基于数据处理器的QUIC加密/解密卸载
2023-11-17王继昌吕高锋刘忠沛杨翔瑞
王继昌,吕高锋,刘忠沛,杨翔瑞
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
QUIC(Quick UDP Internet Connection)是与TCP并行部署在用户空间的一种新型、安全、通用的互联网传输协议[1-4]。它向下基于操作系统提供UDP套接字层,向上为应用层协议(如HTTP3[5])提供可靠且安全的多流传输通道(Multi-Stream)。QUIC与TCP架构的对比如图1所示。在传输功能(Quic-transport)方面,协议栈内置拥塞控制、流量控制和丢包恢复(Quic-recovery)等功能模块,实现类似TCP协议的拥塞控制(Congestion Control)、可信(Reliability)传输。在连接管理方面,建立状态机,对网络连接的建立、保持、迁移、终止等状态进行管理,使QUIC具备面向连接的特性。在安全性能方面,QUIC内置TLS(Transport Layer Security)1.3[6],使用quic记录层(quic-record)模块代替TLS1.2[7]中的记录层(Record Layer)对报文加密/解密,它比当前广泛使用的TLS1.2更加安全,可以更好地保障用户的隐私和通信安全。此外,QUIC没有使用UDP端口来标识一条传输层连接,而是采用连接标示符CID(Connection ID),既为QUIC增加了连接迁移的特性,又保持了与现有网络生态的兼容性。

Figure 1 Comparison of QUIC and TCP图1 QUIC与TCP的对比
QUIC协议可以代替TCP+TLS来完成数据的安全可靠传输。与传统的TCP协议相比,有以下3个显著优势[8,9]:(1)多流(Multi-Stream)传输可缓解TCP协议特有的队头阻塞(Head-of-line Blocking)[10]问题;(2)更短的数据传输延迟,QUIC采用了TLS1.3的早期数据(Early Data)机制,2个终端在一定时间内的重新连接,可以实现0-RTT数据传输延迟;(3)可插拔拥塞控制,由于部署在用户空间,QUIC不需要操作系统和内核的支持,就能够在运行过程中通过调用不同的程序接口实现不同的拥塞控制算法,甚至在不同连接上启用特定于该连接的拥塞控制算法[8]。
QUIC具备诸多优于TCP的设计[8,9],但是在处理报文时,其CPU占用率是同等条件下TCP的3.5倍,这阻碍了QUIC被广泛部署[11]。当前网络技术飞速发展,链路带宽在过去的几年增加了4~10倍,CPU资源(运算速率、核心数、Cache资源等)的发展却停滞不前。紧缺的计算资源限制了QUIC协议栈的性能发挥。为了破除这一障碍,Yang等人[12]对4种符合QUIC规范的开源实现进行了测试和分析,指出CPU占用率的功能部件主要有以下2类(如图2所示):
(1)用户态与内核态之间的数据拷贝,占用了协议相关的总CPU使用率的50%左右。该问题可通过引入DPDK(Data Plane Development Kit)[13]和Netmap[14]等内核零拷贝框架解决。
(2)报文加密/解密AEAD(Authenticated Encryption with Associated Data)[15]操作。在存在内核零拷贝优化的情况下,加密/解密功能模块最高可将每条连接的CPU计算资源占用率提高至40%,且当前还没有行之有效的方法降低AEAD的CPU占用率。

Figure 2 Detailed division of CPU usage[12]图2 CPU占用率详细划分[12]
