一种基于本体和用户日志的查询扩展方法
2015-04-14欧阳柳波谭睿哲
欧阳柳波,谭睿哲
湖南大学 信息科学与工程学院,长沙 410082
1 引言
随着Web技术的不断发展,互联网已成为人们获取信息的主要手段,搜索引擎也在人门的日常生活中扮演越来越重要的角色。现有的搜索引擎和信息检索系统多采用基于关键词的匹配方式进行全文检索,将包含检索关键词的文档作为查询结果返回。但是,由于人们对现实生活中相同对象的描述用词存在着多样性,两个人使用同样的关键词描述同一对象的概率小于20%,因此导致基于关键词机械式符号匹配的检索过程中很大一部分相关文档不能被检索到。
另一方面,用户输入的初始查询词往往较短。研究者对搜狗搜索引擎上的用户查询做了分析,结果表明,长度不超过3个词的查询占了总查询数的93.15%,平均长度为1.85个词[1],在当前的搜索引擎的使用过程中,这个问题变得更加尖锐。较短的查询输入往往不能完整地表达用户的查询意图,因此基于关键词的检索会返回大量无关的结果。
查询扩展是解决用户检索关键词不能准确描述用户意图的有效手段,它利用计算机语言学、信息学等多种技术,在用户查询的基础上通过一定的方法和策略把与查询相关的词、词组添加到查询中,组成新的、更能准确表达用户查询意图的查询词序列,然后用新查询对文档重新检索,从而改善信息检索中的查全率和查准率低下的问题。
目前查询扩展技术按照其扩展词的来源不同主要有全局分析、局部分析和基于关联规则的查询扩展技术等几种[2]。基于全局分析的方法是最早产生的查询扩展方法,该方法对整个文档集的语词进行相关分析(如语词共现分析),计算每对语词间的关联程度(如共现率),构造叙词表,再从叙词表中选取与原查询关联程度较高的词作为扩展词进行扩展。常用的基于全局分析的方法有全局聚类技术、相似性叙词表、潜在语义索引等[3-4]。这类方法的优势是可以最大限度地寻找词及词组之间的关系进行查询扩展,不足之处在于计算开销很大,不适用于海量数据检索。基于局部分析的方法较好地解决了全局分析方法计算开销大的缺陷,该方法利用初检返回的前N篇文档作为扩展词的来源,从中选取与原查询相关的语词进行查询扩展。典型的有局部聚类技术、用户相关反馈技术和局部上下文分析技术[5-6]。这类方法的不足之处在于它的有效性过于依赖第一次检索的结果,当初次检索结果与原始查询相关度不高时,查准率会严重降低。基于关联规则的查询扩展方法的主要思想是通过数据挖掘技术挖掘词间关联规则,将关联规则的后件结论部分作为扩展词的来源。
以上查询扩展技术虽然在一定程度上弥补了用户查询信息的不足,但仍存在两个主要问题:其一,这些查询扩展方法都是基于对文档关键词的分析,忽略了查询概念间的语义关联,因而不能从根本上消除用户查询意图与检索结果之间的语义偏差和用户查询的歧义性问题;其二,对于查询扩展中易出现的大量查询无关词加入扩展集合,使查询扩展后的主旨偏离用户的原始检索意图从而产生“查询漂移”问题,这些方法并没有有效的应对措施。
2 相关概念
2.1 本体
最早给出本体定义的是Neches等人,他们将本体定义为“给出构成相关领域词汇的基本术语和关系,以及利用这些术语和关系构成的规定这些词汇外延的规则的定义”。本体的目标是捕获相关领域的知识,提供对该领域知识的共同理解,确定该领域内共同认可的词汇,并从不同层次的形式化模式上给出这些词汇(术语)和词汇间相互关系的明确定义。领域本体是本体中的一种,它描述的是领域内知识,包括概念、属性、关系、实例和其他元素。领域本体可以用于分析特定领域的类,关系和它们所满足的约束条件,可以有效解决知识的重用和共享[7]。
