利用条件随机场实现中文病历文本中时间关系的自动提取
2010-09-18周小甲李昊旻段会龙吕旭东
周小甲 李昊旻 段会龙 吕旭东
(浙江大学生物医学工程与仪器科学学院生物医学工程教育部重点实验室,杭州 310027)
利用条件随机场实现中文病历文本中时间关系的自动提取
周小甲 李昊旻*段会龙 吕旭东
(浙江大学生物医学工程与仪器科学学院生物医学工程教育部重点实验室,杭州 310027)
从临床病历文本中自动提取医学问题的相关时间属性可以服务于诸如临床决策支持、数字化临床路径等多种医疗信息应用,因此在医学语言处理领域,面向病历文本的时间信息自动提取研究在国际上已开展多年,而中文环境下的相关研究仍属空白。本研究提出了一种基于条件随机场(CRF)的时间关系自动提取算法实现了中文医学病历文本中面向医学问题的时间属性自动提取。该机器学习方法以经过医学问题和时间信息语义标注的病历文本为训练内容,时间关系结果标注采用以医学问题为中心的模式,即仅提取所关心医学问题的时间属性。在此方法框架下通过实验,重点分析了不同的CRF学习模板对于时间关系提取的影响,实验以63份实际病历作为实验文本,以多次交叉验证的方式获得不同学习模板情况下时间关系自动提取准确率的平均值,通过分析实验数据总结了CRF学习模板设计的一般规律,实验中最佳模板情况下时间关系提取正确率可达86.94%,这些结果将为后续研究提供基础。
信息提取;时间关系;条件随机场;医学语言处理
引言
时间作为事件信息的重要组成部分,在文本记录中所占比重平均约为27%,仅次于专有名词[1],面向时间关系的信息提取(information extraction)研究已经广泛开展[2],然而多数的研究都针对特定问题,缺乏有效统一的解决方法。在医学领域中,时间信息同样以非常高的频率出现在临床文本中。随着临床决策支持等临床信息技术应用对于临床信息获取需求的不断增加,利用计算机从临床文本中自动提取临床信息成为医学信息学研究的一个热门研究领域[3~5]。其中对于时间及其关联临床事件的自动提取,可以服务于诸如临床路径、临床决策支持等应用[6],甚至可以服务于疾病发展模式的挖掘,帮助医生及研究者理解和认识动态的医学现象[7],因而在医学领域中的时间信息提取的自然语言处理研究受到越来越多的关注[8-9]。哥伦比亚大学Zhou等开发的TimeText系统在基于病历文本提取时间信息研究中 具有代表性[10-11],它基于MedLEE英文医学语言处理系统[12],提出一套处理临床病历中时间信息的结构框架,其中利用大量术语库和语法规则库等实现了英文病历文本中时间关系的提取。虽然中文环境下的时间信息提取研究已有所开展[13-14],但是面向医学临床文本,服务于医疗信息化的同类研究仍处空白。
实现病历文本中时间关系的自动提取属于信息提取研究范畴[15],目前广泛应用的信息提取方法可以分为两种:基于规则的方法和自动学习方法,基于规则方法主要靠手工编制规则,使其可以处理特定知识领域的信息提取问题,这些规则往往依赖于具体语言、领域、文本格式,难以达到很高的语言覆盖面。自动学习方法主要基于机器学习理论通过对标记好的语料库的学习,训练各种机器学习模型,并基于该训练模型实现对于信息特征的提取。近年来,研究者更侧重于利用机器学习方法增强系统的可移植能力[16]。
本研究基于条件随机场提出了一种面向中文病历文本的时间关系自动提取方法,该方法以医学问题为中心,从临床文本中自动提取指定医学问题的时间属性信息,可以服务于临床决策支持等应用,对于解决目前临床决策支持应用过程中临床信息获取困难的问题具有重要意义。
1 条件随机场
条件随机场是基于统计的序列标记识别模型,是一种最大化条件概率的无向图模型,2001年由John Lafferty等首次提出[17]。条件随机场中给定输入序列 x=(x1,…,xn) ,它的状态序列 y=(y1,…,yn)的条件概率是势函数(potential function)乘积的归一化形式,每个因子的形式为
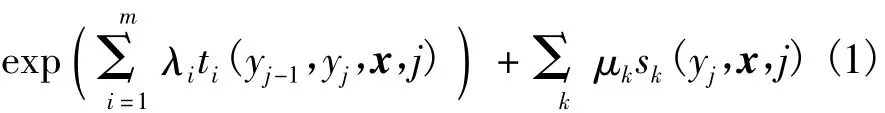
