一种新特征评价方法在红斑鳞状皮肤病诊断中的应用
2012-11-27谢娟英雷金虎谢维信
谢娟英 雷金虎 谢维信
1(陕西师范大学计算机科学学院,西安 710062)
2(西安电子科技大学电子工程学院,西安 710071)
3(深圳大学信息工程学院,ATR国家重点实验室,深圳 518060)
引言
红斑鳞状皮肤病的鉴别诊断是皮肤病科的一个难题[1]。该类疾病包括牛皮癣、脂溢性皮炎、扁平苔藓、玫瑰糠疹、克罗尼克皮炎、毛发红糠疹六个类群。这些疾病是皮肤病诊断中常见的几种疾病,有许多共同的病理特点,共享很多难以区分的临床特征,一种疾病初期经常呈现另一种疾病的特点,然后才显示该种疾病的特点[2]。一般患者最初只有12个特征作为临床诊断特征,进一步的诊断增加了在显微镜下分析得到的22个病征特征[1]。
近年来国内外诸多机器学习领域的学者关注于红斑鳞状皮肤病的诊断研究,并取得了诸多研究成果。Übeyli和Güler于2005年提出了一种自适应模糊神经网络系统来进行红斑鳞状皮肤病的诊断,达到了 95.5% 的分类准确率[3]。2006年,Luukka和Leppälampi使用模糊相似分类器进行该皮肤病的诊断研究,取得了97.02%的分类正确率[4]。同年,Polat和 Güne提出基于模糊加权预处理、最近邻加权预处理以及决策树分类器来进行红斑鳞状皮肤病的诊断研究,分别达到了88.18%、97.57%和99.00%的分类正确率[5]。Nanni于2006年应用LSVM、RS、B1_5、B1_10、B1_15、B2_5、B2_10和B2_15算法对该疾病进行分类研究,分别得到97.22%、97.22%、97.5%、98.1%、97.22%、97.5%、97.8%和 98.3% 的分类准确率[6]。2007年,Luukka提出了基于 Yu’s范数相似性度量的相似性分类器对红斑鳞状皮肤病诊断进行研究,达到的分类准确率为 97.8%[7]。Übeyli于2008年应用带有误差修正输出码的多类支持向量机对鳞状红斑皮肤病诊断的分类准确率达到了 98.32%[8]。2009年,Polat和Günes提出了基于 C4.5决策树和一对其余多类分类方法的混合智能方法研究红斑鳞状皮肤病诊断,取得了96.71%的分类正确率[9]。同年,Übeyli应用联合神经网络模型指导模型选择对红斑鳞状皮肤病诊断进行研究,取得了97.77%的分类准确度[10]。Liu等人应用基于动态互信息的特征选择算法,以朴素贝叶斯、1-最近邻、C4.5和PIPPER四种分类器对红斑鳞状皮肤病进行研究分别获得了96.72%、92.18%、95.08%和92.20%的分类准确率[11]。Karabatak和 Ince于 2009年提出了一种新的基于关联规则和神经网络的特征选择算法对红斑鳞状皮肤病的诊断进行研究,从34个原始特征中选取了24个,达到了98.61%的识别率[12]。2010年 Übey提出了基于 K-means聚类的红斑鳞状皮肤病诊断自动检测[13]。我们基于特征选择思想,提出改进的F-score来度量特征在多类之前的区分能力,也即特征的重要程度,在此基础上,采用顺序前向特征选择策略、顺序前向浮动特征选择策略进行特征选择,以支持向量机(support vector machines,SVM)为分类器提出两种混合的特征选择算法,并将这两种算法应用于红斑鳞状皮肤病的诊断研究,分别取得了很好的研究结果[14-15]。
