基于多传感器信息检测和融合的中国手语识别研究
2010-09-02王文会杨基海
王文会 陈 香 阳 平 李 云 杨基海
(中国科学技术大学电子科学与技术系,合肥 230027)
引言
手语识别研究的目的,是使计算机能够正确理解手语,并将手语转换成容易理解的语音或者文本信息,以增进聋哑人与健听人之间的无障碍交流[1]。同时,手语手势识别研究有助于促进智能人机交互技术、虚拟现实和机器学习等研究的发展[2]。
根据输入设备的不同,手语识别主要分为基于穿戴式输入设备和基于计算机视觉两个方面。基于穿戴式输入设备的手语识别使用的输入设备,主要有数据手套、加速计和表面肌电传感器等[3-4,7]。由于手势运动伴随着肌肉活动,表面肌电信号(surface electromyography,SEMG)可用于检测手势运动引起的肌肉活动状态变化。如Du利用7导表面肌电对11个手势采用基于灰度相关分析的方法,获得了95.9%的识别率[3]。Rehm采用HMM技术,借助1个三轴加速计对8个手势动作达到了97.2%的识别率[4]。基于计算机视觉的手语识别,通过各种成像设备,实现对手势动作的捕获。根据采用的成像设备个数不同,一般可分为单目视觉和立体视觉。单目视觉方面,Nandy采用基于图像的二维方向直方图作为手语特征,针对22个印度手语词,用K-近邻分类器得到了100%的识别率[5]。在立体视觉方面,Vogler等利用1个位置跟踪器和3个互相垂直的摄像机,针对由53个手语词组成的486个句子,在上下文相关的情况下得到了89.91%的识别率[6]。
不同传感器在捕获手势信息方面有着独特的优势,但同时也存在各自的缺点。例如:计算机视觉可提供丰富的朝向、手形手姿、运动以及手与身体相对位置信息,但易受到摄像机视角和背景光照等环境因素影响;SEMG能够反映手的形态、关节的伸屈状态和伸屈强度,对精细手指动作有着独特优势,但由于是一种微弱的电生理信号,对传感器安放位置敏感,可识别手势动作种类有限[3];加速计(accelerometer,ACC)可检测手势的大尺度运动信息,但无法检测小幅度运动手势和静态手势。当前很多有关手语手势的识别研究是采用单一种类的传感器,可检测和识别的手语词汇量和准确性具有一定的局限性。
为有效利用不同类型传感器在捕获手势动作信息上的优势,多传感器检测和融合技术逐渐被引入到手语识别中。Kosmidou综合5导SEMG与三维ACC信号,采用样本熵特征,对60个孤立的希腊手语词取得了高达99%的识别率[7]。邹伟等利用数据手套、视觉和肘部弯曲传感器作为输入设备,对中国手语中的32个单手静态词汇进行了识别研究[8]。Zhang把4导表面肌电与1个加速计作为输入设备,对18个自定义的手势取得了91.7%的实时识别率,并将其应用于虚拟场景中魔方游戏的实时控制[9]。以上研究成果表明,多传感器信息检测和融合技术在手语识别中具有很大的潜力。
本研究利用表面肌电、加速计和网络摄像头作为输入设备,充分结合这3种低成本、便携式传感器在捕获手语信息方面的优势,提出了一种基于多传感器信息检测和融合的中国手语手势识别方法。在有效手语动作的时序分割环节,利用SEMG的幅值变化信息,并结合移动窗技术和阈值检测方法来获得3种传感器的同步活动段信号。在分类融合环节,采用一种多级分类融合策略,在决策级对不同角度的手语动作信息进行融合:首先,利用SEMG在有无动作情况下的幅值变化信息,将手语词区分为单手词和双手词;然后,根据获得的手语图像序列中肤色连通区域的个数不同,将双手词细分为无遮挡词和有遮挡词;最后,在决策融合中利用Sugeno模糊积分,将表面肌电信号、加速计信号和视觉信号进行融合,得出最终判决结果。实验结果表明,该方法可有效地融合不同传感器提供的信息,实现优势互补,获得较高的识别率。
1 基于多传感器信息检测和融合的手语识别方法
图1所示为基于多传感器信息检测和融合的中国手语分类识别实现框图。