式中,ti(yj-1,yj,x,j) 为整个观测序列位置 i以及 i-1标记的特征函数,sk(yj,x,j)是位置i的标记和观测序列的状态特征函数,λi和μk是特征权重,可以从训练语料中估计得到。特征函数只有在判断正确的时候为1,其他情况下为0。又令:
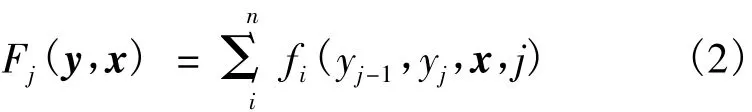
式中,特征函数 fi(yj-1,yj,x,j) 可以是状态特征函数sk(yj,x,j) ,也可以是转移特征函数 ti(yj-1,yj,x,j),因此给定输入序列为x=(x1,…,xn)的状态序列y=(y1,…,yn) 的条件概率是

其中Zλ(x)是归一化因子,

求解序列标注任务就是求pλ(y|x)的最大值Y*:

使用Viterbi等动态优化方法可求得最优解Y*。CRF避免了隐马尔可夫模型(hidden Markov model,HMM)的独立性假设,解决了最大熵模型(Maximum Entropy,ME)所带来的标记偏见问题,不像ME在每一节点都要进行归一化,而是对所有特征进行全局归一化,可以求得全局的最优值,因此在自然语言处理领域的众多序列化标注任务中得到广泛应用[18-19]。
2 中文病历文本中的时间关系提取
本研究关注于临床文本中的各种症状、检查异常以及诊断(为了方便本文将这些统称为“医学问题”)与明确时间的关系提取,在病历文本中医务工作者会记录这些医学问题发生和持续的时间,或者问题发生改变(如症状恶化、缓解或消失等)的时间和持续时间。借鉴人工智能时间推理等时间表示研究领域的相关研究成果[20],结合医学领域信息利用需求,将病历文本中的时间信息分为两类:时间点和时间段,并定义了如表1所示的医学问题时间属性标签。

表1 医学问题的时间属性标签Tab.1 Temporal attribute tags of medical problem
为自动提取这类时间属性,建立了如下图1所示的处理流程,首先利用各种医学语言处理技术实现对于病历文本中医学问题和时间信息的自动语义标注,然后以医学问题为中心的模式对其进行手工时间关系标注,形成CRF训练语料,最后根据训练语料中时间与问题之间的规律,设计CRF学习模板,使用学习模板通过训练获得CRF模型,基于生成的CRF模型可以实现对时间关系的自动提取。图中P-O表示与关心医学问题无关的时间信息;NR表示不相关信息;CLAUSE表示分句标记。下面结合本文所做实验,对时间关系自动提取流程进行详细介绍,并对实验结果进行分析。

图1 关系提取流程Fig.1 The procedure of the relation extraction
2.1 语义标注
语义标注(semantic tagging)的目的是为特定上下文的语言表述赋予一定的语义描述,自动语义标注在构建大型语料库[21]、信息检索[22]和信息提取等研究中具有重要意义。根据应用需要,语义标注可以在词汇、句子和文本不同层次上进行,本研究的语义标注是在词汇和短语层面上进行的。在通用语言领域,基于机器学习的自动语义标注方法是主流方式,而在子语言领域基于带语义注释的术语知识源进行语义标记显示出更好的实用性[23]。对于医学问题的语义标注依赖于建立的一个具有语义注释的医学术语库,采用反向最大匹配法来实现。由于采用面向问题的时间关系提取,因此在所有标记为症状、诊断和检验结果等的语义类型中,每次样本提取都选择特定医学问题标注为P(即关心的问题),其他标注为OP(即其他问题)。由于本研究要提取的时间属性包括了对于问题变化所关联的时间信息,因此一些病历文本中,描述问题变化的词语(如:“加重”、“缓解”、“停止”)等也被添加到带语义注释的医学术语库中,这类词分别标记为:C-M代表恶化或增加;C-L代表改善或减少;C-C代表消失或结束。对于时间信息的语义标注就是寻找时间短语并分配时间点(TP)或者时间段(TD)类型,相关研究表明正则表达式具有非常强大的时间信息模式匹配能力[24],从大量实际病历文本中总结出相关正则表达式,在实验中表现出良好效果。受篇幅限制以及本文重点不在于此,对于语义标注过程的细节不再赘述。
2.2 语料准备
