基于可解释极端随机树模型的DCT 液压响应预测
2023-12-08赵宗琴冉若愚皮家甜
李 想, 王 鑫, 蔡 辰, 赵宗琴, 冉若愚, 杨 德, 皮家甜
(1.重庆师范大学,重庆 401331;2.重庆长安汽车股份有限公司,重庆 401120)
汽车是现代社会不可或缺的交通工具之一,而变速器无疑是传统燃油车甚至混合动力汽车中必不可少的一部分。其中,在各类自动变速器中,湿式双离合器变速器因其具有动力损失小、换挡时间短、更佳的燃油经济性等优点[1],目前被广泛应用于燃油车、插电式混合动力汽车中。DCT变速器通过液压系统作为执行动力源控制离合器和拨叉动作实现动力传动比切换,DCT执行换挡操作时,动力要在两个离合器之间来回切换,液压系统产生液压力去完成换挡同步器以及离合器执行机构的操作[2-3]。
DCT 液压响应对DCT 平稳换挡具有十分重要的意义,关系到驾乘人员的驾驶体验,也是研究基于数据驱动的方法在DCT 控制逻辑优化方面的重要部分。为进一步提升换挡品质以及优化控制策略,众多学者以及DCT 生产商也对DCT 进行着持续深入的研究。饶坤等[4]提出一种离合器压力非线性鲁棒控制策略。戴冬华等[5]基于离合器压力控制阀的压力和电流特性在半结合点附近的非线性关系设计了DCT 半结合点自学习控制策略。然而,影响DCT 变速器执行性能的因素很多,包括液压电磁阀的制造差异、离合器弹簧及间隙、油瓶状态、残余油量等,而上述传统的控制策略很难全面考虑诸多因素以及硬件误差带来的影响。随着机器学习方法日益成熟,基于数据驱动的方法也逐渐被用于DCT 领域。刘永刚等[6]提出了基于数据驱动的双离合器自动变速器换挡过程的自适应控制。王蒙蒙等[7]研究了基于数据驱动的DCT 起步策略智能控制。万有刚等[8]利用集成学习算法挖掘DCT换挡数据中蕴含的控制规律等。这些研究在一定程度上验证了基于数据驱动的方法在DCT 方面的可行性,但是基于数据驱动的方法在DCT 控制逻辑中的研究仍然不足。