SVM由Vapnik等人于20世纪90年初提出[16]。该理论基于统计学习理论的 VC维和结构风险最小化原则,优于传统的经验风险最小化原则,具有很好的泛化性能,是目前很好的机器学习方法之一。SVM通过核函数将低维输入空间线性不可分的样本映射到高维特征空间,使其在特征空间线性可分,并得到一个最大间隔的分类超平面。
分类问题中的特征选择原则是:选择使得某种标准达到最优的特征,剔除冗余的特征,或者对分类原则贡献极小的特征[17]。SVM因为其优越的分类性能自然可以作为分类问题中特征选择的原则。近年来,基于SVM的特征选择引起了不少学着的关注和研究[14,18-21]。将 SVM 引入到红斑鳞状皮肤病的诊断研究,以SVM为分类器,选择使得分类器性能最佳的特征,对该类皮肤病的诊断研究非常有意义[14-15]。
文献[14-15]将 F-score进行推广,用于多类问题的特征区分度度量,将其作为特征重要性的度量准则,以SVM为分类器,提出两种混合的特征选择方法,应用于红斑鳞状皮肤病的诊断研究,取得了很好的诊断结果。但是,改进的F-score准则没有考虑不同的特征测量量纲对特征区分度的影响,本文针对此问题提出一种新的特征区分能力度量准则D-score,避免不同特征的测量量纲对特征重要性的影响,度量特征在两类或多类之间的区分能力;并结合 SFS(Sequential Forward Search,SFS)和 SFFS(Sequential Forward Floating Search,SFFS)搜索策略进行特征选择,以SVM分类器的分类准确率作为特征子集的评价标准,引导特征选择过程。十折交叉验证实验结果表明:基于 D-score和 SFS、SFFS的两种混合型特征选择算法所选择的特征在红斑鳞状皮肤病的诊断中具有很好的分类效果,诊断准确率优于 F-score准则。
1 支持向量机
支持向量机的基本思想是将输入空间线性不可分的数据通过核函数映射到一个高维特征空间,通过在特征空间求解一个线性约束二次规划问题,寻找一个能将数据线性分割的最大间隔分类面[16]。
对于两类分类问题,支持向量机旨在寻求将两类样本分开且保证分类间隔最大的最优分类面。假设样本集为 (x1,y2),(x2,y2),…,(xl,yl),其中xi∈ RN,yi∈ {- 1,+1},i=1,2,…,l。引入核函数的支持向量机可描述为如下的优化问题:
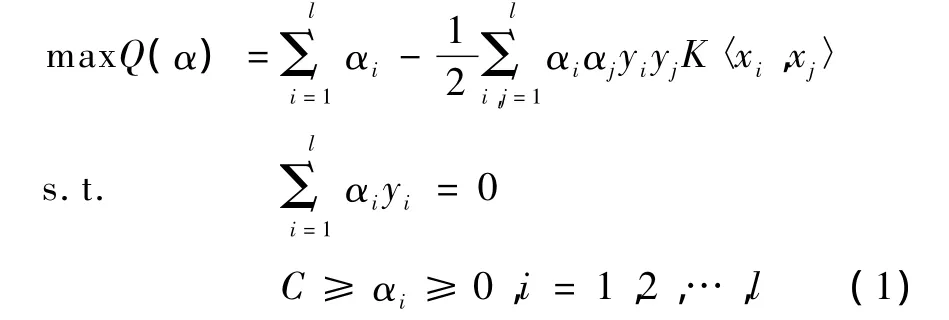
此时SVM的决策函数为
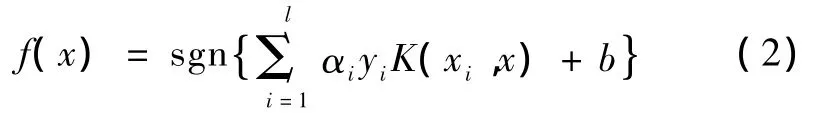
不同核函数导致不同的支持向量机算法,目前采用的内积核函数主要有4类:
(1)线性核函数
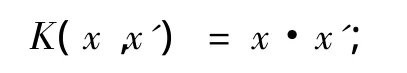
(2)多项式核函数函数
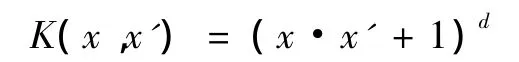
式中d是正整数
(3)径向基核函数:
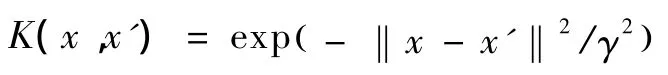
其中γ是正实数
(4)S型核函数:
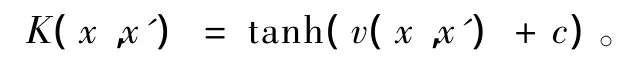
对于多类分类问题,SVM经常将其转化成多个两类分类问题来解决。从而达到使任意两类间的分类间隔都最大。
2 D-score混合特征选择方法
