搭建版刻楷体字书计算机辅助版本校勘平台的设想
2016-01-09朱翠萍,张宪荣
搭建版刻楷体字书计算机辅助版本校勘平台的设想
朱翠萍,张宪荣
(北京师范大学 文学院,北京 100875)
摘要:随着大数据时代的到来,古籍整理的手段不断更新,计算机辅助版本校勘平台的搭建也随之成为社会发展的必然。从资源整理、图像文本化、自动分割与属性标注等几个方面来探讨自动校勘系统搭建所必须解决的问题,为平台搭建工作的全面开展奠定良好的基础。
关键词:版刻;楷体;字书;版本;自动校勘;平台
网络出版地址:http://www.cnki.net/kcms/detail/13.1415.C.20150410.1443.023.html
网络出版时间:2015-04-10 14:43
古之学者往往“幼而时习之”,即使白发苍苍,也不敢说穷尽一经。他们将大量宝贵的时间和智慧都用在了材料积累上,写下的笔记、卡片成千上万张,耗时又费力。今之学者赶上了大数据时代,大家有感于之前整理古籍的辛苦,想一改皓首穷经的局面,搭上计算机技术这列“高铁”,走高效整理的路子,将更多的时间与智慧投入到深入探索和理论提升中来。所以,使用数字化资源来进行学术研究成为当今之必然趋势。
随着OCR光学识别技术的发展,已经可以将古籍转化为文本,结合人工校对,就可以实现古籍的全文本化,便于检索和编辑。但就目前来看,古籍数字化的重点已由全文通索转移到数据分析,“智能化”才是未来发展的方向和重点。通过人工智能技术,可以从图像文件中自动抽取所需信息并形成检索点,为建立专题数据库以及古籍整理的深加工奠定坚实的基础。北京大学李国新教授曾就该问题专门做了论述,并提出了“研究支持功能”的观点:“数字化后的古籍能够提供科学、准确的统计与计量信息,提供古籍内容相关的参考数据、辅助工具,例如:对古籍字数、字频、词频的统计资料,异体字的汇聚显示,读音的自动标注和朗读,行文风格特点的概率统计,必要的背景知识、参考数据的汇聚,在线标点断句工具的配备,不同版本校勘,字典词典、历史年表、历史地图等研究工具的载入等。”计算机辅助版本校勘系统就是基于这一“智能化”目标而搭建的,希望能成为现代新型字书研究者的工作平台。
一、版本校勘概说
版本校勘是指利用不同的版本和其他补充资料,来比较、核对、分析与推断古籍流传过程中所产生的文字差异或错误。这些差异或错误主要表现在误、脱、衍和倒4个方面146-203。所谓“误”,主要是指古籍在传抄或刻写过程中出现的错字,亦称“讹”;所谓“脱”是指古籍在传抄或刻写过程中出现的脱落与遗漏字句的现象,亦称“夺文”;所谓“衍”是指古籍在传抄或刻写过程中无意混入或重复的文字;所谓“倒”是指古籍在传抄或刻写过程中出现的词句颠倒的现象,亦称“倒乙”。
