雾网络中基于统计分布的内容缓存与交付方案*
2023-12-25陈昊宇胡宏林
陈昊宇,胡宏林
(1.中国科学院上海高等研究院,上海 201210;2.中国科学院大学 电子电气与通信工程学院,北京 100049)
0 引 言
随着智能移动设备(如智能手机、平板电脑、可穿戴设备等)的发展和普及,用户对低延迟移动应用程序和多媒体服务的需求大幅增加,这导致了数据流量的爆炸性增长,对未来网络设计形成了挑战[1]。文献[2]中预测:到2023年,连接到IP网络的设备数量将超过全球人口的3倍,其中物联网(Internet of Things,IoT)连接将占全球在线设备和连接数量的一半,5G设备和连接则占据10%以上。通过整合云计算和无线接入网络,云无线接入网络(Cloud Radio Access Network,C-RAN)为满足无线通信系统发展带来的巨大算力与带宽需求提供了可能性[3]。然而,在C-RAN正面临着前传容量受限等一系列挑战的同时[4],集中式云计算能力的线性增速已逐渐与边缘数据的需求拉开差距[5]。为了解决上述问题,进一步整合云计算和雾计算则产生了新的雾无线接入网络(Fog Radio Access Network,F-RAN)架构[6]。它将大量存储、通信和控制功能转移,在网络边缘扩展了传统的云计算范式[7]。在F-RAN中,缓存用户(Caching Users,CUs)和雾无线接入节点(Fog Radio Access Point,F-AP)组成了容量有限的内容服务器,直接向请求用户(Requesting Users,RUs)交付已被缓存的内容。通过避免内容重复传输以及缩小与用户间的物理距离,F-RAN可以节省大量核心网络和回程传输的资源消耗,有效减少用户的服务延迟,进而提高用户体验质量(Quality of Experience,QoE)[1,8]。
内容分发网络(Content Delivery Network,CDN)和信息中心网络(Information Center Network,ICN)等架构对缓存技术的成功实践证明了在移动网络中部署内容缓存的合理性与可行性[5]。然而,一方面互联网与移动网络内容缓存机制的巨大差异使得传统基于CDN的缓存技术在移动网络中无法直接应用;另一方面,与一般移动边缘计算(Mobile Edge Computing,MEC)网络相比,F-RAN能够凭借更强的算力同时处理更多的数据[9]。因此,充分利用F-AP和CUs等边缘设备的缓存、计算和通信能力,方便RUs快速访问和检索内容,对于减轻前传、后传甚至云端和主网的流量负载,有效节约网络带宽和能耗具有重要意义[6,10]。作为提高F-RAN性能的关键组件,如何缓存有使用价值的数据几乎决定了不同终端的服务质量(Quality of Service,QoS)能否得到保证,这导致内容缓存策略的优化成为了F-RAN边缘缓存研究的热点[11-12]。
关于F-AP处的缓存策略,目前已经有丰富的研究[13-15],主要考虑了用户和缓存内容本身的各种特性。然而,这些F-RAN边缘缓存场景中并未考虑D2D技术的应用。事实上,CUs可以与邻近的RUs共享缓存数据,利用D2D链路直接向RUs提供服务。该技术对于F-RAN在延迟和传输成本等内容交付方面的显著性能提升已经得到了研究和验证[11,16]。
