脑电信号的小波特征提取及半监督识别方法的研究
2010-09-02邱天爽
李 芳 邱天爽 马 征
(大连理工大学电子与信息工程学院,大连 116024)
引言
脑机接口(BCI)是指建立一种不依赖于人体外周神经和肌肉组织而在人与周围环境间进行信息交流与控制的新型通道。近年来,随着世界人口的增长和老龄化的加剧,帕金森病、癫痫、脊髓严重损伤及糖尿病引起的外周神经疾病患者的数量也以惊人的速度增加。这些疾病给病人造成了严重的感觉运动功能损伤,病人如同闭锁在自己的世界里,无法同外界进行交流。脑机接口为这些患者找到了一种可能的解决方案。为了提高脑电信号分类正确率,需要改善脑电信号的特征提取和机器学习方法。
在特征提取方面,由于脑电信号是一种典型的非平稳信号,因此在方法的选择上受到了一定的局限,而有“数字显微镜”之称的小波变换(wavelet transform,WT)是适合处理非平稳信号的一种方法[1];目前在BCI中所使用的EEG信号,如SCP(皮层慢电位)或P300(事件相关电位)等往往不是相互独立的,从脑科学的角度来看,相关信息的结合将会提高脑电信号的识别性能,这意味着时频特征的结合会更有利,而小波分析正是非常有效的时频分析方法。在实现基于小波分解系数及子带系数均值特征算法的基础上[2],发现采用更多的信息可以得到更好的分类性能,在此启发下,本研究尝试在特征组合中加入小波熵这一普适特征量[3-4]。结果表明,小波系数、子带系数均值和小波熵的组合特征量能更准确地表示含有瞬变成分的信号的特征信息,是脑电信号分析和处理的有效途经。
在特征分类方面,BCI中使用的分类方法主要有人工神经网络[5]、支持向量机、K均值聚类、遗传算法等等。其中常用的BP网络虽然实现方便,但训练过程很费时,因此针对少量的有标注样本和大量的无标注样本,半监督方法是最适合的。现有的半监督算法包括:自训练、合作训练、期望最大化算法和直推式向量机等;在经过一系列改进之后,目前比较流行的应用于脑电信号分类的方法是基于自训练半监督的支持向量机[6],本研究针对皮层慢电位数据对上述方法进行改进,依据此原理还演绎出基于自训练半监督的K均值聚类法,实验数据的分析结果证明了其快速的收敛性和分类的准确性。
1 基于小波系数及子带系数均值与小波熵结合的特征提取方法
1.1 特征提取算法原理
1.1.1 脑电信号的小波分解
在选定了小波函数和分解层数之后即可进行小波分解。如以Daubechies类db4小波对信号进行6层分解为例,输出的分解结构包含小波分解系数向量C和系数长度向量L。系数向量C结构为:C=[cA6,cD6,cD5,cD4,cD3,cD2,cD1],其中cA6为逼近系数,cD6,cD5,…,cD1为小波系数。
1.1.2 基于分解系数的特征
以Fisher距离指标作为特征的可分离性度量[2],式中Sb为类间离散度矩阵,Sw为类内离散度矩阵,J值越大代表该特征的类别可分离性越好。各子带可以分别按不同的比例,从中选取J值大的逼近系数、小波系数。具体比例值应依据人不同的思维和实验范例来确定。在小波分解C结构中,通过关键系数选择得到C′=[c1,c2,…,cn],即特征系数向量,n为系数向量的维数。
1.1.3 基于小波熵的特征
一个随机信号,如果是由完全无序的过程生成的,那么其在各频段的幅度和能量近似相同,即信号的概率分布接近无序,熵值理论上接近最大值。如果用小波对该信号进行多尺度分析,当该随机信号的不同尺度的系数矢量越接近时,信号的熵值越大,信号信息量越小,相反则信息量越大。因此将熵值作为衡量信号信息量大小的特征值。
将尺度s上的小波系数矢量记为:Ws=(ws1,ws2,…,wsn),其中下标s表示尺度参数,矢量元素wsi(i=1,2,…,n)为小波系数。也可以用Rn空间中矢量的范数来衡量系数矢量的接近程度,即:

根据小波能量的定义,用小波系数矢量的范数序列来衡量信号在各尺度的接近程度,即用各尺度的能量来衡量各频段的信号成分的接近程度。这里对能量序列E1,E2,…,EK归一化,通过归一化的能量序列的分布来分析信号的结构和复杂程度,过程如下:
假设对信号在K个尺度上进行分解,令尺度上的小波系数矢量为Wj=(wj1,wj2,…,wjn),尺度j的能量定义为