特征选择在构建分类系统中起重要作用[22-23],它不但可以减少数据的维数,同时可以降低计算的复杂度,提高分类器的性能[24]。常用的特征选择算法可以分为两大类:Filter方法和 Wrapper方法[25-26]。Filter方法不需要分类器的信息反馈,独立于分类器,依据相关的判断准则选择对分类起重要作用的特征,间接评估分类器的性能,如:反映类间区分程度的距离方法。Wrapper方法依赖于分类器,基于分类器的分类性能评价所选特征子集的优良,从而选择对分类有重要贡献的特征,它可能直观地获得更好的分类性能。但是Wrapper方法所选择的特征依赖于所选用的分类器,且需要较长的训练时间。Filter方法因为不需要分类器的反馈信息,从而训练速度较快,但是分类精度可能不如Wrapper方法。因此,近年来出现了结合 Filter和Wrapper方法优点的混合特征选择方法[14-15,18-21]。
在文献[14-15]基于改进F-score和SVM 的红斑鳞状皮肤病研究基础上,针对改进F-score作为特征评价标准时,没有考虑特征测量量纲对特征区分度可能带来的影响这一缺陷,提出一种新的样本特征区分度评价准则D-score,依据该准则评价特征的重要性,将特征降序排序;分别采用SFS和SFFS特征选择策略,依次加入特征到被选特征子集,以SVM为分类器,评价选择特征子集的分类性能,得到两种混合的特征选择算法。其中,在SFS策略中依次加入各个特征,直到所有的样本特征都加入;在SFFS中每次尝试加入剩余特征中排在最前面的特征,即加入剩余特征中最重要的特征,如果加入该特征导致分类器的分类正确率下降,则删除该特征,即不加入该特征到被选择特征子集。
2.1 传统F-score与改进的F-score
特征选择是从众多特征中选择出对分类识别最有效的那些特征,来实现特征空间维数的压缩。F-score由 Chen 等人提出[19],是一种基于类间类内距离的特征评价准则,能够衡量特征在分类中辨别能力的强弱,是一种简单有效的特征选择方法。传统F-score只能辨别特征在两类问题中辨识能力的大小。其描述如下。
给定训练样本集 xk∈ Rm,k=1,2,…,n。其中正类和负类的样本数分别为n+和n-。则训练样本第i个特征的F-score定义为:
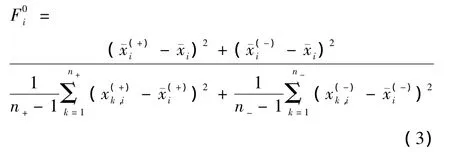
由于传统F-score只能够评估两类分类问题中样本特征辨别能力的大小,为此,提出了改进的 F-score[20],将传统 F-score 推广到了多类问题,应用于特征选择,取得了很好的效果。改进F-score的描述如下。
给定训练样本集 xk∈ Rm,k=1,2,…,n;l(l≥2)为样本类别数,nj为第j类的样本个数,j=1,2,…,l。则训练样本的第i个特征的F-score定义为
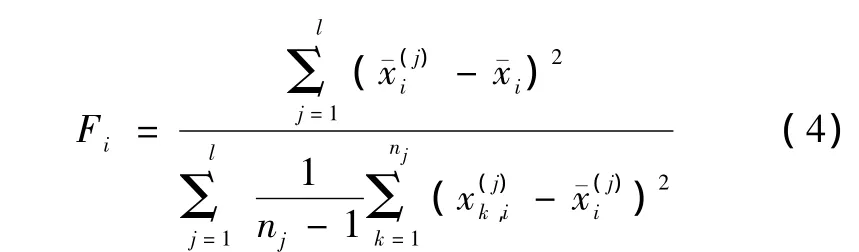
2.2 D-score特征评价准则
2.1 中的F-score均是基于类内类间距离的类别可分性评价准则,没有考虑不同特征的测量量纲对特征重要性,即特征区分度的影响。基于此思想,提出 D-score特征评价准则,以克服 2.1中 F-score的缺陷。D-score定义如下。
首先将式(4)除以l-1,得
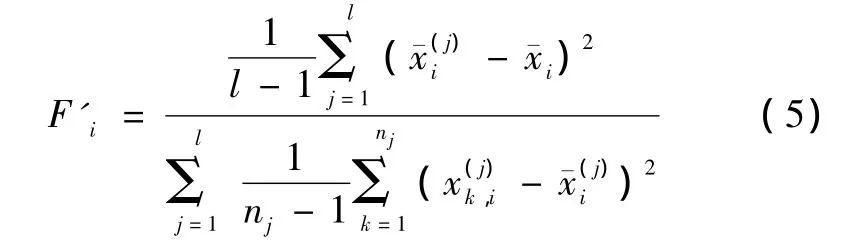