借助领域本体库把用户的原始查询映射成本体中的元素后,使用本体的语义信息及语义推理机制可实现对用户查询的语义层次扩展。
2.2 用户查询日志
用户查询日志记录了用户与系统交互的相关信息,是用户使用检索系统时多次“回馈”结果的积累,被点击次数高的网页相关性好,未点击的网页与查询无关。国内外的不少研究者都针对网络搜索引擎的用户日志进行了相关的研究,对它的分析相当于使用大量用户的相关回馈,可以收集到查询词、返回顺序、点击顺序、网页URL等用户行为信息,对查询词扩展更具普遍性和统计意义[8-10]。
3 查询扩展方法分析
3.1 基本思想
针对传统查询扩展方法存在的缺陷,本文结合本体和用户查询日志,提出一种查询扩展方法。该方法借助领域本体知识库的语义关系和推理规则对用户原始查询进行初始语义扩展,利用本体概念间的语义关联获取检索词的同义词、上位词、下位词,语义蕴涵等形成候选扩展概念集,计算扩展概念集中扩展词与检索词的语义相似度筛选出初始扩展概念集。鉴于初始扩展容易加入查询无关词而产生“查询漂移”问题,本文结合用户查询日志信息对初始扩展概念集进行二次筛选。通过计算查询词与初始扩展概念集中扩展词间的共现度权值,筛选出最终扩展概念集。
3.2 基于本体的语义扩展
3.2.1 本体间语义相似度的计算
语义相似度是指两个概念在语义层次上的相似程度,其取值一般在[0,1]之间。在领域本体中,基于本体层次树结构的语义相似度计算需综合考虑以下几个要素:
(1)语义距离
本体层次树结构决定了利用两个概念在树中的最短路径距离来表示它们的语义距离是一种自然的度量方法。两个概念的语义距离越大,其相似度越低;反之,其相似度越高[11]。
(2)语义重合度
语义重合度是指本体内部两概念结点之间包含相同的上位概念结点在总结点中所占比例。语义重合度表明了两个概念间的相同程度,在实际计算中,可以转化为公共结点的个数除以总结点个数。
(3)结点所处层次深度和层次
在本体层次树中自顶向下,概念的分类是由大到小,大类间的概念相似度一般要小于小类间的相似度,因为概念所处的层次越低,其分类越细。因此,在其他因素相同的情况下,处于层次树中离根结点较远的概念结点间的语义相似度要比离根结点近的概念间语义相似度大,而且处于同一层次的概念语义相似度大于不同层次的概念语义相似度,即层次差越大的两个概念间语义相似度越小。
定义1设X、Y是本体层次树中的任意两个结点,用Dist(X,Y)表示从X到Y所经过的路径长度,即X、Y之间的语义距离。
定义2设本体层次树的根为R,Anc(X)是从X出发,向上直到根R所经过的结点集合,|Anc(X)|表示结点集个数;用Anc(X)∩Anc(Y)表示从X和Y到R共同经过的结点集合;Anc(X)∪Anc(Y)表示从X到R经过的结点集和从Y到R经过的结点集的并集,则概念X,Y之间的语义重合度表示为:
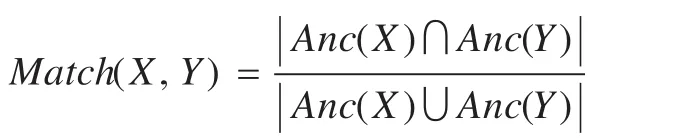
定义3设Depth(X)表示结点X在层次树中的深度,Depth(Y)表示结点Y在层次树中的深度,|Depth(X)-Depth(Y)|表示结点X和结点Y的层次差,记层次树的深度为MaxDepth(MaxDepth=Max((Depth(v)),v表示层次树中的任意结点)。
根据以上三个定义,提出领域本体中计算两个概念X、Y之间语义相似度的计算公式:
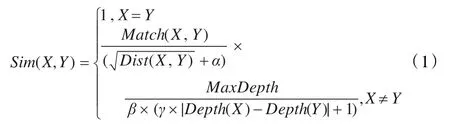