实验采用crf++[25]作为条件随机场算法执行工具。用于crf++工具对于训练和实验语料的输入格式具有特定要求:每行数据作为一个标记(token)必须包含相同的列数,每个病历语句由多行标记组成,中间用空行隔开以区分句子的边界。本研究侧重于时间关系提取部分的研究,所以对语义标注结果进行人工的检查和修正,并面向医学问题从语义标注好的语料中提取样本自动转换为相应的格式。作为一种监督的机器学习方法,还需要手工按照表1所示类型为训练数据标注正确的时间关系,最终形成的训练语料中第一列数据是原始文本分解后的信息,第二列数据是相应的语义标注,第三列是用于crf++学习的时间关系标注正确结果。本研究的实验数据选取了63份覆盖30多个科室的入院记录或者大病历文本,通过上述方法对所选病历进行时间和医学问题的语义标注,并自动生成病历文本中所包含的医学问题列表,选取列表中一个医学问题后,整份病历中所有包含此医学问题的语句将自动显示,挑选出其中包含时间信息语句作为实验语料,本实验最终筛选出319个病历语句作为实验数据,对其中所包含医学问题和时间信息的个数统计如表2所示。

表2 语料统计信息Tab.2 The statistic of corpus
2.3 模板准备
在CRF方法学习过程中,设计适当的特征模板可以引导算法利用合适的上下文信息,以取得良好的学习效果。在crf++工具的模板文件中,每行代表一个特征模板,每个特征模板用专门的宏%x[row,col]确定输入数据中的一个标记,row代表与当前标记的相对行数,col代表绝对列数,从0开始计数,如%x[2,1]表示距当前标记相对行数为2、第一列的标记。crf++针对每个特征模板生成多个特征函数,利用当前标记的特征对特征函数赋予0或1,同时改变特征函数的权值。模板文件中可以有多维的复合模板,即由多个上下文相关标记共同作为一个特征模板,用于CRF算法的学习。
通过对语料标注结果的统计得出一些临床文本表达时间与医学问题的常用模式,如表3所示。其中“窗口跨度”代表时间信息与相关联医学问题标记之间存在的上下文跨度,体现了时间关系提取过程中所需要的上下文信息,“0”对应标注结果中的时间信息,其他数字代表标注结果相对于此时间信息的相对偏移量,如“-1”代表当前时间信息的前一个标注对象。
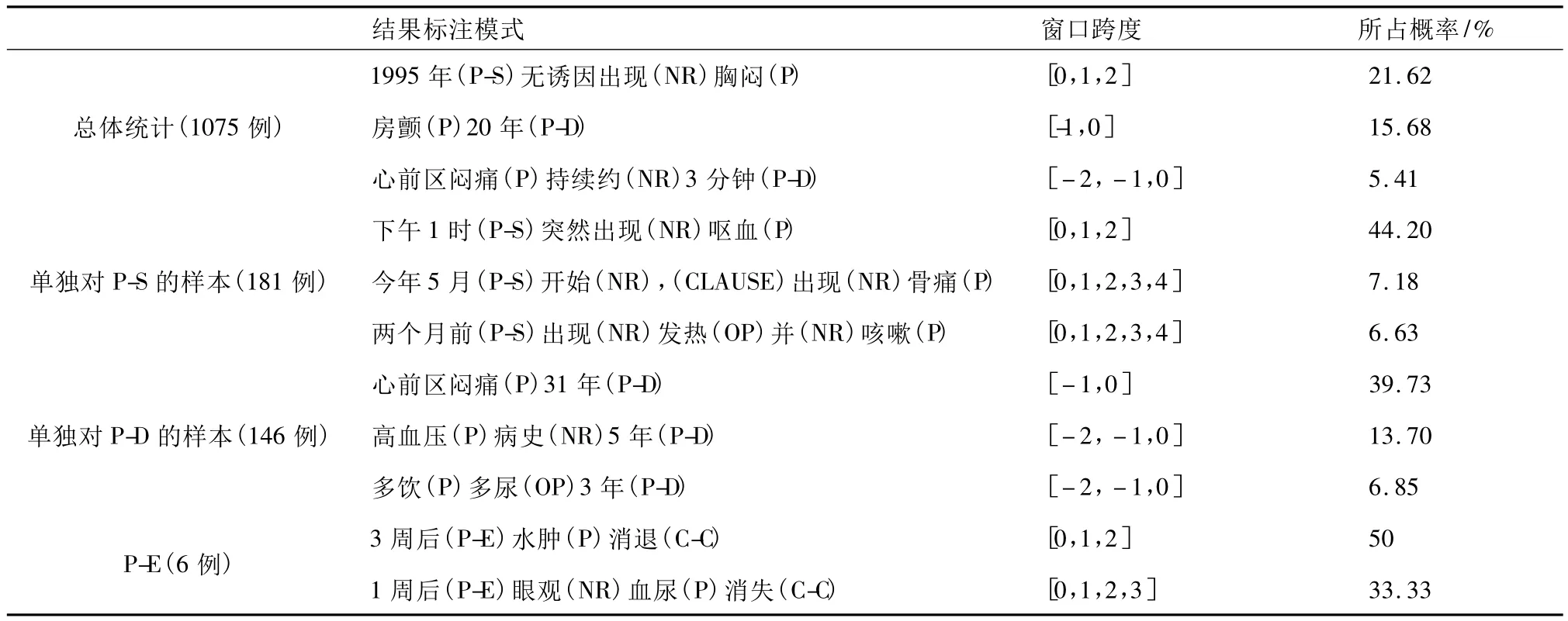
表3 常见时间关系模式Tab.3 Frequency temporal relation pattern

表4 模板文件Tab.4 Template files
模板设计过程中,理论上利用的上下文信息越丰富,则机器学习方法可以寻找出更多蕴涵的语言特征,产生较好的提取效果,但如果所利用上下文信息跨度过大,会降低机器学习的效率,还有可能出现过拟合现象,反而降低提取效果。
CRF方法以语义标注列为特征学习列,基于表3统计结果和模板选择原则,一维原子模板选取距当前标记距离为4的上下文标记,多维复合模板为原子模板的组合,由表3得出的二维复合模板为%x[0,1]/%x[2,1]、%x[0,1]/%x[3,1]、%x[0,1]/%x[4,1]、%x[-2,1]/%x[0,1]。高维特征能把握更多的长距离依赖关系,但也需要更大的训练开销,并带来更严重的数据稀疏问题,所以本文最高维设定为4维。为方便讨论,把不连续的多维特征称为跳跃特征。
为了研究CRF学习模板对于其提取效果的影响,设计了如表4所示的6种较有特点的模板文件。为表示方便,利用A、B分别代表两组不同的一维原子模板,A 代表%x[-4,1]到%x[4,1]的 9 个原子模板,同1号模板文件中所有一维模板;B只比A缺少%x[4,1]模板,同 2号模板文件中所有一维模板。
3 实验
crf++利用用户设定的模板文件对以上标注语料进行训练学习,学习结果以模型文件(model file)形式输出,利用生成的模型文件crf++可以自动在测试数据每行的最后一列标注出相关时间关系信息,实现对病历文本中时间关系的自动标注。本文实验的目的是验证CRF机器学习方法在时间关系提取方面的效果和找出CRF在中文时间关系提取过程中模板选择的规律。
