统一计算设备架构并行图割算法用于肝脏肿瘤图像分割
2010-09-02李拴强冯前进
李拴强 冯前进
(南方医科大学生物医学工程学院,广州 510515)
引言
肝癌是我国常见的、严重危害人民健康的恶性肿瘤之一,肝脏肿瘤的分割对肝癌早期诊断、术前规划和放疗计划的制定等都有十分重要的作用。目前,用于肿瘤分割的方法主要有模糊聚类方法[1],统计分类方法[2]和基于变分和水平集的方法[3]。由于肿瘤组织和正常组织在图像上的灰度分布有重叠,基于像素或体素的模糊聚类方法和统计分类方法很难区分它们。变分和水平集方法的优化结果容易收敛到局部极值,运算量大,收敛速度慢等缺点都限制了其在实际中的应用。
当前图割理论的研究被人们寄予了广泛的关注,它是一种组合优化方法。在计算机视觉领域中,许多问题能够被表达为能量函数最小化问题。在能量函数的最小化求解中,现有的许多数值求解算法受到较多调节参数的约束,而且往往仅能得到函数的局部最优解。组合优化理论中的图割技术为最优化问题提供了较好的解决思路。Greig等首先运用图割技术来求解计算机视觉问题中的能量最小化问题[4]。在Boykov等人的研究工作之后[5-6],图割技术才被广泛用于最小化低水平视觉问题中的能量函数,如图像分割[7,8]、纹理综合[9]、图像提取[10]、多摄像机的场景恢复[11]及医疗影像等计算机视觉问题[12]。
在过去的几十年里,人们提出了许多新的算法试图改善图割的计算性能,降低计算复杂度。其中包括搜索树[13]、动态图割[14]和主动图割[15]等一系列算法,这些方法在一定程度上降低了计算复杂度,提升了收敛速度,但仍达不到实时处理的要求。人们也尝试将其进行硬件加速,图割算法的并行实现最早见于文献[16],该并行方法是基于扩充路径的搜索算法,文献[17]实现了基于压入重标记的并行图割算法,但这两种并行算法都不是在GPU上实现的。Hussein等第一次在GPU上实现了的图割算法,该方法是借助高级绘制语言和图形API,在较为复杂的图形流水线模式下编程实现的,其运行速度比CPU上还要慢[18]。
近几年来,随着可编程图形处理器(GPU)并行处理能力的大幅提高,以及其可编程能力的快速发展,GPGPU(General Computation on GPU)逐渐成为研究的热点,但是,GPU动态随机访问存储器严格的存储模式,以及固定的流水管线成为GPGPU应用的最大障碍。统一计算设备架构(compute unified device architecture,CUDA)技术的诞生开创性的改革了GPU的编程及存储模式。这一GPGPU计算架构中,提供了类似C语言的开发环境,允许设计人员使用C语言和CUDA扩展库的形式编写程序,从而直接利用GPU资源进行计算,降低了开发的复杂度,提高了开发效率。目前,CUDA已经被用于分子动力学[19]、生物信息学[20]、地球物理学[21]、医学图像分析等领域中[22]。
本研究基于CUDA的设计思想和编程方式,对图割算法进行了并行改造,在CUDA架构下实现了其并行算法,在保证分割效果的同时,提高图像数据处理速度,缩短图像处理时间,以达到实时处理的需要,并结合肝脏肿瘤特点,改进了人机交互,实现了肝脏肿瘤图像的快速分割。
1 统一计算设备框架(CUDA)
在CUDA框架下,一个支持CUDA的GPU作为CPU的协处理器,适用于可以分解为SIMD并行模式的算法。它有自己的静态存储器、片上共享存储器以及由一系列流处理单元(streaming processor)整合而成的流式多处理器(streaming multi processors,简称MP)。静态存储器可以分为只读纹理存储器(texture memory)、读写全局存储器(global memory)以及只读常量存储器(Constant Memory),存储于其中的数据可以被所有的流式多处理器访问处理,但速度较慢。而每一个流式多处理器中的读写共享存储器(shared memory)的访问速度较快,但它只能被绑定其上的固定流式多处理器中的处理单元访问。
在CUDA并行程序中,线程是执行的基本单元。一定数量执行相同指令的线程组成一个Block。在这些Block中,线程之间可以通过共享存储器进行数据通信和共享,并实现同步。所有完成相同功能的Block组成一个Grid,Grid间的执行是串行的。当程序加载时,Grid加载到整个设备上,所有Block被串行地分配到每一个流多处理器上,而线程则对应着每一个流单处理器核心。每个Block只能运行在一个多处理器上,但一个多处理器上可以分配多个Block。多个Block能否并行执行则主要依赖于每个Block对资源共享存储器和片上寄存器的使用量。在某个时刻,每个多处理器上即将要执行的一批线程块是处于活跃状态,其中每个线程块按照线程的索引号顺序地分为单指令多数据流(single instruction multiple data,SIMD)组(称warp),多处理器按照SIMD的方式通过时间分片来执行warp,各个线程通过自己的线程索引号,取不同的数据执行kernel。在CUDA程序中,首先必须合理地对GPU程序进行执行配置,即确定Block数和每个Block中的线程数以及共享内存的大小,这样才能更好地提高并行度,并充分利用系统资源。
2 图割的基本理论
基于图割技术的图像分割算法的基本思想为:将图像的分割描述为基于最小化能量函数E(f)的二值分类问题。定义:


图割算法利用图论中的网络流模型来解决上述能量函数的最小化问题。将图像中的每一个像素映射为图中的一个结点,再各设一个虚拟的源点和汇点。每个像素结点p与源点间有边,与汇点间也有边,相邻像素p、q的对应结点间也有边。然后,使用最大流最小割算法求取所建图的最小割,常用的最大流最小割算法有两种,一种为增广路径算法[23],另一种为Push-Relabel算法。本研究采用第二种方法,此方法每次只处理一个节点,适合并行化,关于此方法的详细论述见文献[24]。
3 图割算法在CUDA上的实现
3.1 利用CUDA实现图的构造
图的构造有两种常用的方法[25-26],文献[25]中的方法不需要引入额外的点,保持了网格结构,与CUDA的栅格结构相适应,在构造图时参考了此方法,并结合肝脏肿瘤的特点,引入了感兴趣区域。R为感兴趣区(恰能完全包括肿瘤组织的矩形区域),为非感兴趣区,有∪R=P,O和B分别代表硬约束中被标记为目标和背景的像素点集合,有O∈R,B∈R,且O∩B=φ。节点p,q代表图像数据中像素点,dist(p,q)是两点间的欧氏距离,Ip是p点的灰度值,σ2是图像灰度值的方差,点s和t是虚拟的源点和汇点。Pr(Ip|“obj”)和Pr(Ip|“bkg”)分别是目标对象(obj)和背景(bkg)像素的灰度分布概率密度函数。节点之间的边为n-link,记为(p,q),节点和终节点之间的为t-link,分别记为(p,s)和(p,t)。节点间及节点与终点间边的权重值在CPU上完成计算,然后利用CUDA API中的cudaMemcpy()一次性将其拷入GPU的全局存储器,以供所有线程访问,最终在GPU上完成图的构造。对于边缘上的点会有较少邻域,在处理时以零补齐。边的权重值如表1所示,能量函数采用(1)式。

表1 边的权重值Tab.1 The weight of edges
其中:Dp(“obj”)=-lnPr(Ip|“obj”);
Dp(“bkg”)=-lnPr(Ip|“bkg”);
器容量也不能比所带的电动机小得太多,因为电动机本身的空载电流较大,变频调速器的容量一般不得小于电动机容量的65%。