为探究DCT 液压响应预测方法,本文收集了大量包含了不同工况下的DCT 数据,为模型训练提供了坚实的数据基础。但在训练数据集中,特征数量和预测结果并非一定成正比[9],过多的特征反而可能导致预测精度下降,还会大大增加训练开销[10-11]。如果直接基于人工挑选重要特征,可能导致结果不准确。为建立一个能对重要特征进行可视化选择,且能精准预测DCT 液压响应的模型,本文提出了一种基于SHAP 可解释极端随机树算法的液压预测模型。先绘制特征值图形结合数据的实际物理含义初步删除其值变化小以及没有意义的特征,再利用SHAP 法可视化选择重要特征,最后训练模型并进行预测。同时,将时间切片作为特征参与模型训练,结合某汽车公司DCT 实验室获取的数据,预测结果表明,该模型预测的结果在设计误差允许范围内,预测液压结果较精准,一定程度上解决了不同工况以及硬件误差带来的执行精度不可控的影响,可以为基于数据驱动的控制逻辑优化提供较准确的结果。
1 问题描述
DCT通过液压系统作为执行动力源控制离合器和拨叉动作实现动力传动比切换,但DCT 变速器不同样本、不同工况下的液压系统执行精度响应不完全可控。DCT 换挡示意图如图1 所示。究其原因,除了制造差异等工程问题外,DCT控制策略容差能力也是重要原因之一。而控制策略容差能力主要体现在DCT自适应学习与补偿策略方面。
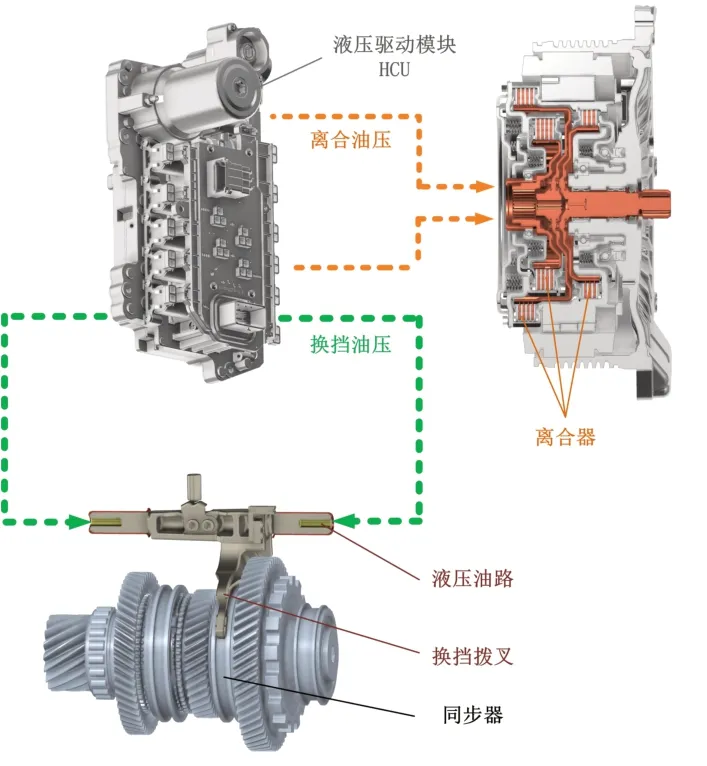
图1 DCT变速器通过液压模块控制离合与换挡示意图
由PPV 电磁阀阀芯平衡方程可知,当电流较小时,如果要对压力进行控制,电磁力需要克服与运动趋势反向的摩擦力、弹簧力、出口压力腔反馈压力[12]。PPV 电磁阀示意图如图2所示,电磁阀阀芯平衡方程如式(1)所示。同时,由于PPV 电磁阀设计有正遮盖量,电磁阀在小电流区域无法克服正遮盖行程及摩擦力,阀口无法打开致使压力为0,该电流区域称之为压力死区。