能量序列的分布定义为各尺度的归一化能量

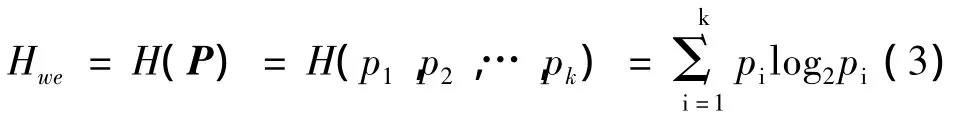
1.1.4 基于子带系数均值的特征
EEG经多尺度小波分解后,各小波子带系数均值分别代表不同频率段的时间均值信息,与信号整体均值相比,更能细致地刻画均值信息。小波子带系数均值为

式中,ni为子带系数长度,i为子带序号。求出每个子带的系数均值,并基于Fisher距离判别准则,按一定比例,从中选取部分系数均值作为特征,得到M′={m1,m2,…,mq}特征均值向量,q为特征向量的维数。
1.1.5 3种特征量的形成与结合
1)对每个训练样本,用指定的小波函数进行指定层次的分解,得到系数向量C。
2)各子带按不同的比例,从C中选取部分具有较高可分离能力的逼近系数、小波系数,得到C′,可分离能力指标基于上述的Fisher准则。基于同样的过程可以从小波各子带系数均值中选择部分系数均值得到M′。
3)对每个训练样本,用指定的小波函数进行不同尺度(j=1,2,…,k)的分解。用每次分解后得到的小波系数来计算该尺度的能量,最终进行归一化,对归一化的能量序列进行小波熵的计算,得到小波熵的特征序列N′。
4)按照上述方法,得到C′、M′和N′,假设EEG信号的采样通道为CH1~CHL,则结合所有待分析的EEG通道的C′、M′和N′形成特征向量,L为所分析的EEG通道数。将特征向量其归一化,形成最终的特征向量:X={C′1,M′1,N′1,C′2,M′2,N′2,…,C′L,M′L,N′L}。
2 基于自训练半监督的支持向量机和K均值聚类分类算法
2.1 改进的基于自训练半监督的支持向量机
2.1.1 算法原理
标准SVM分类器定义如下(针对两分类问题)[6]:

yi(wTxi+b)≥1-ξi,ξi≥0,i=1,2,…,N(6)式中,xi∈Rn是一个训练样本(特征向量),yi∈{-1,1}是xi的标注,C>0是归一化常量。
自训练半监督算法即是以少量训练样本(有标注)训练SVM,并以循环的方式不断更新训练样本(添加无标注的样本)及SVM,最终得到一个优化后的支持向量机,并对测试样本进行最终分类。该方法的改进之处在于每次循环更新训练样本时,以等量的有标注训练样本加入到新建的训练样本中,这样充分利用了已有的训练样本,同时也减少了时间的消耗。
2.1.2 算法实现的具体步骤
已知条件:一个小的训练数据集FI,含有N1个样本{xi,i=1,…,N1},其标注为[y0(1),…,y0(N1)];一个大的测试样本集FT,含有N2个样本{xN1+i,i=1,…,N2}。
步骤1:用FI的少量样本训练一个SVM,并对FT进行分类。此时SVM的参数为w(1)∈Rn,ξ(1)∈RN1,b(1),得到的预测标注为[y(1)(1),…,y(1)(N2)];
步骤2:k次循环(k≥2)遵循步骤2.1~2.3
步骤2.1:定义一个新的训练样本集FN=FI+FT+(k-1)×△F′I,FT的标注由第k-1次循环预测得到,△F′I为每次循环增加的训练集中已标注的样本增量;
步骤2.2:用FN训练一个SVM,并再次对FT进行分类。这时的SVM参数表示为w(k)∈Rn,ξ(k)∈RN1+N2,b(k),预测标注更新为[y(k)(1),…,y(k)((N2)];
步骤2.3:计算目标函数值

