(x)=max{0,pi(x)},i=1,2,…,m ,pi(x)为原约束优化问题中的约束条件函数,包括等式函数与不等式函数,qi(x)是约束冲突函数,θ(qi(x))是一个多级赋值函数,γ(qi(x))是罚函数的力度,h(.),θ(.),γ(.)是依赖于具体的问题.
1.2 MIMIC算法
MIMIC算法(Mutual Information Maximization for Input Clustering)是最早提出的一种双变量相关的分布估计算法[5],它将变量之间的关系简单化,只考虑相邻的两个变量之间的关系,避免了遗传算法中的交叉和变异等操作,减少了参数的设置,更容易求解.
De Bonet等人[6]在1997年提出的MIMIC算法是用链式结构来表示变量之间的关系,其模型图如图1所示.
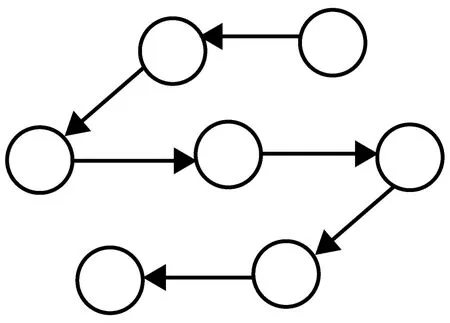
图1 MIMIC概率图模型Fig 1 The probabilistic graphical model of MIMIC
对于需要优化的变量(x1,x2,…,xn),存在一个最优的排列π=(i1,i2,…,in),使得根据优势群体估计出来的概率分布模型与优势群体的实际概率分布之间的K-L距离达到最小.其中,π=(i1,i2,…,in)表示变量x1,x2,…,xn的一个排列;pl(xij|xij+1)表示第ij+1个变量取值为xij+1时,第ij个变量取值为xij的条件概率.因此,我们的任务是找到一个适当的排列π,使得根据优势群体估计出来的概率分布模型与问题的实际概率分布模型尽可能的接近.K-L距离的定义为:
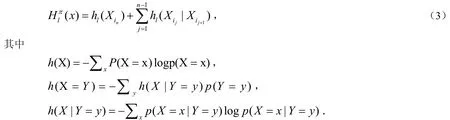
MIMIC算法构建概率模型的过程为:先随机产生xin,用条件概率pl (xin-1|xin)产生xin-1,以此类推得到xin-2,xin-3,…,x1;再利用贪婪算法[6]来最小化plπ(x)与plπ的K-L距离得到一个最优排列π*=(i1,i2,…,in);最后利用π*构建优势群体的概率模型
1.3 信赖域算法
信赖域算法[7]作为一种非常重要的优化算法,与传统的线性搜索方法一样,也是在优化算法过程中求出每次迭代的位移,进而确定新的迭代点,不同的是普通的线性搜索是先产生搜索方向,然后确定搜索步长,而信赖域算法则是直接去确定位移来产生新的迭代点.因此,信赖域算法是一种很好的局部寻优方法,特别是对于一些病态最优化问题具有非常稳定的性能.文献[7]将信赖域算法与微粒群算法结合应用于求解约束优化问题.
信赖域算法的基本思想是:先给定一个信赖域半径,作为在位移过程中的上界,并把当前迭代点作为中心点,用此半径确定一个信赖域的闭球区域,通过求解这个区域内的信赖域子问题的最优点来确定“候选位移”.如果“候选位移”能够使目标函数有足够的下降量,则该“候选位移”作为可接受位移,并且扩大信赖域半径,继续进行迭代,否则缩小信赖域半径,通过去求解新的信赖域子问题进而得到新的“候选位移”,这样重复下去,直到满足终止条件.

其中Δk是信赖域半径,||.||是向量范数,一般取其2范数.
设上述子问题的最优解是dk,Δfk是f在第k次迭代的实际下降量,Δqk是对应的预测下降量,Δqk一般取正数,且Δfk=fk-f(xk+dk),Δqk=qk(0)-qk(dk).定义它们的比值为rk,且.当rk<0时,有Δfk<0,则xk+dk不能作为下一次的迭代点,因此需要缩小信赖域半径来重新求解信赖域子问题;当rk接近1时,则说明子问题与原目标函数在此信赖域范围内有较好的近似,因此xk+1=xk+dk可以作为下一次的迭代点,并且下一次的迭代可以增大信赖域的半径的值;对于其他的情况,信赖域的半径则可以保持不变.