图1 基于多传感器信息检测和融合的中国手语识别整体框图Fig.1 The flow diagram of multi-sensor information detection and fusion method
1.1 手势分割
为得到每个传感器对于手语动作的同步描述,需要从肌电、加速计和视觉传感器采集的连续手势输入信号中分割出动作开始到结束的有效手势活动段。对于视频和加速度信号而言,如何从连续信号中自动分割出含有有效手势动作的活动段信号,还没有比较完善的算法。由于SEMG直接体现了肌肉的活动强度,其幅值变化可用于判断手势是否在执行状态,且不受手臂其他无意识动作的影响。因此,利用SEMG的幅值变化信息来实时提取活动段,具体实现过程如下:
先按式(1)计算右手的S导SEMG在t时刻的平均绝对值,再按式(2)计算移动窗内64点的平均绝对值的平均平方和,有

当肌电信号加窗平均幅值SEMGMA(t)大于开始阈值fH时,表示手语动作开始执行,此时开始同步保存3种传感器信号;当肌电信号的加窗平均幅值小于结束阈值fL时,表示手语动作结束,此时停止保存这3种传感器信号。fL<fH是避免无意识的抖动被错认为有效手势,而且可以防止手势执行过程中信号帧断裂。
1.2 手势特征提取
对于ACC信号,将降采样的原始信号作为特征,就可以得到比较好的识别效果[4]。因此,先将ACC活动段信号降采样为32个点,然后进行归一化调整,对于三轴加速度信号,形成一个3×32的时间序列作为特征向量。
SEMG信号常采用多导电极进行采集。由于不同手势所涉及的肌肉群及其用力强度均不一样,导致各导的SEMG信号幅度也有所不同,信号幅值的平均绝对值MAV可以作为区分不同手语的有效特征。同时,SEMG是肌肉收缩时产生的随机非平稳的生物电信号,而AR模型系数是在SEMG分类识别方面效果比较好的频域特征。因此,本研究采用MAV和四阶AR模型的前3个系数来作为每导SEMG信号的特征参数[9]。将各导SEMG特征串联,作为手语词的特征。
手势图像特征提取一般是基于轮廓信息或手势分割后的二值化图像,本研究采用几何矩[10]和方向直方图[5]提取视觉特征。因在打手语过程中存在一些不确定因素,比如手势与摄像头之间相对距离、角度的不惟一会导致不同人或者同一个人在不同时刻手语获得的图像有偏转或移动等缺陷。将几何矩用于提取不同手语的特征,可以做到不随手势图像的平移、旋转和大小变化而变化,具有良好的适应性和稳定性。有些手语词的手姿表达基本一样,区别仅仅在于手指的指向不同,几何矩对于这些词不能有效区分。而方向直方图考虑的是手势的边缘轮廓信息,可以提供手指的朝向信息。因此,采用几何矩和方向直方图作为手势图像特征,既利用了手势的整体形状信息,又保留了轮廓细节信息。常用的几何矩有7个特征分量[10],实验表明使用前4个不变矩特征量的效果比7个都用效果要好,所以使用前4个分量作为一帧手势图像的几何矩特征。几何矩特征向量中各特征分量的数量级差异比较大,实验中分别取100、101、102、103作为分量调节系数。将各帧几何矩组合在一起,形成一个手语词的特征;将边界方向量化成36柄,形成方向直方图特征向量。
1.3 多级分类融合策略
图2为本研究采用的基于多传感器信息检测和融合的手语分类策略。为有效融合多传感器信息,该分类策略充分利用不同传感器可从不同侧面捕获手势动作信息的特点,同时考虑手语词的整体信息和细节信息,采用由单双手词划分、有遮挡和无遮挡双手词划分、模糊积分融合构成的多级分类方法,以提高中等词汇量手语的识别率。
1.3.1 基于EMG的单双手词区分

图2 基于多传感器信息检测和融合的手语多级分类策略Fig.2 Multi-level classification strategy based on multi-sensor information detection and fusion
中国手语词汇共有5 600余个单词手势动作[1],可分为单手词和双手词两大类。单手词在执行时一般只需要使用右手(或称主手)表达手势所蕴涵的信息,双手词则需要左右手相互配合。单双手词的划分采用SEMG信号来完成:SEMG的幅度可以直接反映肌肉的活动强度,在手语动作执行期间的信号幅度较大,词与词之间的停顿时期的信号幅度较小,故可依据左手的SEMG幅度来判断左手有无动作(设定阈值),从而实现单双手词的划分。
1.3.2 基于视觉信号的有遮挡和无遮挡双手词区分
双手词又可分为有遮挡和无遮挡两种。双手有遮挡词的主要特点是:在整个动作执行过程中,左右双手有接触,或者由摄像头获得的图像帧序列中左右手有部分重叠。如图3所示,手语词“元旦”为无遮挡词,而“信”为有遮挡词。在对双手词的手势帧图像(IMG)进行背景去除和肤色检测后,可以发现手部连通区域为1个或者2个。因此,依据视觉上手部连通区域个数的不同,对双手词进行双手有遮挡和双手无遮挡的划分。

