基于内存映射文件的进化算法数据存储引擎
2015-04-14姜三义代真真周爱民
姜三义,代真真,李 阳,周爱民
华东师范大学 计算机科学技术系,上海 200241
1 引言
基于统计和机器学习的进化算法目前日益引起人们的重视。进化算法[1]是一种通过多次迭代搜索来获取全局最优解的随机优化算法[2]。作为一类启发式搜索算法,是否具备良好的搜索记忆功能,即通过一定方式存储并利用已搜索的解空间,是评价算法好坏的关键之一。从本质上来说,进化算法维护的种群和其他信息实际上可以看作是一个动态变化的数据集(数据库)。当前及历史数据集隐含了进化算法搜索的规律,因此可以通过模式识别和机器学习的方法来挖掘隐含在这些数据集中的规律并指导进化算法的搜索。有效存储和组织当前和历史群体信息,是实现这类算法的前提。
由于进化算法的搜索空间往往比较大,存储记忆时需要平衡算法效率和磁盘空间[3]。随着计算机磁盘容量的迅速增长和单位容量成本的降低,可以将更多的算法数据存储到磁盘中。但是在性能上,现有的通用数据库技术或传统文件存储方式并不能很好地满足这种需求。使用通用数据库时,需要额外搭建专有的数据服务系统,进行数据库维护,并且由于数据库索引等机制的存在,数据库对于大量实时算法数据的存储效率并不理想。算法设计人员因而往往将数据以文件的形式直接存储到磁盘上。由于磁盘I/O的效率问题,采用传统文件方式保存数据会大量增加算法的执行时间。现代操作系统支持基于虚拟内存技术的内存映射文件机制。通过使用内存映射文件,存储速度相比于传统文件I/O方式可以得到极大提升[4]。
内存映射是将磁盘上的文件或部分文件内容映射到进程地址空间内部区域的一种机制。通过创建内存映射文件,应用程序可以直接读写内存来访问磁盘文件数据,相比于使用文件的读写函数具有更快的I/O速度。在Windows和Linux操作系统中都支持内存映射文件机制,通过使用系统提供的编程接口,应用程序可以利用内存映射机制提高I/O效率。
内存映射文件可以被直接应用于程序中,对于一些简单的程序是完全可行的。但是在进行复杂数据结构的存储组织,并且需要确保大量数据和文件的可靠和安全时,需要进行复杂的代码设计和编码调试工作,以解决合理分配和动态扩展数据文件,存储不同数据结构等问题,这对程序编码人员提出了很高的要求,在很大程度上限制了内存映射文件技术被广泛利用。
本文介绍了使用C++编程语言实现的嵌入式数据存储引擎(EADB),EADB利用内存映射文件实现了数据存储,支持Linux和Windows这两个不同平台,提供统一的读写接口,支持复杂数据结构的存储组织。通过使用EADB,应用程序在获得I/O性能提升的同时,可以减少编码工作量。通过在进化算法中使用EADB,提高了进化算法执行过程中的数据存储效率。
2 算法记录
本文称进化算法迭代过程中产生的解为“算法记录”。不同进化算法的执行框架基本相同,首先进行种群随机初始化和个体适应度计算,然后进行有限次数的迭代使得群体在搜索空间中不断进化。每一次迭代包含的步骤包括:重组、变异、适应值评估和选择等。每一次迭代产生的解包含染色体、适应值或其他信息[5]。
进化算法的种群个体(即染色体)可以表示为确定长度的二进制位串或格雷码,也可以使用符号集、实数或实数数组来表示。进化算法作为一类启发式搜索算法,也被成功应用于多目标优化领域[6-7]。每个种群个体的适应值,在单目标优化和多目标优化问题中的表示方式是不一样的。在单目标优化问题中,适应值是一维的变量;而在多目标优化问题中,适应值则一般是多维的向量。由此分析,算法记录中的内容在形式上包括一维变量和多维向量,所以可以使用数组来统一存储记录内容[8-9]。