步骤3:(循环终止步骤)假定给一个正常量δ0,如果满足下式

或者已标注的训练样本全部训练过,则算法在第k次循环后停止,测试样本的最终分类标注为[y(k)(1),…,y(k)(N2)];否则进行第k+1次循环。
2.2 改进的基于自训练半监督的K均值聚类
2.2.1 改进算法的具体步骤
在了解K均值聚类算法[8]的基础上,确定训练样本的中心,并在自训练半监督的过程中不断修改中心值,直到达到收敛为止。算法流程如下:
1)将两类训练样本分别求均值构成初始聚类中心;
2)取出一小部分训练样本(该实验取了前L个,L即一个通道内的特征量维数),聚类中心为2(根据类别数决定),K均值算法内最大循环次数为Max=1 000,容错误差在10-8左右;
3)初始的训练及测试:用L个训练样本构造均值聚类中心,获得新的聚类中心;以新的聚类中心来对测试样本进行划分T0、T1;
4)循环:将上次划分的测试样本T0、T1分别加入到两类训练样本中,并重新确定聚类中心,若达到最大循环次数或满足容错误差,则以此中心重新对测试样本进行分类;
5)判断算法是否达到收敛(收敛的标准为新的聚类中心与两类训练样本的原始聚类中心重合),若收敛,则停止循环并计算最终分类结果;否则继续4)。
3 实验结果及讨论
3.1 P300信号的特征提取处理结果
该实验主要是验证改进的特征提取算法的有效性。基于Oddball模式,设计了靶刺激与非靶刺激的实验来产生P300信号,并在本实验室用Neuroscan采集了大量的数据,之后分别对3个被试的实验数据进行预处理来获得4种组合方式的训练样本和测试样本。为了验证改进的特征提取算法的优越性,分别应用文献[2]中的小波系数及子带均值法和所提出的结合小波熵的特征提取算法来获得最终的特征量,输入到BP神经网络得到测试结果[5]。
从表1中可以看出,利用改进的3种特征量结合的算法,最优分类正确率可达到95.90%,而且相比于小波分解系数和子带系数均值法,分类效果基本上都有所提高,最多提高2.27%。这说明小波熵的加入,补充了信号信息量大小这一特征,丰富了单一的不同频段上的时域特征,从而提高了信号的识别率。为了进一步提高分类正确率,还利用了改进的自训练半监督分类器,下文主要利用BCI2003竞赛数据来验证算法的有效性。

表1 实验数据的分析结果以及两种特征提取算法的比较Tab.1 Data analysis results and contrast of two feature extraction methods
3.2 BCI2003竞赛数据处理结果
3.2.1 数据描述
数据取自一个健康的被试,为BCI2003竞赛Data Set Ia的标准数据。被试按要求对计算机屏幕上的一个光标进行向上或向下的移动,同时他的皮层电位被记录下来。在记录的同时将其皮层慢电位(Cz-乳突)通过视觉的方式反馈给被试[9]。正皮层电位将会使屏幕光标向下移动,而负电位将使光标向上移动。
刺激间隔为6s。对于每次试验,从开始后0.5s到试验结束,将会在屏幕的上部或下部高亮显示一个目标,被试的任务就是根据这一目标所表明的正向或负向含义进行相应的活动。视觉反馈的呈现时间为第2s到第5.5s。本数据集将每次试验仅取这3.5s的数据用于训练和检验。采样频率为256Hz,因此每个导联将得到896个样本点。
EEG记录来自6个位置:A1,A2,C3f,C3p,C4f,C4p,参考电极为Cz。共有268个训练样本,293个检验样本。训练样本中前135个为光标向下(类别“0”),后133个为光标向上(类别“1”)。数据分析的目标是依据这些原始数据将检验样本的类别“0”与“1”正确区分。
3.2.2 特征提取处理结果
以小波变换分解系数、子带系数均值和小波熵作为初始特征向量,以Fisher距离指标作为特征的可分离性度量,针对所采用的数据背景,各子带系数的选取比例设为:30%、35%、23.5%、12.9%、5%、2%、0.22%,小波分解的不同尺度为j=1,2,…,6,最终获得特征向量。图1表示通道1获取的特征量分布情况,每个通道共43维,系数分布取36维,系数均值分布取1维,小波熵为6维。为了更清晰地显示两类样本的分类效果,如图2所示。
3.2.3 分类算法处理结果及分析
1)改进的基于自训练半监督的支持向量机
文献[6]中自训练半监督SVM算法中的初始训练样本是固定的,这是由于训练样本数较少的关系,但针对本实验数据,为了充分利用已知标注的训练样本,算法中将不断更新初始训练样本。