QUIC传输协议因其部署方便、多流并发等优于TCP的特性,在未来数据中心网络中的应用必定更加广泛。如何在保证QUIC传输性能的同时,克服CPU占用率过高的缺点,在当前的硬件设备上对QUIC协议栈功能模块的优化设计成为当前的研究热点。本文基于DPU(Data Processing Unit)[16]平台提出了卸载QUIC加密/解密的NanoBPF(Nano Berkeley Packet Filter)模型。该模型利用DPU支持的卸载众核特性,将RISC众核卸载至DPU上,结合了快速数据路径XDP(eXpress Data Path)[17]的设计思想,通过在DPU上引导启动eBPF(extended Berkeley Packet Filter)代码作为运行时环境,以XDP程序的形式将加密/解密AEAD操作卸载至eBPF中。加密/解密AEAD操作完全在DPU众核上执行,减少主机的CPU开销,从而提高报文吞吐率,满足未来数据中心网络的海量报文快速处理的需求。
本文在Genesys2开发板上对NanoBPF(Nano Berkeley Packet Filter)进行评估,主要在本地实验场景测试QUIC协议的吞吐率,对性能提升进行评估;在基于Docker[18]的网络拓扑中设置瓶颈链路,测试TCP与QUIC共存时的带宽占比,评估其公平性和可部署性。评估结果表明,报文加密/解密的软件卸载能提高近13%的报文吞吐率,性能提升明显。在与TCP共存的瓶颈链路中,带宽占比达到阈值后,保持了相对静止状态,且研究表明,该带宽比可以通过动态修改QUIC滑动窗口参数来保证瓶颈链路上的公平性[8],为NanoBPF模型在未来数据中心网络中的广泛部署提供了参考依据。
2 协议卸载与优化方法相关研究
本节对协议卸载与优化的相关研究做了细致调查分析,为NanoBPF的设计提供参考。以下分别从硬件卸载、RISC-V众核加速和XDP数据包快速处理3个方面阐述协议优化的典型方法及存在的不足。
2.1 面向无状态功能模块的硬件卸载
TOE(TCP Offload Engine)[19]充分探讨了TCP在可重构硬件上卸载的工作。作为传输层协议的QUIC,也可以进行同样的尝试。仿照TOE的设计思想,Yang等人[12]通过剖析4种不同QUIC实现,分析不同协议构建块的CPU成本,提出硬件/软件协同设计的QUIC加速方案,在基于通用FPGA的智能网卡上实现部分协议栈的卸载。考虑到现有可编程网卡的可用资源有限,卸载整个或者部分协议栈实现起来比较困难且通用性不强,Hay等人[20]认为,目前在用户空间中实现的QUIC无法像TCP等旧协议栈一样,依靠硬件卸载提升性能,但是可以设计一个接口来支持硬件卸载。他们从IPsec加密和传输分段可以显著降低TCP协议栈对CPU利用率的研究中受到启发,提出了对QUIC短报头报文的AES-GCM[21]加密/解密以及QUIC报文分段进行卸载的方法。通过测试可知,卸载加密/解密和报文分段将CPU利用率降低了15%,吞吐量增加了32%。
以上2个方案中,面向无状态功能模块的硬件卸载的思想值得借鉴,但是加密/解密密钥的管理和传输配置等依然由QUIC协议栈生成和控制,硬件与主机之间需要进行频繁的交互。缺乏有效的交互机制(如零拷贝),导致上下文切换和数据拷贝的开销过大,很大程度上制约了QUIC的性能提升。
2.2 基于RISC-V众核的并行处理
Ibanez等人[22]为最小化分布式应用中RPC的尾部延迟,提出了一种通过扩展RISC-V核建立的新型网络优化原型——NanoPU(Nano Processing Unit)。它在每个芯片上实例化512个RISC-V微核,每个核分配16 KB的L1缓存。在分布式应用场景中,该芯片能够达到350 Mpkts/s处理速度,比软件处理方案快了近50倍,线到线(Line-To-Line)延迟仅为65 ns,比当前最先进的技术的快了13 s。理想情况下,网卡维护一个全局RX队列,微内核可以从这个队列中提取下一个处理消息,从而实现最低的预期等待时间。但是,仅有一个全局队列是不合理的,因为它要求所有的核同时从一个全局RX队列中读取数据。为此,NanoPU中启用了JBSQ(2)(Join Bounded Shortest Queue)[23]硬件核心选择算法,对全局队列中的任务进行科学调度,其中“2”表示每个核中未完成任务的最大数量。
