Hoeffding克隆选择算法及其在关联分类中应用
2012-06-29王洪亮
王洪亮,赵 理,2
(1. 石家庄职业技术学院,河北 石家庄 050081;2. 西安理工大学,陕西 西安 710048)
1 引言
工程应用中,克隆选择算法(CLONALG)解决了许多复杂的实际问题。然而,在计算某些迭代的高复杂性的问题时,亲和力的计算需要大量的时间,或者并不存在一个显性的亲和力计算公式。此时,我们不得不构造复杂的估计模型来估计细胞的亲和力。事实上,亲和力估计已经变成克隆选择算法在处理某些高复杂性问题的关键问题之一。
与传统的分类方法(决策树、规则学习、关联规则、贝叶斯、统计理论等)相比,基于关联规则的关联分类方法能取得比较高的分类精度[1-2]。然而,关联分类的一个主要问题,例如,CBA算法和CMAR算法,就是需要消耗大量的时间来搜索可能的关联规则。特别是当支持度门限被设置为一个较小的值的时候。而小的支持度门限往往又有利于提高分类器的精度[3-4]。传统关联分类算法中,规则的发现过程和分类器的构造过程是两个分开的过程。这导致了传统关联分类的低效[5-6]。
本文提出一种新的克隆选择算法,Hoeffding克隆选择算法(H-CLONALG),来解决关联分类过程中耗时的亲和力(精确度或支持度)计算问题。该算法能在不完全读取数据集中所有记录的前提下,准确地确定父代种群中个体亲和力的高低顺序,进而选择高质量的个体形成子代种群。该算法的主要特点在于,可以以确定的概率保证得到的子代个体就是最优的或接近最优的子代个体。该算法跟传统的克隆选择算法具有相似的计算精度,但是,其运算时间要大大的低于后者。
2 关联分类
Liu首先提出了一种关联分类方法[7-8],被称为CBA方法。该方法基于发现的关联分类规则来构造分类器。关联分类规则的挖掘和关联规则的挖掘的不同之处就在于,前者可以同时挖掘用来表示不同分类的频繁项集,而后者挖掘的是所有的频繁项集。关联分类的框架由以下两步组成: (1)产生所有的关联分类规则,形式如“iset=>c”,其中iset表示属性的集合,c表示类;(2)基于关联分类规则,构造分类器。一般来说,关联分类器的构造是基于分类规则的可信度大小,由关联分类规则的子集构成。
目前,常用的基于进化类优化算法的关联分类算法将这两个过程整合在一起,改善关联分类的效率。然而在这些算法中,当数据集较大时,个体亲和力(适应度)的计算仍然是制约算法计算效率的一个关键问题。文献[9]提出一种被称为“CPAR”的分类方法。该方法联合了关联分类和传统的基于规则分类方法的优点,利用贪婪算法直接从训练数据中产生规则,而不像传统的关联分类方法那样先产生大量的候选规则,再生成分类器。另一种被称为基于人工免疫算法的关联分类算法(AIS-AC)利用进化的方式,只寻找能构造有效分类器的规则的子集来生成分类器,提高了关联分类的效率[10]。文献[11]提出了一种叫作“EvoCMAR”的进化的分类方法直接挖掘分类的关联规则。但是,在这些方法中,每条规则的适应度的计算,需要遍历数据集中所有的样本记录,这依然是阻碍这些方法有效应用的一个问题。
3 Hoeffding边界
当独立的随机变量xi的某些分布信息给定时,由n个这些随机变量组成的和的分布函数是非常重要的。它们是现代概率理论的基础。
假设X1,X2, … ,Xn为具有一阶和二阶矩的独立变量,
(1)
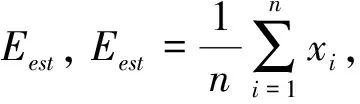
假设实值随机变量r的变化范围为B。已经观测到该变量的n个独立的观测值,计算得到其均值为rmean。Hoeffding边界以1-δ的概率保证该变量的真实均值(读取所有记录后计算得来)与rmean的差距小于ε。