3.2 Push-Relabel算法在CUDA上的实现

Push Kernel(node v):
1)将h(v)从全局存储器拷入块的共享存储器中。
2)向符合条件的邻域节点v泵水,并将泵水量保存在全局矩阵A中。
3)更新节点v的余流e(v)和残留网络中边(v,w)的容量。
Pull&Relabel kernel(nodev):
1)将h(v)从全局存储器拷入块的共享存储器中。
2)依据矩阵A更新每一个节点的余流e(v)及残留网络中边的容量rf(v,w)。
3.3 性能优化
由于全局存储器的存储空间不会被缓存,访问速度很慢,需要400~600个时钟周期,因此,如何优化对全局存储器的访问就显得格外重要。在CUDA技术中,当half-warp(本研究中为GeForce 8800 GTS显卡,一个warp 32个线程,half-warp为16个线程)线程同时进行存储器访问可合并为一个存储器事务时,全局存储器带宽的使用率将达到最高,即全局存储器的对齐访问[27]。为每一个节点的高度、边的权重和标记值分别分配了32 bits的全局存储空间,这样16个节点的高度、边的权重和标记值的存储空间均为64 bytes,恰为half-war个线程的一个存储器事务的访问区域,保证了每个half-warp内的线程对全局存储器访问地址的连续性,避免了线程交叉或间隔访问内存,实现了全局存储器对齐访问。
合理设计每个Block中的线程数以及共享存储器的大小,对提高并行度,充分利用系统资源亦十分重要。线程模块的规模是有限制(每一个线程模块最多只能分配512个线程)的,而在线程模块大小一定的情况下,共享存储器的空间分配也会在一定程度上限制硬件上流式处理器的并行执行能力,共享存储器分配过大或者线程分配过少时,都会影响计算能力。利用CUDA Occupancy Calculator v 1.2,综合共享存储器和线程规模对性能的影响,线程模块大小设计为16×16,共享存储器的大小分配为1K。图1和图2显示了当前硬件配置下,线程模块和共享存储器对计算性能的影响,其中三角标记值是所选择的共享存储器和线程模块的分配情况。

图1 在当前共享存储器分配下线程模块大小对性能的影响Fig.1 The thread size impact on performance with the current allocation of shared memory

图2 在当前线程分配下共享存储器大小对性能的影响Fig.2 The shared memory size impact on performance with the current allocation of thread
4 交互
图割方法分割结果的准确性和效率,跟用户的交互有直接的关系。试验中发现,由于医学图像不均匀和像素重叠的特点,要想准确快速的将肿瘤组织分割出来,交互起来十分繁琐。另外统计发现,肿瘤病变组织只占整个图像的很小一部分,一般在10%左右,所以,周围很大一部分的组织分布信息对于要分割的目标都是没有意义的,甚至会增加分割的难度。据此,在分割时规定了感兴趣区域,所谓感兴趣区域就是图像内部包含分割目标的一个小区域,采用的是矩形区域,交互时在对角线的位置上选取两个点,系统自动生成一个矩形区域,并将该矩形区域的边界点作为交互中的背景点,统计其灰度分布信息,感兴趣区域以外的部分直接划分为背景,此后只需在感兴趣区域内选取目标像素点。图3给出了交互方法与传统的图割交互方法的交互量和分割结果的比较[28]。图3所示为本研究和传统交互方法及对应的分割结果。图3(a)为交互方式及对应的分割结果,白色矩形内部为感兴趣区,且矩形区域的边界点作为背景点,黑色为标记的目标点,图3中(b)和(c)是传统的交互方式及对应的分割结果,即没有引入感兴趣区,其中,黑色为标记的目标点,白色为标记的背景点。图3(c)相对图3(b)而言,由于交互的相对仔细,交互时划定的目标点和背景点较多,得到的分割结果就较好,相反,图3(b)的分割结果就较差,出现了严重的过分割。由图3可以看出,引入感兴趣区之后交互变得相对简单,而在传统的交互方式下相对复杂,交互对结果的影响较大,易出现错误划分(如图3(b)),需进行二次分割。
5 实验方法
实验数据为5组肝脏CT数据。对每幅图像,给出了医生手动分割的结果,作为金标准。为验证本方法的有效性,将本方法与在CPU上运行的图割算法[28]进行了比较,CPU和GPU的计算时间是指分割该组数据中含肿瘤切片的平均时间,不包括用户交互时间。为定量的评价分割精度,本研究用重叠率η来对分割结果进行评价[29]。
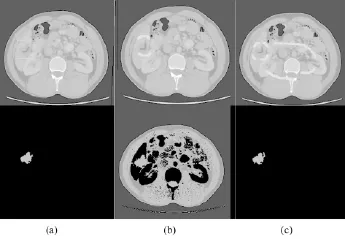
图3 原图及交互(上)及其分割结果(下)。(a)文中交互方法及其分割结果;(b)和(c)传统交互方法及其分割结果Fig.3 Source images and interaction(upper)and segmentation results(bottom).(a)our interactive methods andsegmentationresults;(b)and(c)traditional interactive methods and segmentation results