其中,α是一个可调节的参数,α的值反映了语义距离与语义相似度的关系,取值为正实数;β是一个可调节的参数,β用于调节语义重合度的值对相似度的影响,β的取值范围为(MaxDepth-1 ,MaxDepth],引入β主要是因为当本体树深度值较小时,语义重合度对相似度的影响过大,所以加入β来做调节,因为本体树中语义重合度最大的两个概念是本体树中最大层次上结点和其父结点,β的这个取值范围可以保证在X≠Y的情况下Sim(X,Y) < 1;γ是一个可调节的参数,γ用于调节概念层次差对相似度的影响,γ的取值范围一般在(0,1)之间。
3.2.2 初始扩展词的选择
为避免基于本体扩展后的候选扩展概念集中加入过多查询无关词影响扩展精度,引入参数λ1控制扩展的范围。定义用户的初始查询为S,S经分词和去掉停用词后可表示为K={k1,k2,…,kn}。设查询词ki的初始权重为1,ki借助领域本体知识库进行语义扩展生成候选扩展概念集Q。对Q中的每个扩展查询词qj,根据公式(1)计算其与ki的语义相似度值Sim(ki,qj) ,并将结果与给定的阈值λ1(λ1的值由实验得到)比较;最后,将Q中Sim(ki,qj)>λ1的扩展词保留形成初始扩展概念集。
3.3 基于用户查询日志的扩展词二次筛选
3.3.1 基于用户日志的词共现计算
共现描述的是有相互关联的事物在相同时间或地点一起发生或出现的情形。可见,事物的相互联系是共现发生的内在原因,而共现现像是事物相互联系的外在表现。所以,通过分析共现现象可以了解事物之间的联系强弱和关联类型。所谓共现词,是指在文档中经常同时出现的词项,以一个词为中心,伴随着一组经常与之搭配出现的词,把这组词称为它的共现词汇集,该集合描述了该词的语义上下文或语境[12-13]。
用户查询日志是搜索引擎记录用户行为的重要载体,用户点击行为在统计意义上表明“用户认为点击对象与查询相关”[14]。通过计算原始查询词与查询扩展词在用户点击文档集中的共现频度和共文档率,可以有效分析出查询词与扩展词在用户点击文档集中的关联强弱,从而将用户反馈加入到查询扩展中避免“查询漂移”问题的出现。
定义4在日志中,针对用户的一个查询词ki,记录用户所点击的文档集合称为点击文档集D,|D|表示集合D中元素个数 (|D| =n,ds∈D,s∈[1,n]);查询词ki根据本体初始扩展形成的初始扩展概念集合记为Q(|Q|=m,qj∈Q,j∈ [1,m]);点击文档集D中包含的词项集合称为词项集T,|T|表示集合T中元素个数。
定义5对于初始扩展概念集中的任意扩展词∀qj∈Q,qj在文档ds中出现的频度记为f(qj,ds),称为qj在ds中的词频,如未出现则f(qj,ds)=0。qj与查询词ki在ds中的共现频度表示为f(qj,ds)·f(ki,ds)。
定义6设|Dqj|表示文档集D中包含qj的文档的个数,则查询词ki与扩展词qj的共文档率可用|Dqj|与|D|的比值来表示。共现文档率体现的是语词在整个文档集合中的关系。此外,在用户日志记录中,用户点击某文档的顺序越靠前,表示用户对网页的认同度越大,可以认为该文档中包含的词项跟用户的初始查询词越相关,用Ord(ki,ds)表示文档ds在查询词ki点击记录中的顺序值。
综合定义4到6,提出扩展词qj在查询词ki点击文档集中的共现度权值计算公式:
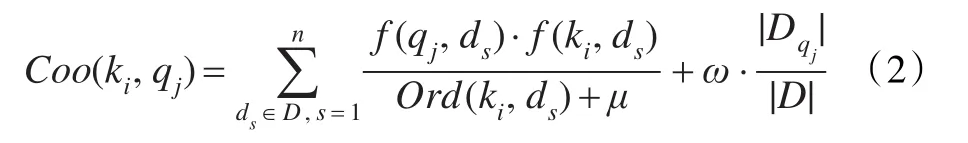
其中,μ是一个可调节的参数,用于调节用户点击顺序对共现词频的影响,取值为正实数,引入μ是为了避免用户点击顺序值过小时,其对共现度权值影响过大;ω用于调节共文档率在共现度权值中所占比重。