4 Hoeffding 克隆选择算法
4.1 克隆选择算法
克隆选择的原则最早是由Burnet[13]提出来的,后来一种叫作“receptor editing”的概念被提出来加强Burnet的理论[14]。克隆选择算法是一种有效的、便于使用的方法,被广泛应用到许多优化和模式识别的任务中。它对高亲和力的细胞赋予较低的变异率;对低亲和力的细胞赋予较高的变异概率。根据文献[15],克隆选择算法主要包含以下几步。
(1) 初始化种群Pr;置空记忆集合M;
(2) 根据亲和力选择最好的n个细胞形成新种群Pn;
(3) 由种群Pn产生克隆种群C(高亲和力细胞产生比较多的后代);
(4) 变异种群C中的细胞产生种群C*;
(5) 从C*中选择较好的细胞,更新记忆库M;
(6) 多样性引入(用新产生的细胞Nd代替旧的d个细胞)。
4.2 Hoeffding选择
设F(Xi)为从种群中选择个体的评判标准,读取了n条记录后,算法根据F(Xi)的值对种群中的个体从大到小排队,假设Xj为第j个个体,Xj+1为第(j+1)个个体,ΔF=F(Xj)-F(Xj+1)>=0为这两个个体亲和力(适应度)的差距。则给定一个合适的δ值,如果ΔF>ε,那么Hoeffding边界可以以1-δ的概率保证,前j个个体就是正确的选择。这样,种群只需要积累n条记录,使得ε变得小于ΔF,就可以从种群中以概率1-δ来正确地选择最优的j个个体。ε是n的单调递减函数。

定义2(真实平均亲和力): 个体Xi的真实亲和力F(Xi)就是指,当计算所有记录后个体亲和力的平均值。
本文中Hoeffding选择算法操作表述如下。
(1) 初始化概率参数1-δ,数据集规模N;
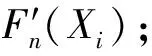

4.3 Hoeffding 克隆选择算法
H-CLONALG算法和CLONALG算法的主要不同在于,CLONALG算法的亲和力计算与选择操作使用传统的方式,而H-CLONALG算法的亲和力计算和选择使用Hoeffding选择算法(估计的方式)与传统选择算法相结合的方式,如图1中虚线框所示。
5 理论分析与证明
5.1 正确性分析
定义4(选择正确性概率): 选择正确性概率Prselection(j/m)是指在一次选择操作中,从种群规模为m的种群中正确的选取j个最优个体的概率。
定义5(算法正确性概率): 算法正确性概率Pralgorithm(t)是指在连续的t代进化中,连续正确的选取j个最优个体的概率.
定理1: 若Prn表示种群亲和力正确概率,n表示已经读取的样本记录数,m表示种群中个体总数,B是预测增量亲和力边界,那么:
证明: 令X1,X2,…,Xm表示种群P中个体,读入n条记录(样本)后,个体Xi的实时亲和力Fn(Xi)为Fn(X1),Fn(X2), …,Fn(Xm)。根据Hoeffding不等式,可以得到:
根据: Pr {A∨B}≤Pr {A}+Pr {B},可得:
翻转上式,可得: Prn≥1-2me-2nε2/B2, 令,Δ=2me-2nε2/B2,
得到:
定理2: 若Pralgorithm(t)表示算法连续进化t代后,连续正确选择j个最佳个体的概率,nt表示在t代选择时读取的样本记录数,m表示种群中个体总数,B是预测的增量适应度边界,那么:
证明: 令Prselection(j/m)表示选择操作中,读入n条记录(样本)后,正确选择j个最优个体的概率。根据定理1,可以得到:
翻转后,得到:
根据: Pr {A∨B}≤Pr {A}+Pr {B},可得:
翻转得到:
则:
5.2 效率分析