实验中首先将319句标注好的语料资源随机分为5组,然后采用5折交叉验证(5-fold cross validation)方法分别对不同的特征模板进行评测获得算法时间关系标注的准确率(即时间关系标注正确个数与标注为时间的标记总数之间的比值),为了降低训练和测试数据对于模板效果的影响,这样的实验共进行了10次,然后将10次实验准确率的平均值作为评价模板的依据。表4所述的6类模板的最终评测结果如图2所示。
4 结果讨论
从图2中分析可得,基于CRF自动提取病历文本中医学问题的时间属性的准确率基本可以达到80%以上,使用6个模板中的最优模板,与时间点相关的时间关系提取正确率可达84.97%;与时间段相关的时间关系提取正确率可达89.43%;与全部时间信息相关的时间关系提取正确率可达86.94%。这样的自动提取效果虽然不能满足完全自动信息获取,但在一些辅助信息录入应用中已经具有显著的应用潜力。

图2 不同模板下的时间关系提取结果Fig.2 The results of temporal relation extraction using different templates
本研究是在较小语料环境下开展的,因此一些机器学习方法的通常弊端也在结果中显现,一些错误标注是由于训练数据的不完备造成数据稀疏问题引起的,还有一些错误是由于本身自然语言描述过程中相关信息之间的距离过长,超出了机器学习所提供的模板长度,使得提取失败,另外病历文本中存在部分不明确的时间表达关系,也给人工标注关系和自动判断带来了困难。
如图2所示,随着特征模板复杂性的增加,准确率整体上呈现上升趋势,但其中还蕴含了一些有趣的现象:模板2相比模板1缺少了%x[4,1]特征模板,准确率却比模板1略高,由此分析此特征模板在模板文件1中可能引起了过拟合现象,然而模板6与模板5相比,同样缺少%x[4,1]特征模板,但因缺少此模板引起准确率的下降,这些结果表明某个特定模板是否引起过拟合现象不仅在于训练语料的特点,亦和模板文件中各模板之间的关系相关;模板4和模板3相比正确率有明显提升,可见相邻的上下文特征有更好的学习效果;模板3虽然比模板1增加了三维和四维特征模板,但时间点的关系提取正确率明显降低,说明增加的多维跳跃特征引起了与时间点相关的规则学习混乱,多维跳跃特征不利于时间点相关的规则学习;模板5将模板4中的8个二维相邻特征改为4个跳跃特征,性能有所提高,显示出模板4中的二维相邻特征效率低下,由表3统计所得的跳跃特征更能抓住时间关系提取的特征。
综上分析,认为以文本语料所得的常见时间关系模式是二维特征模板设计的重要依据;更高维的特征模板选取连续的上下文特征有利于规则的学习;某个特征模板是否产生过拟合现象不仅取决于训练语料,也与模板文件中各模板之间的关系相关。
5 结论
在我国医疗信息化开始逐步转向临床,各类临床支持信息系统开始走入应用的大背景下,研究中文环境下的病历文本中的关系信息自动提取具有非常现实的价值,在中文医学语言处理规则解析尚缺乏基础的前提下,本研究提出的这一套面向医学问题的时间关系自动提取框架,具有了相当的应用潜力,在后续的研究中,会结合实际的应用需求对该方法进行优化实现。同时所提出的框架也可以应用于中文环境下的其它关系信息提取,而本研究对基于CRF的信息提取方法中的特征模板评测和规律总结,也为后续相关研究提供了很好的参考。
[1] 王昀.金融领域中汉语时间信息提取的研究[D].北京:清华大学计算机科学与技术系,2004.
[2] Xiao Ling,Weld DS.Temporal information extraction[A].In:Cohn A.ProceedingsoftheTwenty-FourthConferenceon Artificial Intelligence(AAAI-10)[C].Atlanta:GE,2010.156-161.
[3] Xu Hua,Stenner SP,Doan S,et al.MedEx:a medication information extraction system for clinical narratives[J].Journal of the American Medical Informatics Association,2010,17(1):19-24.