式中,Φ为人工手动分割结果分割目标的像素数;Γ为手动分割结果和自动分割结果重叠的像素数,评价结果如表2所示。
使用的实验平台是Intel Core2 6320,主频1.86GHz,系统内存1G,显卡采用的是NVIDIA公司提供的GeForce 8 800 GTS,该显卡静态存储器的大小为640M,有12个流式多处理器,每个多处理器中有8个流式处理单元,每个流式处理器上有一块16K的共享存储器。编程环境为Wondows XP下Visual Studio C++2005 MFC。
6 结果与分析
本算法与传统的CPU串行的图割算法[28]相比,计算速度有了明显的提升,加速一般在8~10倍,同时分割精度也得到了很好的保证,重叠率稳定在94%左右,完全可以满足临床需要,量化评价结果如表2。图4给出了几幅不同类型的肝脏CT图像的分割结果,第一行图像中肿瘤区域灰度分布均匀且边界清晰,第二行图像中肿瘤区域灰度分布不十分均匀且边界较模糊,其中白色标记点为本算法所分割的肿瘤区域的边界点。对于不同类型的肝脏CT数据,本算法的分割结果边界光滑(见图4),结果令人满意。另外,我们还将本方法用于分割脑部MRI数据,部分分割结果如图5所示,其中第一行肿瘤区域灰度分布均匀,第二行肿瘤区域灰度分布变化相对较大。由图5可以看出,本算法在分割MRI脑部数据时也取得了令人满意的结果,具有较强的实用性和扩展性。

表2 对5组数据的肝脏肿瘤分割质量评价Tab.2 The quality estimation of liver tumor segmentation from 5 sets data
7 结论
利用CUDA技术实现了图割算法的并行化,并结合CUDA全局存储器访问,线程块大小及共享存储器分配对计算性能的影响,在实现时进行了优化,并将其应用于肝脏肿瘤的分割。实验表明,该方法相对于传统的CPU串行算法,在保证分割精度的同时,运算速度有了明显的提升。目前,本算法仅是对二维图像的分割,下一步工作中,将对本算法进行扩展,使其能够应用于三维图像的分割,增强大型数据的处理能力。

图4 肝脏CT数据分割结果。(a)~(f)为不同类型的肝脏CT数据分割结果Fig.4 The segmentation results of liver CT data.(a)~(f)segmentation results for different types of liver CT data