式(5)中分子表示的是各类别之间的方差,此处以各个类的中心点代表相应类,分母表示各个类别的类内方差之和。分子越大,表明类间的差异越大;分母越小,表明类内的差异越小。因此式(5)的值越大,表明相应特征的分类能力越强,即类间越疏,类内越密,分类效果越好,也就是此特征的辨别力越强。
方差反映了数据分散程度的绝对值,其数值的大小一方面取决于原变量值本身水平的高低,也就是与变量的均值大小有关,变量值绝对水平高的,离散程度的测度值自然也就大,绝对水平小的其离散程度的测度值自然也就小;另一方面,它们与原变量值的计量单位相同,采用不同计量单位计量的变量值,其离散程度的测度值也就不同[27]。为了消除均值和测量单位不同对离散程度统计量的影响,引入离散系数。离散系数是一组数据的标准差和其对应的均值的比值,也称为变异系数,用 v表示,定义为

受离散系数的启示,为在一定程度上消除均值和不同量纲对离散程度的影响,将式(5)中的类内类间方差分别除以各自的均值,得
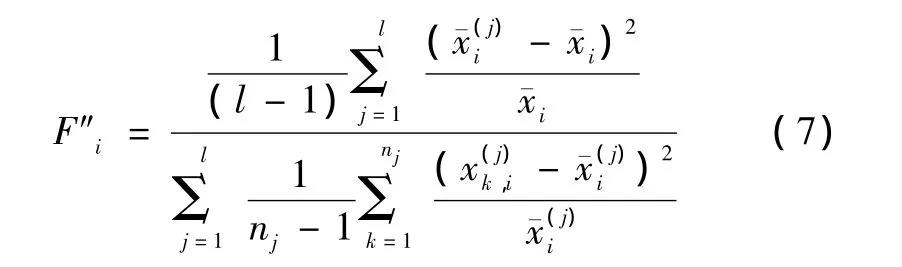
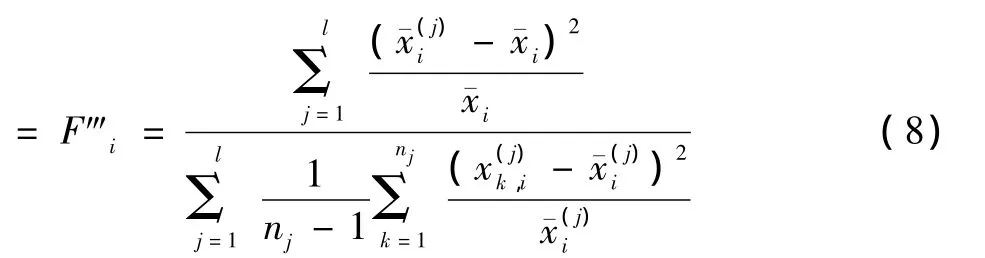
2.3 顺序前向搜索(SFS)
顺序前向搜索由Whitney于1971年提出[28],是一种自下而上的搜索方法。搜索过程从空集开始,首先选择最好的一个特征加入被选择特征子集,然后选择最好的一对特征加入被选择特征子集,其中这个最好的特征对里包含已经入选的那个最好特征。该过程一直进行,每次从未被选择的特征中选择一个最好的特征,即该特征和已被选择的特征子集组合具有最好的分类特性,直到达到指定数目特征或者满足其他搜索停止条件。
SFS只需要逐步添加“最好”的一个特征,本文实验并不是每次选择和已经被选择的特征子集组合具有最佳分类性能的特征,而是根据特征的 D-score值依次加入未被选择的具有最高D-score值的特征。实验中选择分类正确率开始下降时,所对应的被选择特征子集为最优特征子集。
2.4 顺序前向浮动搜索(SFFS)
SFS的缺点是:“子集嵌套”,一旦某个特征被选中,之后就没有办法剔除该特征,这样仅能得到一个局部最优的特征子集。Pudil等人于1994年提出顺序前向浮动搜索算法(SFFS)[29],克服 SFS方法的特征子集嵌套的缺陷。
本研究借用顺序前向浮动搜索策略的思想,依次尝试加入D-score值最好的特征,当加入某一个特征后,若训练集的分类正确率没有上升,则不加入当前选择的特征;否则则加入该特征。然后尝试加入下一个D-score值最好的特征。直到所有的特征被扫描一遍结束。该方法能够在一定程度上避免陷入局部最优解,同时选取的特征数目一般会比SFS策略选取的特征数目少。
3 实验方法
3.1 数据的获取与预处理
红斑鳞状皮肤病数据来自于UCI数据库中的dermatology数据集,该数据集有34个特征,366个样本,其中有8个样本有缺失数据,本实验中剔除了这些有特征缺失的样本,实际使用了358个样本。为了使实验结果具有统计意义,采用10折交叉验证方法进行实验,同时进行10折交叉实验之前对样本进行了随机打乱预处理;10折的分法为对每一类的样本依次逐个加入到10个不同样本集合中(初始时各样本集合为空),直到这一类的每一个样本都被加入。这样实现了样本均匀划分为10份的目的,以每一份分别作测试样本,其余九份作训练样本,实现10折交叉验证实验。文中对比实验在同样划分的同一数据集上进行。
3.2 SVM核函数及参数选择