PPV 电磁阀还具有压力迟滞与径向不平衡力等缺陷,导致压力响应精度不可控。压力死区与压力迟滞如图3 所示。目前,业界广泛采用自学习策略与补偿策略来适应不同工况下压力响应的差异。由于温度发生变化导致油压变化,而传统的物理模型无法预测不同温度下油压的数值,导致换挡品质不高。而基于数据驱动的自学习策略可以在不同温度下学得最适合当前状态的换挡油压,结合物理模型以期能满足各工况下的性能要求。因此,本文重点探究利用数据预测压力响应方法,为基于数据驱动与物理模型相结合的控制策略提供预测结果。
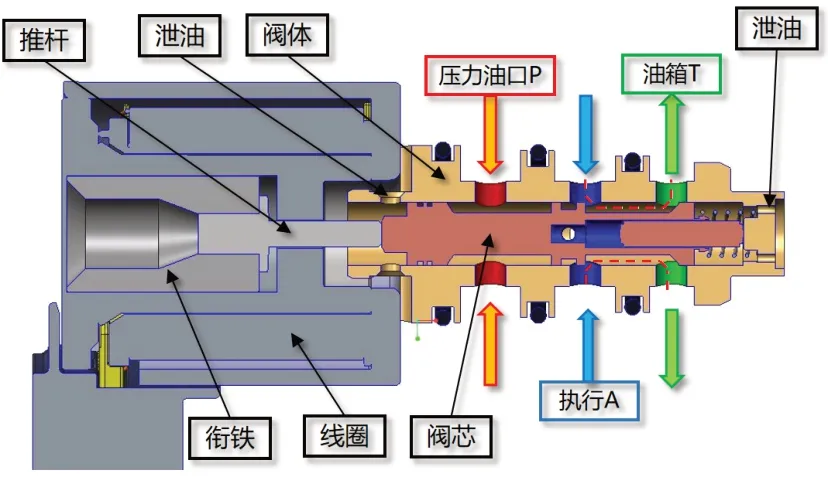
图2 PPV电磁阀(常态位)

图3 压力死区与压力迟滞示意图
式中:Fe为电磁力;Ff为摩擦力;Fbs为稳态液动力;Fs为弹簧力;Fp为出口压力腔反馈压力。
2 数据与模型
2.1 数据集
本文利用的数据集为某汽车公司DCT 试验室采集的真实DCT 数据。主要包括DCT 在不同温度工况下的数据,具体温度工况见表1。采集的原始数据共计73 个特征,1 个标签,具体特征见表2,其中TRANS_bar_ClPressure 为标签值,其余为特征。该模型须能预测出不同温度下的液压响应,因此,将温度(temperature)也作为一条特征变量。由于原始数据量较庞大,为了方便试验,本研究在上述数据集中,在每一种温度工况下选取8 万条数据,共计64万条数据。

表1 不同温度工况

表2 数据的全部特征
2.2 可解释性ET模型
集成学习[13]是组合多个个体学习器,从而获得比单一学习器性能更优的模型。