1.4 结合信赖域算法的混合MIMIC算法
MIMIC算法作为分布估计算法的一种,其用概率模型代替了遗传算法中的交叉与变异的操作,避免了在遗传算法中导致积木块被破坏的问题,因此受到了许多学者的关注与研究,并且在此基础上提出了许多的改进策略[8],在许多领域进行了成功的研究应用[9-11].对于标准的MIMIC算法,虽然也能够找到问题的全局最优解,但在后期进化的速度非常慢,每一代的改变程度也很小,这说明分布估计算法的全局搜索能力非常强,而局部搜索能力较弱,因此在MIMIC算法的基础上加入一种局部寻优方法非常强的信赖域算法来平衡粒子的搜索过程,进而提高算法的搜索能力和效率.在实际操作中,对约束条件采用上文1.1中的罚函数法,将约束优化问题转化成为无约束的优化问题进行求解.
具体操作步骤如下:
Step 1:对群体初始化,同时设置参数,随机的产生N个个体作为初始群体opop,k→0;
Step 2:利用罚函数法将约束优化问题转化为无约束优化问题;
Step 3:计算群体中每个个体的适应值,若符合终止条件,则算法结束,否则转下一步;
Step 4:用轮盘赌法和截断法选择M<N个个体来作为优势群体,并保留p个最优个体;
Step 5:利用贪婪算法来寻找最优排列建立优势群体的概率模型;
Step 6:利用逆序方法从模型中采样m次,与上述p个个体构成N个个体,其中m+p=N;Step 7:对上述N个个体执行信赖域搜索,寻找更优的个体,转Step 3.
2 数值试验
2.1 测试函数
为了测试算法的性能,选取文献[12]中的四个测试函数,并对所得结果进行比较.

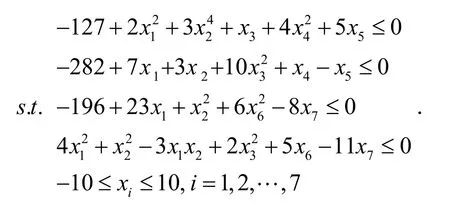
2.2 参数设置
在Matlab试验中,算法的各个参数设置为:群体规模2 000,最大迭代次数为1 000,精度为10-6,分别进行30次试验.
2.3 试验结果及分析
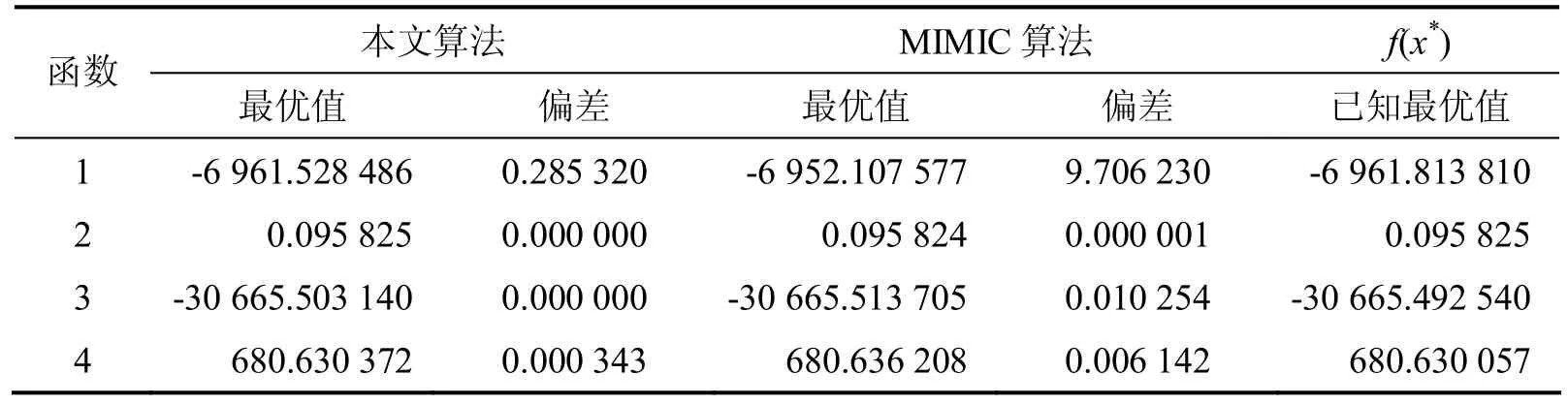
表1 本文算法与MIMIC算法对测试函数结果的比较Table 1 The comparison of the results of test functions with this algorithm and MIMIC algorithm
表1给出了四个测试函数的已知最优值f(x*)、运用本文算法独立运行30次试验后的最优值以及最优值与函数已知最优值的偏差,并且与文献[4]中直接用MIMIC算法对测试函数运行结果进行了比较.由表1可以看出,本文算法与直接运用MIMIC算法对四个测试函数都能找到最优解,但本文算法得到的最优解明显要优于MIMIC算法得到的,尤其对于函数1,本文算法与函数最优值之间的偏差明显要比MIMIC算法好.实验结果验证了本文算法的可行性与有效性.