NanoPU的超高性能以及超低延迟的实现,很大程度上得益于基于改进的RISC-V多核并行设计以及对RPC请求的直接响应。其借助RISC指令集的微内核实现报文处理加速的设计思想为协议性能优化提供了有力参考。但是,NanoPU的众多微内核的管理与调度成为了制约NanoPU性能跃升的瓶颈,如果管理不当,会造成内核之间的数据污染。而且,NanoPU的部署相对困难,功能固化,无法灵活卸载多种协议模块,在适应多样化用户需求的网络环境中的可部署性相对较差。
2.3 基于eBPF的XDP通用协议栈优化
Høiland-Jørgensen等人[17]提出了一种基于eBPF的新型通用的、可编程报文处理框架——XDP(eXpress Data Path)。XDP可以看作是一种软件卸载,卸载协议栈的关键功能模块的同时,允许内核的网络栈处理其余部分,支持定制的高速报文处理与内核特性混合工作模式。性能评估表明,XDP在单个CPU核上实现了高达24 Mb/s的原始数据包处理性能。虽然比不上DPDK,但是保留了内核安全性和管理的兼容性,并提供了稳定的编程接口。Vieira等人[24]在5G网络下提出了基于eBPF和XDP的报文快速处理设计,用以降低报文处理延迟。在操作系统分配套接字缓冲区(Socket Buffer)之前,通过设备驱动程序接收链中的一个钩子(Hook),在内核中实现快速的包处理。当报文被接收时,包含BPF程序的钩子就会被执行。其中,eBPF虚拟机在设备驱动程序的上下文中运行,为自定义报文处理程序提供安全的运行时环境。

Figure 3 NanoBPF model图3 NanoBPF 模型
基于eBPF的XDP通用协议栈加速为协议优化提供了可部署的兼容性以及可编程的灵活性。但是,当前的XDP程序只能挂载到操作系统的内核中,运行时验证和编译进程将会占用大量的主机CPU资源,从而限制主机处理数据的性能。鉴于此类问题,Kicinski等人[25]提出了一种将XDP程序卸载到智能网卡的设计理念,与DPDK[13]将网络流上载(Upload)到用户程序的内核旁路模式相反,eBPF智能网卡采用卸载模式(Offload),由灌入智能网卡中的XDP程序直接处理数据流。该研究为本文中基于DPU以eBPF/XDP程序的形式卸载QUIC加密/解密模型提供了思路和细节参考。
3 NanoBPF加密/解密卸载模型
当CPU的计算资源成为制约协议栈性能发挥的关键瓶颈时,通常可以采用硬件卸载、片上多核并行和XDP软件卸载相结合的方式进行优化。Yang等人[12]的测量结果为模型设计提供了重要的背景支撑。以该研究结论为出发点,本文提出基于DPU中RISC众核的协议卸载模型——NanoBPF。结合协议栈通用优化框架,选择QUIC中CPU占用率较高的报文加密/解密模块进行卸载,以期达到性能优化的目的。
3.1 NanoBPF模型
NanoBPF模型如图3所示。该模型按照功能可划分为PISA硬件传输(Protocol Independent Switch Architecture HW Transport)、报文分类(Packet Classifier)、报文加密/解密(Pakcet Crypto)和核心选择(Core Sel)4个模块。受NanoPU[22]中基于P4的硬件流水线启发,PISA硬件传输模块对接受到的报文进行3层以下的预处理。报文分类器根据QUIC报文的分类逻辑,对传入的报文进行分类,可调用XDP返回码(Return Code)实现报文的重定向。报文加密/解密模块在核心选择模块选定的核心上,对分类后的报文进行加密/解密处理,并在加密/解密结束前调用Redirect返回码,将数据直接送往用户空间。RISC多核eBPF代码运行在DPU上,为功能模块的运行提供安全的运行时环境。其中,功能模块均为受限的C语言编码,在被LLVM/Clang编译器编译成字节码后,依靠BPF_maps完成功能模块的动态加载。