3.3.2 基于用户查询日志的扩展词二次筛选
为避免初始扩展出现“查询漂移”问题,引入参数λ2对初始扩展概念集中的扩展词进行二次筛选。利用公式(2)计算初始扩展概念集Q中的每个扩展词qj与原始查询词ki在用户点击文档集中的共现度权值,并与扩展词qj的语义相似度权值累加作为其总权重E(ki,qj) :
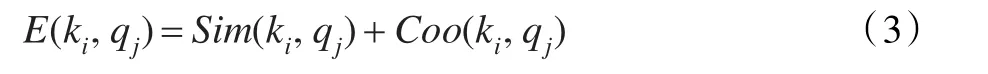
最后,将E(ki,qj)<λ2(λ2的值由实验得到)的扩展词从初始扩展概念集中删除形成最终扩展概念集,并以扩展词的总权重作为其在最终扩展概念集中的排序依据。
4 查询扩展算法
基于本体和用户日志的查询扩展算法使用本体进行语义层面上的扩展,采用直接映射的方式将用户查询映射为本体中的概念、实例或属性。具体的查询扩展算法描述如下:
步骤1用户输入查询请求,系统经过分词、去掉停用词后,正确抽取出用户查询中的词组作为初始查询概念集K(K={k1,k2,…,kn})。
步骤2从K中取出一个未处理的初始检索词ki,设置ki的权重为1并标记为已处理。
步骤3检查初始检索词ki是不是领域本体中的概念、实例或属性,如果是,跳转到步骤4;否则跳转到步骤2。
步骤4使用本体的语义关系和推理规则获取检索词ki的同义词、上位词、下位词、语义蕴涵等形成候选扩展概念集Q(Q= {q1,q2,…,qn})。使用公式(1)计算Q中的每个扩展词qj与检索词ki的语义相似度值Sim(ki,qj) ,根据计算结果,将Q中语义相似度值大于给定阀值λ1的扩展词保留,并用语义相似度值作为qj的权重放入Q,此时的Q为初始扩展概念集。
步骤5在用户查询日志的基础上,使用公式(2)对初始扩展概念集Q中的每个扩展词qj计算其与检索词ki在用户点击文档集中的共现度权值Coo(ki,qj) ,并由公式(3)得出扩展词qj的扩展总权重E(ki,qj) ,从Q中删去E(ki,qj)<λ2的扩展词形成最终扩展概念集。
步骤6检查是否存在未处理的检索词,如果有,跳转到步骤2;否则跳转到步骤7。
步骤7将最终扩展概念集中的检索词与扩展词按其权重排序。
步骤8输出最终扩展概念集,算法结束。
5 实验结果与分析
5.1 体系结构
基于本体和用户日志的查询系统原型框架如图1所示。
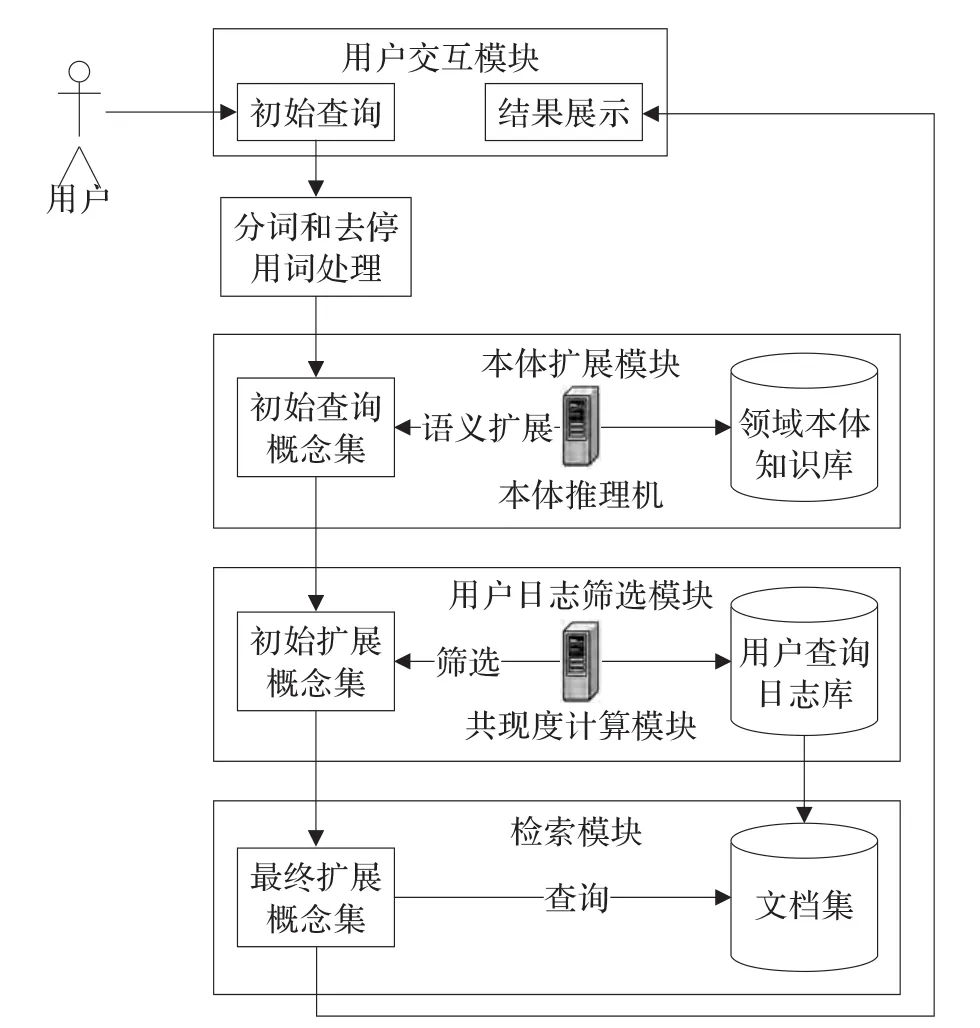
图1 基于本体和用户日志的查询系统原型框架
该原型主要由4个模块组成:用户交互模块、本体扩展模块、用户日志筛选模块和检索模块。各个模块的功能描述如下:
(1)用户交互模块包含用户查询界面和用户查询结果展示界面,是用户使用系统的唯一接口。
(2)本体扩展模块由领域本体知识库和本体推理机构成。其中,领域本体知识库中的本体使用OWL DL语言描述。本体推理机使用惠普实验室提供的开源工具Jena作为推理引擎,推理机通过领域本体知识库对用户原始查询进行语义扩展,并对扩展词计算语义相似度,选取相似度值超过阀值的扩展词形成初始扩展概念集。
(3)用户日志筛选模块由用户查询日志库和共现度计算模块构成,共现度计算模块利用用户查询日志通过局部共现分析法计算初始扩展概念集中扩展词与原始查询词在用户点击文档集中的共现度权值。最后,结合初始扩展词的语义相似度值和共现度权值筛选出最终扩展词形成最终扩展概念集。