目前在多个领域已经取得较好应用,如李恒杰等[14]利用集成学习预测电动汽车充电桩超短期负荷;贾志强等[15]使用XGBoost模型对消费行为进行预测;OGUNLEYE等[16]使用XGBoost 为慢性肾脏病(Chronic Kidney Disease,CKD) 提供了早期廉价的诊断方法;GUPTA 等[17]对比了随机森林、线性模型、支持向量机神经网络等模型预测新冠肺炎(Corona Virus Disease 2019,COVID-19)病例的确诊、治愈和死亡数据,发现随机森林(Random Forest, RF)模型的准确率最高。
极端随机树(Extremely Randomized Trees,ET)[18]模型属于集成学习,它和随机森林[19]类似。随机森林是Bagging 的一个扩展变体,其个体学习器是CART 决策树。其继承了Bagging 的随机选择样本,同时增加了属性随机,即在当前节点的属性中随机选择包含k个属性的子集,然后从这个子集中选择一个最优属性用于划分。而ET 和RF 不同的是ET 模型使用全部的样本,且完全随机选择特征进行分裂。在本研究中,相较于其他几个对比模型效果更好,具有更高的抗拟合能力以及更好的泛化性。ET模型决策过程如图4所示。
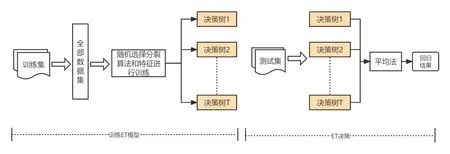
图4 ET模型决策过程
SHAP(Shapley Additive exPlanations)[20]是机器学习中用于解释模型输出的方法,可以通过计算每个特征对预测标签的贡献来解释结果。模型的准确率和可解释性同等重要,但是模型越复杂准确率越高,其可解释性越差,面临着准确率和可解释性的矛盾[21]。而SHAP 方法可以计算特征的全局重要性,并将特征根据重要性进行排序,比直接采用经验判断特征重要性具有更高的准确度。
为清楚地对比本研究采用模型相较于其他对比模型的准确性和有效性,选取平均绝对值误差(MAE)、均方误差(MSE)以及可决系数(R2)3个指标进行比较。其中以MSE 为主要衡量指标,MSE反映预测值与真实值的误差,该值越小,则误差越小。R2表示可决系数,其取值范围为[0,1],越接近1 表明模型效果越好。MAE、MSE 及R2如式(2)所示。在数据集1,即只包含表4 中所示特征的数据集上,本文模型和其他模型的结果对比见表3。由表3可知,基于可解释ET模型的MSE要低于其他几个模型。