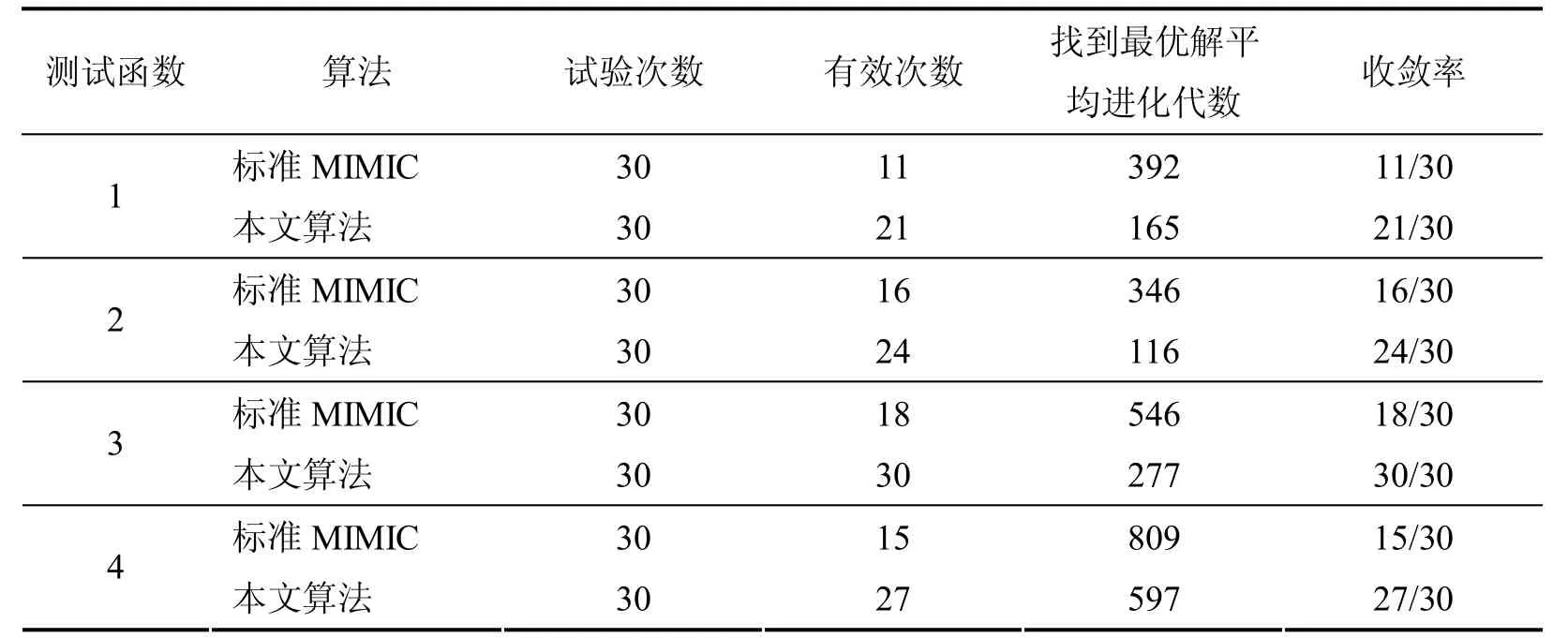
表2 四个测试函数收敛性的比较Table 2 The convergence comparison of four test functions
表2给出了本文算法与MIMIC算法对四个测试函数分别进行30次试验得到的有效试验次数、运行过程中找到最优解的平均迭代次数以及收敛率的比较.由表2可知,对于四个测试函数,在有效次数、找到最优解的平均进化代数以及收敛率方面,本文算法明显要优于标准的MIMIC算法,尤其是对于函数3,本文算法能够达到100%的收敛.试验结果表明,本文算法是一种寻优能力和可靠性更高的优化算法,其性能比标准MIMIC算法有明显提高.