上述关于F-RAN环境下F-AP与D2D设备合作缓存的研究主要从各个节点的角度考虑它们与内容集的具体映射关系,这相当程度上削弱了所有D2D设备形成的缓存空间的整体性。然而,若因系统随机性而采取一段时间内的期望视角,在CUs具备显著内容交付优势的前提下,直接优化CUs缓存命中率是必要的。因此,本文主要以一个包含单个F-AP和多个D2D设备的F-RAN系统为研究对象,通过数学证明探究有关建模与内容统计分布之间的联系,从而导出优化目标并设计关于一般优化问题的求解算法。针对边缘存储,本文提出了基于统计分布的内容缓存与交付方案,实现了CUs缓存命中率的近似全局最优解,同时验证了相应交付方案对于优化平均下载延迟的有效性。
1 F-RAN系统模型
1.1 网络模型
本文考虑一个包含多个D2D设备的典型F-RAN系统,如图1所示,其中共包含了一个功能完善的云计算中心(Cloud Computing Center,CCC),一个F-AP,多个CUs和多个RUs。在该网络结构下,F-AP位于其覆盖区域中心,可以通过前传链路传输并缓存来自CCC的内容,也可以通过无线链路直接服务这一区域内的所有CUs和RUs。

图1 F-RAN系统模型

1.2 内容缓存与用户请求模型
本文将内容的流行程度视为用户请求相应内容的概率,并假定该信息可以由CCC端基于大量用户请求数据定期获取。当缓存空间有限时,设CCC服务器存储了一个大小为N的总体内容库C={c1,c2,c3,…,cN},其中ci(i∈{1,2,…,N})表示所有内容中第i流行的内容文件。随着RUs实际请求的发生,该库及其包含的流行度信息将定期更新,下一步F-AP和CUs即可根据预先制定的缓存策略更新它们存储的内容集,以便RUs在后续的一段时间内通过不同链路直接取得已被缓存的内容。设F-AP本地存储空间大小为NF,执行最流行内容缓存(Most Popular Content Cache,MPC)策略[17],缓存了CCC端最流行的NF个内容,则F-AP缓存的内容集为CF={c1,c2,c3,…,cNF}。此外,假设单个CU本地存储空间的大小为NC,其缓存的内容集CC为CF的一个子集,由F-AP经无线链路直接传输获得。综上所述,显然有N>NF>NC。CUs内容集的形成方法即为本文主要讨论的内容缓存方案。
针对用户请求模型,本文规定F-AP覆盖区域内所有RUs都首先将它们的内容请求发送给F-AP。不失一般性,令CCC服务器所存储的所有内容都有相同的大小s,且用户请求内容ci的概率服从Zipf分布,则pi有表达式如式(1)所示:
(1)
式中:β是控制受欢迎内容集中程度的Zipf指数[18],当β的值逐渐增大时,越来越多的用户请求会向越来越少的高流行度文件集中[19]。
1.3 内容交付模型
当F-AP接收到RUs的内容请求以后,系统将处理这些请求,然后交付相应内容,并于期间产生一定的下载延迟。此处有关下载延迟的具体定义为F-AP接收到内容请求至请求内容完成交付之间所经历的时间。假设每个RU请求到达都遵循独立泊松过程,且有相同的强度(到达率)λ(请求数/秒),即每个RU平均每秒发出λ个请求。对于不同RU的不同请求,F-AP接收后有3种服务模式可供选择。
1.3.1 CCC模式
当RUs请求的内容ci∉CF时,F-AP就会通过前传链路向CCC端转发该信息。收到指令之后,CCC端则可通过高功率节点(High Power Nodes,HPNs)直接向RUs提供此类流行度较低的突发性内容[6]。设CCC模式经历的下载延迟为固定常数t。
1.3.2 F-AP模式
当RUs请求的内容ci∈CF时,若满足下列条件之一,则请求的内容由F-AP直接交付给RUs:
1)在距离某个RU不超过RC的范围内没有CUs存在,或存在若干个CUs但都未缓存内容ci时;
2)在距离某个RU不超过RC的范围内,存在一个缓存了内容ci的CU,但F-AP按照一定的概率判断其交付内容所需的时延过长,不适宜为该RU提供服务时。