图5 脑部MRI数据分割结果。(a)~(f)为不同类型的脑部MRI数据分割结果Fig.5 The segmentation results of brain MRI data.(a)~(f)segmentation results for different types of brain MRI data
[1]Phillips WE,Velthuizen RP,Phupanich SL,et al.Applications of fuzzy C-Means segmentation technique for tissue differentiation in MR images of a hemorrhagic glioblastoma multiforme[J].Magn Reson Imaging,1995,13(2):277-290.
[2]Capelle A,Colot O,Fernandez-Maloigne C.Evidential segmentation scheme of multi-echo MR images for the detection of brain tumors using neighborhood information[J].Information Fusion,2004,5(3):203-216.
[3]Taheri S,Ong SH,Chong V.Level-set segmentation of brain tumors using a threshold-based speed function[J].Image and Vision Computing,2010,28(1):26-37.
[4]Greig DM,Porteous BT,Seheult AH.Exact maximum a posteriori estimation for binary images[J].Royal Statistical Society,Series B,1989,51(2):271-279.
[5]Boykov Y,Veksler O,Zabih R.Markov random fields with efficient approximations[R].TR97-1658,1997.
[6]Boykov Y,VekslerO,Zabih R.Fast approximate energy minimization via graph cuts[J].IEEE Trans Pattern Anal Mach Intell,2001,23(11):1222-1239.
[7]Sumengen B.Fast and adaptive pairwise similarities for graph cuts-based image segmentation[A].In:Bertelli L,Sumengen B,Manjunath BS,eds.2006 Conference on Computer Vision and Pattern Recognition Workshop[C].Washington:IEEE Computer Society,2006.179-185.
[8]Lombarert H,Sun Y,Grady L,et al.A multilevel banded graph cuts method for fast image segmentation[J].ICCV,2005,1:259-265.
[9]Kawatra V,Sehool A,Essa I,et al.Graphcut textures:image and video synthesis using graph cuts[J].Proceedings of ACM SIGGRAPH 2003,2003,22(3):277-286.
[10]Rother C,Kolmogorov V,Blake A.CrabCut:interactive foreground extraction using iterated graph cuts[A].In:Chesnais A,Charles P,eds.Proceedings of the 2004 SIGGRAPH Conference[C].New York:ACM,2004.309-314.
[11]Roy S,Cox I.A maximum-flow formulation of the n-camera stereo correspondence problem[A].In:Bertelli L,Cox I,eds.Proceeding of the Sixth International Conference of the Computer Vision[C].Washington:IEEE Computer Soeiety,1998.492-502.
[12]Kim J,Zabin R.Automatic segmentation of contrast-enhanced time resolved image seriea[J].Journal of X-Ray Science and Technology,2003,22(11):502-509.
[13]Boykov Y,Kolmogorov V.An experimental comparison of mincut/max-flow algorithms for energy minimization in vision[J].IEEE Trans Pattern Anal Mach Intell,2004,26(9):1124-1137.
[14]Kohli P,Torr PHS.Effciently solving dynamic markov random fields using graph cuts[J].ICCV,2005,2:922-929.
[15]Juan O,Boykov Y.Active graph cuts[J].CVPR,2006,1:1023-1029.
[16]Shiloach Y,Vishkin U.An O(n2logn)parallel max-flow algorithm[J].Journal of Algorithms,1982,3(2):128-146.
[17]Goldberg AV.Efficient graph algorithms for sequential and parallel computers[R].TR-374,1987.
[18]Dixit N,Keriven R,Paragios N,Gpu-cuts:Combinatorial optimization graphic processing units and adaptive object extraction[R].TR-77455,2005.
[19]Stone JE,Phillips JC,Freddolino PL,et al.Accelerating molecular modeling applications with graphics processors[J].Journal of Computational Chemistry,2007,28(16):2618-2640.
[20]Manavski SA,Valle G.CUDA compatible GPU cards as efficient hardware accelerators for Smith-Waterman sequence alignment[J].BMC Bioinformatics,2008,9(2):171-176.
[21]Belleman RG,Bédorf J,Portegies Zwart SF.High performance direct gravitational n-body simulations on graphics processing Units-II:An implementation in CUDA[J].New Astronomy,2008,13(2):103-112.
[22]秦安,徐建,冯前进,等.基于GPU的快速三维医学图像刚性配准技术[J].计算机应用研究,2010,27(3):1198-1200.
[23]Edmonds J,Karp RM.Theoretical improvements in algorithmic efficiency for network flow problems[J].ACM,1972,19(2):248-264.
[24]Goldberg AV,Tarjan RE.A new approach to the maximum-flow problem[J].ACM,1988,35(4):921-940.
[25]Kolmogorov V,Zabih R.What energy functions can beminimized via graph cuts?[J].IEEE Trans Pattern Ana Mach Intell,2004,26(2):147-159.
[26]Boykov Y,Veksler O,Zabih R.Fast approxi-mate energy minimization via graph cuts[J].IEEE Trans Pattern Anal Mach Intell,2001,23(11):1222-1239.
[27]NVIDIA Corporation.CUDA Programming Guide 2.0[EB/OL].http://www.nvidia.com,2008-06-21/2010-06-02.
[28]Boykov Y,Funka LG.Graph cuts and efficient N-D image segmentation[J].International Journal of Computer Vision,2006:70(2):109-131.
[29]张治国,周越,谢凯.一种基于Mumford-Shah模型的脑肿瘤水平集分割算法[J].上海交通大学学报,2005,39(12):1955-1958.