在仿真试验中,令优势群体个数从500开始,以100递增直至1 000,进而来探索优势群体个数与进化时间的关系.为了方便观察,将函数1和2放在图2中,将函数3和4放在图3中,如下所示.
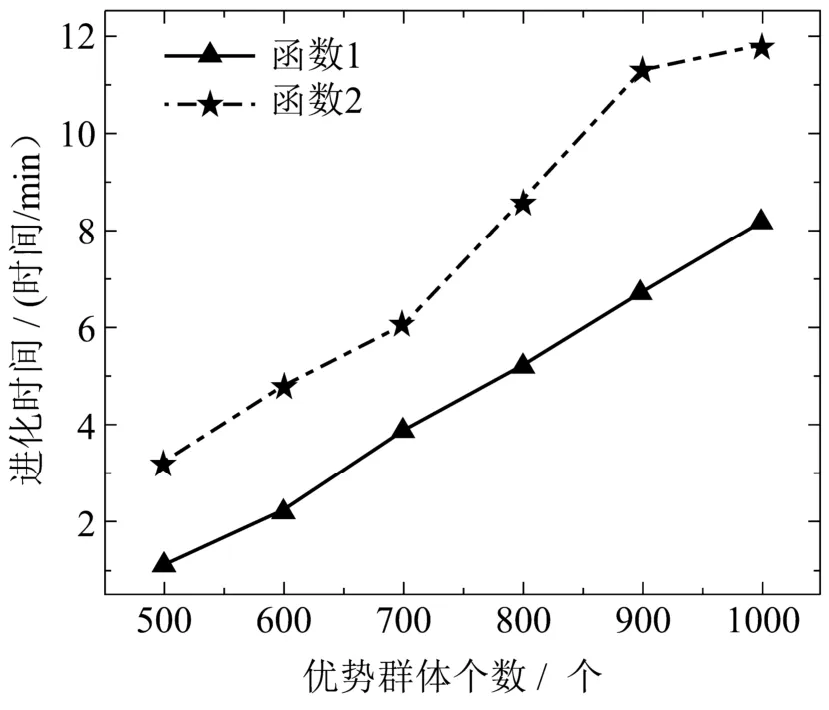
图2 优势群体个数与进化时间关系图Fig 2 The diagram of the relationship between the number of dominant groups and evolution time
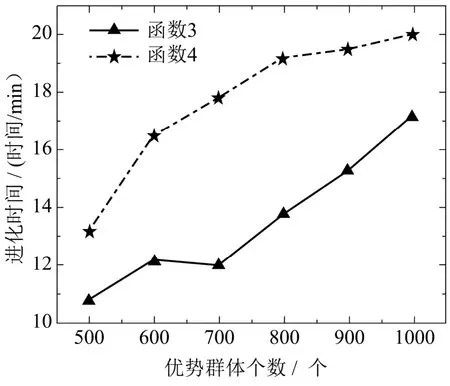
图3 优势群体个数与进化时间关系图Fig 3 The diagram of the relationship between the number of dominant groups and evolution time
由图2图3可知,函数进化所需时间随着优势群体个数的增加而增加,并且对于维数较高的函数,进化时间也在增加.因此,选择合适的优势群体个数在种群中所占的比例,有利于缩小搜索的范围,提高解的收敛速度.对于高维函数进化时间长的问题,由于连续域分布估计算法研究进展相对缓慢,还有待于进一步的研究和改进.