图1 训练样本的通道一特征量分布Fig.1 The feature distribution of train data

图2 训练样本的通道一特征量分布Fig.2 Two-dimension feature distribution of train data
更新方法:初始样本量为50(已标注的),然后以20为递增量,将上一轮的测试样本的最终标注及相应的样本加入初始样本中训练SVM,更新次数根据测试样本量的大小而定,递增量可变。
分别以不同的特征量来验证该分类器的有效性,结果如下:
特征1:只以小波分解系数和子带系数均值为特征量,每个通道37维。由于特征维数的大小会影响SVM的分类效果,所以对特征量进行了均值化降维处理,得到的最终样本维数为12。
特征2:以小波变换分解系数、子带系数均值和小波熵作为特征向量,每个通道43维。降维处理后得到的特征量维数是18。
如图3所示,对于特征一的分类结果,最高分类正确率为88.40%,而基于改进的特征量的分类结果有了显著的提高,最高达到91.13%。经过计时,它们的收敛时间相差约5s,而且从曲线的趋势来看,特征二能够很快地达到一定的分类精度,有利于今后实现实时在线的工作。这里,特征量经过降维处理后达到很好的分类效果,说明对于该分类器,过多的原始特征向量反而造成分类时的干扰。

图3 改进的基于半监督的SVM的分类正确率曲线。(a)针对特征1;(b)针对特征2Fig.3 The classification accuracy using improved semi-supervised SVM classifier.(a)feature 1;(b)feature 2
2)基于自训练半监督的K均值聚类
对由小波系数、子带系数均值和小波熵组成的258维特征量进行模式识别,分别采用K均值聚类法和改进的基于自训练半监督的K均值聚类法来分类测试样本,实验结果如下:
①单纯的K均值聚类:如果所有特征量都加入,分类正确率为87.03%;如果只加入43维的特征量(即一个通道的特征量),则分类正确率为72.01%
②K均值+半监督:对于所有训练样本,在加入43维特征量的情况下,最优的结果是90.10%
分类器②比较稳定,而且花费的时间很短,达到的分类正确率也比较理想。
3)算法比较
分别用BP神经网络、基于半监督的支持向量机和基于自训练半监督的K均值聚类算法对特征一和特征二进行训练和识别,结果见表2。
显然,本研究提出的两种基于自训练半监督的改进方法,相比于BP网络,大大提高了收敛速度,有效地减少了训练时间,并且比较可靠稳定。其中,改进的支持向量机对特征量的维数要求较高(通常需要降维),但同时能很好的分辨特征量的不同组合;而改进的K均值聚类法则对特征量的变化不太敏感,但需要大量的特征量来支持。

表2 不同特征量组合下三种分类方法的分类精度的比较Tab.2 The accuracy rates of three classification methods in different features
4 结论
实验结果表明,本研究提出的新的小波特征量组合法以及改进的基于自训练半监督SVM和K均值聚类法,能够有效地从自发脑电中提取出皮层慢电位,使被试实现对光标控制,不仅获得较为理想的分类正确率,而且在训练时间和收敛速度上有所贡献,为在实际系统中应用奠定了基础,为脑机接口的研究提供了一种更加实用、更加自然的控制方式。
[1]Qi Limei,Li Xiaofeng,Zhang Guozhu.Wavelet transform theory and its application in signal processing[J].Journal of the University of Electronic Science and Technology of China,2008,37(3):386-388.
[2]杨帮华.自发脑电脑机接口技术及脑电信号识别方法研究[D].上海:上海交通大学,2007.
[3]He Zhengyou,Liu Zhigang,Qian Qingquan.Study on wavelet entropy theory and adaptability of its application in power system[J].Power System Technology,2004,28(21):17-21.
[4]He Zhengyou,Chen Xiaoqing,Luo Guoming.Wavelet entropy measure definition and its application for transmission line fault detection and identification(part I:Definition and methodology)[A].In:International Conference on Power System Technology 2006[C].Chongqing:IEEE,2006.1-6.
[5]周开利,康耀红.神经网络模型及其MATLAB仿真程序设计[M].北京:清华大学出版社,2005.
[6]Li Yuanqing,Li Huiqi,Guan Cuntai,et al.A self-training semisupervised support vector machine and its application in brain computer interface[A].In:IEEE International Conference on Acoustics,Speech and Signal Processing[C].Honolulu:IEEE,2007.385-388.
[7]李建勋,柯熙政,郭华.小波方差与小波熵在信号特征提取中的应用[J].西安理工大学学报,2007,23(4):365-368.
[8]徐义峰,陈春明,徐云青.一种改进的K-均值聚类算法[J].计算机应用与软件.2008,25(3):.275-277.
[9]Hinterberger T,Mellinger J,Birhaumer N,et al.The thought translation device:structure of a multimodal brain-computer communication system[A].In:Proceedings of the 1st international IEEE EMBS Conference on Neural Engineering[C].Capri Island:IEEE,2003.603-606.
