基于网络和标签的混合推荐算法
2015-04-14张新猛蒋盛益张倩生
张新猛,蒋盛益,李 霞,张倩生
广东外语外贸大学 思科信息学院,广州 510006
1 引言
随着Internet的迅速发展,World Wide Web信息呈指数级增长态势,新内容的快速增长带来信息超载问题:过多的信息使用户难以获取个人想要的内容,反而使信息使用效率降低。搜索技术允许人们通过关键字在海量数据中搜索想要的信息,但是没有考虑用户的个性化需求,为所有用户提供了相同的搜索结果。个性化推荐采用知识发现技术根据用户的喜好为用户推荐个性化的信息,是一种解决信息过载的有效工具。目前几乎所有大型的电子商务系统,如Amazon(图书推荐)、CDNOW(音乐推荐)、Netflix(电影推荐)等,都不同程度地使用了各种形式的推荐系统。个性化推荐系统已经给电子商务领域带来巨大的商业利益。据VentureBeat统计,Amazon的推荐系统为其提供了35%的商品销售额[1]。目前,主要的个性化推荐方法有基于规则的推荐、协同过滤推荐(Collaborative Filtering,CF)、基于内容的推荐(Content-Based)、混合推荐系统以及基于网络(Network-Based)的推荐等。
近年来,网络理论成为理解和分析复杂系统有效的工具,节点代表实体,边代表实体之间的联系。二分图是复杂网络中的一种,包含两类节点,只有不同类别的节点之间才有边相连接。周涛首先提出依赖用户与项目之间的网络结构关系的推荐算法[2],并进一步讨论了减少流行项目的初始资源配置,能够进一步提升推荐精度和个性化程度[3]。文献[4]考虑用户与项目的度的相关性,在资源分配模型中引入用户与项目的度乘积的λ指数,λ指数为可调参数[4]。文献[5]等在初始资源分配时同时考虑用户的度及用户的兴趣,以用户选择的项目的平均度定义为用户的兴趣,根据用户的兴趣与项目的度的距离进行初始资源的分配,强化了流行项目的影响,同时弱化了非流行项目的影响。张新猛等[6]考虑了二分图边权,按照边权重比例进行资源分配,高评分项目得到优先推荐,推荐结果个性化程度更高。
随着Web2.0的快速发展,社会化标签系统[7](又称为协同标签系统)已成为Web2.0一种主要应用,它允许用户用随意的单词或短语标记喜爱的资源(URL、电影、图片、音乐等),这些短语和单词就称为Tag,反映了用户的偏好。最近,不少研究将社会化标签应用到推荐系统中[8],文献[9]应用标签系统,构建用户-标签-项目关系,在一定程度上解决了冷启动问题。
不同的推荐算法均存在各自的缺陷,把多种推荐算法进行结合,提出混合推荐算法,具有比独立的推荐算法更好的准确率。Melville等[10]利用基于文本分析的方法在协同过滤系统中用户的打分向量上增加一个附加打分,附加分高的用户的信息优先推荐给其他用户。Yoshii等[11]利用协同过滤算法和音频分析技术进行音乐推荐。本文提出基于网络和标签的混合推荐算法,采用TF-IDF(Term Frequency-Inverse Document Frequency)方法和支持度两种方法构建用户对标签的偏好模型,然后对基于网络推荐算法模型与两种用户偏好模型进行线性组合推荐。在标准数据集MovieLens上进行了测试,实验结果表明,该算法在推荐精度、个性化程度、用户偏好程度等方面均有改进。
2 相关研究
2.1 基于网络的推荐模型
文献[2]首先提出基于二部分图的推荐算法(Network-Based Inference,NBI),用户与项目构成二分图,假设每个项目均有一定的初始资源,通过用户-项目之间的边将资源平均地分配给用户,反过来,每个用户又将自己所有分到的资源再次通过二部分图边平均地分配给它们所参与的项目,得到项目之间的资源推荐关系,然后根据用户已选择的项目对未选择项目进行评分,将评分最高的项目推荐给用户。考虑一个由m个用户n个项目所构成的二部分图,用户集U={U1,U2,…,Um},项目集I={I1,I2,…,In},二部分图表示为G(U,I,E),E表示二部分图的边,即连接用户和项目的边。项目j分配给项目i的资源计算公式为:

其中,ail的值为:

k(Ul)表示用户l的度,即用户l连接到项目的边数。k(Ij)表示项目j的度,即项目j连接到用户的边数。
用户Ui对项目Ij预测评分模型为:

其中项目Ij为用户Ui未选择的项目,1≤j≤n,aji=0。
2.2 基于TF-IDF的项目表征
在基于内容的推荐中,最常用的用户兴趣模型构建方法是TF-IDF[12]。TF-IDF是一种统计方法,用以评估字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。TF表示词条在文档d中出现的频率,IDF表示反文档频率,以总文件数目除以包含该词语文件的数目,再将得到的商取对数得到。
基于内容推荐根据用户已选择的项目,对项目提取关键词,用关键词的TF-IDF值所构成的向量表示用户配置文件,对候选项目同样采用项目关键词的TF-IDF值所构成的向量来表示[12],采用如夹角余弦等方法计算用户与项目的相似度,将相似度最高的项目推荐给用户。该方法通常应用于内容特征较多的文件推荐,比如,Fab是一个网页推荐系统,系统中用一个网页中最重要的100个关键词来表征这个网页。Syskill和Webert系统用128个信息量最多的词表示一个文件。
3 基于网络和标签的混合推荐模型
3.1 基于标签TF-IDF值的用户偏好模型
项目标签不仅可以为每个资源进行更准确的特征描述,同时也能用于构建用户的偏好模型,进而实现更准确的个性化资源推荐[14]。本文以项目的标签作为项目的内容特征,采用用户已选择项目标签的TF-IDF值表示用户的偏好。所有项目的标签构成标签集T={T1,T2,…,Tr},用户Ui选择的项目集合表示为I(Ui)={Ij|1≤j≤n},项目Ij具有标签集合表示为T(Ij)={Tk|1≤k≤r},用户Ui选择的项目所有标签构成偏好标签集T(Ui)={Tk|Tk∈T(Ij),Ij∈I(Ui)} ,以向量 vi=(vi1,vi2,…,vik) 表示用户Ui偏好配置文件,其中每个分量vik是用户Ui已选择标签Tk的TF-IDF值,表示用户Ui对标签Tk的偏好程度,计算公式定义为:

其中tfik为用户Ui选择标签Tk的频率,idfk为标签Tk的反文档频率,tfik计算公式定义为:

nik为用户i所选项目中标签Tk出现的次数,tfik表示用户Ui所选项目中标签Tk出现的频率,显然频率越大,用户对该标签的偏好程度越大。
idfk表示标签Tk在项目中出现的普遍程度,值越小表示该标签越普遍,定义为:

其中n为项目总数,nk为包含标签Tk的项目数量。
可见标签Tk的在某一用户Ui所选项目中出现频率越高,而该标签在项目中出现的频率越低,用户Ui对标签的权重越大,即对该标签的偏好程度越大。
在分类属性聚类算法中,采用对象与簇在各属性上的平均相似度作为对象与簇的相似度[13],本文借鉴此方法,取项目中所有标签对应的用户偏好配置文件中权重平均值作为用户对项目的偏好,用户Ui对项目Ij基于标签TF-IDF的偏好表达式为:

|T(Ij)|表示项目Ij的标签集合T(Ij)的元素个数。
图1为一个用户-项目-标签关系示意图,用户集U={U1,U2},项目集I={I1,I2,I3},标签集T={T1,T2,T3,T4},用户U1的项目集I(U1)={I1,I2},用户U2的项目集I(U2)={I2,I3},项目I1的标签集T(I1)={T1,T3},项目I2的标签集T(I2)={T1,T3,T4},项目I3的标签集T(I3)={T2,T3,T4},用户U1的标签集T(U1)={T1,T3,T4},用户U2的标签集T(U2)={T1,T2,T3,T4} 。 用 户 对 各 标 签 的TF值 分 别 为tf11=2/5,tf13=2/5,tf14=1/5,tf21=1/6,tf22=1/6,tf23=1/3,tf24=1/3,各标签IDF值分别为idf1=ln(3/2+0.01),idf2=ln(3/1+0.01),idf3=ln(3/3+0.01),idf4=ln(3/2+0.01)。用户U1对项目I3的预测偏好值P(U1,I3)=(0+tf13×idf3+tf14×idf4)/3=(2/5×ln1.001+1/5×ln1.501)/3=0.027 208 704。用户U2对项目I1的预测偏好值P(U2,I1)=(tf21×idf1+tf23×idf3)/2=(1/6×ln 1.501+1/3×ln1.01)/2=0.035 502 685。
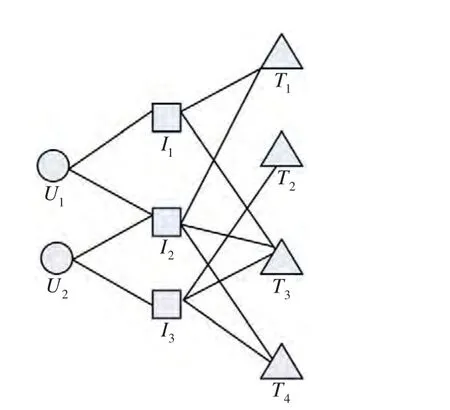
图1 用户-项目-标签
3.2 基于标签支持度的用户偏好模型
用户对标签TF值或TFIDF值越大表示对该标签的偏好程度越大,但对于一些非主流项目,该类项目总数量比较少,即使用户对此类项目偏好程度很高,用户选择此类项目的比例仍然很低,因此虽然该项目的IDF值较高,由于其TF值低,无法获得较高的TFIDF值。CBUID算法[15]通过计算对象分类属性值在簇中的出现的频率计算对象与簇之间的相似度,计算方法为该属性值在簇中出现的次数除以簇的对象个数。受此启发,将用户选择包含该标签的项目个数与该类项目总数的比值作为用户对该标签的偏好的一种度量,这里称为用户对该标签支持度。显然,比值越大,用户对该类标签的兴趣越大,该度量方式更注重用户的偏好,可以将更多非主流项目推荐给用户。用户Ui对标签Tk的支持度表达式为:

nik为用户Ui选择项目中包含该标签Tk的项目数目,Nk为具有标签Tk的项目总数目,支持度Sik表示用户Ui选择具有标签Tk的项目数占该类别项目总数的比值,若用户选择了所有具有某类标签的项目,达到最大值1,若用户没有选择任何具有该标签的项目,达到最小值0,显然该值的范围为[0,1],比值越大,表示该用户对该类别项目偏好程度越大。
如项目总数为1 000,用户选择的总项目数为300,选择A类项目的数量为10,A类项目的总数为20,选择B类项目的数量为20,B类项目的总数为100,经过计算用户对两类项目的TFIDF值是相同的,而A类项目支持度为10/20=0.5,B类项目支持度为20/100=0.2,而实际应用中,B类项目比较流行,用户可以很方便地获取,而A类项目,用户却难以发现,因此推荐给用户A类项目,更能获得用户喜爱。
一个项目包含多个标签,参照文献[15],取用户对项目中包含的标签的支持度的平均值作为用户对项目的支持度,用户Ui对项目Ij的支持度表示为:

|T(Ij)|为项目Ij包含的标签个数,用户Ui对项目Ij的支持度取项目包含标签的支持度的平均值。如图1,N1=2,N2=1,N3=3,N4=2,n11=1,n12=0,n13=2,n14=1,n21=1,n22=1,n23=2,n24=2。SUP(U1,I3)=(0+2/3+1/2)/3=7/18 ,SUP(U2,I1)=(0+1/2+2/3)/2=7/12 。
3.3 基于网络和标签混合推荐模型
推荐算法混合的形式有多种,可以是串行方式,首先用一种推荐技术产生一个较为粗略的候选结果,在此基础上使用第二种推荐技术进一步精确地推荐,也可以将多种推荐技术的计算结果加权混合产生推荐。采用串行方式,需要分别运行推荐算法,时间复杂度为两种推荐算法的复杂度和,而加权混合方式,多种推荐算法可在相同的遍历中同时进行运算,时间开销较小。本文算法采用加权混合方式,在基于网络的评分基础上,增加两种用户偏好值的附加分量。用户U i对项目Ij的预测评分表达式为:

其中权重x1+x2+x3=1,其值由各模型的精确性及经验值得出。本文通过改变公式(9)中的x1、x2、x3的值在数据集MovieLens上进行测试,在三者的比值为1∶1∶1时,取得较好的推荐效果,本文测试结果均在此权重组合下得到的,但并不代表三种模型在推荐中的作用相同。事实上,本混合推荐算法中以基于网络的推荐为主,另外两种用户偏好值在数据集MovieLens上运行结果都要小于基于网络推荐的评分,相当于在基于网络推荐评分上增加一个附加分。本文在实验中针对公式(10)分别统计了所有用户项目预测中F(Ui,Ij),SUP(Ui,Ij),P(Ui,Ij)各项的平均值,三种模型平均值的比值约为50∶33∶17,即在最后对项目的预测分数中三种模型预测结果所占比重,表示了事实上三种模型的重要程度,比重越大,重要程度越高。
4 算法描述
算法主要有三个步骤:第一步统计用户及项目的相关统计信息,构建基于TF-IDF和支持度的偏好模型;第二步计算项目间资源分配矩阵;第三步根据基于网络和标签的混合推荐模型为某用户计算未选择项目的预测评分。
第一步构建用户基于标签的偏好模型。
输入:用户集U,项目集I,训练集T
输出:用户偏好配置文件,用户标签支持度SUP(Ui,Tk)(1)ForeachtinT
(2)统计每个用户Ul的度,记为k(Ul)
(3)统计每个项目Ii的度,记为k(Ii)
(4)得到每个项目Ii所连接用户集合,记为U(Ii)
(5)统计用户Ul选择标签Tk的次数nlk
(6)统计标签Tk被选择总次数Nk
(7)Endfor
(8)计算用户各标签的TF-IDF值,得到用户偏好配置文件
(9)计算用户对各标签的支持度SUP(Ul,Tk)
第二步计算项目间资源分配矩阵。
输入:用户集U,项目集I,训练集T
输出:资源分配矩阵W=(wij)n×n
(10)ForeachIiinI
(11)ForeachIjinI
(12)wij=0
(13) ForeachUlinU(Ii)∩U(Ij)
(14)wij=wij+ail×ajl/k(Ul)
(15) Endfor
(16)wij=wij/k(Ij)
(17)Endfor
(18)Endfor
第三步为某个用户计算所有未选择项目预测评分。
输入:用户Ul,项目集I,资源分配矩阵W=(wij)n×n
输出:用户Ul对未选择项目的评分集合
(19)ForeachIiinI
(20)F(Ul,Ii)=0
(21)ForeachIjinI(Ul)
(22)F(Ul,Ii)=F(Ul,Ii)+wij×alj
(23)Endfor
(24)ForeachTkinT(Ii)
(25)P(Ul,Ii)=P(Ul,Ii)+vlk
(26)SUP(Ul,Ii)=SUP(Ul,Ii)+Slk
(27)Endfor
(28)P(Ul,Ii)=P(Ul,Ii)/|T(Ii)|
(29)SUP(Ul,Ii)=SUP(Ul,Ii)/|T(Ii)|
(30)score(Ul,Ii)=x1F(Ul,Ii)+x2SUP(Ul,Ii)+x3P(Ul,Ii)
(31)Endfor
|I|表示集合I的长度;最后再取评分最高top-N个项目推荐给用户Ul。
从算法流程中可以看出,两种用户对标签的偏好模型的构建都穿插在NBI算法流程中,主要增加的行有5~6及24~29,并没有过多额外的时间开销。
5 实验分析
5.1 实验数据
采用标准数据集MovieLens(http://www.grouplens.org)检测算法的有效性。MovieLens数据集包含1 682部电影,943个用户,共有100 000条用户对电影的评分。评分在1~5之间,1表示最不喜欢,5表示最喜欢,其中评分在3分及以上的记录有82 520条,如果评分至少3分表示用户推荐该电影,将3分及以上的评分记录构建“用户-电影”二部分图,那么“用户-电影”二部分图共有82 520条边。为了便于对比实验,按照文献[2]中方法将数据集随机选取其中90%作为训练集,剩余10%作为测试集。本文实验每次随机划分数据集后,分别用NBI和本文算法进行评分预测,进行10次取平均值比较推荐结果,因此实验结果是在训练集与测试集都完全相同的情况下进行的对比测试。
个性化推荐结果的评价通常从精确度和个性化程度进行评价[3],本文通过推荐精度和召回率验证推荐精确度,利用命中项目平均度及多样性验证推荐的个性化程度。给定了推荐列表的长度L,系统把排名最靠前的L个项目推荐给用户,观察所推荐的L个项目,假设二部图边Ui-Ij出现在测试集中,如果Ij为所推荐的L个项目之一,那么称项目Ij被算法命中。本文分别在给定推荐列表长度L为5、10、20、50、100的情况下,对算法进行了实验和讨论。
5.2 推荐精度
推荐精度和召回率是评价推荐结果精确度的两个度量值,精度是推荐结果中命中项目数量与推荐项目总数的比值,召回率是推荐结果命中项目数量与测试集中用户实际选择的项目数量的比值。
召回率计算公式为:

精度计算公式为:

L为推荐长度,本文采用Nr/(Lmt)算平均精度,即命中项目的总数与总推荐数的比值。
表1为文本算法与NBI算法在不同推荐长度下,各种算法组合情况下命中项目总数、精度及召回率,其中NBIT、NBIS、NBITS分别表示NBI与标签支持度组合、NBI与TF-IDF组合、NBI与标签支持度及TF-IDF组合。从表1中可知,NBITS算法效果最好,NBIT及NBIS也均优于NBI算法。
5.3 个性化程度
除了测量推荐结果精度,推荐结果的个性化程度也是评价推荐效果的一个有意义的指标,比如推荐给用户10部电影,其中8部是非常流行的,而另外2部是适合用户偏好的,流行的电影通常可以在更多的场所得到推荐(比如电视、网络、电影院等),而符合用户偏好的非流行电影却难以被用户发现,因此这2部非流行的电影对用户的意义更大。为测试推荐结果个性化程度,分别采用推荐项目流行度和多样化两种方法进行测量。
项目流行度以推荐项目的平均度来测量,项目的度为项目被用户选择的次数,度越大,说明项目越流行,将流行项目推荐给用户,虽然能得到用户认可,推荐命中率提高,但推荐结果个性化程度较低。给定推荐长度为L,所有被推荐项目的平均度
推荐结果多样性指为不同用户推荐结果差异程度,采用用户间推荐项目列表的汉明距离评定推荐结果多样性,设用户Ui与Uj推荐项目列表重叠项目的数量Q、L为推荐项目个数,其汉明距离为Hij=1-Q/L。通常来讲,汉明距离越大推荐结果个性化程度越高,计算所有用户之间的汉明距离并取平均值作为评价推荐结果个性化的强度,记为S=<Hij>,若为所有用户推荐相同的项目,S=0,若所有用户推荐项目列表没有相同的项目,则S=1。图2是本文算法和基于网络的推荐算法NBI在不同推荐列表长度情况下的命中项目平均度,显然NBITS的平均度较小,表明更考虑了用户的偏好,而不是将最流行的项目推荐给用户。图3是各算法在不同推荐长度下用户间平均汉明距离,NBITS算法汉明距离较大,表明NBITS算法为不同用户推荐了更多不同的项目。NBIT命中项目平均度低于NBIS,且NBIT命中项目汉明距离高于NBIS,说明TF-IDF方法对提高个性化程度更明显。
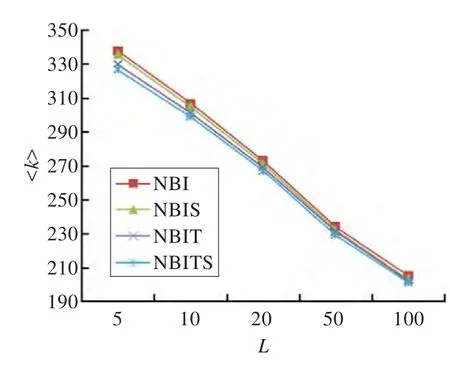
图2 典型推荐长度下命中项目平均度

