基于主动学习和自学习的噪声源识别方法
2015-04-14高志华贲可荣
高志华,贲可荣
海军工程大学 计算机工程系,武汉 430033
1 引言
潜艇声学故障识别是根据影响潜艇隐身性能的振动异常壳体部位向内定位出仓内设备或区域(即查找内部主要噪声源),从而提供声学故障报警和修复建议[1]。因此声学故障识别研究对于提高潜艇隐身性能十分关键,也是目前研究热点之一。潜艇中的故障会带来不正常的机械振动,从而引发异常的声响。由于振动参数比起其他可从潜艇中获取的状态参数更能直接、快速、准确地反映机器运行状态,所以振动噪声信号一般作为对机组状态进行监测与诊断的主要依据。实际应用中很难获取到描述各种故障(工况)状态的噪声源样本,即可以采集到大量的机械噪声数据,但对这些数据进行标注需要专家参与且要耗费大量时间且代价昂贵。由于存在可用于学习的已标注噪声源样本严重缺失的问题,因此研究小样本条件下潜艇的机械噪声源识别具有重要意义。
在拥有少量有标识样本的情况下,如何利用大量的未标识样本来改善学习器性能成为当前机器学习研究中最受关注的问题之一[2]。研究表明,对于训练样本的精确标记不但需要该领域中大量的专家参与,并且标记样本花费的时间是其获取时间的10倍以上[3]。这种现实使传统的机器学习算法无法得以有效应用,原因在于监督学习需要大量标记样本对分类器进行迭代训练,否则根据 PAC(Probably Approximately Correct)学习理论,算法的泛化性能无法有效提高[4]。
在这种情况下,半监督学习和无监督学习方法应运而生并迅速发展,成为解决上述问题的重要技术。半监督学习中的主动学习技术利用一个好的样本选择策略对众多未标注样本进行选择标注,使之能够加入到训练集中进行训练[5]。本文提出一种基于主动学习和自学习的SVDD(Support Vector Data Description)噪声源识别方法,该方法首先采用不确定性采样策略从大量无标记样本中选择信息量大的样本交给专家进行标注,然后对未标记样本加以利用,选出部分有代表性的样本进行自动标注,进一步将通过主动学习和自学习标记后的样本加入到训练集中对分类器SVDD进行循环训练,以实现在最少标记样本代价下最大程度地提高分类器的性能。
2 基于主动学习和自学习SVDD分类算法
2.1 支持向量数据描述方法
支持向量机(SVM)方法具有良好的理论性质,如以统计学习理论为基础的泛化能力,以核方法引入的非线性机制,以及凸优化理论保证的全局最优解性质等[6]。与已有的机器学习方法(如神经网络)相比,SVM更易于使用,因此在许多领域得到了广泛应用。支持向量数据描述方法(SVDD)灵感来自于支持向量机,是一种采用直接寻找封闭区域分类的单类(one-class)分类方法[7]。Vapnik认为如果样本的数据量比较小时,采用直接寻找封闭区域的方式来分类比估计概率密度的方法更为有效[8]。
给定数据集{xi}(xi∈Rn;i=1,2,…,N),通常情况下,即使排除了偏远的样本点,数据依然不会呈现球状分布。为了使算法适用于更广泛的领域,SVDD采用同SVM方法类似的核函数方法,把样本变换到更高维的特征空间,假设非线性映射ϕ(x)将数据映射到高维特征空间。奇异的数据点应该位于超球体的外面,为了减少奇异点的影响,引入松弛因子ξi≥0(即允许存在错误)。为训练样本建立一个最小超球,设超球球心和半径分别为a和R,则广义描述模型即为如下凸二次规划:

约束条件为:

其中C是一个常数,控制对错分样本的惩罚程度。将式(2)代入式(1)引入Lagrange系数后优化方程变为:
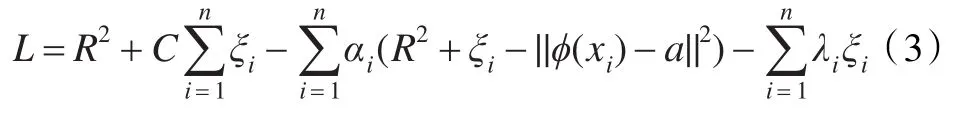

图1 基于主动学习和自学习的学习系统框图
对于任一支持向量xs,R由下式给出:

正定核或Mercer核都可以用来作为SVDD的核函数,本文选用高斯核:
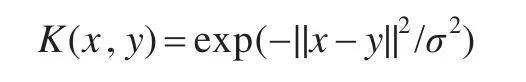