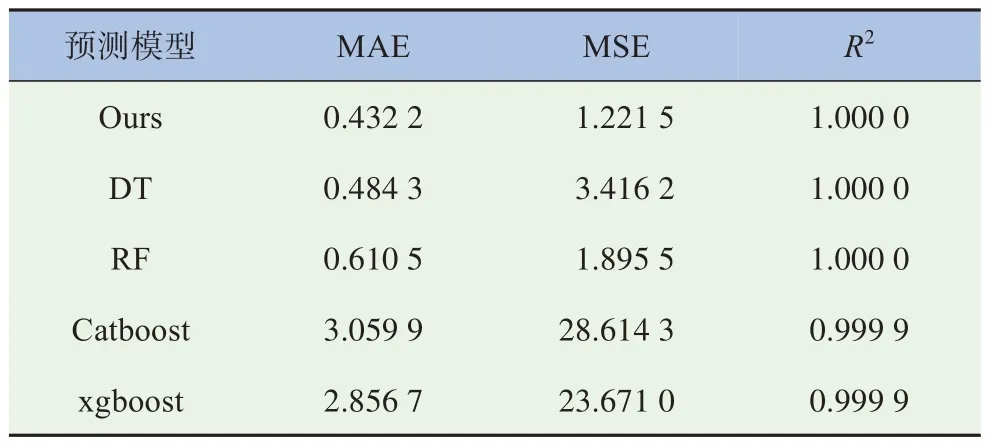
表3 本文所使用的模型和其他模型结果对比

表4 删除无关特征后的剩余特征
式中:MAE 为平均绝对值误差;MSE 为均方误差指标;R2为可决系数;y为液压响应实际数据;为模型预测的液压响应值;为液压相应实际平均值。
2.3 模型建立
根据本文提出的模型设计了如下试验。首先对传感器采集的多项关于DCT 的数据进行清理,通过绘制特征值的折线图,可以发现很多的恒值特征,再结合实际物理模型对结果预测的先验知识,发现这一部分特征对于液压响应计算影响不大。因此,可以将这一部分特征删除,初步减少数据维度,然后输入模型进行训练。接着使用SHAP 算法对结果进行解释,将重要特征可视化排序。同时通过SHAP 图可发现该数据和时间具有一定关系,因此,试验2 将时间处理成切片并输入模型进行训练和验证。最后,由于汽车ECU 计算能力有限,为了工程化考虑,试验3 仅保留几个最重要的特征并进行训练,最后输出结果。具体流程如图5所示。
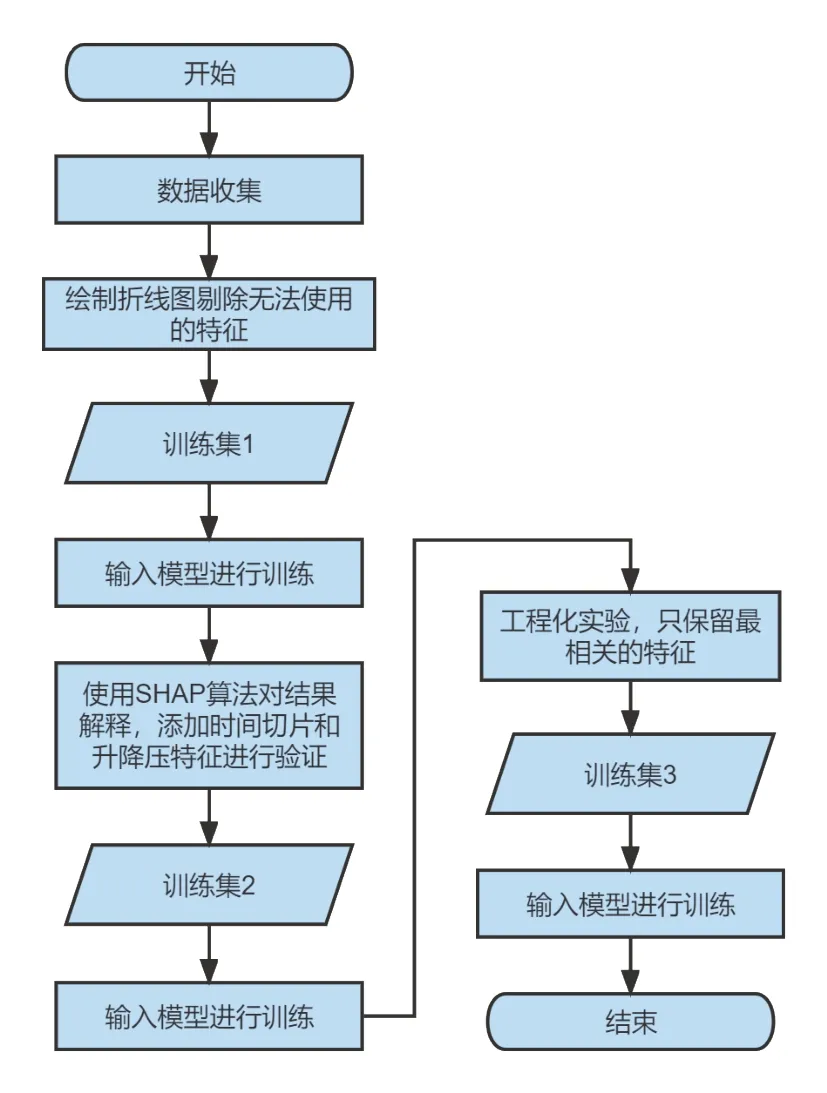
图5 可解释ET模型预测流程
3 结果与分析
3.1 数据集划分
本研究的目标是利用特征变量预测DCT 液压响应,即表2 中红色标签。考虑到实际应用需要,本研究将误差设计为25 kPa以内。同时为了探究模型在高温工况下的表现,将数据集中120 ℃工况下的数据作为测试集,测试模型的实际预测效果。为保证较好的训练结果,本研究在训练时采用10 折交叉验证[22],10 折交叉验证是将原始数据随机划分为几乎相等的10份,每次轮流使用其中9个作为训练集,剩余1个作为测试集,总共轮流10次。