实验中支持向量机的核函数采用径向基核函数RBF[30]。为此,需要确定 SVM的惩罚因子和核函数参数γ。为了得到具有较好推广性能的SVM模型,采用网格搜索和10折交叉验证相结合的方法来选择最优的 C 和 γ。其中,C ∈ {2-5,…,215},γ ∈{2-15,…,25}。实验中对每一对(C,γ)参数组合,在训练集上进行10折交叉验证实验确定该组C和γ对应的分类正确率平均值,选取训练集平均分类正确率最佳的一组C和γ为SVM的最佳参数,构建具有最大分类间隔的SVM分类模型。以此模型对相应测试集进行分类,得到测试集分类正确率。此处使用的SVM工具箱为台湾林智仁教授等开发的LibSvm 工具箱[31]。
3.3 D-score+SFS+SVM特征选择
根据式(8)计算每个特征的D-score值,并依据D-score值对特征进行降序排序;利用 2.3描述的SFS,每次从未被选取的特征中选择一个 D-score值最大的特征添加到被选特征集合(被选特征集合初始为空集);采用SVM对当前选取的特征子集进行评价,SVM参数的选择依据3.2描述的训练集上的网格搜索和10折交叉验证进行。迭代一直进行,直到所有特征都加入被选特征子集。选择分类效果最佳,即训练集分类正确率开始下降时的特征子集,作为最优特征子集,构建分类模型,得到具有最大分类间隔的分类超平面。
为证明D-score特征评价准则的有效性,对基于D-score特征评价准则与 SFS的混合特征选择方法和基于改进F-score与SFS的混合特征选择方法,在同样划分的红斑鳞状皮肤病数据集上进行10折交叉验证的对比实验。
3.4 D-score+SFFS+SVM特征选择
3.3中基于D-score与SFS,并以支持向量机的分类准确率评估所选特征子集的混合特征选择方法具有“子集嵌套”缺陷,即一旦某个特征入选,即使所加入的特征是冗余特征,后边也无法再将其删除。为了避免这种“子集嵌套”问题,及其在红斑鳞状皮肤病诊断中所带来的潜在缺陷,改变搜索策略,采用2.4所述的SFFS搜索策略,以SVM为分类工具,在特征加入过程中删除(不加入)那些不重要的或冗余的对分类不起作用的特征。即每加入一个特征都进行判断,如果所加入的特征对分类正确率无正面影响,则将此特征不加入被选择特征子集;否则,加入该特征到被选特征子集。该方法所选择的特征未必具有较大的D-score值,但是考虑了特征之间的相关性,所选择的特征子集具有最好的训练集分类正确率。
为验证基于 D-score准则和 SFFS特征搜索策略的混合特征选择方法在红斑鳞状皮肤病诊断中的有效性,将基于D-score和SFFS的混合特征选择方法与基于改进F-score和SFFS的混合特征选择方法,在同样划分的红斑鳞状皮肤病数据集上进行10折交叉验证的对比实验。
4 实验结果与分析
4.1 D-score+SFS+SVM实验结果分析
基于D-score准则和 SFS搜索,以及 SVM的混合特征选择方法在红斑鳞状皮肤病数据集的10折交叉验证实验结果,与基于改进 F-score准则和SFS,以及SVM的混合特征选择方法在同一数据集的10折交叉验证实验结果如图1、2所示。图1为训练集上10折交叉验证实验的平均分类正确率。图2为相应测试集的平均分类准确率。曲线上的误差棒为10折交叉验证的分类正确率标准差。从图1、2可见基于 D-score准则的特征选择优于基于改进F-score准则的特征选择。按照训练集平均分类正确率开始下降选择最优特征子集,改进的F-score准则选择的最优特征子集包含21个特征,训练集平均分类正确率为97.7967%,测试集平均分类正确率为97.4983%;D-score准则对应的最优特征子集包含特征数为25个,训练集的平均分类正确率为98.8517%,测试集的平均正确率为98.6111%,均高于F-score准则。由此可见本研究提出的 D-score特征评价准则对红斑鳞状皮肤病具有更好的诊断效果。