本文将one-class分类方法SVDD扩展至多类分类问题中。初始训练时为每一个模式类构建一个超球,使得该超球体内包含该模式类别中的所有已标注样本。当大量未标注样本载入后,选择其中最有“价值”的样本进行标注,并将最终选择的样本加入到训练集中进行学习以更新分类模型。在选择最有“价值”样本的过程中,既考虑到样本的不确定性,又兼顾样本的代表性,采用主动学习技术和自学习相结合的方法对样本进行标注。
考虑到构造训练样本集的标注负担,在算法设计时主要从两个方面出发:(1)对于选出的用于人工标注的样本必须是对于当前的分类模型而言最具信息量的,以最大化人工标注的效率;(2)对于剩余的大量未标注样本所包含的信息,在不增加人工标注负担的情况下,要进一步加以利用。基于以上两点考虑,本文提出了一种基于不确定性样本选择和代表性样本选择相结合的SVDD分类算法。其中,最具信息量的样本采用主动学习技术选取,提供给专家进行手工标注。在剩下的未标注样本集中选择有代表性的样本进行自动标注,进一步对训练样本集进行补充更新。本文提出的基于主动学习和自学习的SVDD分类系统,如图1所示。
该学习系统包括两个部分:学习引擎使用SVDD作为基准学习算法得到分类器,对训练集进行训练,对测试集进行测试。选择引擎综合考虑未标注样本集中样本的不确定性和代表性两个因素,选择最有“价值”的样本进行标注,并将最终选择的样本加入到训练集中进行学习以更新分类模型。算法在分类器达到指定分类率或指定迭代次数时终止。
2.2 不确定采样的主动学习
主动学习(active learning)技术可以解决标注困难带来的有限样本情况下的分类问题,在主动学习中,学习器主动选择那些对于当前分类模型最有价值的样本进行标注,并将这些带有类别标号的样本添加到训练样本集,对分类模型进行重新训练。通过迭代的方式,对分类模型进行更新[9]。采样策略是主动学习技术的核心,可以分为3种:基于不确定性的采样策略、基于版本空间缩减的采样策略和基于误差缩减的采样策略[10]。
基于不确定性的采样策略是适用性最广的一类采样策略,它可以有效减少人类专家的工作量,提高分类器的分类精确度和泛化能力,是目前研究最为充分的采样策略[11]。这种采样思想虽然适用于大多数分类模型,但在与不同分类模型时,算法实现方式各不相同。本文选择的是SVDD这样一种采用封闭区域分类的分类模型,采样策略使用样本与区域描述边界之间的距离作为计算形式,选择与落入单类描述边界之外或多类描述区域重叠的样本作为最不确定的样本。
对于多类分类问题,SVDD对每一个目标类训练一个相应的超球,假设有m类,每个类分别被标记为ωi(i=1,2,…,m)。将属于类别ωi的训练样本记为子集Di,用Di训练一个SVDD分类器,并计算出相应的中心ai和半径Ri。设未标注样本集为U={x1,x2,…,xn},Y={1,2,…}为可能的类别标号,ai为由已标记样本集确定的m个模式类的SVDD超球球心。未标注样本xs(xs∈U)到球心ai的距离为:

当m个最小超球确定之后,它们之间的位置也随之确定。理想的情况是超球之间彼此独立,但实际上超球之间完全有可能出现交叠的情况,因此新样本xs与超球之间的位置关系有3种:(1)xs落入某一个超球中;(2)xs落入两个或多个超球的交叠区域;(3)xs落在所有超球之外。
情况(1)说明未标注样本xs同时落在两个(或更多)已知类别的封闭决策区域之内,即被标记了多个类别标签。情况(3)说明未标注样本xs落在所有已知类别的封闭决策区域之外,即被判决为不属于任何已知类别。这两种情况都说明了样本xs不能被已有的学习模型预测所属类别,样本所属类别具有不确定性,需要交给专家进行人工标注。
2.3 代表性样本的自学习