版本校勘的目的是将这些问题或差异找出来,然后进行分析研究,以求存真复原,为阅读和研究提供一个最为接近原稿的善本。关于古籍校勘的方法,诸家所论不一,如叶德辉于《藏书十约》中提出了死校与活校两法,程千帆先生则在《校雠广义(校勘编)》中分对校与理校两类,而最为学界推崇的还是陈垣先生在《校勘学释例》卷6中所归纳的4种校勘方法,即“对校法”、“本校法”、“他校法”和“理校法”,简称“四校法”。现据陈先生所说分别申述如下144-149:1.对校法。指选定一个版本为底本,然后用其他不同的版本与之进行比对;2.本校法。指在没有其他版本和有关资料对比的情况下,依据该书自身体例,结合文字、音韵及训诂等相关领域的专业常识进行校勘;3.他校法。指利用其他书,例如书中的引证部分,来验证本书中的文字是否正确;4.理校法。指在没有版本或其他材料可以依据的情况下,利用所具备的理论知识和逻辑推理的方法,来分析验证所校书中的文字是否正确。
从整体来说,校勘就是利用比较和分析的方法对某一个文本进行校异和勘误的工作。校异工作的内容相对客观,只是对比异同,可以借助计算机辅助完成。勘误则是相对主观性的工作,需要人们借助一定的理论知识来进行判断推理。如果借助计算机,就属于人工智能的范畴,难度比较大。所以,就目前而言,自动校勘还主要体现在校异工作方面。
字书,古人称为“小学书”,是专门收集和研究汉字形音义的工具型书籍。其范围包括:主形的“文字”系列、主音的“音韵”系列、主义的“训诂”系列及其他相关的音义类著作。“版刻楷体字书”是指通过雕版印刷方式制作的字体风格为楷体的辑录汉字形音义信息的工具书。因其具有工具性,所以使用面广,流传年代久远,这样势必造成字书的版本丰富多样。笔者对几部重要字书的版本做了一个简单的统计,并通过字头数量,对校勘字符量做了一个预估,见表1:
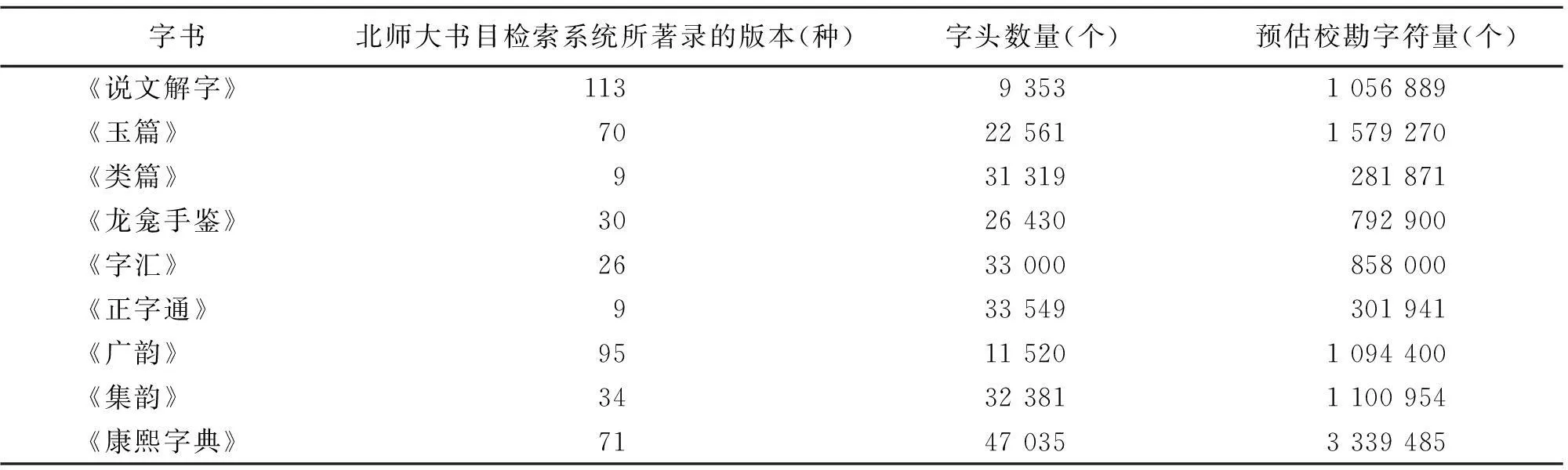
表1 部分字书版本及字头数目
通过上述统计可以看出,仅仅字书校勘的基础字符量就少则几十万,多则上百万。如果再加上释文,可能就涉及上亿字符,再加上对各种问题的归类和分析,可以想见,校勘的工作量何等繁重。所以,利用计算机辅助校勘成为迫切需要攻克的难题。
二、搭建版刻楷体字书版本校勘平台的主要工作内容
版本校勘是一个系统工程,需要经历“校”、“按”和“断”3个步骤。在这个过程中,有几个主要问题需要注意。第一,通过梳理版本源流,确定善本,然后以善本为底本,其他的为校本,展开校勘。这一工作开展的前提就是尽可能多、全地收集不同版本,以便选到最优质的资源。第二,自动校勘所能处理的是文本文件,而获取到的第一手资源是纸本或图像,这就需要经历一个文本转化的过程。在转化过程中,对版式和字符自动识别的精确度会直接影响到校勘的效果。所以,提前分析版式信息,建立尽可能大的字符识别字典,会大大提高自动校勘的效率。第三,在自动校勘过程中,实现精确对应的前提是自动分割的准确。所以,研究适合古籍字书的自动分段、自动分词和自动匹配技术,是搭建自动校勘平台过程中的核心问题。
(一)搭建版刻楷体字书版本校勘平台的基础——资源整理
目前,散藏于日本、美国、英国、越南、中国香港、中国台湾以及中国大陆的各大图书馆中的字书资源已被陆续收集到一起。在此基础上,可以对这些字书的版本信息进行分解,提取版本信息“因子”,然后将这些“因子”进行归类与去重,形成字书版本知识专库。据《古籍著录规则》(GB 3792.7-2008)规定,古籍版本项包括版本类型和出版发行两个部分,其中,前者可分为稿本、抄本和刻本等13种类型,后者则依次包括以下几个方面:
1.国别:就目前所见到的汉字字书的版本,涉及的国别主要有中国、日本、韩国、朝鲜和越南。
2.出版年(修版年或印刷年):关于版本的年代,有几种不同的记录方式:
(1)朝代:楷体字书涉及的中国朝代主要有汉、南北朝、隋、唐、宋、元、明、清和中华民国等。
(2)帝王纪年:帝王纪年的基本格式是:年号+年份。中国的年号:例如,延祐3年、弘治14年、万历26年及康熙43年等。日本的年号:例如,昭和5年、享保12年、弘化3年、宽政2年、庆安2年、明治16年、大正15年、天保15年、文化7年、宽永4年与安永9年等。
(3)干支纪年:干支纪年具有循环性。所以,出现同样的干支字眼,还需要进一步界定,否则,在计算机对版本时代进行自动排序的时候,会出现错误。
(4)公元纪年:公元纪年是以耶稣诞生年为元年,之前的年份称为“公元前某年”,之后的年份称为“公元后某年”。
3.制、藏地:即出版地,包括修版地或印刷地,例如,汲古阁、经纶堂、芳梫堂、种善堂和世裕堂等。
4.刻工:即出版者,包括修版者或印刷者,例如,李显、李书云、陈昌治、郑世豪、毛谟和陆颢等。
根据上述版本知识信息,先进行归类、排序和统计,再结合正文各方面的信息进行版本顺序的梳理。同时,还可以根据这些版本信息,观察字书发展演变的历史,绘制字书历史演变图。这些为版本校勘平台的搭建提供了丰富的资源基础和序列模型。
(二)搭建版刻楷体字书校勘平台的前提——文本化
版本校勘的核心是对正文文字的勘校。要实现校勘自动化,需要将纸本字书扫描为图像,然后再将图像的内容进行OCR识别,最终转化为可编辑的文本格式,这就是所谓的“文本化”过程。一般来说,在文本化过程中需要注意以下环节:
1.版式分析:在古籍数字化过程中,版式分析的结果直接影响着文字采集的效果,以至影响到文字识别的效果。常见的版式信息主要由以下几个方面组成:
(1)版面类型:横排、竖排、左右两栏横排——有分割线、左右两栏横排——无分割线、上下两栏竖排——有分割线和上下两栏竖排——无分割线;
(2)制作类型:版刻、手写体和印刷体;
(3)字符排列类型:只有大字、只有小字和大小字混合;
(4)修饰信息:无框线和列线、只有单框线、有单框线和列线、有单框线和中缝线、只有双框线、有双框线和列线以及有双框线和中缝线;
(5)符号信息:符号是版式信息的重要组成部分,可以分为几类:标点符号,例如,句读、专名号、分隔号和替代符等;版式符号,例如,鱼尾、墨等、墨围、空围和墨盖子等;专类符号,例如,工尺谱和乐谱符号等。
上述这些信息看似是外部特征,但都是古籍字书的重要组成部分,一旦遗漏,将会丢失很重要的知识信息。而版式分析是否符合图像实际,也将直接影响字符采集的准确性和效率。所以,版式分析是搭建版本校勘系统过程中不可忽略的一项重要内容。
2.文字识别
文字识别是文本化的核心目标,识别效果直接影响着文本化的效率和保真的程度。文字识别效果主要受以下几个因素影响:
(1)文字识别技术。文字识别技术主要指OCR,就是利用电子设备,对图像文件进行分析处理,获取文字及版面信息的过程。衡量OCR系统性能好坏的主要指标包括拒识率、误识率与识别速度等。字书扫描后的字图清晰、完整,识别率就高;字图不清楚,或者粘连许多框线、点读等杂质,识别率就会比较低。当然,不排除一些字图清晰却识别不正确的情况。例如《集韵》中的“从”字,在北京创新力博数码科技有限公司开发的采集平台系统中会认同为“久”字,见图1:

图1 字符识别错误示例
从图像效果来看,“从”字字图很清楚,字形结构也很简单,但却被错误识别为“久”字,其原因就是该系统对字形的结构分析有误。字图中的“从”字左边的部件“人”小于右边的部件“人”,被电脑自动分析为左上包围结构,在字形上与之最接近的就是“久”字。所以,识别出现错误。这说明该识别系统在字形训练方面还不够全面,面对变化了结构和笔形的情况,就会出现类似错误。
(2)字符集大小。字符集是描述多个文字和符号的集合,不同的字符集所含的字符数量有一定差异,其中比较常见的字符集有26-27:
1)中国大陆:最早的是GB2312-80,收字6 763个,比较小;最大的是GB18030-2005,收字70 244个。
2)中国台湾:常见的是Big5码,收字13 053个。
3)中国香港:在Big5码的基础上扩展的字符集是HKSCS-2004,收4 500个字,441个符号。
4)日本:在JISXO208的基础上扩展的字符集是JISXO213-2004,收11 233个字。
5)韩国:在KSC5657-1991基础上扩展的字符集KSC5657-1991,收2 856个韩国汉字。
字符集大且系统兼容性好,就会支持显示更多的字码,反之,则会出现空码与乱码现象。在上述字符集中,GB18030-2005所含的汉字字符最全,但也还有一定的区域局限,一旦换到没有安装该字符集或者与该字符集不兼容的系统中就无法使用。就目前来讲,Unicode码是唯一的国际性编码,它是经过字符宽度整合的编码方式,为全世界上百万个字符定义了唯一的编码值,并提供了一个标准化的方法,能够满足在同一系统平台上使用多种语言的编码。同时,它还专门定义了中日韩统一表意文字集,简称CJK。该字符集中的字符主要来源于中国、日本、韩国、朝鲜、越南、新加坡以及中国的台湾、香港和澳门,包括了简体汉字、繁体汉字、方块十字、日本国字、韩国独有汉字、越南喃字和香港方言字,共计74 616个字符,它是汉语古籍文本化过程中首选的字符集。
(3)字形认同规则。字形认同规则是指在文字识别之后,尤其是对于一些相近字形进行判别,是应该看作一个字,还是应该看作不同的字的判别规则。该规则主要由笔画规则和字形规则共同组成,可以视研究目的来决定宽严标准。如果专门进行字形研究,则采取严式标准;如果字形不是研究的主要目标,则可以采用较宽的标准,尽量认同。例如,“刻”字,见图2:

图2 新旧字形差异图
从字图来看,这两个字形只有“点”的差异,但从字形上讲,这属于新旧字形的差异,应该按照两个字符来处理;但是,如果不研究字形,只研究其读音、释义或其他方面的内容,则没必要看作两个字符,完全可以认同为一个“刻”字。但需要注意的是文本化阶段的“判同”还是“别异”,其结论将直接影响将来下一步校勘的结果。
(三)自动分割与属性标注