(4)检索模块的功能是使用最终扩展概念集对文档集进行检索并将结果返回给用户。该模块利用Lucene开源工具包对文档集建立基于倒排序索引结构的索引库。检索模块检索时将直接从索引库通过关键词匹配找到满足条件的文档,从而避免了扫描文档集中的每一篇文档,大大加快了检索速度。最后,对得到的相关文档根据检索词权重降序排序,取前k个文档提交给用户。
5.2 实验数据准备
本文实验的目的是验证使用基于本体和用户日志的查询扩展方法后,相比于传统查询扩展方法,在检索性能和鲁棒性上是否有提升和改善。
为此,在系统原型上构建了一个关于计算机软硬件的领域本体知识库,从搜狗用户日志中抽取了有关计算机软硬件领域的200个关键词查询日志作为实验日志存入用户查询日志库,并对其中用户点击的网页进行了文字内容下载,去除了失效网页和长度过短的网页,最后得到的网页文档集合包括5 000个网页作为测试文档集。
实验选取了基于局部共现的查询扩展方法和基于本体的查询扩展方法作为对比方法;采用prec@30作为检索性能评测指标。prec@X指的是针对某个查询,在检索出X篇文档时的准确率。prec@30在搜索引擎中通常反映了前两页检索结果的准确率。
5.3 实验结果
根据实验需要,首先对查询扩展方法的鲁棒性进行评估。查询扩展是对原查询的优化,其扩展词数量会影响到检索的查准率。因此,扩展词数量对检索性能的影响是检验扩展方法鲁棒性的重要依据。图2给出了扩展词规模对三种查询扩展方法的检索性能影响的变化曲线。
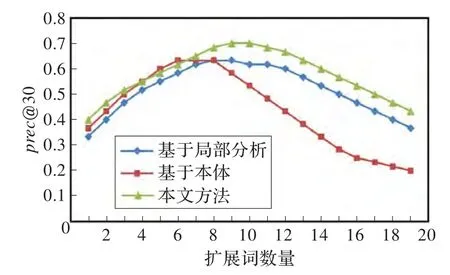
图2 扩展词规模对三种查询扩展方法的影响
从图2中可以看出扩展词规模对基于本体的查询扩展方法具有较大的影响,当扩展词数目N>20时,随着N的增大,检索性能下降的幅度较大,从而产生了“查询漂移”问题;相比而言,基于局部共现的查询扩展方法和本文方法受扩展词规模的影响并不明显,其鲁棒性要远远好于基于本体的查询扩展方法。从图中可以看出,当扩展词数量控制在15~25个时,本文方法检索准确率处于最高。为此,实验设置有效性阀值为λ1=0.5,λ2=0.7,将扩展词数量控制在此范围之内。
接下来对查询扩展方法的检索性能进行测试。对所搜集的文档集采取以上三种方法通过随机构造10次不同的查询语句进行查询,检索性能对比结果如图3所示。
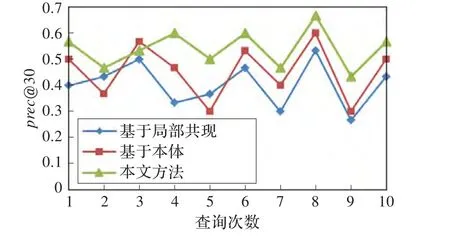
图3 三种查询扩展方法的检索性能对比
从图3可以看出,在这三种查询扩展方法中,后两种查询扩展方法相比于基于局部共现的查询扩展方法检索性能有较大提高。主要原因是基于局部共现的查询扩展方法依然是以查询词为中心进行机械式的扩展,忽略了查询概念间的语义关联,只能检索出部分相关文档,所以导致检索性能较低。在后两种语义查询扩展方法中,本文方法在检索性能上高于基于本体的查询扩展方法,原因是本文方法利用基于用户查询日志的词共现分析算法对本体扩展形成的扩展集进行了二次筛选,缩小了扩展范围,使扩展后的查询与初始查询的真实意图更加相关。
由以上实验结果可知,本文基于本体和用户日志的查询扩展方法较传统查询扩展方法不仅在检索性能上有了明显进步,同时可以避免在扩展词数量增多时出现的“查询漂移”问题,具有良好的鲁棒性。
6 结束语
针对传统查询扩展的缺陷,提出一种基于本体和用户查询日志的查询扩展方法,从语义层次上实现了查询扩展,并对扩展词进行二次筛选。实验结果表明,本文查询扩展方法能有效扩展用户查询,大大提高检索准确率。但本文方法的初始扩展对领域本体库依赖性较强,若用户查询无法直接映射到领域本体,则扩展性能较差。下一步的工作重点是解决用户查询无法映射到领域本体时如何调整查询扩展策略。