在大量未标注样本集中提取不确定性样本交由专家标注之后,可以进一步从剩下的未标注样本集中提取部分确定的且具有代表性的样本进行自动标注,然后加入到训练样本集中,用于提高分类模型的泛化性能。自学习是半监督学习中一个常用的技术[12]。在自学习中,添加到训练样本集里的样本的标号不是由用户进行人工标注,而是由当前的分类器预测得到的。从直观上说,如果选择那些在当前分类器下分类结果最明确的样本进行自学习,引入错误标号的概率是最小的。但是从样本所包含的信息量这个角度来说,这些分类结果最明确的样本所包含的信息量是非常低的,对于当前分类面的影响极小。因此,将这些样本加入到训练样本集,对分类模型的影响很小,同时反而增加了分类器训练时的计算负担。为解决以上矛盾,本文通过设置阈值来提高自学习选出样本的信息量。
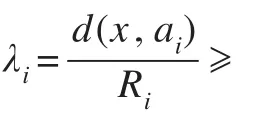
2.4 ALSL-SVDD算法描述
假设ω为已知模式类别,将训练样本集和未标注样本集分别记为L和U,其中L是在初始分类时,由专家人工标注的少量样本。
步骤1用训练样本集L采用SVDD算法训练出ω个超球状封闭决策区域。
步骤2导入未标注样本集U。
步骤3用训练生成的ω个SVDD分类器对未标注样本集U进行预测:
(1)采用2.2节中的不确定样本选择的主动学习策略从U中选出M个样本,所构成的集合记为SAL,由专家对SAL中的样本进行人工标注;
采用2.3节中的代表性样本的自学习方法从剩余的未标注样本集合U-SAL中选出N个样本,所构成的集合记为SSL,并记录其类别标号,即进行样本的自动标注。
步骤4更新训练样本集:Lnew=L∪(SAL∪SSL)。
步骤5更新分类模型:用训练样本集Lnew重新训练SVDD分类模型。若达到指定分类精度或迭代次数,则算法停止;否则转至步骤2。
3 实验及相关分析
3.1 实验数据
实验使用1∶1实体舱段模型构建仿真环境,在舱段内安装了泵、电机、激振器3种设备各一个,3种设备各自有不同的工作模式,泵可以工作在关闭、半开、全开3种状态,电机可以工作在关闭和开启两种状态,激振器可以产生不同工作电压下频率不同的振动。3种设备各自的工作模式与不同模式之间的组合,共形成45种工作模式(工况),用以模拟潜艇的正常或突变时的机械噪声源。使用布设在相应部位的振动加速度传感器进行振动噪声信号采样,通过功率谱特征提取方法处理采样信号,经过采样保持、A/D转化、低频滤波、FFT变化、积分压缩、归一化,最终提取25维特征向量作为噪声源样本进行研究。实验环境中共布设了19个振动加速度传感器,本文实验只针对单传感器采集数据,数据由布设在耐压壳左舷位置的传感器采集获得。
3.2 实验设置与结果分析
设计实验验证本文提出的ALSL-SVDD算法的性能,实验环境是PC机2.5 GHz CPU,2 GB内存,Windows XP操作系统,Matlab 7.1实验平台。实验以SVDD为基准分类模型,参数设置:核函数为RBF(Radial Basis Function),惩罚因子ξ和控制因子C通过十折交叉验证每次均取最佳参数。
实验采用有标注数据进行学习的算法(简称Init)和随机采样方法(简称Random)作为对比算法。有标注数据进行学习的算法是一般的有监督学习方法,训练时需要大量已标注样本。随机采样方法可以认为是一种被动学习,被动地接受随机选定的训练样本,忽略了样本包含的信息量。本文提出的ALSL-SVDD学习算法从未标注样本集中选择最有价值的样本,可以更快改善分类器的性能。实验分别从各类别识别率、总识别率和样本标注代价两个方面对算法的性能进行评价。
实验选取6种典型工作模式(工况),每种工况16个样本。将整个数据集各类分别取30%作为已标注样本集,50%作为未标注样本集,全数据集用于测试。表1给出了3种算法各类别的识别率和总的识别率。
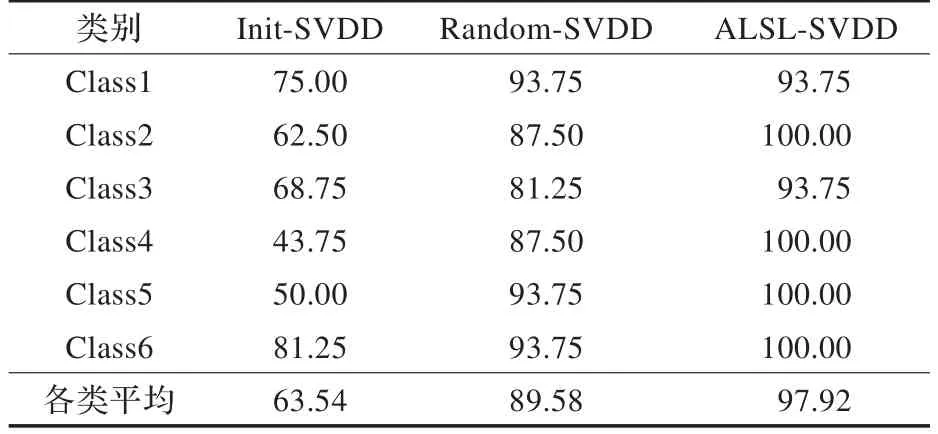
表1 3种算法的识别率比较 (%)
就实验结果的各类平均识别率来看,Random-SVDD和ALSL-SVDD明显优于Init-SVDD,原因是Random-SVDD和ALSL-SVDD在初始的30%的已标注样本集基础上继续从50%的未标注样本集选择样本标注,扩充了训练集。但是Random-SVDD只是随机的选择样本,而ALSL-SVDD是有指导性地选择有价值的样本,因此在识别率达到几乎同等较高水平时,采用ALSL-SVDD所需的标注代价较Random-SVDD相比要低,如图2所示。