4.2 D-score+SFFS+SVM实验结果分析
基于D-score、SFFS以及 SVM的混合特征选择方法与基于改进 F-score、SFFS和 SVM的混合特征选择方法在红斑鳞状皮肤病数据集的10折交叉验证实验结果分别如表1和表2,以及图3所示。

图1 训练集正确率比较Fig.1 The comparison of accuracy on training set
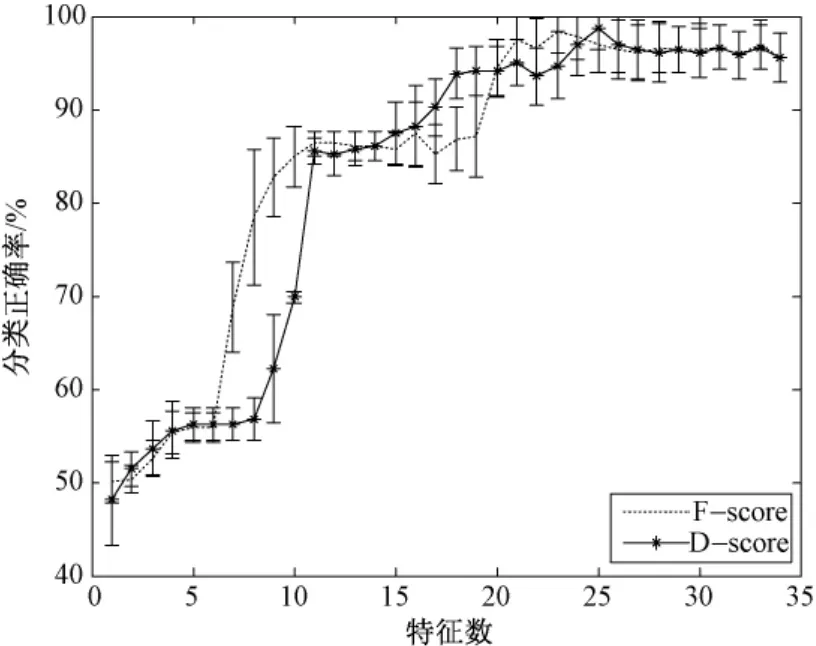
图2 测试集正确率比较Fig.2 The comparison of accuracy on testing set
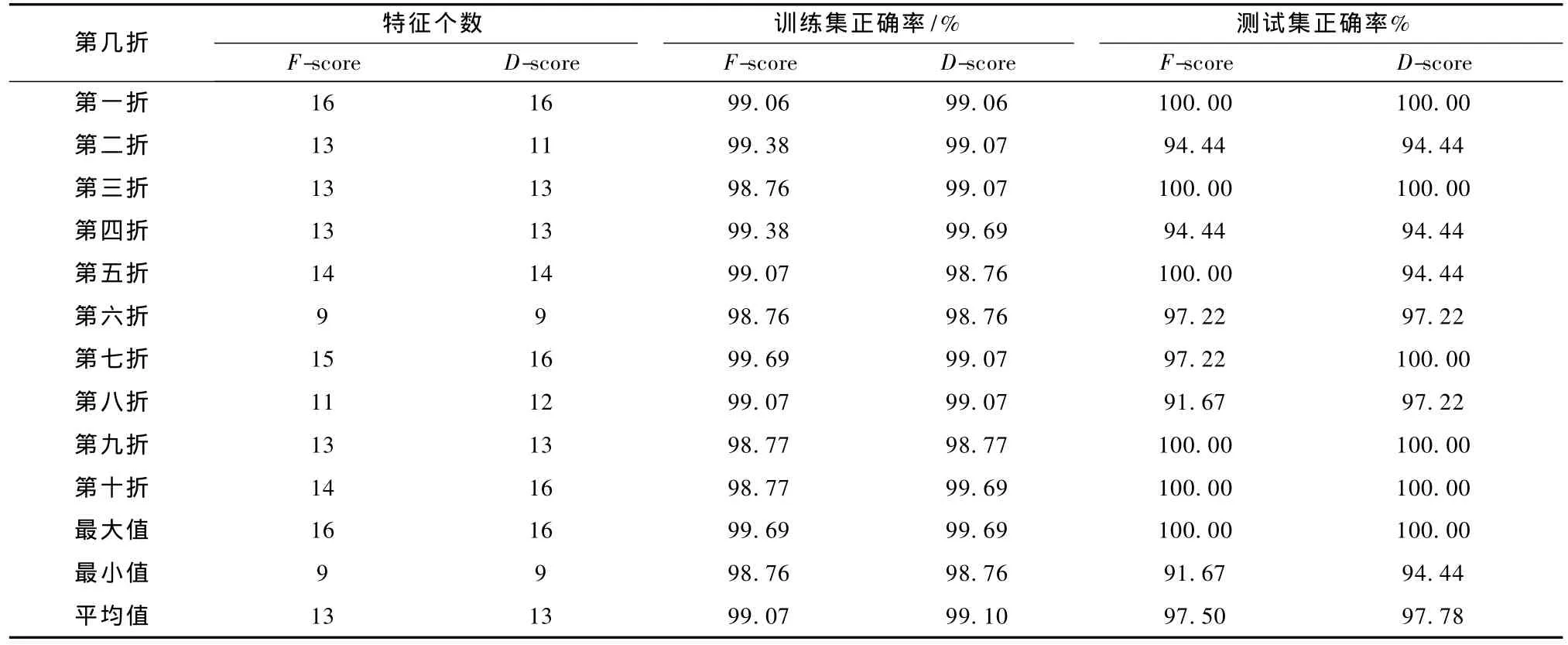
表1 F-score+SFFS与D-score+SFFS特征选择结果Tab.1 The experiment results of F-score with SFFS and D-score with SFFS
表1显示,D-score特征评价准则选择的特征个数平均在13.3左右,近似于改进 F-score准则所选择的特征数;训练集的平均分类正确率为99.0998%,高于改进F-score准则的99.0693%;测试集的平均分类正确率为97.7778%,优于改进F-score准则 97.5%的诊断效果。由此可见,D-score特征评价准则无论在训练集还是测试集,其分类正确率都优于改进的 F-score准则。因此,本研究提出的 D-score特征评价准则实现了对红斑鳞状皮肤病特征的有效选择,基于该准则的混合特征选择方法对诊断红斑鳞状皮肤病具有更好的诊断效果。
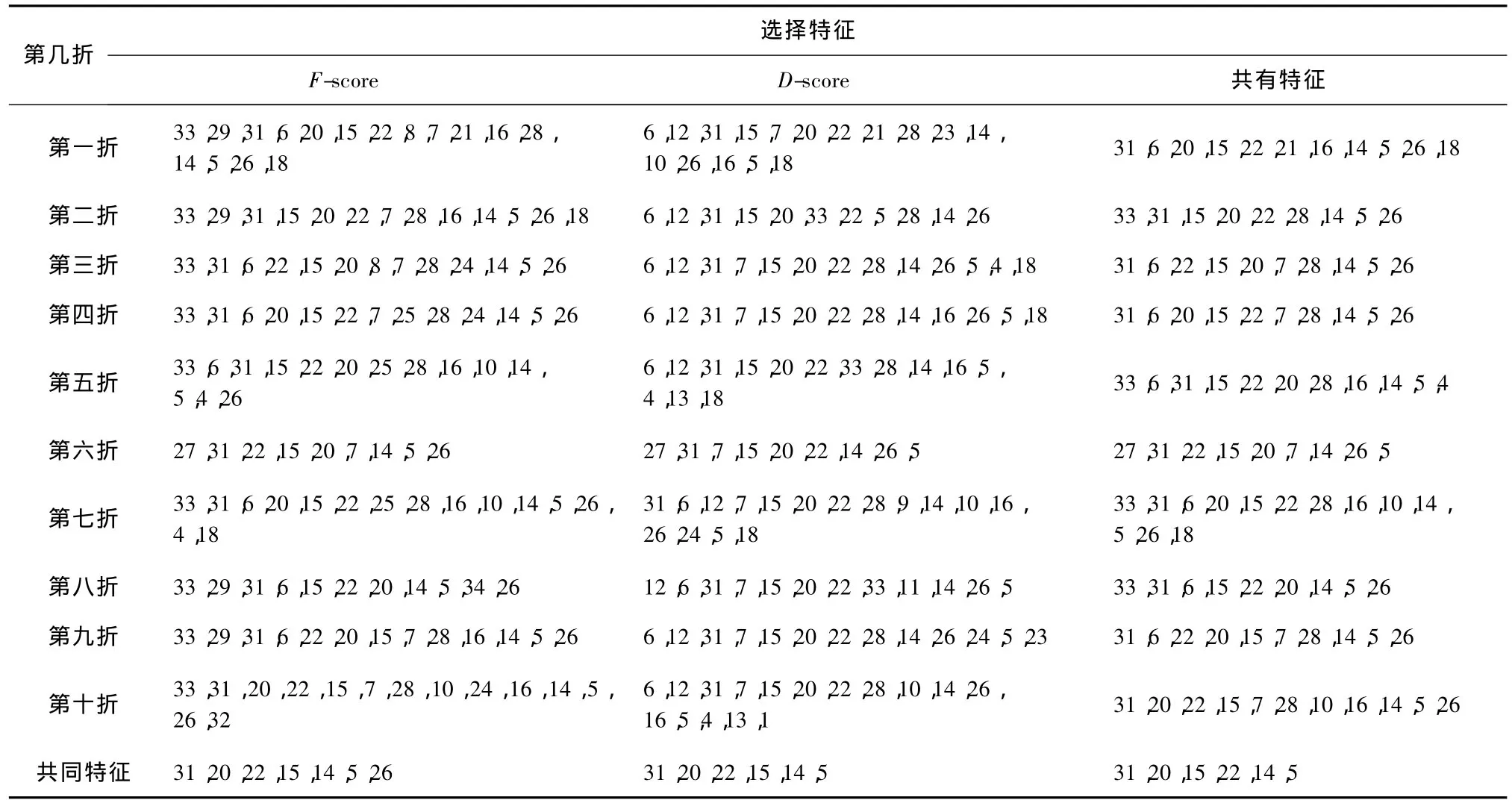
表2 F-score+SFFS与D-score+SFFS所选择特征比较Tab.2 The features selected by F-score with SFFS and D-score with SFFS
表2对基于改进 F-score、SFFS和 SVM 的混合特征选择方法,和本文基于D-score、SFFS与SVM的混合特征选择方法所选择的特征进行比较。从表2的比较可以看出:两种特征评价方法对同样的训练集选择出的特征不完全相同,但是第 31、20、15、22、14和5这六个特征是两种不同的特征评价准则所选择的共同特征。另外,表2还显示,D-score和改进F-score两种特征评价准则的十折交叉验证实验的共同特征只有一个特征(第26个特征)的差异,其他6个共同特征一致。这表明,D-score准则以不同的特征组合取得优于改进F-score准则的分类效果。以上分析还表明,不同的特征组合可以得出同样正确的诊断结果,这为红斑鳞状皮肤病的诊断提供了多种不同的诊断依据选择。