在自动校勘过程中,计算机可以借助特定的程序指令对字符之间的差异进行机械的比较。比较的基本过程是:计算机会将一个版本中的所有字符看成一个字符串,与另一个版本的字符串进行比对,如果相等,则跳过;如果不等,则切分成诸多子串,再进行比对,并把比对的结果分别反馈为异、脱、衍及倒等几种情况。该类动作循环进行,直至对整个文本对比结束。在这个过程中,至为关键的是如何切分篇章问题,即:自动切割技术。一般来说,字书作为一种工具书,有着明显的体例和结构分布,在段落分割方面相对清晰。但是,段落内部还有着丰富的知识信息,需要进一步详细标注。所以,寻找形式标记、归纳属性模板和实现自动标注应该是自动分割的前提。就目前来讲,从字书中提取到的主要属性要点有字头、释音、释义、释形和注释等,这些属性有的有形式标记,例如:字头一般为大字;释音一般用某某切、某某某某二切、某某某某某某三切、某某反、音某、某声、某韵、叶音某和谐某等来提示;释形主要指“六书”解释法,具体描述主要有“象某某之形”、“从某某声”及“从某从某”等;注释所含的内容相对复杂一些,无法归入前述属性类别的都暂时处理为注释部分,例如:案语、书证、人证、上同、同上、文几和重音几等内容都标记为注释。
关键词除了标注上述属性要点,还需要建立一定的专类知识库加以辅助,形成索引。与版本校勘相关的专类知识库主要有:中国字书专名库,主要用来帮助自动提取字书类专有名称,例如,《说文解字》《玉篇》《龙龛手鉴》《五音集韵》《方言》和《广雅》等;字书引文知识库,主要是用来帮助自动提取作为例证的各类引文的书籍名称,例如,《周礼》《庄子》和《汉书》;“小学”专家名称库,主要用来帮助自动提取“小学”专家名称,例如,许慎、段玉裁、顾野王、扬雄、陈彭年和宋祁;异体字字表,主要用来帮助对比不同版本中的字形差异,沟通字际关系。
收稿日期:20141208
基金项目:“中国博士后科学基金”第七批特别资助,第五十六批面上资助项目(224241)
作者简介:朱翠萍(1980-)女,山东德州人,北京师范大学文学院文字学专业在站博士后,主要研究方向为汉语言文字学。
中图分类号:TP 311.52文献标识码:A
总之,自动校勘是在前述版式分析、字符识别和属性标注等工作的基础上进行的,其整个系统工作的流程可以通过图3示来展现。
三、搭建版刻楷体字书校勘平台的意义和应用前景
版刻楷体字书计算机辅助版本校勘系统将是一个非常有价值的系统平台,一旦搭建成功,将有利于提高校勘的效率和准确性,减少单纯人工校勘与笺注过程中不必要的时间浪费和失误。另外,这一系统平台的建立将有利于改变新时代字书研究者的工作方法,原因在于目前计算机虽然很普遍,但对多数字书研究者来说,还仅仅局限于代替手写这一最基础的工作,其它大量重要的工作内容还都处于手工劳动阶段。如果该系统能顺利运行,新型字书研究者将会把目光转向自动化方面,全方位利用计算机技术来进行文字整理与研究工作。
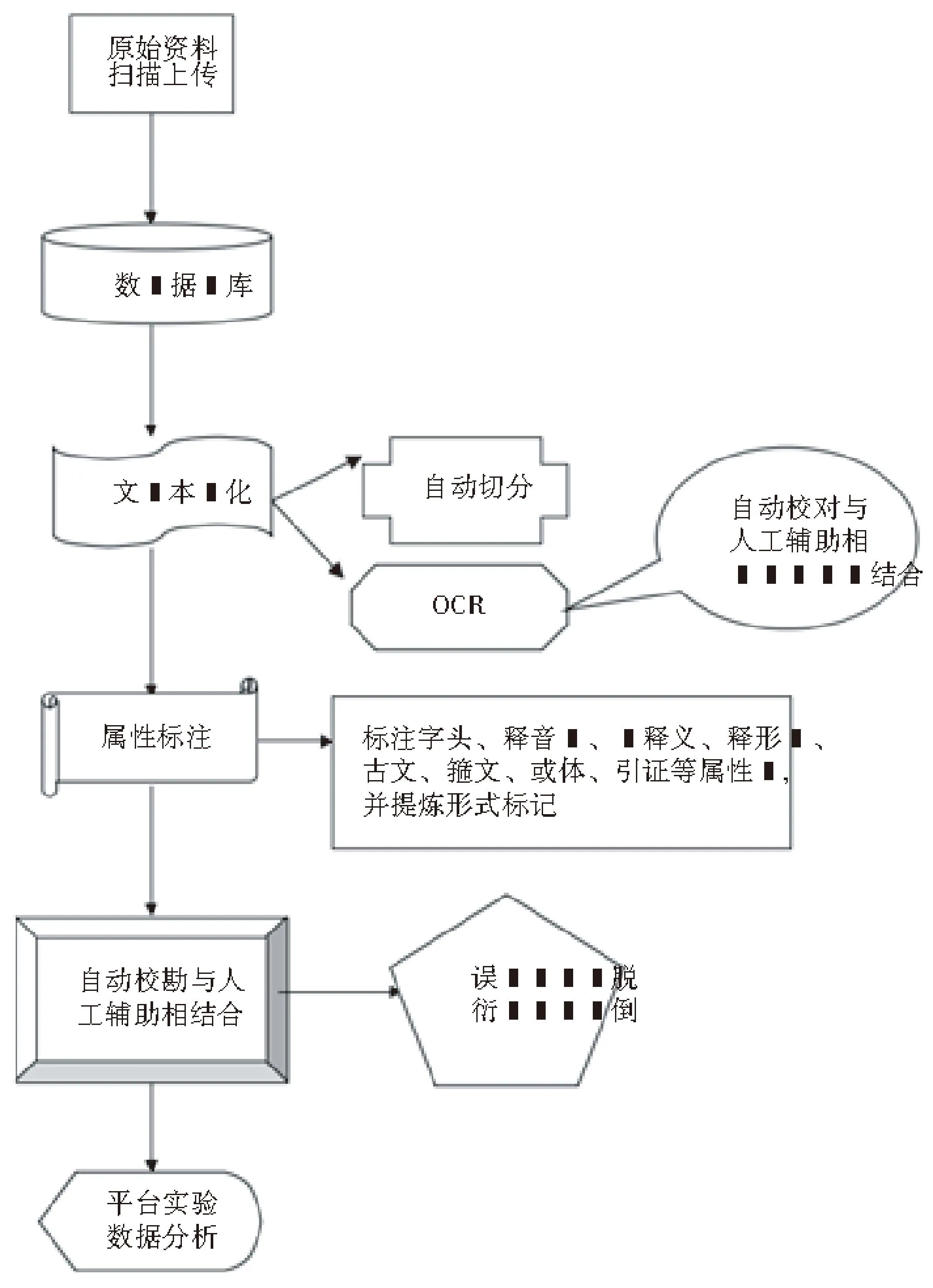
图3 版本校勘平台流程图