图3 遮挡和无遮挡双手词举例Fig.3 Samples of double-hand sign word with and without occlusion
1.3.3 基于模糊积分的决策级融合
鉴于手语词在表达的过程中存在着大量的不确定因素,而模糊理论中的模糊积分在处理不确定因素方面具有一定的优越性,本研究采用Sugeno模糊积分综合SEMG、ACC、方向直方图和几何矩4种特征通过相应的分类器所提供的局部决策,消除它们之间的数据冗余和矛盾,做出最终识别判决。
在3类传感器信号的特征描述中,有些特征是一维向量(EMG和方向直方图),而有些特征是连续的观察值时间序列(ACC,几何矩图像帧序列),所以需用不同结构的分类器(简称异构分类器)进行分类处理。根据各传感器信号特征的特点,采用隐马尔科夫模型(HMM)[9]和最近邻分类器(NN)[11]来分别处理时间序列和一维向量。HMM是一种统计学模型,具有较强的时序建模能力。受到HMM在连续语音识别领域有着成功应用的启发,众多研究者将HMM引入手语识别领域,同样取得了比较好的效果[6,9]。考虑到手语的运动特点,采用HMM模型为直观left-right形式的Bakis模型[9],设定HMM有5个状态3个混合项。不管是HMM还是NN,待识别词的特征输入后,都会给出待识别词与词库中各词的似然概率或距离测度,后续处理中将这些数据归一化后当做模糊隶属度,以表明待识别词与词库中某个词的相似程度。
模糊积分是定义在模糊测度上的非线性函数,它运用模糊集合的知识,用模糊测度取代了加权值,从多个分类器的结果中找出最大一致性的结果。模糊测度的类型有可能性测度、信任度和λ-模糊测度gλ等[12],本研究在手语识别中用的是λ-模糊测度gλ。
设X=(x1,x2,…,xn)是一有限集合,p(X)是X的幂集,定义在p(X)上的集合函数g:p(X)→[0,1]称为模糊测度,满足条件g(φ)=0,g(X)=1;∀A,B∈p(X)。若A⊂B,则g(A)≤g(B)。
gλ模糊测度除满足上述两个基本条件外,同时满足下面的附加条件,即

式中,参数λ为实数,λ>-1且λ≠0,存在惟一的λ满足

设a为待识别的对象,C={C1,C2,…,Cm}表示m个类别集合,A=(s1,s2,…,sN)是N个分类器集合。设fj(si)表示分类器i中手势a属于类别Cj的支持度或者称之为置信度,即待识别词a与手势词库中第j个HMM或NN模型之间的似然概率。设有限集合Ai=(s1,s2,…,si),i=1,2,…,N。若fj(si)按降序排列,即fj(s1)≥fj(s2)≥…≥fj(sN),则gλ可由单点上的模糊测度(即模糊密度)gi=g({si})依据下列公式递推求得