图3显示,改进 F-score和 SFFS结合有第 5、14、15、20、22、26 和31 等6 个特征在10 个不同训练集上均被选择,第33个特征的被选频率90%,第28个特征的被选频率为80%,第6、7个特征的被选频率是70%,第16个特征的被选频率为60%,其他特征的被选频率均低于50%,因此在诊断中这些被选频率低于50%的特征可以被忽略。基于D-score与SFFS 的混合特征选择实验中第 5、14、15、20、22、31这5个特征被100%的选中;被90%选中的特征有:6、12、26;第7和第28个特征以80%的频率被选中;其他特征被选择的频率均低于50%,成为可以被忽略的特征。由此可见,基于 D-score和 SFFS的混合特征选择方法不仅提供了更准确的诊断效果(由表1实验结果可知),而且该方法提供了更多的诊断依据选择,但是需要首先考虑的特征数只有5个,低于改进F-score准则结合SFFS策略的6个必须考虑特征,将第26个特征作为进一步诊断的备选择特征考虑。
5 讨论和结论
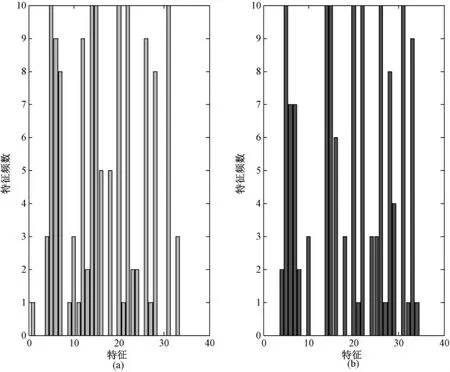
图3 F-score+SFFS与D-score+SFFS所选择特征的被选频数比较。(a)F-score+SFFS;(b)D-score+SFFSFig.3 The frequencies of selected features by F-score+SFFS(a)and D-score+SFFS(b),respectively
本研究提出了一种新的不受特征测量量纲影响的特征评价准则D-score,不但可以评价两类分类问题中特征的重要性,且能够评价多类分类问题中特征的分类辨识能力大小。将D-score准则分别与SFS和SFFS特征选择策略结合进行特征选择,以SVM为分类工具,对被选择特征子集的分类性能进行评价,引导特征选择过程,得到两种混合的特征选择算法。该两种混合特征选择方法应用于鳞状红斑皮肤病诊断研究,并与基于改进F-score的相应混合特征选择方法进行实验比较。10-折交叉验证的实验结果显示,本研究提出的D-score特征评价准则是一种有效的特征辨识能力评价准则,基于该准则的混合特征选择方法实现了对鳞状红斑皮肤病的有效诊断,诊断准确率优于基于改进F-score准则的混合特征选择方法;同时 D-score准则与SFFS特征搜索策略结合提供了更多的诊断依据选择,而首先需要考虑的诊断特征只有5个,低于改进F-score准则与SFFS搜索策略结合所得的必须考虑的诊断特征个数。然而,D-score准则与改进 F-score准则一样,对于特征辨识能力的度量只考虑了单个特征的辨识能力,没有考虑特征之间的相关性,实验中特征之间的相关性依赖于特征选择策略,而特征之间的相关性对特征选取有很大影响。如何在特征辨识能力评价准则上考虑特征之间的相关性是我们正在进一步研究的内容。同时,使用SVM为分类工具,并以此评价所选择特征子集的分类性能,需要确定SVM的最佳参数,以提高分类器的泛化性能,这增加了算法的时间复杂度。关于SVM最佳参数的选取方法,依然是SVM分类器的瓶颈。
[1]Güvenir HA,Demiröz G,˙Iter N.Learning differential diagnosis of erythemato-squamous diseases using voting feature intervals[J].Artificial Intelligence in Medicine,1998,13(3):147 -165.