[4] Demner-Fushman D,Chapman WW,McDonald CJ.What can natural language processing do for clinical decision support?[J].Journal of Biomedical Informatics,2009,42(5):760-772.
[5] Meystre SM,Savova GK,Kipper-Schuler KC.Extracting information from textual documents in the electronic health record:a review of recent research[J].Yearb Med Inform,2008,47(1):128-144.
[6] Augusto JC.Temporal reasoning for decision support in medicine[J].Artificial Intelligence in Medicine,2005,33(1):1 -24.
[7] Savova G,Bethard S,Styler W.Towards temporal relationdiscovery from the clinical narrative[A].In:Lucila OM,eds.AMIA 2009 Annual Symposium Proceedings[C].San Francisco:AMIA Symposium,2009.568-572.
[8] Moskovitch R,Shahar Y.Medical temporal-knowledge discovery via temporal abstraction[A].In:Lucila OM,eds.AMIA 2009 Annual Symposium Proceedings[C].San Francisco:AMIA Symposium,2009.2-6.
[9] Gaizauskas R,Harkema H,Hepple M,et al.Task-oriented extraction of temporal information:the case of clinical narratives[A].In: MontanariA.Proceedings ofthe Thirteenth InternationalSymposium on Temporal Representation and Reasoning[C].Budapest,Hungary:IEEE Computer Society,2006.188-195.
[10] Zhou Li,Friedman C,Simon P.System architecture for temporal information extraction,representation and reasoning in clinical narrative reports[A].In:Friedman CP,eds.Proceedings of the 2005 AMIA Annual Symposium[C].Austin:AMIA Symposium,2005.869-873.
[11] Zhou Li,Melton GB,Parsons S.A temporal constraint structure for extracting temporal information from clinical narrative[J].J Biomed Inform,2006,39(4):424 -439.
[12] Friedman C.A broad-coverage natural language processing system[A].In:Overhage JM,eds.Proceedings of the 2000 AMIA Annual Symposium[C].Los Angeles:AMIA Symposium,2000.270-274.