3 结 论
MIMIC算法作为分布估计算法中的一种,是一种简单的随机优化算法,其全局搜索能力很强,缺点是在进化过程中种群比较单一,在进化后期收敛速度较慢,导致局部收敛性较弱.针对以上缺点,本文将局部收敛性很强的信赖域算法加入到MIMIC算法中,提出了一种结合信赖域算法的混合MIMIC算法.
改进后的MIMIC算法充分结合了信赖域算法局部搜索能力强的特点,又保持了分布估计算法全局搜索能力强的优点,使得原来的算法在解决优化问题时有了一定的改进.把改进后的算法应用于处理非线性约束优化问题,结果表明,本文提出的算法提高了算法的局部搜索能力,减少了进化的代数,并且找到的最优值与已知最优值非常接近,收敛效率很高,其综合性能比标准MIMIC算法有明显的提高.
[1] Larranaga P,Lozano J A. Estimation of distribution algorithms: a new tool for evolutionary computation [M]. Boston: Kluwer Press,2002: 1-126.
[2] 周树德,孙增圻.分布估计算法综述[J].自动化学报,2007,33(2):115-118.
[3] 马昌凤.最优化方法及其Matlab程序设计[M].北京:科学出版社,2010:74-99.
[4] 张金风,夏桂梅,王泰.一种基于罚函数的混合分布估计算法[J].西南民族大学学报,2015,41(1):120-123.
[5] Jordan M I,Lecun Y,Solla S A. Advances in neural information processing systems [M]. Cambridge: MIT Press,1997: 1-63.
[6] De Bonet J S,Isbell C L,Viola P. MIMIC: finding optima by estimating probability densities [EB/OL]. [2014-08-08]. http://www.cc.gatech.edu/~isbell/papers/isbell-mimic-nips-1997.pdf.
[7] 李金莱,香清.一种求解约束优化问题的信赖域微粒群算法[J].计算机工程与应用,2011,47(10):54-56.
[8] 程玉虎,王雪松,郝名林.一种多样性保持的分布估计算法[J].电子学报,2010,38(3):194-197.
[9] 张金风,夏桂梅,张文林.基于MIMIC算法的备件优化模型[J].太原科技大学学报,2015,36(2):154-159.
[10] 罗国军,张学良,郭晓冬,等.MIMIC算法在非线性多约束机械优化问题中的应用[J].太原科技大学学报,2013,34(6):440-444.
[11] 孙涛,朱生鸿,李玥,等.改进的分布估计算法在配网重构中的应用[J].电力系统及其自动化学报,2014,26(6):54-59.
[12] Michalewicz Z,Schoenauer M. Evolutionary algorithms for constrained parameter optimization problems [J]. Evolutionary Computation,1996,4(1): 1-32.
A Hybrid MIMIC Algorithm Integrated with Trust-region Algorithm
XIA Guimei,ZHANG Wenlin
(School of Applied Science,Taiyuan University of Science and Technology,Taiyuan,China 030024)
The Trust-region algorithm is introduced in this paper in allusion to the defect with the estimation of distribution algorithms which is weak in local search capability. Meanwhile,the distributed estimation algorithm integrated with the trust-region algorithm is proposed. Due to the trust-region algorithm is a partial optimal seeking method,the local search capability of the trust-region algorithm is strengthened with each particle implemented respectively. The new algorithm not only maintains the diversity of population,but also possesses a more comprehensive learning ability,which improves the searching capability of the algorithm,and avoids the occurrence of premature convergence. Numerical experiments show that the proposed algorithm is in position to converge the optimal solution which meets every constraint condition. Therefore,it is a very strong searching ability and provides a brand-new effective way to solve nonlinear constrained optimization problems.
Estimation of Distribution Algorithms; Trust-region Algorithm; MIMIC Algorithm
O221
:A
:1674-3563(2017)02-0001-07
10.3875/j.issn.1674-3563.2017.02.001 本文的PDF文件可以从xuebao.wzu.edu.cn获得
(编辑:封毅)
2015-11-10
山西省自然基金(2014011006-2);太原科技大学研究生教改项目(20133001)
夏桂梅(1968-),女,山西大同人,副教授,研究方向:最优化理论与应用