3.2 特征分析
3.2.1 保留恒值以外特征试验
为了可以更加全面地收集数据,投入了大量传感器采集原始数据,由此导致原始数据维数过多,如果直接采用算法选择重要特征,会造成计算时间太长,而且可能计算不准确。因此,本试验先绘制出了特征值的图形,可以发现很多特征值为恒值,为恒值的部分特征如图6 所示,图中红色表示标签值,蓝色为特征值。对于树模型这些特征无法使用,可以直接删除,保留除恒值以外的特征后形成数据集1,作为试验1。删除恒值特征后剩余的特征见表4,可以看到,数据已由表2 中的74 维降至表4所示的43维,大大减少了数据维度。
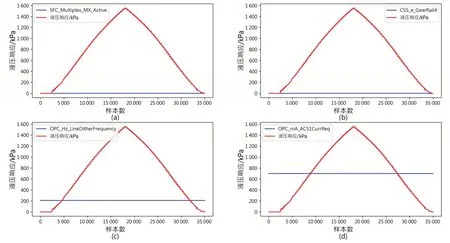
图6 一部分值为零值(a和b)和恒值(c和d)的特征
3.2.2 添加时间切片及升降压判定试验
在SHAP 图对模型结果分析后,发现时间对结果具有一定影响。经过对标签值图形观察后,发现其具有一定规律。具体来说,在一定时间周期内,液压响应的波形先上升后下降,即先升压后降压,为了区分升降压阶段而添加升降压标志。同时时间也应该随着压力变化而周期性变化,但数据中原始时间是不断上升的(见图7 绿色实线),不利于模型学习时间与液压响应之间的关系。因此,将时间进行切片,液压响应值变化后时间重新从0 开始计算,选取液压响应上升时的一段数据进行绘图,说明液压与时间的关系。时间切片及升降压判定特征示意图如图7 和图8 所示。图7 中红色线段代表压力,可以看到压力每变化一次,时间都重新从0 开始。由图8 可知,压力上升阶段标志为1,而下降阶段标志为0。SHAP图解释模型结果如图9~10所示。图9 中横轴表明特征的重要程度,数值越大说明该特征越重要。试验2 在试验1 的数据中增加了升降压判定以及时间切片特征,形成数据集2。
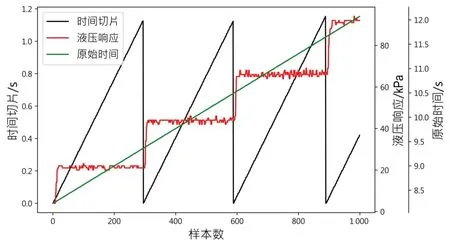