[13] Li Wenjie,Wong Kamfai.A word-based approach for modeling and discovering temporalrelations embedded in Chinese sentences[J].ACM Transactions on Asian Language Information Processing(TALIP),2002,1(3):173 -206.
[14] Li Wenjie,WongKamfai,YuanChunfa.Towardautomatic Chinese temporal information extraction[J].Journal of the American Society for Information Science and Technology,2001,52(9):748-762.
[15] Hobbs JR.The generic information extraction system[A].In:Sundheim B,eds.Proceedings of the 5th Conference on Message Understanding[C].Baltimore:Association for Computational Linguistics,1993.87 -91.
[16] 李保利,陈玉忠,俞士汶.信息提取研究综述[J].计算机工程与应用,2003,39(10):1 -5.
[17] Lafferty JD,McCallum A,Pereira FCN.Conditional random fields:Probabilistic models for segmenting and labeling sequence data[A].In:Brodley CE,Danyluk AP,eds.Proceedings of the Eighteenth International Conference on Machine Learning[C].Massachusetts:Morgan Kaufmann Publishers Inc,2001.282-289.
[18] Zhao Hai,Huang Changning,Li Mu.An improved Chinese word segmentation system with conditional random field[A].In:Dale R,eds.Proceedings of the Fifth SIGHAN Workshop on Chinese Language Processing[C].Sydney: 2006 Association for Computational Linguistics,2006.162 -165.
[19] Peng Fuchun,McCallum A.Information extraction from research papers using conditional random fields[J].Information Processing& Management,2006,42(4):963 -979.
[20] Zhou Li,Hripcsak G.Temporal reasoning with medical data-A review with emphasis on medical natural language processing[J].Journal of Biomedical Informatics,2007,40(2):183 -202.
[21] Dill S,Eiron N,Gibson D,et al.A case for automated large-scale semantic annotation[J].Web Semantics:Science,Services and Agents on the World Wide Web,2003,1(1):115 -132.
[22] Kiryakov A,Popov B,Terziev I,et al.Semantic annotation,indexing,and retrieval[J].Web Semantics:Science,Services and Agents on the World Wide Web,2004,1(1):49 -79.
[23] Coden AR,Pakhomov SV,Ando RK,et al.Domain-specific language models and lexicons fortagging[J].Journalof Biomedical Informatics,2005,38(6):422 -430.
[24] Amo S de,Daniel A,Furtado.First-order temporal pattern mining with regular expression constraints[J].Data & Knowledge Engineering,2007,62(3):401 -420.
[25] Taku Kudo,CRF++:Yet another CRF toolkit[EB/OL].http://crfpp.sourceforge.net/,2009 -05 -06/2010-04-15.
The Automatic Extraction of Temporal Relation from Chinese Narrative Medical Records Using Conditional Random Fields
ZHOU Xiao-Jia LI Hao-Min*DUAN Hui-Long LU Xu-Dong
(College of Biomedical Engineering and Instrument Science,The Key Laboratory of Biomedical Engineering,Ministry of Education Zhejiang University,Hangzhou 310027,China)
The automatic extraction of temporal attributes related to medical problems from clinical narrative text serves various applications in medical informatics,such as clinical decision support,digital clinical pathway and so on.For this reason,in the domain of medical language processing,studies about automatic temporal information extraction from narrative medical records have been developed abroad for several years.Nevertheless,there is little investigation on Chinese language.This study proposed a solution to automatic extraction of temporal attributes of medical problems from Chinese narrative medical records based on conditional random fields(CRF).In this solution,the medical records were firstly semantically annotated with medical problem and temporal information tags to fulfill the CRF training task.In the labeled training dataset the temporal relationship was tagged based on medical problem oriented mode,that is to say only interested medical problem's temporal attributes were tagged.A further analysis of the impacts of various feature templates of CRF on temporal relationship extraction was taken.A multiple cross-validation method was used to evaluate different CRF learning templates in the corpus including 63 practical narrative medical records.The general principle of template design was proposed.And the accuracy of temporal relationship extraction reached 86.94%with the optimal template file.
information extraction; temporal relationship; conditional random fields; medical language processing
R318
A
0258-8021(2010)05-0710-07
10.3969/j.issn.0258-8021.2010.05.012
2010-05-10,
2010-07-23
国家自然科学基金资助项目(30900329);中国博士后基金资助项目(20090451467)
*通讯作者。 E-mail:Haomin_li@yahoo.com