同一个进化算法在每一次迭代中需要保存的数据记录的数量有可能不同,例如在基于分解技术的多目标进化算法(Decomposition based Multi-Objective Evolutionary Algorithm,MOEA/D)求解背包问题的算法中,每一代最优群体的个体数量可能是不同的[10]。但是,在同一个进化算法的一次执行过程中,算法记录的内容在结构上是一致的。
3 内存映射文件
内存映射文件的实现借助于操作系统底层的虚拟内存机制[11]。使用虚拟内存的目的是为了弥补物理内存的容量不足问题。在虚拟内存系统中,每个进程拥有独立的连续完整的地址空间。基于程序的局部性原理,操作系统仅将运行进程所必需的一部分指令装入内存,在进程执行时通过请求调入和置换功能进行内外存数据交换,使进程能够持续运行。
虚拟内存技术不仅仅解决了物理内存容量不足的问题,它的出现使得操作系统发生了巨大的变化。当今大部分操作系统(包括Windows和Linux)在I/O系统中均采用了文件缓存机制(在Windows中称为系统缓存,在Linux中称为页面缓存),在内核虚拟地址空间中分配一个分段用于文件数据缓存。操作系统进一步将该分段划分为块,每一块包含若干分页(在32位Windows系统中,页面大小是4 KB,分块大小是256 KB;在32位Linux系统中,页面大小是4 KB,分块大小也是4 KB)。在访问文件时,操作系统始终按块为单位(即使只访问一个字节数据)将文件数据拷贝到文件缓存中。当文件缓存中的页面被调度到物理内存中后,内存与磁盘文件之间建立了字节上一对一的关系,在页内的数据访问都是在物理内存中完成的,避免了频繁的文件I/O,极大提高了读写能力。同时,由于虚拟内存的“按需调度”原则,只将一部分数据而非整个文件调入内存,因而可以节约大量物理内存[12-13]。
内存映射文件在此基础上进一步加快了文件访问速度。使用传统文件I/O方式时,仍然需要通过系统调用(即文件读写函数)从内核空间将数据复制到用户空间,即读操作使用的内存缓冲区。而建立内存映射文件后,操作系统将进程的虚拟页面直接映射到系统文件缓存上,使得进程可以直接访问这一部分内存。通过建立内存映射文件,一方面避免了使用系统调用,访问速度得到数量级的提升;另一方面,在用户空间中无需对文件内容进行缓冲,不仅减少了物理内存复制工作,还节省了一半的物理内存空间[14]。
内存映射文件带来的另一个优点是在编写数据存储程序的时候,在内存及外存中只需要定义一套数据结构,可以直接将内存映射区域中的数据看作程序中定义的数据结构类型对应的对象[15]。
内存映射文件允许将文件的一部分映射到内存中,从而可以处理非常大的文件。Windows支持的文件大小最大达到16 EB。Linux支持的最大文件大小在不同的文件系统上略有差别,大部分系统都实现了LFS(大文件系统)技术,文件大小可以达到或超过2 TB。
4 存储引擎的实现与使用
4.1 存储引擎的数据表示方法
本研究定义了一种数据描述方法:ASON(Algorithm Structured Object Notation),即算法结构化对象表示法,来描述算法记录,可以满足进化算法记录的数据存储要求。每一个ASON所描述的算法记录可以包含若干个数据字段,每一个数据字段都是一个键值对(key-value pair),每个键名是一串字符串,键值是一个数值数组。例如,ASON可以表示如下使用键值对描述的算法记录:

记录中的“popsiz”、“gen”、“fitness”、“chromo”分别表示种群大小、当前迭代值、个体适应度和染色体。使用ASON可以实现对象内数据字段的灵活组合,不仅可以包含进化算法的适应度及染色体,还可以包含其他的数据字段。本文为简单起见,只考虑染色体和适应度值信息。
使用C++宏“ASON”在程序中按照C++数据流的序列化方式构建算法记录,采用STL的std::vector容器作为数组类型。宏ASON的使用方法参见如下代码:

宏“ASON”返回的是抽象数据结构类型ASONObj的对象实例。在内存中,一个ASONObj对象表示为二进制字节序列。首先是4个字节表示对象长度,紧接着是若干个数据字段,最后是结束标志符。每个数据字段的第一个1个字节表示字段值类型;然后是一条字符串,表示字段名称,由字符’�’结尾;接着是4个字节表示字段维数,然后是表示数组数据的若干个字节。这种数据结构支持了对象内数据字段的遍历。ASONObj对象的内存结构如图1所示。

图1 ASONObj对象的内存结构
图中注明了各个域所占用的存储空间大小,单位是字节(Byte),其中值数组所占用的存储空间大小N=值维数×该类型数值变量所占用字节数。字段值的类型是一个C++枚举值:


其中的MinKey和MaxKey表示类型代号的最小、最大值,分别是-1和127,这样所有的类型值可以用一个字节表示。因为数据字段的第一个字节表示字段值的类型,所以结束字段只需要一个字节用于存储EOO表示对象结束,而无需作为一个完整的数据字段。
ASONObj提供objdata()和objsize()函数将数据提供给调用者,表示整个对象的数据内容和长度。
4.2 数据文件结构的设计
数据文件的内容包含两部分:文件头和记录列表。文件头部包含数据存储引擎的版本号、文件长度等基本信息,还包括文件空间的信息。记录顺序的保存在文件中,每一条算法记录又被封装为一条“文件记录”。
类DataFileHeader定义了数据文件的头部数据结构,其中的主要数据成员如图2所示。

图2 文件头数据结构
文件的头部占据64 KB的空间。预留较大的空间便于对文件头部数据结构的扩展定义。文件头部数据结构的头部大小用“file_header_size”表示,值为65 536。
变量“data”是C++中的一种实现手法,变量“data”的地址就是指向第一条文件记录的地址。
变量“unused”用于存储未使用位置在文件中的地址偏移量,初始值为file_header_size。变量“unused-Length”用于存储文件中尚未使用空间的字节数。数据文件的大小是按照需求量逐步扩充的。当“unused-Length”小于下一条文件记录的长度时,存储引擎自动地扩大文件,可以在实际过程中调整扩增的大小。
变量“fixed”用于表明该文件中的所有文件记录是否长度相等。为了加快数据存储速度,本研究并没有在数据文件中加入任何索引机制。对于所有文件记录等长的情况(fixed等于1),EADB可以通过类似C++数组下标访问的方式快速地访问每一条文件记录,这是最快的数据寻址方式。对于变长记录则需要通过遍历每一条文件记录,获取并叠加记录的长度来逐步定位。
每一条文件记录都包含自身的头部结构和数据体。在存储进化算法的算法记录时,文件记录的头部只需包含文件记录长度。类FileRecord定义了文件记录的数据结构,如图3所示。

图3 文件记录数据结构
记录的数据结构的变量“length”存放记录的长度,其值中包含头部自身的长度。变量“data”是C++中的一种实现手法,变量“data”的地址就是记录中数据的其实地址。文件记录数据结构的头部大小用“record_header_size”表示,值为4。
4.3 内存映射文件的数据访问方法
创建内存映射文件的时候,新建文件的大小至少应为文件头的大小(FileHeaderSize)。在执行创建内存映射文件的步骤之后,需要对文件头部数据结构的字段进行初始化。
在创建内存映射文件时,可以得到内存映射区域的内存地址,通过该地址可以在内存中直接访问文件数据。如果从文件起始处建立内存映射区域,则偏移位置0就是DataFileHeader对象在内存中的起始字节。
对于每一条文件记录,也是相同方法,从文件中偏移位置65 536开始,通过类型转换得到文件记录对象的指针,可以实现文件记录对象的逐条遍历。
算法1和算法2分别描述了对内存映射文件进行数据写入和读取的操作。同时假定由MAP-VIEW算法来创建内存映射区域,所创建区域的内存地址为position,MEMORY-COPY算法执行内存复制。
算法1内存映射文件数据写入