算法的复杂度是指最坏情况下,执行算法使用的时间和空间。由于使用的计算机不同,数据的表示方法不同,编程语言的不同等因素的存在,精确地确定算法的执行性能是很困难的。由于算法H-CLONALG和CLONALG只在亲和力的计算、个体选择环节不同,所以,在这里我们只分析两种算法在选择阶段的时间复杂度的不同。
对于算法H-CLONALG来说,t代间隔内用于亲和力计算以及选择个体的时间主要包括:Ts1和Ts2。Ts1表示使用传统的CLONALG算法时,亲和力计算和选择的时间开销,其复杂度为:O(N×M)+O(N2)。M表示数据集的记录总数;N表示种群规模。Ts2表示H-CLONALG算法中Hoeffding选择的时间复杂度,为:O((t-1)×n×N)+O((t-1)×N2)。参数n为Hoeffding选择发生时,读入的记录数。
对于算法CLONALG来说,t代间隔内用于亲和力计算以及选择个体的时间为:O(N×M×t)+O(N2×t)
两种算法在选择阶段的时间差距为:
由于参数n总小于M,所以当t>1时,算法H-CLONALG的运行时间总小于算法CLONALG的运行时间。两种算法对内存空间的需求很近似。
6 实验分析
我们在配置为: 主频3.0 GHz、内存512MB、操作系统Microsoft Windows XP的Pentium PC机上对提出的算法进行了实验。实验用到的数据集来自于UCI机器学习的专业数据集[16]。为了和其他算法作对比,并使仿真结果真实可信,我们选择了Adult、Digit、Letter、Nursery等几个大的数据集来作对比。数据集Digit的属性个数、类别数、样本个数分别为16、10、10 992;数据集Adult的属性个数、类别数、样本个数分别为14、2、48 842;数据集Letter的属性个数、类别数、样本个数分别为16、26、20 000;数据集Nursery的属性个数、类别数、样本个数分别为8、5、12 960。小的数据集、高的支持度门限往往导致不可信的实验结果。
6.1 种群规模
在图2中,将数据集Nursery随机分割为训练样本集(8 640条记录)和测试样本集(4 320)。算法H-CLONALG的可信度、支持度和覆盖度门限最初被设置为50%, 10% 和98%。根据定理1,随着种群规模m的上升,种群正确性概率的下界应该变小。然而,当我们把判断条件设置为“g mod t=t+1”(只留下Hoeffding选择操作),并且固定参数B,n和δ时,我们发现随着种群规模m的上升,该算法更稳定、快速地找到了最优解。这是什么原因呢?
事实上,概率Prn和概率Prselection(j/m)的差距是很大的。Prn表示的是在遇到n个记录后,种群中所有的个体的平均亲和力跟真实的亲和力相差在ε范围内的概率;而Prselection(j/m)表示的是在遇到n个记录后,正确的选择j个最优个体的概率。一般来说,Prselection(j/m)是要高于Prn的。定理1是基于假设,“算法能根据估计的亲和力,从种群中正确的选择j个个体”。实际上,即使错误的计算了每个个体的亲和力,算法还是有可能正确的选择j个最优的个体。例如,10个个体的真实亲和力分别为{0,1,…,9}。如果我们错误的得到了这些个体的亲和力为{0, 1.2, 2.2, 3.2, 4.1, 5.1, 6.3, 7.4, 7.9, 9.2},算法还是可以得到最优的前五个个体。
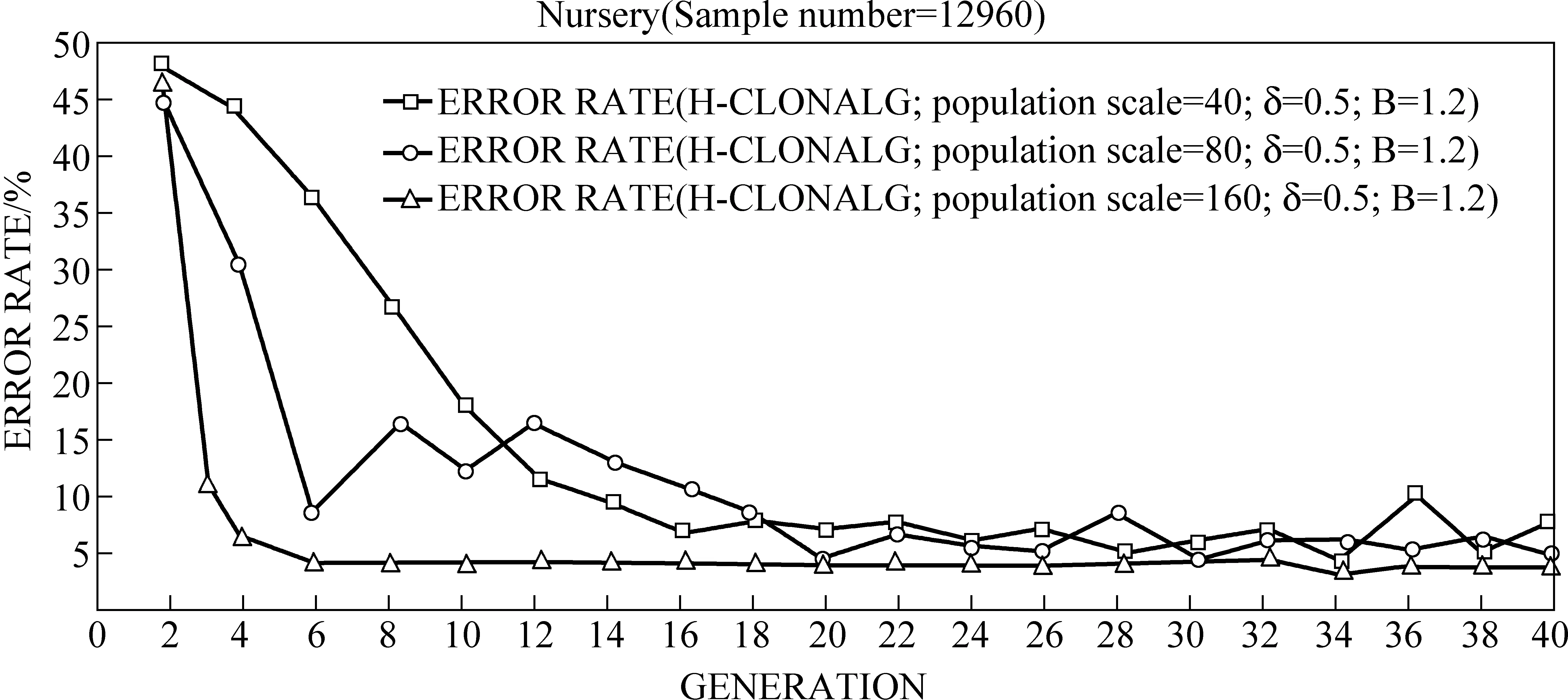
图2 不同种群规模对算法影响
6.2 选择概率和样本总数
令TH-CLONALG/CLONALG表示算法H-CLONALG和算法CLONALG在相同的进化代数内所花费时间的比值。我们测试了H-CLONALG算法在不同的样本数据集规模和参数设置1-δ的前提下的运算性能。