图7 原始时间、切片时间与压力之间的关系

图8 升降压标志示意图
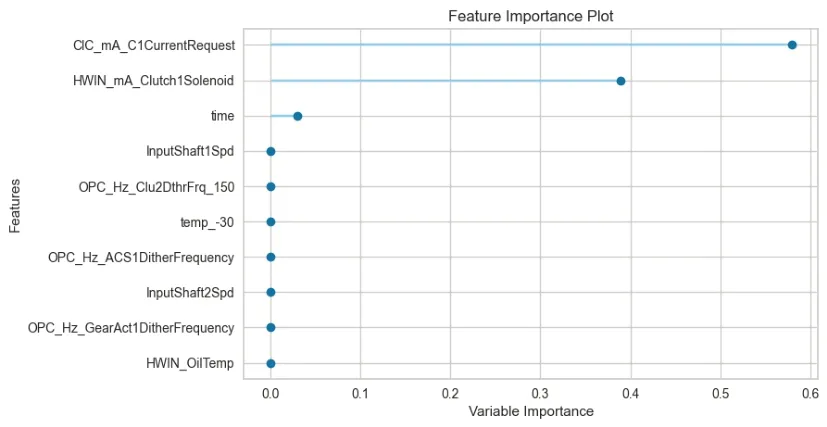
图9 SHAP特征重要性分析图
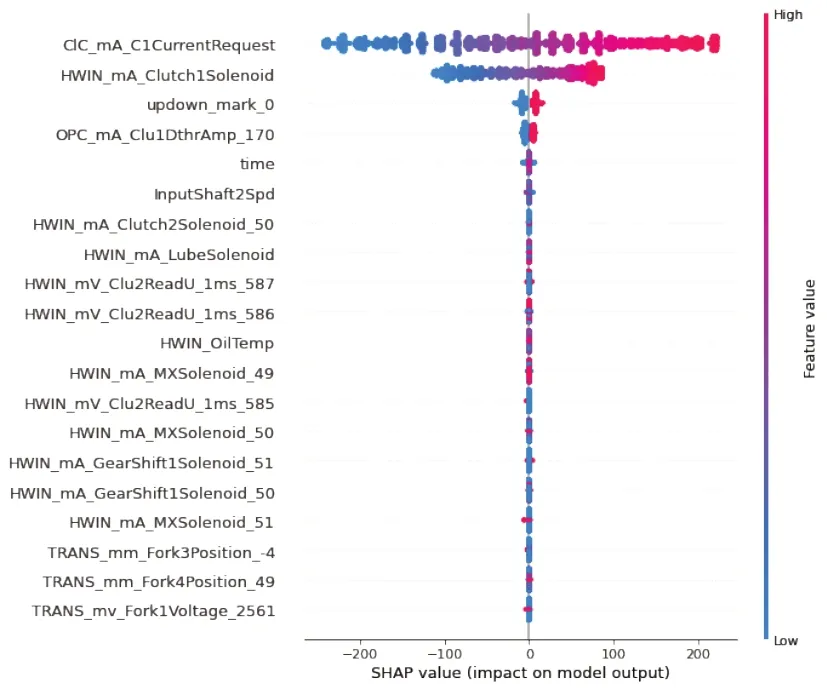
图10 SHAP摘要图
SHAP 图会显示比较重要的一些特征及其重要度。图中每一行代表一个特征,横坐标为SHAP值,越靠前说明特征越重要。一个点代表一个样本,颜色越红说明特征本身数值越大,颜色越蓝说明特征本身数值越小。由图9~10 可知,请求电流(mA_ClCurrentRequest)和时间(time)对结果影响较大。
3.2.3 重要特征可解释选择试验
由于车辆ECU 并不具备实验室环境下的高算力,所以需要将模型轻量化,即只保留最重要特征。基于试验2 中SHAP 算法对重要特征的选择,且考虑到模型需要预测不同温度(temperature)下的液压响应,因此,试验3保留了如表5所示的4个特征,形成数据集3,作为试验3训练数据。表5中“TRANS_bar_Cl1Pressure”表示需要预测的标签,“time”表示时间切片属性,“temperature”表示温度属性,“updown_mark”表示升降压判定属性,“ClC_mA_C1CurrentRequest”表示电流属性。

表5 工程化模型训练所需特征
3.3 试验结果分析
在建立好的3 个数据集上分别进行训练以及预测,表6 为3 次试验的10 折交叉结果的平均值,评估指标使用MAE,MSE 以及R2,其中以MSE 作为主要评估指标。从MSE 结果可以看出,添加时间切片(第2 次试验)的MSE 比没有添加时间切片(第1 次试验)的MSE 降低了0.551 2,这表明添加时间切片以及升降压标记对模型精度提升有促进作用,同时也说明SHAP 法选择的特征是正确的。轻量化试验(第3 次试验)的MSE 比第1,2 次试验结果高很多,但训练时间相比于1,2 次试验短很多(Time/s 下的时间是在64 GB 2.9 Ghz 的CPU 上的训练时间,不同机器的时间可能有所差异),且训练误差仍然可接受误差以内,更适合工程化应用。3次试验结果见表6所示。