图2 两种算法的学习曲线
图2给出了ALSL-SVDD和Random-SVDD两种算法的学习曲线。其中,横轴给出人工标注的样本数目,纵轴给出各类平均分类正确率。从学习曲线图上可看出,整体呈上升趋势,且ALSL-SVDD的上升速度更快,尤其是在样本标注数目较少时。在达到相同的分类正确率(约90%)时,ALSL-SVDD方法比随机采样算法节约了将近1/4的样本标注工作量。
4 结论
本文针对潜艇故障识别中噪声源样本标记代价大的问题,分析了适用于解决小样本分类问题的支持向量数据描述分类模型和样本标注技术,提出了一种基于SVDD的主动学习和自学习方法相结合的分类算法。这种算法以SVDD为基准分类模型,初始训练时仅需少量已标注样本,对于大量未标注样本算法每次从中选择最不确定的样本交给专家标注,同时选择最具有代表性的样本进行自动标注。最后在潜艇机械噪声源数据集上的实验结果表明,该方法可以在不降低识别率的同时有效减少标注代价。本文算法中的参数threshold是在训练前人为指定的,下一步的研究是如何进行无监督参数选择,对ALSL-SVDD算法作进一步的改进。
[1]章林柯,崔立林.潜艇机械噪声源分类识别的小样本研究思想及相关算法评述[J].船舶力学,2011,15(8):940-947.
[2]缪志敏,赵陆文,胡谷雨,等.基于单类分类器的半监督学习[J].模式识别与人工智能,2009,22(6):924-930.
[3]Zhu Xiaojin.Semi-supervised learning literature survey,TR1530[R].University of Wisconsin-Madison,2005.
[4]Hsu D J.Algorithms for active learning[D].Sandiego:University of California,2010.
[5]Settles B.Active learning literature survey,TR1648[R].University of Wisconsin-Madison,2009.
[6]Vapnik V N.The naturn of statistical learning theory[M].New York:Springer-Verlag,1995.
[7]Tax D M J,Duin R P W.Support vector data description[J].Machine Learning,2004,54:45-66.
[8]Vapnik V N.Statistical learning theory[M].Danvers,MA:John Wiley&Sons,2000.
[9]Dasgupta S.Coarse sample complexity bounds for active learning[M]//Advances in Neural Information Processing Systems.Cambridge:MIT Press,2006:235-242.
[10]Muslea I,Minton S,Knoblock C A.Active learning with multiple-views[J].Journal of Artificial Intelligence Research,2006,27:203-233.
[11]吴伟宁,刘扬,郭茂祖,等.基于采样策略的主动学习算法研究进展[J].计算机研究与发展,2012,49(6):1162-1173.
[12]陈荣,曹永锋,孙洪.基于主动学习和半监督学习的多类图像分类[J].自动化学报,2011,37(8):954-962.