NanoBPF结合了eBPF的工作模型以及NanoPU的众核并行设计思想,有以下3个方面的优点:
(1)XDP可以在不中断的情况下进行动态重编程,修改功能模块的逻辑;
(2)既不需要专用的硬件支持,也不需要专门用于报文处理的资源,在商用DPU上就能够实现;
(3)eBPF能够以最好的性能执行XDP程序,且在DPU网卡上执行,无需修改内核和操作系统。
3.2 功能模块
下面依次描述各模块的设计以及功能。
3.2.1 PISA硬件传输(PISA HW Transport)
为了减少协议栈传输逻辑处理所导致的主机开销,本文参考NanoPU[22]设计架构中基于P4的PISA流水线,对接收的报文进行预处理。硬件传输模块主要处理3层(3-Layer)以下数据帧头:
(1)添加/去除数据帧头,完成太网帧之间与QUIC报文之间的转化;
(2)从接收的消息中提取元数据参数,用于组装/分段和乱序报文;
(3)重组(Reassembly)缓存区接收的乱序报文,分包(Packetization)缓冲区对发送报文进行分段。
硬件传输模块工作在流水线(Pipeline)模式下,可以同时处理多个以太网帧,当主机建立起一个QUIC连接之后,主机CPU可以不再关注报文发送和接收情况,由PISA负责报文的发送、接收、确认、重传、校验等处理。硬件传输模块能够有效地释放CPU时钟周期,而且硬件实现的传输控制模块的响应速度要远快于软件的,能够进一步降低处理时延。
3.2.2 报文分类(Packet Classifier)
作为XDP功能流水线的接入点,它以XDP程序的形式挂载到eBPF虚拟机中,主要通过报文头的flag字段以及报文号字段共同确定报文的类型,调用XDP返回码对报文进行分类处理,决定报文下一步的处理流程。处理过程如下:截取传入报文的报文头第0个字节header[0],执行header[0]& 0x80,确定是报头类型;然后执行header[0]&0x30或者header[0]&0x40,进一步验证报文的合法性。相关规定表明:(1)在长报头报文中,除最初的Initial报文、Retry报文和版本协商报文外,其他报文均需要经过加密保护,通过执行header[0]& 0x30得出不同的值,确定以上3种报文类型;(2)短报头通常为1-RTT报文,且header[0]&0x40位必须为1。
以输入流为例,对于识别出不同类型的报文头的处理原则为:(1)将不满足以上条件的报文调用Drop返回码作丢弃处理;(2)无需解密的报文调用Pass返回码交付到网络子系统;(3)需要进行解密操作的报文交付到全局队列(Global Queue)缓存。
输出流以相反的顺序进行处理,在交付到硬件传输单元前,再次对报文头部进行分类验证处理。eBPF与用户空间之间的数据交流可通过调用Redirect返回码,携带重定向的参数实现。
3.2.3 报文加密/解密(Pakcet Crypto)
QUIC报文的加密/解密主要分为AEAD和报头保护2个部分。AEAD中的加密算法通常在QUIC初始化过程中被确定,其中最常使用的是AES_GCM,也是在运行过程中CPU占用率最高的环节。AES_GCM加密算法目前有多种实现方案,其中以软件实现方案为众。得益于开源eBPF运行时环境的动态载入特性,可以将AES_GCM的C语言实现编译成BPF字节码,在执行之前由eBPF自带的JIT编译器编译成本地RISC操作码,由DPU核解释执行。通过测试,该AES_GCM实现能够以不低于2.4 Gbps的速率处理报文。报头保护的操作比较简单,在加密完成之后使用报头保护密钥以及密文样本加密生成5字节掩码与报头的相应字段进行异或操作。