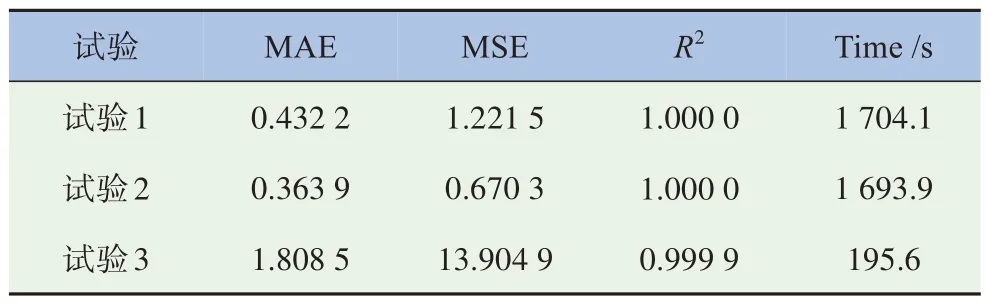
表6 三个试验结果对比
为了进一步验证模型的精确度,说明模型的预测结果,本研究在测试集上做进一步的测试,并且将模型预测的预测值和实际值对比。将每个样本的预测值和实际值差值的绝对值做平均(MAE),如表7 所示。图11 展示了3 个试验结果的预测值和实际值的曲线对比,图12展示了3个试验真实值和预测值的差值。可以发现,试验3 在测试集上的效果最好,与真实值贴合最紧,说明模型具有较好的泛化能力。

表7 不同模型实际值和预测值差值的均值
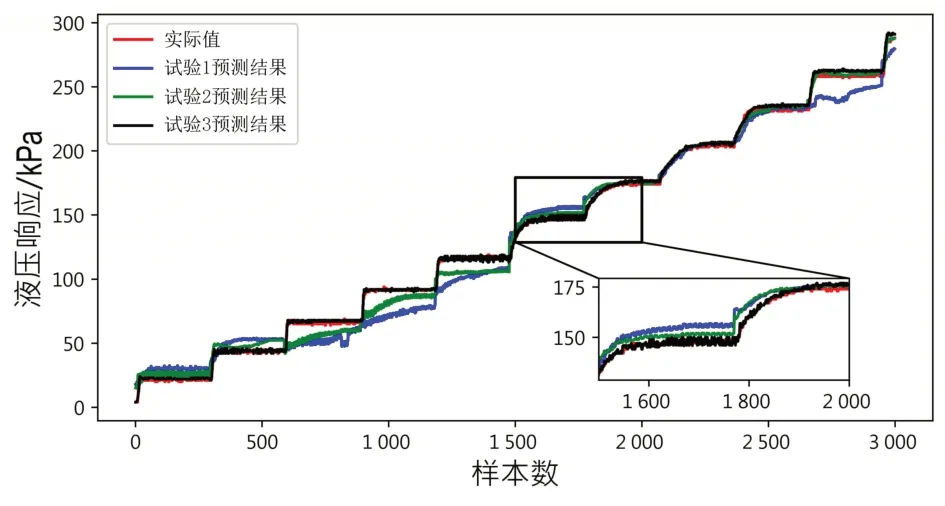
图11 不同试验预测结果和实际值对比图
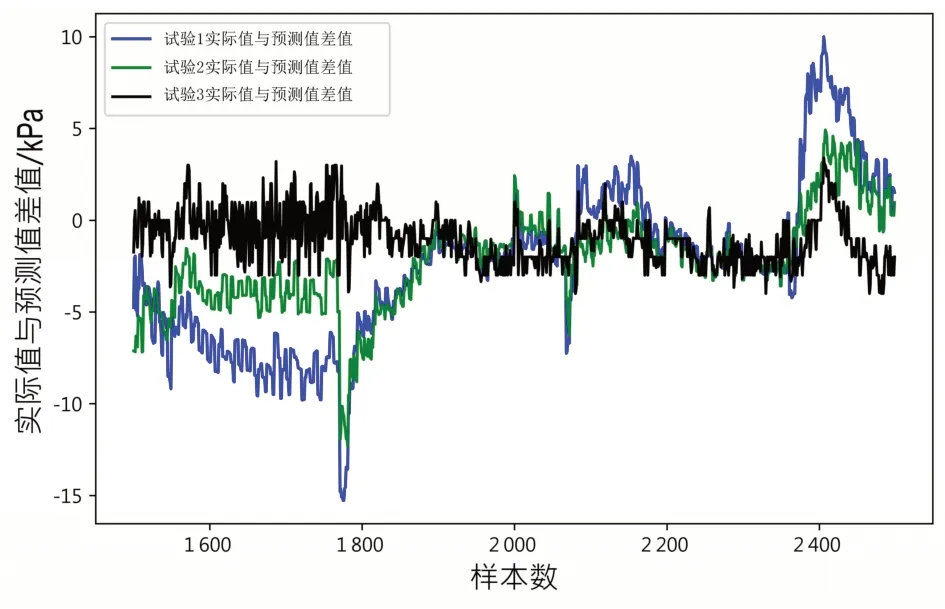
图12 不同试验实际值和预测值的差值图
4 结论
为了探究DCT 液压响应预测方法,本文提出了一种基于SHAP可解释的ET模型。利用SHAP算法筛选重要的特征变量,作为ET 模型的输入,构建预测模型。通过对比试验可知,基于SHAP 可解释ET模型具有以下优势:
1)该模型可以较准确地预测液压响应,为基于数据与物理双驱动的控制方法提供较准确的预测结果;
2)利用SHAP 算法可以对重要特征进行筛选,并且具有良好的解释性,可以降低训练数据维度,减少训练时间,同时又不会降低预测精度;
3)加入时间切片和升降压判定属性后,模型MSE 降至0.670 3,降低了0.551 2,说明时间序列对液压结果有一定影响。
本试验结果可直接运用于工程实际,在整车标定时,可参考试验得出的液压响应时间和跟随效果值。