将Nursery的测试集中的记录随机裁剪为 2 160、4 320、6 480、8 640条。从图3可见,随着样本数据集规模和参数1-δ的提高,算法的运行时间变化是很明显的。对CLONALG算法而言,更高的样本数据集规模会导致更多的运行时间,这是很容易理解的。可是,为什么随着样本规模的上升,相对运行时间TH-CLONALG/CLONALG变的更短了呢?从第4.2节中,我们可以看出,Hoeffding选择算法的终止条件是"ΔF>ε"。根据公式(6),当B,m和δ被固定时,参数ε主要由当前记录数n决定,而不是N。换句话说,Hoeffding选择操作的运行时间跟数据集规模N没有必然的关系。而对于传统的选择操作来说,其运算时间主要由参数N来决定。所以,随着参数N逐渐变大,相对运行时间TH-CLONALG/CLONALG将会变得越来越小。

图3 不同数据集规模对算法影响 (Nursery)
6.3 不同数据集比较
图4中我们对提出的H-CLONALG和AIS-AC算法[10]、msCAB算法做了比较。数据集Adult和Digit已经被分割为训练集和测试集,我们可以直接使用。数据集Letter和Nursery没有被分割,我们随机将其分割为训练集和测试集。分别执行以上三种算法来作对比。msCBA算法是基于Apriori算法的关联分类算法。执行中,将AIS-AC算法的种群规模设置为100,最大进化代数设置为50,克隆率和多样性引入规模都设置为20。覆盖度门限设置为98%。在算法H-CLONALG算法的执行中,参数t,1-δ分别设置为5,0.8。其他参数与AIS-AC相同。分别运行以上算法10次,图4中给出了运行结果的对比图。从运行结果来看,当数据集规模较大时,H-CLONALG算法的运行时间要明显低于AIS-AC算法和msCBA算法的运行时间。理论上讲,H-CLONALG算法和AIS-AC算法的相对运行时间的极限为1/t。然而,实时上,在针对以上四个数据集的比较中可以看出,这两种算法的运行时间差距远没有理论分析的那么大。这是因为,针对不同的数据集,随机变量的分布是不同的,相对运行时间的极限在实际中是不可能达到的,只能不断接近。一般来说,数据集规模越大,两种算法运行效率的差距就越明显。两种算法的精度是很相似的。对不同的数据集,得到的精度略有不同。但是,总的来说,两种算法分类精度是很接近的。

图4 针对不同数据集算法性能
7 结论
对于传统的关联分类算法而言,尽管对于不同的数据集它们具有不同的执行性能,但是没有哪种算法从根本上比其他算法更优越[4-5]。特别是当支持度门限被降低时,它们都表现出近似的行为: 候选的频繁项呈指数增长[6-7,11]。这将导致运行时间的指数增长。然而,对于提出的H-CLONALG算法而言,由于算法以一定概率保证下的估计方式来计算亲和力,所以,当支持度阈值降低时,算法的运行时间并没有明显的变化。
基于理论和实验分析表明,本文提出的H-CLONALG算法能保证关联分类的正确性,并有效地提高分类器的构造速度。特别是针对规模较大的数据集的关联分类问题。我们下一步的工作重点为,分析该框架的通用性,将不同算法纳入到该算法框架下来,并提高其运行速度。
[1] T. S. Lim, W. Y. Loh, Y. S. Shih. A comparison of prediction accuracy, complexity and training time of thirty-three old and new classification algorithms [J]. Machine Learning, 2000, 40(3): 203-228.