本文假设F-AP有足够强的服务能力,可以同时传输大量内容,因此对于随机到达的RUs请求,F-AP不会形成内容请求队列。令F-AP到RUs的数据传输速率为rF,则该模式经历的下载延迟为ci从F-AP传输到相应RU所需要的时间,即tF=s·rF-1。
1.3.3 CUs模式
当RUs请求的内容ci∈CF时,若在距某个RU不超过RC的范围内存在一个缓存了ci的CU,且F-AP按照一定的概率判断其适合提供服务,则ci由该CU交付给该RU,具体分为两步:
1)F-AP首先识别出适合的CU,向其发送一条包含内容请求信息的指令,通知它准备交付内容;
2)收到指令后,CU再通过D2D链路向发出请求的RU交付内容。
本文假设CUs服务能力有限,最多同时传输一个内容,因此对于RUs随机到达的请求,每个CU都将形成一个内容请求队列。故该模式经历的下载延迟包括内容请求在队列中的等待时间及其所需的服务时间(此处服务时间由指令从F-AP传输到相应CU和ci从指定CU传输到相应RU两部分时延组成)。令F-AP发送指令部分的时延为tFC,CUs和RUs间的数据传输速率为rC,队列服务时间则可被表示为tC=tFC+s·rC-1。本文考虑把每个CU的内容请求队列都建模成独立的M/D/1排队模型,即请求到达服从泊松过程且服务时间固定[20]。
综上所述,包括F-AP判断某个CU是否适合提供服务的概率的具体计算方法在内,完整的模式选择方法即为本文主要讨论的内容交付方案。
2 内容缓存与交付方案性能分析
2.1 缓存命中率
本文选取了缓存命中率作为分析方案性能的一项指标,用PHC表示。它的定义为任意一个RU所请求的内容在其最大可通信范围内的某个CU处已被缓存的概率。因此,关于CUs缓存命中率的讨论与内容交付模型CUs模式下F-AP对相应CU是否适合提供服务的判断无关。同时,较大的PHC意味着CUs可以通过D2D链路满足更多的RUs内容请求。下面,本文将从内容统计分布的角度导出PHC的表达式。
假设缓存了内容ci的CUs在所有CUs中的占比为δi,δi∈[0,1],且任意一个RU位于一个半径为RC的圆形区域的中心。故缓存了ci的CUs在F-AP最大服务范围内的分布服从密度为δiγC的齐次PPP,根据二维泊松过程的性质,区域AC内存在m个此类CUs的概率如式(2)所示:
(2)
若令m=0,则式(2)给出了区域AC内不存在相应CUs的概率[21],即缓存未命中概率,那么至少有一个缓存了ci的CUs位于AC内的概率为1-Pi(m=0)。此外,由于RUs内容请求的概率分布一致且只与内容本身有关,当任意一个RU请求内容ci的概率都为pi时,仅考虑ci的缓存命中率如式(3)所示:
PHC,i=pi[1-Pi(m=0)]=pi(1-e-δiKCC)。
(3)
在放置CUs缓存的过程中,各个内容之间不涉及相关性。结合式(3)及上述定义,若要计算CUs能够交付任意一个请求内容的概率,可以对所有ci∈CF的PHC,i求和。CUs缓存命中率如式(4)所示:
(4)
同时易得,δi关于CUs本地存储空间大小的约束如式(5)所示:
(5)
2.2 平均下载延迟
本文还选取平均下载延迟作为分析内容缓存与交付方案性能的另一项指标,用DAC表示。它的定义为所有RUs长期经历的平均下载延迟。基于F-RAN的3种服务模式,本文需要对不同的内容交付链路进行讨论。
首先是CUs的M/D/1排队模型,这里面包括两个参数:平均请求到达率和平均服务率(队列服务时间的倒数)。假设GCU表示所有CUs组成的集合,GRU表示所有RUs组成的集合。对于任意一个RUx∈GRU,到达任意一个CUy∈GCU的内容请求遵循强度为λy(x)的泊松过程。参数λy(x)的表达式如式(6)所示:
(6)
式中:ηy∈(0,1]为CUy的交付系数,它表示F-AP判断CUy适合为RUs提供服务的概率;gy,i(x)为指示函数。若gy,i(x)=1则表示CUy是最接近RUx的缓存了内容ci的一个CU,且CUy和RUx之间的距离不大于RC;否则gy,i(x)=0。
因此,对于CUy处的泊松过程,它的内容请求总平均到达率λy的表达式如式(7)所示:
(7)
根据M/D/1排队模型的性质[22]和CUs处的平均服务率,CUy处的流量负载可以用系统中的平均内容请求总数Ly来表示。参数Ly的表达式如式(8)所示:
(8)
其次是F-AP模式,它虽然并不涉及排队模型或队列等待时间,但是不妨同样利用平均请求到达率和平均服务率两个参数加以理解(服务时间部分仍然成立)。对于F-AP处的泊松过程,内容请求到达的总平均速率为其能直接交付的所有RUs请求除去已通过CUs模式交付的部分。结合平均服务率计算,F-AP处的平均内容请求总数(即流量负载)始终为下载延迟期间内容请求到达的总量,故参数LF的表达式如式(9)所示:
(9)
最后,考虑到CCC模式的下载延迟,CCC处平均内容请求总数L的表达式同理可得如式(10)所示:
(10)
综合上述3种模式下的流量负载和排队理论的利特尔法则(Little's Law),上述模型有传输延迟方程[23]:系统长期平均请求数=长期平均请求到达率×系统长期平均请求等待时间。方程中有两项已知,即3种服务系统的总平均内容请求数,以及所有RUs请求的平均总到达率,而系统等待时间已经包括仅CUs模式涉及的队列等待时间和3种模式都涉及的服务时间两部分。因此,所有RUs内容请求经历的平均下载延迟如式(11)所示:
(11)
3 基于统计分布的内容缓存与交付方案
本文对F-RAN中内容缓存与交付问题进行建模,导出了方案评价指标的量化表达式,目的是寻找关键影响因素以最大化CUs缓存命中率,并验证优化结果对降低平均下载延迟的有效性。为了求解该模型引出的一般优化问题,本文将提出基于统计分布的内容缓存与交付方案,尽可能地提升内容缓存与交付方案的性能和用户体验。
从2.1节中PHC表达式导出的过程和结果可知,影响其大小的因素只有各个ci对应的δi。因此,为了最大化CUs缓存命中率,优化结果仅需考虑内容的整体统计分布,而与CF和GCU之间的映射关系无关。记缓存策略矢量Δ=(δ1,δ2,δ3,…,δNF)。本文所提方案的思路如下:通过计算求出最优Δ使PHC达到最大,再按定义将不同内容随机放置于一定数量的CUs本地存储空间以形成所有CC。基于统计分布的内容缓存与交付方案最优缓存命中率问题的最小化表述如式(12)所示:
(12a)
δi∈[0,1],i=1,2,…,NF,
(12b)
(12c)
tCλy=1-ξ,y∈GCU。
(12d)
式(12b)表示内容分布的统计结果是0~1之间的比例值;式(12c)表示实际缓存要完全占用CUs的本地存储空间;式(12d)中ξ为一较小正数,用于使得M/D/1排队模型的服务强度(即服务能力利用率:平均到达率与平均服务率的比值)小于1,以满足排队系统的稳定条件,保证不会形成无限队列。此处假定F-AP已经掌握了NC,KCC,β,λ,tC等必要信息。记式(12a)中目标函数-PHC=W(Δ),且一般而言KCF足够大,足以将δi视作连续变量,故容易求得函数W的一阶梯度和Hessian矩阵如式(13)和式(14)所示:
(13)
(14)
