和谐社会评价指标的筛选方法研究
2010-10-21张启銮王晓洁
张启銮,王晓洁
(大连理工大学 管理学院,辽宁 大连 116024)
0 引言
只有科学合理的社会评价指标体系,才有可能得出全面准确的社会发展评价结论,评价过程中评价指标的选取是否合理,直接影响评价结果的准确性。因此如何科学地选择指标,构建指标体系,是进行和谐社会发展评价研究中首先要解决的问题。
目前国际权威机构可持续发展指标体系中具有代表性的有联合国可持续发展委员会设计的指标体系[1],世界银行衡量可持续发展的新国家财富指标体系[2]。国内具有代表性的有中国社会科学院社会学研究所社会指标课题组设计的指标体系[3]等。以上两类指标体系虽然权威性强,但是偏向于从宏观层面对各个国家社会发展综合情况的评价,不适合同一国之内不同地区微观层面的评价。而学术文献整理得出的指标评价体系中具有代表性的是Fuentes N.和Rojas M社会指标解读[4],Adam Mellows设计的社会指标体系[5]等。这类体系的指标在反映同一社会信息时采用多个重复指标,指标体系过于庞杂。
现有社会评价指标体系的筛选可分为两类。一类是根据专家经验主观确定社会评价指标体系,如李莉[6]等通过主观经验确定城市可持续发展指标体系。这类方法的弊端是指标的选择受人为影响较大,易于出现“仁者见仁,智者见智”的情况。二是客观筛选方法。如兰国良[7]利用主成分分析法对城市可持续发展的社会经济评价指标进行了筛选;欧阳建国[8]等利用因子分析法选取中国各地区可持续发展的指标。此类方法易受选择样本数据的影响,并且完全依靠数据确定指标,忽略了指标的实际含义。
由此,本文提出首先定性的海选和初选指标;然后将信息熵约简法和相关性分析方法相组合,实现对指标的定量筛选;再根据科学发展观的要求对用定量方法得到的指标体系进行定性的补充和完善;最终建立科学的社会评价指标体系,并通过实证检验,确认为较为理想的结果。
1 和谐社会评价指标筛选的原理
1.1 指标的定量筛选思路
(1)通过信息熵约简法删除对准则层区别能力小的指标,保证指标对社会评价具有高度影响。
(2)通过相关性分析删除各准则层内相关系数大的指标,避免指标之间信息重复。
1.2 指标筛选前的数据标准化
1.2.1 正(负)向指标规范化
设xij为第j个评价对象第i个指标的隶属度;vij为第j个评价对象第i个指标的值;n为被评价对象的个数。根据正向指标的规范化公式[9],xij为:

负向指标规范化公式只是分子为最大值减去第i个指标值。式(1)表示第j个评价地区第i个指标值与该指标最小值的偏差相对于该指标最大值与最小值偏差的比重,比重越大标准化后值越高。
1.2.2 适中指标规范化
设 xij、vij的含义同前文,vij0为第 j个评价对象第i个指标理想值,则xij为:

中华人民共和国国民经济和社会发展第十一个五年计划纲要[16]中指出,人口自然增长率“十五”年均增长率为6.3‰,而“十一五”时期的主要预期目标为小于8‰。因此,本文确定7.2‰为人口自然增长率的理想值。
1.3 信息熵约简法的原理
对于给定的j,xij(i=1,2,…,n)的差异越大,则指标准则层的比较作用就越大,也即它所包含和传输的决策信息就越多,信息熵可被用来度量这种强度的大小。
首先,设 xij(i=1,2,…,n;j=1,2,…,m)为第 i个准则层中的第j项指标的观测数据,根据熵值计算公式[10]:第j个评价指标的熵值:

其次,第j个评价指标的区分能力量度wj’的定义为:

各准则层的评估值相差越大,指标对于准则层的比较作用就越大,即指标的区分能力就越强,所以将各准则层下区分能力小的指标进行删除。此方法是为了删除所在准则层中对评价结果影响很小的指标,以实现对指标体系的约简。
1.4 相关性分析方法
指标的相关性是刻画指标与指标间信息重复程度大小。如果两个指标之间存在一定的相关性,这种相关性会导致被评价对象信息的重复使用,从而降低评价的科学性和合理性。相关系数越大,这个指标越容易被其他指标所替代。相关性分析就是剔除相关系数较大的指标,也即可以被其他指标所替代的指标。
首先,计算各个评价指标之间(xij)的相关系数Rij[11](其中,Zij为指标的标准化值)。
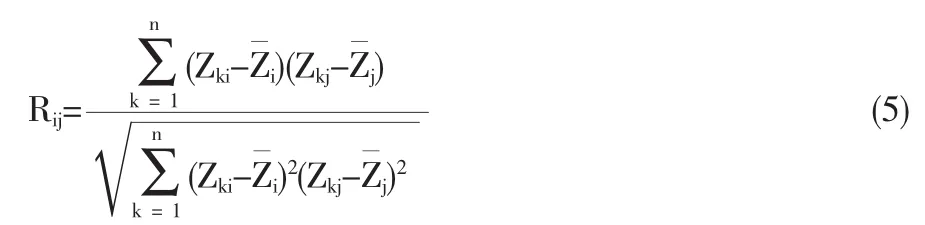
其次,考察指标与同层内余下所有指标的相关系数,并规定一个临界值M(0<M<1)。如果Rij>M,则可以删除这一评价指标。
本文选取临界值0.9,这样可以达到用较少的指标反映指标集90%以上的信息,从而简化指标体系。
将熵值约简法与相关性分析相结合的差别及特色在于:首先利用熵值约简法删除对准则层区别能力小,也即对评价结果没有显著影响的指标。然后利用相关性分析将同一准则层内相关系数大的指标剔除,保证指标信息的不重复。两者结合保证筛选出的指标不重复且对评价结果有显著影响。
1.5 指标体系构建合理性的判定标准
根据某些分析方法用数据方差表示指标信息含量的方法,本文提出建立指标体系构建合理性的判定标准,认为如果用30%以下的指标反映了90%以上的海选指标信息,则认为指标体系构建成功。
设:S为原始指标数据的协方差矩阵;trS为协方差矩阵的迹,表示协方差矩阵的主对角线上各指标方差之和;s为筛选后的指标个数;h为海选指标的个数。则筛选后的指标对海选指标的信息贡献率In为[12]:

式(6)的含义是筛选后的s个指标的方差之和trSs占海选的h个指标的方差之和trSh的比值,表示s个筛选后的指标所反映的h个海选指标的信息。此方法解决了指标体系构建合理性缺乏定量判定标准的问题。
2 实证分析
2.1 社会评价指标的海选和定性初选
本文选取12个省区作为样本,包括山东、辽宁等沿海地区;河南、山西等内陆省份;广东、上海等经济发达地区;黑龙江、四川等经济欠发达地区;北京、陕西等汉族为主的地区;广西、云南等少数民族集中的地区。易知,此样本又涵盖了东、中和西部地区,可反映我国社会发展的一般状况。
社会评价指标筛选的原始数据均来源于相关省 (市)的2007《统计年鉴》[15]、2007《中国统计年鉴》[17]和有关地区统计局网站上的数据。
根据以人为本,全面、协调与可持续发展和科学发展内涵,以权威机构的典型文献[1~3]和社会综合评价指标体系的相关文献[4~8]为基础,海选了涉及社会发展评价的共计72个指标。然后,根据同类指标信息最优原则选择同类指标中信息量大的指标,根据可观测性原则删除数据无法获得的指标,以保证初次筛选后的指标体系可以量化,定性初选后的指标共50个。
2.2 数据预处理
2.2.1 国民幸福指数
国民幸福指数是衡量人们对自身生存和社会发展状况的主观感受和体验的指标[14],反映了人们生活的幸福感以及社会发展的和谐程度。但无论是权威机构,还是发达国家官方的社会评价,国民幸福指数都没纳入现有社会评价体系。本文根据以人为本原则设置“国民幸福指数”,是国家监控经济社会运行态势、了解人民生活满意度、设立政绩考核标准中必不可少的部分,也更能准确地检验社会发展的综合水平。
设:GNH[13]为国民幸福指数;S为收入的增长率;G为基尼系数;U为失业率;I为通货膨胀率。则