算法2内存映射文件数据读取

算法1和算法2通过偏移地址访问数据记录,其中的对象“obj”是ASONObj类型的实例。偏移地址address不包含文件头部长度,需要在访问数据文件内容时将其纳入。
FILE-WRITE-AT-POSITION用于改变文件中的数据。对于新增加数据记录,则算法的输入address即为变量“unused”的值。写入数据时执行内存拷贝操作MEMORY-COPY,然后调整文件头部unused和unused-Length两个状态变量的值。
FILE-READ-AT-POSITION用于读取文件中的数据。在数据读取时,创建内存映射区域之后,根据偏移量定位,可以准确获得数据记录在内存中的地址。通过C++强制类型转换,就可以从该地址构造出指向数据结构DataFileHeader对象的指针,从而获得记录的数据内容和长度,并最终转换为ASONObj对象。
4.4 ASON对象的精简存储
每一个ASON对象中都添加了字段名称以及其他的一些辅助信息,这将造成数据存储空间的浪费。为了避免空间浪费,当DataFileHeader的“fixed”变量为1的时候,利用其中的“cache”字段,将一个完整的ASONObj对象保存在“cache”中,然后,在文件记录中仅保存数据字段的值数组。这样可以有效减少所需存储空间。在获取记录的时候,根据“cache”中缓存的ASONObj结构信息,可以从精简的文件记录中快速的构造出完整的ASONObj对象。
使用上述方法要求算法记录的长度不超过64 512字节。此外,若是文件中记录长度不一致,也无法使用如上所属的精简存储方式。
4.5 存储引擎程序应用接口
EADB的应用接口通过C++类EADB提供,主要包括open、close、Add和Get四个方法。Open和Close用于打开(创建)和关闭一个数据文件;Add用于向数据文件中添加算法记录;Get用于获取算法记录。操作接口使用的数据结构是ASONObj。

Open方法参数“filename”表示数据文件名称;参数“fixed”用于指示是否所有记录的内容及长度一致:一致则可以使用ASON对象的精简存储;参数“fileStepSiz”用于指示数据文件扩容的步长。根据不同算法设定合理的步长,可以在一定程度上加快存储速度。
4.6 数据文件的查看与数据导出
EADB支持通过存入的顺序来访问数据记录。为了查看数据文件中的数据,本研究开发了GUI数据文件管理程序,用于显示数据文件的基本信息,例如迭代次数、种群数量等,查询算法记录,或者将算法记录根据某种规则导出为文本文件,用以在Matlab或其他程序中使用算法记录进行算法可视化等分析工作。
5 实验结果及分析
5.1 实验1基本性能测试
为了测试数据存储引擎的性能,本文将EADB与采用标准C函数库的文件I/O方式和用谷歌公司的LevelDB用来存储变长字符串进行实验对比,观察其数据存储速度。LevelDB是谷歌公司推出的超高性能文件数据库,支持键值对存储和索引。
本文分别用较长数据和较短数据做比较,这样更能对比不同方法的性能。较短数据测试中,随机生成小于201字节的可读字符串;较长数据测试中,随机生成小于5 001字节的可读字符串。两个实验各自包含30组数据,每组数据的数量分别为20 000的倍数。每次实验时对每组数据进行30次测试然后计算耗时均值。在Windows 2008 Server R2 64位操作系统上运行,CPU为Intel Xeon X5680,3.33 GHz,96 GB 内存,外部存储器为Promise VessRAID 1 840 s SCSI RAID5磁盘阵列,其中的磁盘驱动器为西部数据WD2002FYPS硬盘(2 TB,7 200 r/s)。存储较短数据的三种方式的效率曲线如图4所示。

图4 Windows上较短数据实验结果
图4结果显示出,对于短数据,用EADB比文件I/O和LevelDB的速度快。随着存储数据的数量的增加,EADB的优势越来越明显。由于各种因素的影响,例如计算机中同步处理了大量其他任务,导致实验结果的曲线有一些跳跃,但是可以得出,各种存储方式的存储效率均呈线形变化,这意味着数据存储速度可以在数据量持续增大时基本保持不变。比较来说EADB方式性能最好,存储速率最高。
存储较长数据的三种方式的效率曲线如图5所示。
图5结果显示对于更长数据的存储,EADB仍然比文件I/O和LevelDB快,并且随着存储数据的数量的增加,EADB速度上的优势越来越明显。同时可以看出,随着数据量的增多,LevelDB存储方式越来越不稳定。比较来说EADB方式对长数据的存储性能也是最好,存储速率最高。