[1]余慧佳,刘奕群,张敏,等.基于大规模日志分析的搜索引擎用户行为分析[J].中文信息学报,2007,21(1):109-114.
[2]黄名选,严小卫,张师超.查询扩展技术进展和展望[J].计算机应用与软件,2007,24(11):1-5.
[3]Luan Lihua,Ji Genlin.Fast clustering algorithm based on quad-tree[J].Computer Applications,2005,25(5):1001-1003.
[4]Dai Jiahong.Fuzzy cluster-based query expansion[D].Taiwan,China:National Sun Yat-sen University,2004.
[5]Chang Y,Ounis I,Kim M.Query reformulation using automatically generated query concepts from a document space[J].Information Processing and Management,2006,42(2):453-468.
[6]张超盟,李战怀,温宗臣.局部上下文分析剪枝概念树的查询扩展[J].计算机工程,2009,35(14):45-48.
[7]Avigdor G,Giovanni M,Hasan J.OntoBuilder:fully automatic extraction and consolidation of ontologies from Web sources[C]//Proc of the ICDE 2004.Boston:IEEE Computer Society,2004.
[8]朱鲲鹏,魏芳.基于用户日志挖掘的查询扩展方法[J].计算机应用与软件,2012,29(6):113-116.
[9]崔航,文继荣,李敏强.基于用户日志的查询扩展统计模型[J].软件学报,2003,14(9):1593-1599.
[10]Wen J R,Nie J Y,Zhang H J.Query clustering using user logs[J].ACM Transactions on Information Systems,2002,20(1):59-81.
[11]王栋,吴军华.自动更新的本体概念语义相似度计算[J].计算机工程与设计,2009,30(19):4419-4421.
[12]Peat H J,Peter W.The limitations of term co-occurrence data for query expansion in document retrieval systems[J].Journal of the American Society for Information Science,1991,42(5):378-383.
[13]陈钟,彭波,月宏飞,等.一种词汇共现算法及共现词对检索系统排序的影响[J].清华大学学报,2005,45(S1):1857-1860.
[14]Zhang Z,Nasraoui O.Mining search engine query logs for query recommendation[C]//Proceedings of the 15th International World Wide Web Conference,2006:1039-1040.