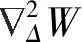
Q(Δ,μ,τ,λ)=W(Δ)-μΔT-μ(1-ΔT)+θ(‖Δ‖1-NC) 。
(15)
式中:不等式的约束矢量μ=(μ1,μ2,μ3,…,μNF)和τ=(τ1,τ2,τ3,…,τNF)各个分量均为非负,分别表示限制Δ中各个分量不小于0和不大于1所对应的约束系数;非零参数θ则为式(12c)对应的等式约束系数。
进一步地,上述一般优化问题还需要的求解条件如式(16)所示:
(16)
式中:运算符“∘”表示矩阵的哈达玛(Hadamard)积。
根据Zipf分布的性质,pi的大小将随着i的增大逐渐减小,因此,不难预计δi的变化也遵循相似态势,即Δ中需要在流行度较高的内容中出现尽可能多的1,而在流行度较低的内容中出现尽可能少的0。本文由此对δi进行分段讨论。
假设当1≤i≤NL时,δi=1,显然μi=0,故此时关于τi的约束如式(17)所示:
τi=piKCCe-KCC-θ≥0。
(17)
假设当NL+1≤i≤NH时,0<δi<1,显然此时μi=τi=0,故关于δi的约束如式(18)所示:
θ=piKCCe-δiKCC。
(18)
假设当NH+1≤i≤NF时,δi=0,显然此时有τi=0,故关于μi的约束如式(19)所示:
μi=θ-piKCC≥0。
(19)
综上,关于δi的求解方程组如式(20)所示:
(20)
(21)
式中:变量NL由不等式确定,具体计算方式为寻找满足式(22)的最大正整数。
(22)
另外需要说明的是,在不同内容关于CUs本地存储空间的随机放置完成以后,上述算法有必要通过交付系数保证自身的成功执行。计算后得到各个CUy∈GCU的交付系数ηy如式(23)所示:
(23)
至此,本文提出的基于统计分布的内容缓存与交付方案的具体描述如下:
输入:单个CU的本地存储空间大小NC,CUs最大通信范围内的CUs数量KCC,Zipf指数β,每个RU请求遵循的相同到达率λ,CUs模式的队列服务时间tC
输出:缓存策略矢量Δ,各个CUy∈GCU处的交付系数ηy

2 WhileNL′-NL>1

Else
End if
End while//用二分法求解NL;
3 Fori=1,NL
δi=1
End for//对Δ赋值;
按式(21)计算δi
End for//对Δ赋值;
δi=0
End for//对Δ赋值;
6 Fory∈GCU
按式(23)计算ηy
End for//计算所有的ηy,共KCF个。


图2 内容交付方案模式选择流程
4 仿真实验与结果分析
4.1 参数设置
针对基于统计分布的内容缓存与交付方案的仿真实验使用Matlab完成,通过执行具体F-RAN网络中的重复随机试验取得1 000组数据,依据其均值评估本文所提算法。仿真实验中使用的详细初始参数如表1所示。

表1 仿真实验基本参数
4.2 实验结果分析
本文选取了文献[12]中介绍的两种内容缓存与交付方案进行对比实验,通过仿真程序分别实现了基于概率(Probability-based,PB)的缓存策略、基于边缘缓存用户分类(Edge Caching Users Classification,EUC)的缓存策略以及基于统计分布(Frequency Distribution,FD)的内容缓存与交付方案,目的是验证本文所提方案分别在优化CUs缓存命中率和平均下载延迟方面的优越性和有效性。