在手语识别中,可将Sugeno模糊积分简化为
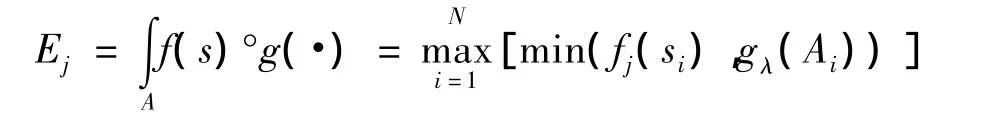

然后,使用最大隶属准则,得到对象a的隶属类别。

在基于模糊积分的分类器融合中,模糊测度对最终输出的融合结果有着很大的影响。计算模糊测度时,需要先确定模糊密度。模糊密度可以理解为信息源对于整个决策的重要性,不合适的模糊密度可能使得融合精度非常不稳定,有时甚至会使融合精度低于单分类器的分类率。在多传感器手语识别中,各个传感器所提供的信息是不同的,各个信息源对手语识别的重要性也不同。为避开单分类器所能达到的性能限制,有效利用各个子分类器的互补性,定义每个分类器对不同手势类别的分类率为模糊密度gi,然后由gi递推,得到模糊测度gλ。
加权平均、D-S证据理论和模糊积分是比较常用的决策融合方法[12-13]。为验证所提出方法的有效性,同时开展了基于前2种决策融合方法的手势识别实验,并对3种方法得到的结果进行了对比分析。加权平均是一种简单直观的方法,它将各个分类器提供的匹配结果进行加权平均后作为融合结果。D-S证据理论将每个传感器的每一次测量值作为一条证据,不同特征经过分类器后得到匹配结果,以此作为该证据对各个手语词的基本概率赋值,然后利用基于Dempster的正交规则对基本概率赋值进行组合。在多个证据合成时,可以两两递归组合来实现融合[13]。
2 实验及结果分析
2.1 实验方案
基于实验需要,构建了一个基于OpenCV开放源代码和多线程技术的3类传感器数据采集平台。8个自制的表面肌电电极、2个自制的三轴加速计和1个普通的USB接口的网络摄像头,用于实时采集手势动作信号。图4为表面肌电电极和加速计安放示意图,左右手的前臂上分别安置4个表面肌电电极和一个加速计电极,其中4个肌电电极的第一导安放于上肢前臂靠近腕关节的拇伸肌和食指固有肌对应位置处,其他三导分别安放于靠近肘关节的伸指总肌、尺侧腕伸屈肌等处,加速计和参考电极安放于腕关节附近。为了方便手语信号采集,用腕带将电极捆绑在手臂上,肌电和加速计的信号采样率设为1kHz。视频信号采用单目正面视觉获取,在实验过程中,将网络摄像头正对着受试者。视频采样帧率为30帧/s,每帧图片的空间分辨率为640像素×480像素,采样环境为常规背景、普通光照下的实验室环境。