[2] J. Han, J. Pei, Y. Yin. Mining frequent patterns without candidate generation[C]//Proceedings of 2000 ACM SIGMOD Intl. Conf. Manage Data, 2000: 1-12.
[3] W. Li, J. Han, J. Pei. CMAR: Accurate and efficient classification based on multiple class association rules[C]//Proceedings of the IEEE Int’l Conf. on Data Mining (ICDM01),2001: 369-376.
[4] R. Agrawal, R. Srikant. Fast algorithms for mining association rules[C]//Proceedings of 20th Int. Conf. Very Large Data Bases(VLDB),1994: 487-499.
[5] A. A. Freitas. Understanding the crucial differences between classification and discovery of association rules: A position paper[J]. SIGKDD Explor.Newsl.,2000,2(1):65-69.
[6] D. R. Carvalho, A. A. Freitas, N. F. Ebecken. A critical review of rule surprisingness measures[C]//Proceedings of 4th Int. Conf. Data Mining,2003: 545-556.
[7] B. Liu, H. Hsu, Y. Ma. Integrating classification and association rule mining[C]//Proceedings of 4th Int. Conf. Knowledge Discovery Data Mining, 1998: 80-86.
[8] B. Liu, Y. Ma, C.K. Wong. Classification using association rules: Weaknesses and enhancements[M]. Data Mining for Scientific and Engineering Applications, R. L. Grossman, C. Kamath, P. Kegelmeyer, V. Kumar, and R.R.Namburu,Eds.Berlin,Germany:Springer-Verlag,2001.
[9] X. Yin, J. Han. Cpar: Classification based on predictive association rules[C]//Proceedings of 2003 SIAM Int. Conf. Data Min.(SDM’03),2003.
[10] Tien Dung Do, Siu Cheung Hui, Bernard Fong. Associative classification with artificial immune system[J]. IEEE transactions on evolutionary computation, 2009,13(2):217-228.
[11] G.Yang, S.Mabu, K.Shimada, et al. A New Associative Classification Method by Integrating CMAR and An Evolutionary Three-layers Structure[C]//Proceedings of ICROS-SICE International Joint Conference 2009 August 18-21, Fukuoka International Congress Center, Japan, 2009:2920-2925.
[12] W. Hoeffding. Probability inequalities for sums of bounded random variables [J]. Journal of the American Statistical Association, 1963,58:13-30.
[13] F. M. Burnet. The Clonal Selection Theory of Acquired Immunity. Nashville [M]. TN: Vanderbilt Univ. Press, 1959.
[14] M. C. Nussenzweig. Immune receptor editing revise and select [J], Cell, 1998, 95(7): 875-878.
[15] L. N. de Castro, F. J. Von Zuben. Learning and optimization using the clonal selection principle[J]. IEEE Trans.Evol.Comput., 2002, 6: 239-251.
[16] D. J. Newman, S. Hettich, C. Blake, et al. UCI Repository of Machine Learning Databases. Berleley[R]. CA: Dept. Information Comput. Sci., University of California, 1998.