图3展示了不同内容缓存与交付方案下,CUs缓存命中率随CUs分布所服从的齐次PPPΦC密度变化的情况。此处设置变量γC∈[2×10-4,10×10-4],Zipf指数β=0.5。由图3可以看出,CUs缓存命中率会随着CUs分布密度的增加而不断增加,但鉴于取整运算等原因,导致图像出现了数值跳变。不难理解,当γC数值较小时,CUs数量少,因而形成的整体缓存空间较小,能够缓存的内容也很少,这使得PHC的数值偏低。然而当γC的数值增大时,除了CUs形成的整体缓存空间增大外,单个RU周边存在CUs的概率也在增加。此时,本文提出的FD方案尽可能地考虑了CUs可提供服务的多样性,避免了单个RU周边存在CUs的数量变多时缓存内容重复而可能出现的无效缓存现象(内容已被缓存但没有机会进行交付)。因此,相较于其他内容缓存与交付方案,FD方案在CUs缓存命中率方面具有显著优势。
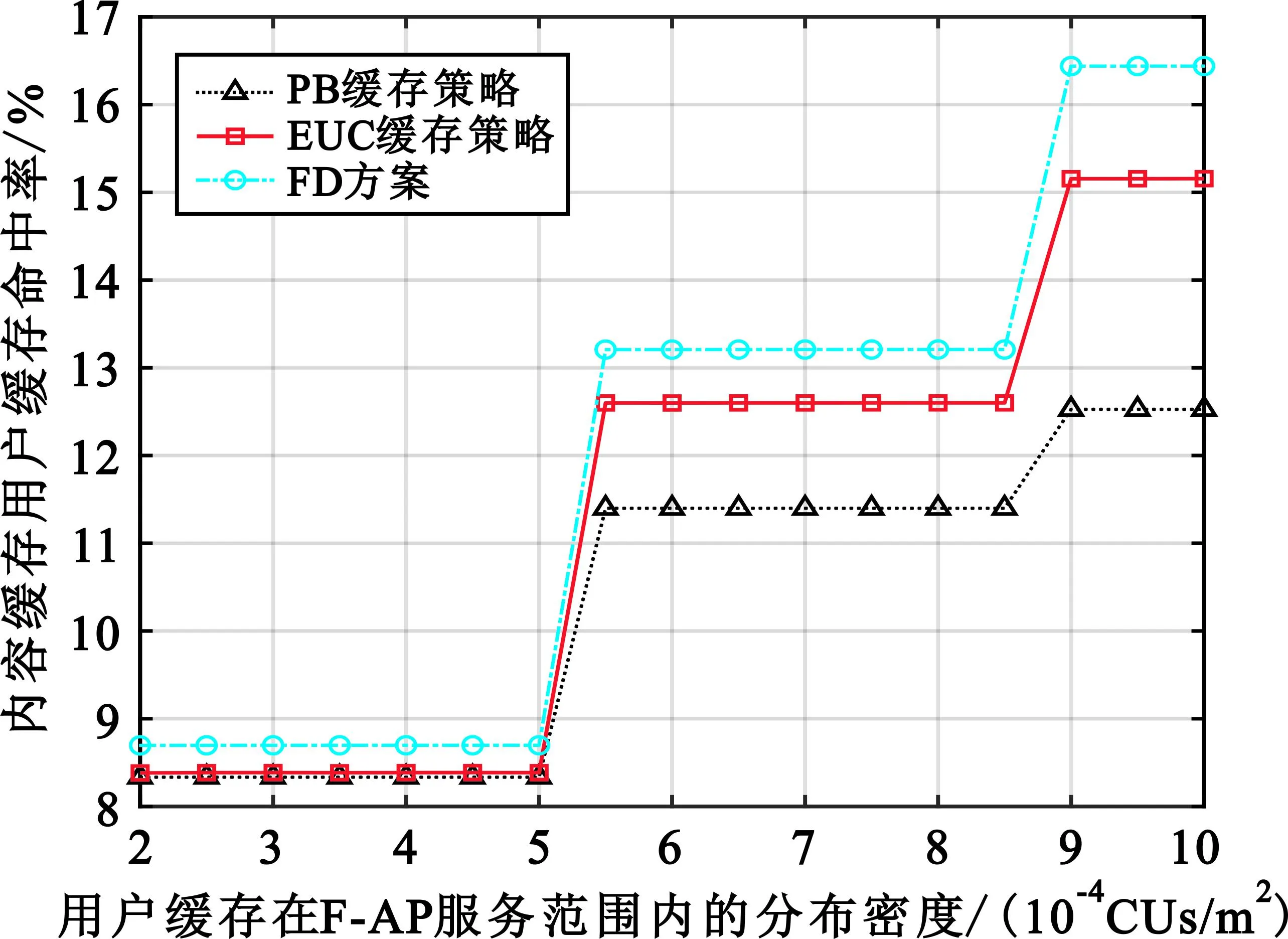
图3 CUs分布服从不同密度齐次PPP对CUs缓存命中率的影响
图4展示了不同内容缓存与交付方案下,CUs缓存命中率随Zipf指数变化的情况。该部分的其他参数设置还包括变量β∈[0.15,0.65]以及γC=5×10-4。根据Zipf分布的性质,当β增大时,越来越少的高流行度文件将有越来越高的概率被RUs请求。此时,即使缓存内容保持不变,CUs缓存命中率也会提高。仿真结果表明,这一过程中FD方案相较于其他缓存策略始终保持了显著的性能优势,这是因为它有效减少了RUs附近的CUs因缓存内容相同而造成的缓存空间冗余。从期望的视角观察,F-RAN网络凭借FD方案的内容丰富性和它本身被请求概率增大两方面因素获得了更高的CUs缓存命中率。更重要的是,本文提出的算法可以达到CUs缓存命中率最大化问题的近似全局最优解。

图4 不同Zipf指数对CUs缓存命中率的影响
图5展示了不同内容缓存与交付方案下,平均下载延迟随Zipf指数变化的情况,其中补充参数的设置与图4部分相同。这项仿真在实验设计上具备的主要差异在于,由于PB和EUC缓存策略本身并不包含交付系数的概念,在假定各个CU的交付系数都为1的情况下,就需要舍弃会形成无限队列的部分数据,而仅保留使平均下载延迟计算有效的数据。图5的结果显示,当CUs缓存的内容变得更加流行以后,更多的RUs请求将会通过CUs模式交付,D2D链路则会始终保持内容交付方面的性能优势。这意味着提高CUs缓存命中率可以通过让更多的流量负载向CUs转移从而减小平均下载延迟,证明了本文所提算法的有效性和执行边缘缓存的价值。除此之外,就FD方案而言,即使有队列等待时间,相比其他两种缓存策略,它用内容缓存方案中的随机性和内容交付方案中的交付系数对其进行控制与均衡,最终既没有浪费缓存空间,也实现了更优越的性能。仿真实验的设计还表明,限制单个CU处的内容请求到达率是必要的,FD方案利用交付系数避免了无效数据,增强了算法的鲁棒性。

图5 不同Zipf指数对平均下载延迟的影响
5 结束语
本文主要针对雾网络中的缓存进行性能优化,提出了基于统计分布的内容缓存与交付方案,利用带KKT条件的拉格朗日乘数法最大化了CUs缓存命中率,并且通过仿真实验分析了各个变量对有关性能指标造成的影响,验证了优化CUs缓存命中率与降低平均下载延迟的相关性。结果表明,本文设计的算法有效,实现了预期效果,达到了优化目标的近似全局最优解,可以始终保持性能优势。因此,在设计内容缓存与交付方案时,直接采取期望视角是必要的,本文从节点分布和用户请求等建模开始,到算法中考虑的内容在概率和统计分布方面的特征都体现了这一点。值得注意的是,为了保证内容缓存与交付方案的成功执行,需要将交付控制纳入考量,事实上它是方案性能的重要影响因素。
下一步将考虑流行度预测、用户移动性等对模型更精确的随机表示和更多的优化方法,探讨此类研究思路与本文的差异。