以上实现方法与已有同类软件算法相比,一方面经过JIT编译后的操作码能够以最高性能运行,提升了数据加解密的处理速度;另一方面释放了主机CPU处理加密/解密的时钟周期。
3.2.4 核心选择(Core Sel)
在数据流量较大时,为防止出现进程饿死或者计算资源浪费的问题,传入的报文必须面向多核心作负载均衡。该模块的设计依赖于软件实现的改进的SJBSQ(4)(Software-based JBSQ)调度算法,算法伪码如算法1所示。为输入或者输出的数据流量维护一个全局队列,并在每个核心上维护每核的队列,通过特定的调度算法,将处理的任务下发到不同的内核进行处理。
算法1SJBSQ(4)
输入:Cid,Core;/*Cidfor connection id,Coreis a structure,include couter,bitmap and max number*/
输出:True,False。
1.functionCoreselection(Cid,Core)
2.tmp←index←HASH(Cid,core.max);
3.ret←SELECT(index,tmp,Core);
4.ifret=waitqueuethen
5.returnFalse;
6.else
7. process by the selected core;
8.UPDATECORE(index,core);
9.returnTrue;
10.endif
11.endfunction
12./*Overall process of core selection algorithm.*/
13.functionUPDATECORE(index,core)
14.core.counter[index] --;
15.ifcore.bitmap[index]=1then
16.core.bitmap[index] ← 0;
17.core.counter[index]++;
18.endif
19.endfunction
20./* Processing logic for counters and bitmaps after a core has processed a task.*/
21.functionSELECT(index,tmp,Core)
22.ifindex+1=tmpthen
23.ret←waitquenen;
24.returnret;/*The core is busy,so wait*/
25.endif
26.ifcore.bitmap[index]=0then
27.ifcore.counter[index]=4then/* Counters cannot exceed 4 */
28.core.bitmap[index] ← 1;
29.endif
30.ret←index;
31.else
32.ret←SELECT(index++,tmp,core);
33.endif
34.returnret;
35.endfunction
36./* Select the core to process the next task.*/
该算法采用由2个表实现。第1个表由每核位图通过连接id的索引号动态映射到各连接ID号;第2个表由内核维护一个不大于4的计数器,控制等待处理的报文数量。报文到达时首先检验该连接ID对应索引号的位图是否为1,如果不为1,则进一步查验计数器的值加1后是否为4,如果为4,则将该核心对应的位图置为1,待报文处理完成后恢复为零,且计数器减去相应的值。位图为1时索引号自增,按照相同逻辑在下一个核心上处理。如果所有核心上的等待处理报文数均为4,则进入阻塞等待状态。通过SJBSQ(4)调度算法,可以科学地选择运行的内核,核心选择功能模块由绑定的核心(Core 0)进行单独管理。
3.3 报文处理流程
结合以上对各模块的介绍,从入、出、加密/解密处理3个阶段描述NanoBPF的报文处理流程。