表1 典型推荐列表长度的命中项目总数、精度及召回率
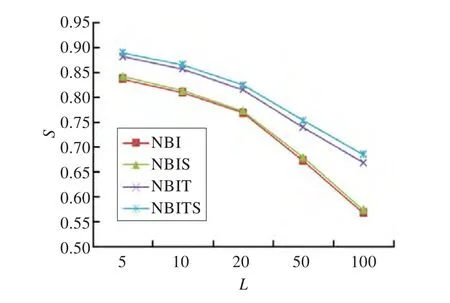
图3 典型推荐长度下推荐项目用户间平均汉明距离
6 结束语
NBI算法根据用户-项目二分图结构计算项目之间的推荐程度,根据用户已选择项目计算未选择项目的推荐程度获取推荐列表,核心思想采用了项目与项目之间的关系。而本文算法在NBI算法的基础上,根据用户选择项目的标签信息,分别采用TF-IDF和标签支持度的方法构建用户偏好模型,根据待预测项目的标签计算用户对项目的偏好程度,并与NBI推荐模型进行线性组合推荐。经过在数据集上测试证明,在推荐精度、个性化程度等方面均比单纯的基于网络的推荐均有所改进。但本文对各模型的加权组合方法尚待进一步探讨,各模型权重需要一种更为科学的方法确定,同时本文算法需要进一步在更多数据集,尤其大数据集上进行测试验证。
[1]刘建国,周涛,汪秉宏.个性化推荐系统的研究进展[J].自然科学进展,2009,19(1):1-15.
[2]Zhou Tao,Ren Jie,Medo M,et al.Bipartite network projection and personal recommendation[J].Physical Review E,2007,76(4):6116-6123.
[3]Zhou Tao,Jiang Luoluo,Su Riqi,et al.Effect of initial configuration on network-based recommendation[J].Europhys Lett,2008,81(5):8004-8008.
[4]Pan Xin,Deng Guishi,Liu Jianguo.Weighted bipartite network and personalized recommendation[J].Physics Procedia,2010,3(5):1867-1876.
[5]Liu Jianguo,Zhou Tao,Wang Binghong,et al.Effects of user tastes on personalized recommendation[J].International Journal of Modern Physics C,2009,20(12):1925-1932.
[6]张新猛,蒋盛益.基于加权二部图的个性化推荐算法[J].计算机应用,2012,32(3):654-657.
[7]Scott A G,Bernardo A H.Usage patterns of collaborative tagging systems[J].Journal of Information Science,2006,32(2):198-208.
[8]Zhang Zike,Zhou Tao,Zhang Yicheng.Tag-aware recommendersystems:a state-of-the-artsurvey[J].Journalof Computer Science and Technology,2011,26(5):767-777.
[9]Zhang Zike,Liu Chuang,Zhang Yichen,et al.Solving the cold-start problem in recommender systems with social tags[J].Europhysics Letters,2010,92(2):8002-8008.
[10]Melville P,Mooney R J,Nagarajan R.Content-boosted collaborative filtering for improved recommendations[C]//Proceedings of the 18th National Conference on Artificial Intelligence,Edmonton,2002:187-192.
[11]Yoshii K,Goto M,Komatani K,et al.An efficient hybrid music recommender system using an incrementally trainable probabilistic generative model[J].IEEE Transactions on Audio Speech and Language Processing,2008,16(2):435-447.
[12]王国霞,刘贺平.个性化推荐系统综述[J].计算机工程与应用,2012,48(7):70-80.
[13]Pazzani M J,Billsus D.Content-based recommendation systems[M]//The Adaptive Web:Methods and Strategies of Web Personalization.Berlin,Heidelberg:Springer-Verlag,2007:325-341.
[14]刘斌,杨帆.支持多维标签云的移动餐厅推荐系统仿真研究[J].计算机工程与应用,2012,48(4):240-243.
[15]Jiang Shengyi,Song Xiaoyu,Wang Hui,et al.A clusteringbased method for unsupervised intrusion detections[J].Pattern Recognition Letters,2006,27(7):802-810.