该系统将是字书整理甚至是古籍整理界的一个很好的工作平台。古籍研究者可以借助此平台进行文字切分,达到采集的目的。也可以对所采集到的数据进行属性标注,以便根据研究需要进行统计分析,得出较为全面、切实的结论,从而提高文字研究的水平。古籍出版者可以利用该平台所提供的影像数据制作影印善本,或者等不同版本的校勘工作完成之后,筛选出较为理想的版本,制作高质量的校点本。汉字教学者可以利用从该平台中获得的丰富的数据资源和汉字理据,突破单纯的继承前人结论和人云亦云的局限,从源头上审视所授内容,并形成自己独特的见解,从而增添汉字教学的特色性。
综上所述,随着大数据时代的到来,在古籍资源获取及目录检索等方面的效率都将大大提高,这为自动校勘奠定了技术基础,重拾人们对于古籍版本校勘的信心。但是,技术和理论是矛盾的两个方面,技术的发展推动着新的理论和视角的诞生,新的理论和视角反过来又影响和指导着新技术的实现空间。只有两者相适应,才会最大限度地发挥效能。
参考文献:
[1]李国新.中国古籍资源数字化的进展与任务.大学图书馆学报,2002,(1):21-26.
[2]倪其心.校勘学大纲.北京:北京大学出版社,1987.
[3]陈垣.校勘学释例.北京:中华书局,1959.
[4]陈力.中文古籍数字化的再思考.国家图书馆学刊,2006,(2):42-48.
[5]王芸,肖禹.汉语古籍全文文本化研究.上海:中西书局,2012.
[6]李先耕.古籍用汉字库的要求.第一届中国古籍数字化国际学术研讨会论文集.北京:五洲传播出版社,2009.
[7]刘志基.建设通用数字化平台推动古文字研究现代化.东方学术文库(第二卷).上海:上海人民出版社,2004.
Assumption on Building a Computer-aided Platform for
Collating Relief Printing Dictionaries
ZHU Cui-ping,ZHANG Xian-rong
(School of Chinese Language and Literature,Beijing Normal University,Beijing 100875,China)
Abstract:With the arrival of the era of big data,methods of collatiing ancient books are constantly updated,and it is inevitable to build a computer-aided platform for collating relief printing dictionaries.From the perspectives of resource organization,image textulization,automatic segmentation and marking property,the article discusses some necessary problems in this field,which will lay a good foundation for the platform building.
Key words:relief printing;regular script;dictionaries;version;automatic collation;platform
(责任编辑乔志杰)