图4 数据采集系统中表面肌电传感器和加速计安置Fig.4 SEMG and ACC sensor placement
本研究以从文献[1]中选取201个高频手语词作为识别对象,包括61个单手词、72个双手有遮挡词、68个双手无遮挡词。实验数据共有9 648个样本,由4位年龄在20~25岁之间的健康受试者分别对每个手语词采集12遍构成。在实验中,受试者被要求站在距离摄像头1m左右的地方执行动作,做单手词时用右手执行,左手自然下垂在身侧。每个手语动作中选取8个样本用作训练样本,剩下的4个样本作为测试样本。
为了验证基于多传感器信息检测与融合的方法对于中国手语识别的有效性,对7种不同的传感器组合情况进行了数据分析处理,包括单用肌电信息(EMG-only)、单用加速度信息(ACC-only)、单用视觉信息(IMG-only)、融合肌电和加速度信息(EMG+ACC)、融合肌电和视觉信息(EMG+IMG)、融合加速度和视觉信息(ACC+IMG)、融合肌电、加速度和视觉信息(Three-sensors)等。
在每种组合情况下,手语识别过程都会充分利用所涉及的传感器的优势。例如第一种情况EMG-only,先按照前面讲到的多级分类策略中的第一级,利用EMG的幅值特性,将单双手词先区分开,然后用EMG的特征分别对单双手词进行识别。对于EMG+IMG,则先利用EMG和视觉信号特点,将单手词、双手无遮挡和双手有遮挡区分开,然后利用模糊积分对EMG和视觉特征进行决策融合。
2.2 结果与分析
表1以平均识别率和标准差形式,给出了不同传感器组合情况下各受试者的手语识别结果。单传感器的识别率为79.10%~96.89%,传感器两两组合情况下的识别率为95.15%~97.64%,3个传感器组合情况下的识别率高达99.13%~99.75%。这些结果表明,多传感器融合可使手语词的识别率得到一定的提高。同时,对比单传感器和多传感器情况下的标准差可发现,两两组合情况下的标准差小于单传感器情况,3种传感器组合的标准差小于两种传感器组合的标准差。此结果说明,多传感器融合可显著消除不同手势动作模式的可分性差异。以第二个受试者的具体识别结果为例,在EMG-only情况下,单手词“墙壁”有两个错分成了单手词“玻璃”,双手有遮挡词“扶”有3个错分成了双手无遮挡词“填”,因为这些词执行时,肌肉收缩状态差不多或完全相同,所以出现错误分类。但是,这些词空间轨迹和手的朝向有很大不同,采用加速计或视频信息即能正确识别。在单用ACC的情况下,如单手词“你”有两个错分成了“谢谢”,这两个单手词都是静态词,加速计提供的信息类同,区别是一个伸食指,一个伸大拇指,利用EMG或视觉信息则可将其区分开。双手有遮挡词“椅子”有两个错,识别成了双手无遮挡词“对称”,这在多级融合策略中可以很容易通过图像连通区域的个数不同而将其区分。
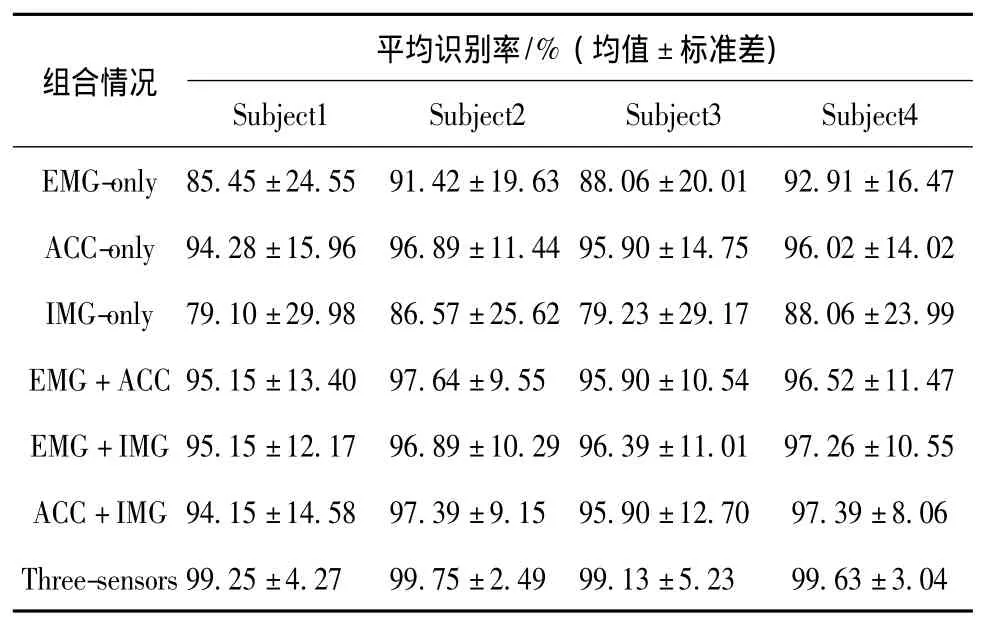
表1 不同传感器组合情况下的手语识别实验结果Tab.1 Classification results of different sensor combinations
表2给出了基于模糊积分、加权平均和D-S证据理论的决策融合分类对比结果。其中标号A表示模糊积分,B为加权平均,C为D-S证据理论。从表2中可得出:3种传感器组合的识别率基本上都大于两种传感器组合,前者的标准差小于后者的标准差。而且,在3种传感器融合的情况下,基于模糊积分的识别率最高,基本上都在99%以上,标准差也是最小。除了ACC+IMG这种组合情况外,模糊积分与D-S证据理论的识别率几乎都大于加权平均,说明了模糊积分和D-S证据理论能更好地利用多个分类器之间所具有的互补性,产生精度更高的结果,降低了分类的不确定性。然而,D-S证据理论在多个分类器融合时需要两两进行递归组合,并且涉及乘积操作,计算复杂度随着测量维数的增加以指数形式递增,容易出现“维数灾难”[13]。而模糊积分考虑到了子分类器的可靠性问题,计算简单,可扩展性和可移植性比较好。对于ACC+IMG出现的情况,可通过表3来解释。在ACC+IMG组合的情况下,首先利用视觉信号的特性,将手语词分为具有单连通域与双连通域的两个子集,然后分别用相关特征获得子分类器的局部决策。由于ACC侧重于描述大尺度手势动作的空间轨迹,IMG侧重于手的形状轮廓和朝向,ACC与IMG之间存在互补信息较多,所以加权平均也能够得到比较好的融合结果。在EMG+IMG组合情况下,加权平均性能比另外两种融合方法差很多,具体可见表4。由于EMG描述的是手势动作的用力方式,体现的是手势形态和手腕精细动作,它与IMG都是提供对手语手姿方面的信息,两者存在较多冗余;而基于EMG与IMG的子分类器之间的局部决策存在冲突和矛盾的地方,是非可加的,D-S证据理论与模糊积分可从多个分类器的一致和相互冲突的结果中找出最大一致性的结果,因此得到了远高于子分类器的识别率。