[2]Güvenir HA,Emeksiz N.An expert system for the differential diagnosis of erythemato-squamous diseases[J].Expert Systems with Applications,2000,18(1):43 - 49.
[3]ÜbeyliED,Güler˙I.Automaticdetectionoferythematosquamous diseases using adaptive neuro-fuzzy inference systems[J].Computers in Biology and Medicine,2005,35(5):421 -433.
[4]Luukka P,Leppälampi T.Similarity classifier with generalized mean applied to medical data[J].Computers in Biology and Medicine,2006,36(9):1026-1040.
[5]Polat K,Güneş S.The effect to diagnostic accuracy of decision tree classifier of fuzzy and k-NN based weighted pre-processing methods to diagnosis of erythemato-squamous diseases[J].Digital Signal Processing 2006,16(6):922-930.
[6]Nanni L. An ensemble of classifiers for the diagnosisof erythemato-squamous diseases[J].Neurocomputing 2006,69(7):842-845.
[7]Luukka P.Similarity classifier using similarity measure derived from Yu's norms in classification of medical data sets[J].Computers in Biology and Medicine 2007,37(8):1133-1140.
[8]Übeyli ED.Multiclass support vector machines for diagnosis of erythemato-squamous diseases [J]. Expert Systems with Applications,2008,35(8):1733-1740.
[10]ÜbeyliED. Combined neural networks for diagnosis of erythemato-squamous diseases [J]. Expert Systems with Applications,2009,36(3):5107-5112.
[11]Liu Huawen,Sun Jigui,Liu Lei,et al.Feature selection with dynamic mutual information[J].Pattern Recognition,2009,42(7):1330-1339.
[12]Karabatak M,Ince MC.A new feature selection method based on association rules for diagnosis oferythemato-squamous diseases[J].Expert Systems with Applications,2009,36(10):12500-12505.
[13]ÜbeyliED,DoˇgduE.Automaticdetectionoferythematosquamous diseases using k-means clustering [J].Journal of Medical System.2010,34(2):179-184.
[14]Xie Juanying,Xie Weixin,Wang Chunxia,et al.A novel hybrid feature selection method based on IFSFFS and SVM for the diagnosis of erythemato-squamous diseases[C].//Diethe T,Cristianini N,Shawe-Taylor J,eds. JMLR Workshop and Conference Proceedings Volume 11:the First Workshop on Applications of Pattern Analysis.Cambridge:MIT Press,2010:142-151.
[15]Xie Juanying,Wang Chunxia.Using support vector machines with a novel hybrid feature selection method for diagnosis of erythemato-squamous diseases [J]. Expert Systems with Applications,2011,38(5):5809-5815.
[16]Vapnik V.The Nature of Statistical Learning Theory[M].(2nd edition).New York:Springer,1995.
[17]Fu KS,Min PJ,Li TJ.Feature selection in pattern recognition[J].IEEE Transactions on Systems Science and Cybernetics,1970,SSC-6(1):33 -39.
[18]Liu Yi,Zheng Yuan.FS_SFS:A novel feature selection method for support vector machines[J].Pattern Recognition,2006,39(7):1333-1345.
[19]Chen YL. Lin JL. CombiningSVMswith variousfeature selection strategies[C] //Guyon S,Nikravesh M,Zadeh L,eds.Feature Extraction,Foundations and Applications.Berlin:Springer,2006:315 -324.
[20]谢娟英,王春霞.基于改进的F-score与支持向量机的特征选择方法[J].计算机应用,2010,30(4):993-996.
[21]Guyon I,Weston J,Barnhill S,et al.Gene selection for cancer classification using supportvectormachines[J]. Machine Learning,2002,46(1-3):389-422.
[22]Liu Huiqing,Li Jinyan,Wong Limsoon.A comparative study on feature selection and classification methods using gene expression profiles and proteomic patterns[J].Genome Informatics,2002,13:51-60.
[23]Hua Jianping,Tembe WD,Dougherty ER.Performance of feature selection methods in the classification of high-dimension data[J].Pattern Recognition,2009,42(3):409 - 424.
[24]Guyon I.Elisseeff A.An introduction to variable and feature selection[J].Journal of Machine Learning Research,2003,3:1157-1182.
[25]Kohavi R.John G.Wrappers for feature selection[J].Artificial Intelligence,1997,97(1-2):273-324.
[26]Blum A,Langley P.Selection of relevant features and examples in machine learning[J],Artificial Intelligence,1997,97:245-271.
[27]刘春英,贾俊平等.统计学原理.北京:中国商务出版社,2008:99-101
[28]Whitney AW.A direct method of nonparametric measurement selection[J].IEEE Transactions on Computers,1971,20:1100-1103.
[29]Pudil P,Novovicova J,Kittler J.Floating search method in feature selection[J].Pattern Recognition Letters,1994,15(11):119-1254.
[30]Hsu CW,Chang CC,Lin CJ.A practical guide to support vector classification[R]. Technical Report,Department of Computer Science,National Taiwan University.July,2003.
[31]Chang CC,Lin CJ,LIBSVM:a library for support vector machines[CP].http://www.csie.ntu.edu.tw/~ cjlin/libsvm.2010-04-01/2010-07-20.