将计算国民幸福指数的数据[15][17]代入式(7),即得到各省的国民幸福指数。
2.2.2 指标规范化
利用公式(1)、(2)对初选后的数据分别进行规范化处理,结果如表1所示。
2.3 信息熵约简和相关性分析对指标的筛选
⑴利用EXCEL对定性初筛保留的指标进行信息熵的约简分析。从定性初筛的50个指标中集中删除了人均储蓄存款余额等24个指标。

表1 社会评价指标筛选原始数据及标准化数据
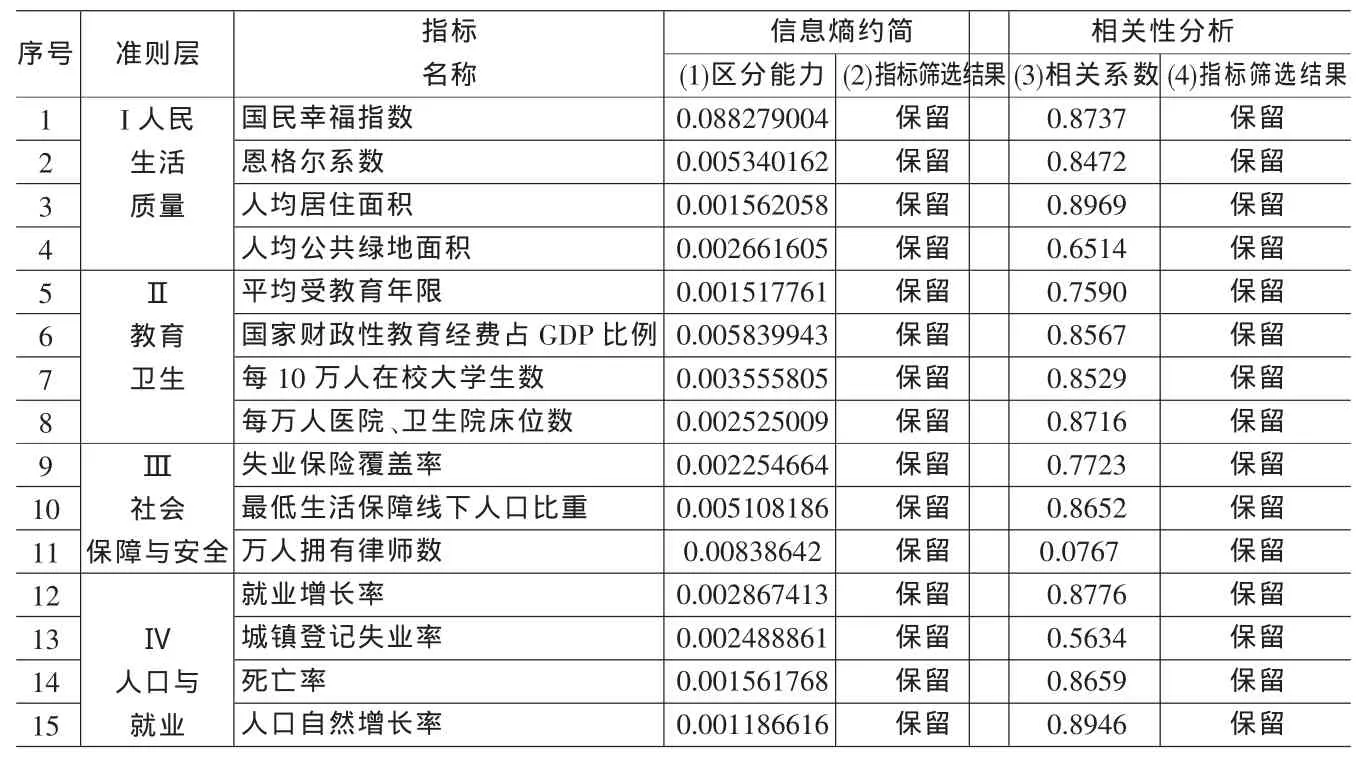
表2 指标筛选的信息熵分析和相关性分析
⑵使用SPSS软件13.0计算经过信息熵约简筛选后剩余各准则层内指标的相关系数。给定临界0.9,删除相关系数大于该临界值的11个指标。
综上所述,经过定量组合筛选指标后,指标体系由初选后的50个指标缩减到15个指标。定量筛选的最终结果如表2。
2.4 定性分析对指标体系的完善
由于定量方法主要依据数据的变动大小来删除指标,会导致将重要指标由于数据变化不明显而被删除,无法反映全面与协调发展的科学发展观内涵。因此,在定量筛选指标的基础上本文根据权威机构典型文献的高频率原则,以人为本的原则,全面、协调、可持续发展原则补充定量方法剔除的个别指标,实现对指标体系的完善。通过理性分析保留准则层Ⅰ中的居民消费价格指数、城镇居民人均可支配收入;准则层Ⅲ中的养老保险覆盖率、每10万人交通死亡数等指标。通过以上方法从72个海选指标中筛选了包含19个指标的和谐社会评价指标体系,见表2。
2.5 指标体系构建合理性的判定
根据指标原始数据计算各指标的方差,将筛选后的指标方差之和trSs和海选指标的方差之和trSh代入式(6),得到:

即从海选指标集中筛选出26.34%(19/72=26.34%)的指标反映了98.4%的原始信息,证明所构建的指标体系是合理的。
3 结论
综合评价指标的筛选单纯依靠主观方法或客观的统计学方法都是欠科学的。本文采用定量筛选和定性分析相结合的方法筛选指标,既保证了筛选出的指标在所在准则层中对评价结果影响最大,又避免了同一类指标的信息重复;本文所加入的国民幸福指数指标,能准确地检验社会发展的综合水平,体现以人为本的原则;根据用方差表示信息含量的思路,将筛选后的指标反映的海选指标信息含量作为指标体系构建合理性的判定标准,解决了指标体系的合理性判定缺乏定量标准的问题。实证分析表明,最终建立的指标体系,用26.34%的指标反映98.4%的原始信息,体现了科学发展观的内涵,符合和谐社会发展的基本要求。相信在此指标体系的基础上对和谐社会进行评价,将具有客观性、全面性和系统性。
[1]World Commission on Environment and Development(WCED).The Brundtland Report,Our Common Future[M].Oxford:Oxford University Press,1987.
[2]World Bank.Monitoring Environment Progress[M].WashingtonD.C:The World Bank Press,1995.
[3]中国社会科学院社会学研究所.社会发展与社会指标研究资料[M].北京:中国社会出版社,1991.
[4]Fuentes N,Rojas M.Economic Theory and Subjective Well-being:Mexico[J].Social Indicators Research,2001,53(3).
[5]Adam Mellows.Social Indicators[R].London:House of Commons Library,2004.
[6]李莉,吴洁,岳超源.城市可持续发展指标体系及综合评价研究(二).武汉城市建设学院学报,2000,17(3).
[7]兰国良.可持续发展指标体系构建及其应用研究[D].天津大学博士学位论文,2004,(5).
[8]欧阳建国,欧晓万.中国各地区可持续发展主要影响因素的定量研究[J].决策研究,2005,(6).
[9]李美娟,陈国宏,陈衍泰.综合评价中指标标准化方法研究[J].中国管理科学,2004,(6).
[10]朱梅红,李爱华.基于熵权的中国西部各省份科技实力综合评价[J].数学实践与认识,2006,(12).
[11]胡永宏.综合评价中指标相关性的处理方法[J].统计研究,2002,(3).
[12]余锦华,杨维权.多元统计分析与应用[M].广州:中山大学出版社,2006.
[13]程国栋,徐中民.建立中国国民幸福生活核算体系的构想[J].地理学报,2005.11,60(6).
[14]国民幸福指数[EB/OL].http://baike.baidu.com/view/635709.htm,2007.3.26.
[15]北京、上海等12个省的《统计年鉴2007》[M].北京:中国统计出版社,2008.
[16]第十届全国人民代表大会第四次会议.中华人民共和国国民经济和社会发展第十一个五年计划纲要[EB/OL].http://politics.people.com.cn/GB/59496/4208562.html,2006.3.14
[17]国家统计局.中国统计年鉴2007[M].北京:中国统计出版社,2008.