表2 采用不同融合方法的手语识别实验结果对比Tab.2 Comparison of classification results with different fusion methods

表3 Subject2在ACC+IMG组合情况下的识别率Tab.3 Recognition rates of subject2 with condition ACC+IMG

表4 Subject3在EMG+IMG组合情况下的识别率Tab.4 Recognition rates of subject3 with condition EMG+IMG
3 结语
手语词主要是通过手形变化和空间运动轨迹,以及手同身体之间的相对位置关系表达相关信息。无论是手形变化还是手部运动,均在执行过程中存在一些不确定因素。采用肌电、加速度和视觉3种传感器作为手势输入设备,提出了一种基于多传感器信息检测和融合的中国手语分类识别方法。该方法采用的多级分类策略考虑到了各个传感器的优势和手语词汇的模糊特性,用模糊积分将来自不同分类器的识别信息进行有机结合,用以提高多传感器融合系统的分类精确率,改善系统的稳健性。对于201个中国手语词汇,3种传感器融合的识别率均在99%以上,此实验结果证实了多传感器融合在手语识别中的有效性和可扩展性。同时,对采用不同决策级融合方法进行的对比实验,结果证实了基于Sugeno模糊积分的融合方法的有效性和实用性。
[1]中国残疾人联合会教育就业部,中国聋人协会.中国手语[M].北京:华夏出版社,2003.5-200.
[2]Von AU,Zieren J,Canzler U,et al.Recent developments in visual sign language recognition[J].Universal Access in the Information Society,2008,6(4):323-362.
[3]Du Yichun,Lin Chiahung,Shyu Liangyu,et al.Portable hand motion classifer for multi-channel surface electromyography recognition using grey relational analysis[J].Expert Systems with Applications,2010,37:4283-4291.
[4]Rehm M,Bee N,André E.Wave like an Egyptian:accelerometer based gesture recognition for culture specific interactions[A].In:Proceedings of the 22nd British HCI Culture,Creativity,Interaction[C].Swinton:British Computer Society,2008.13-22.
[5]Nandy A,Prasad JS,Mondal S,et al.Recognition of isolated indian sign language gesture in real time[A].International Conference on Recent Trends in Business Administration and Information Processing[C].Germany:Springer Verlag,2010.102-107.
[6]Vogler C,Metaxas D.ASL recognition based on a coupling between HMMs and 3D motion analysis[A].In:Proceedings of the Sixth International Conference on Computer Vision[C].Los Alamitos:IEEE,1998.363-369.
[7]Kosmidou VE,Hadjileontiadis LJ.Sign language recognition using intrinsic mode sample entropy on sEMG and accelerometer data[J].IEEE Transactions on Biomedical Engineering,2009,56(12):2879-2890.
[8]邹伟,杜清秀,原魁,等.一种基于证据理论的中国手语单手静态词识别方法[J].系统仿真学报,2008,20(22):6142-6150.
[9]Zhang Xu,Chen Xiang,Wang Wenhui,et al.Hand gesture recognition and virtual game control based on 3D accelerometer and EMG sensors[A].In:Proceedings of the 13th International Conference on Intelligent User Interfaces[C].New York:Association for Computing Machinery,2009.401-405.
[10]Hu MK.Visual pattern recognition by moment invariants[J].IRE Transactions on Information Theory,1962,8:179-187.
[11]Duda RO,Hart PE,Stork DG,著.李宏东,姚天翔,译.模式分类[M].(第2版).北京:机械工业出版社,2003.146-151.
[12]Verikas A,Lipnickas A,Malmqvist K,et al.Soft combination of neural classifiers:A comparative study[J].Pattern Recognition Letters,1999,20(4):429-444.
[13]Basir O,Yuan XH.Engine fault diagnosis based on multi-sensor information fusion using Dempster-Shafer evidence theory[J].Information Fusion,2007,8:379-386.