图5 Windows上较长数据实验结果
由此可见,对于存储任何数量级别的数据,EADB都表现出明显的优越性,且随着数据的增多,性能优势越明显。
5.2 实验2多目标进化算法实验
进化算法有很多分支,本文选取较为复杂的MOEA/D算法求解多目标背包问题进行实验。通过选择多个不同的测试题,设定不同的背包个数(代表目标数)、物品数(即变量数、决定染色体长度)和种群大小,来代表不同难易程度的问题。
此次实验是在MOEA/D算法的每一代计算之后保存染色体、适应度以及权重三个指标,这三个指标的数据类型均为实数数组。算法对15个测试题进行6轮运算;测试环境与实验1相同。实验结果如表1所示。
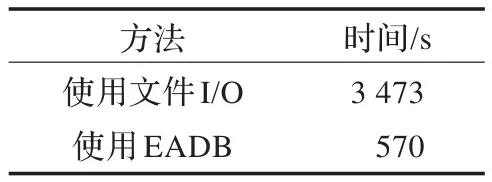
表1 MOEA/D算法测试结果
由表1数据可以看出,在使用MOEA/D算法解决问题的过程中存储算法数据时,使用EADB耗费的时间仅仅是文件I/O方式的16%。换句话说,使用文件I/O方法时,算法程序执行所消耗的84%以上时间是进行文件I/O操作,真正执行算法运算的时间不足16%。由此可以得出结论:使用EADB替代文件I/O可以大大提高算法程序执行的效率。
6 结语
进化算法的应用范围十分广泛,已经在众多科学计算领域和工程领域得到了应用[16]。许多进化算法的执行时间往往达到或超过数小时,其执行过程中产生的算法记录是进行算法分析的重要依据。EADB通过采用内存映射文件技术,实现了快速数据存储,减少进化算法执行过程中因数据存储而带来的时间耗费,有效促进了进化算法的实现。同时,EADB作为一个嵌入式数据存储引擎,不仅使用简便,还可以在多个方面进行优化,进一步提升速度。
[1]Michalewicz Z.Genetic algorithms+data structures=evolution programs[M].3rd ed.Berlin:Springer-Verlag,1999.
[2] 谢金星.进化计算简要综述[J].控制与决策,1997,12(1):1-7.
[3]郑有志,覃征,邹玲.关于进化算法记忆存储方法的探讨[J].计算机应用研究,2007,24(4):88-90.
[4]Silberschatz A,Galvin P B,Gagne G.Operating system concepts[M].北京:高等教育出版社,2007.
[5]姚新,陈国良,徐惠敏,等.进化算法研究进展[J].计算机学报,1995,18(9):694-706.
[6]公茂果,焦李成,杨咚咚,等.进化多目标优化算法研究[J].软件学报,2009,20(2):271-289.
[7]Purshouse R C.On the evolutionary optimisation of many objectives[D].Sheffield:University of Sheffield,2003.
[8]余有明,刘玉树,阎光伟,等.遗传算法的编码理论与应用[J].计算机工程与应用,2006,42(3):86-89.
[9]Baskar S.Performance of hybrid real coded genetic algorithms[J].InternationalJournalof ComputationalEngineering Science,2001,2(4):583-601.
[10]Zhang Qingfu,Li Hui.MOEA/D:a multiobjective evolutionary algorithm based on decomposition[J].IEEE Transactions on Evolutionary Computation,2007,11(6):712-731.
[11]Bryant R E,O’Hallaron D R.Computer systems:a programmer’s perspective[M].2nd ed.Boston:Prentice Hall,2011.
[12]Richter J,Nasarre C.Windows via C/C++[M].5th ed.Washington:Microsoft Press,2008.
[13]Bovet D P,Cesati M.深入理解Linux内核[M].3版.北京:中国电力出版社,2007.
[14]杨宁学,诸昌钤,聂爱丽.内存映射文件及其在大数据量文件快速存取中的应用[J].计算机应用研究,2004,21(8):187-188.
[15]Buhr P A,Goel A K,Wai A.μDatabase:a toolkit for constructing memory mapped databases[C]//Persistent Object Systems Workshops in Computing,1992:166-185.
[16]玄光男,程润传.遗传算法与工程设计[M].北京:科学出版社,2000.