3.3.1 Ingress入流水线
报文到达网卡时,可编程PISA流水线按照QUIC协议的处理逻辑进行预处理,并将处理完成的报文交付给重组缓冲区。此时,在缓冲区中,为每条需要交付给应用的消息维护一段元数据,该元数据包含连接配置信息、消息编号等。经过缓冲区重组的报文与元数据一并交付给eBPF。由于eBPF属于事件触发(Event Driver),报文一到达,XDP程序就开始运行。
首先由报文分类器通过报文头部的flag字段对报文类型进行解析,识别报文号空间。报文分类后的处理可以分为以下3种情况:(1)报文类型无法识别,通过XDP的Drop返回码将报文丢弃。(2)识别为握手报文、版本协商报文或者Retry报文时,由于QUIC协议栈以明文的形式处理这些报文,XDP允许将报文上传(Pass)到内核网络栈,同时主机CPU会分配并填充一个skb(socket buffer),由内核协议栈继续处理。(3)识别为需加密/解密处理的报文时,将报文交付到eBPF代码中的全局队列中,并提取报文的连接ID为索引,对eBPF和用户空间各自维护的状态表(State Table)表项进行同步,获取报文解密信息。在众核选择模块根据连接ID为报文分配处理的内核之后,在相应的内核上进行解密处理,最后通过Netmap零拷贝机制,应用程序从共享内存中提取数据。
3.3.2 Egress流水线
应用程序下发的消息可以分为2种情况进行处理:(1)当应用程序下发的消息不需要进行加密处理时,直接将数据交付给主机的QUIC协议栈进行处理,完成之后,由eBPF通过其中的XDP程序转发到Packetization缓冲区。(2)需要进行加密处理时,应用程序线程通过Netmap[14]机制将消息和相关的元数据发送到DPU的缓存空间,用户空间与eBPF代码维护的状态表根据连接ID索引进行表项信息同步,获取该消息的加密信息;使用获取到的加密信息对该消息进行加密,由XDP程序将加密后的数据交付到重组缓冲区,由硬件传输模块根据报文元数据、UDP的负载情况进行分段处理,之后与元数据一并交付给PISA流水线,根据携带的元数据添加相应的报文头,通过网口转发至相应的网络节点。
3.3.3 报文加密/解密处理
报文加密/解密分为AEAD和报头保护2个部分。其中AEAD处理的数据量较大,流程比较复杂,占据了大部分的时钟周期;而报头保护每个报文只需进行一次AES加密/解密,其余均为异或操作,相比AEAD简便得多。所以,在处理一个QUIC报文时,报头保护操作所占用的CPU资源可忽略不计。

Figure 4 Encryption logic of AES_GCM图4 AES-GCM加密逻辑
(1)AEAD。AES-GCM是带认证和加密的算法,即可以对给定的原文生成加密数据和认证码。在获取到需要加密/解密的报文以及相应的密钥之后,AES_GCM的加密流程如图4所示。准备工作:检查报文长度,并通过相应的填充方式对报文进行填充,使其长度为16字节的整数倍。①将消息按每组16字节分成明文组,同时启动计数器(Counter)。按照前8位根据初始向量iv(initial vector)生成随机数,后8位全为零的规则生成计数器Counter+0,使用密钥加密第0个计数器值;②将消息元数据的副本作为附加消息与初始密钥作有限域的乘法,得到Mh0;③从第1个计数器开始,计数器值在前一个计数器的基础上加1,依次将加密后的计数器值与明文分组相与,得到初步的加密数据;④再依次将初步加密数据与前一个Mh相与,直到明文处理结束得到MhN;⑤当消息分组加密处理完成之后,最后得到的加密数据块MhN与第0个计数器的加密值Ek0相与,得到用来认证本条消息的检验值(Tag)。其中IV为握手过程生成的初始向量,key在QUIC初始化时生成。
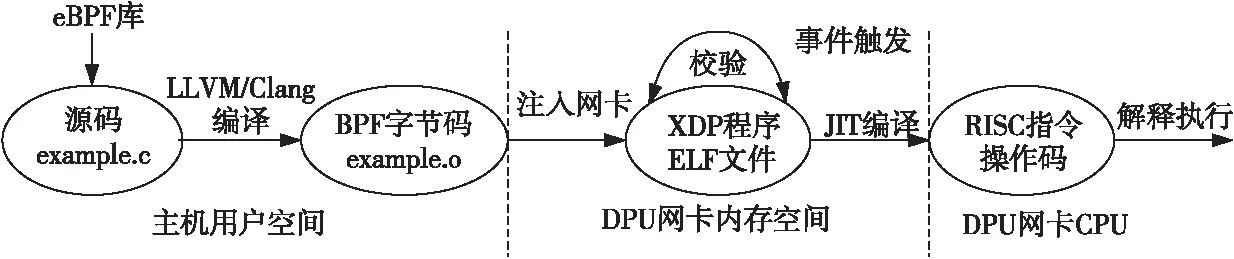
Figure 5 Workflow of eBPF图5 eBPF工作流程
(2)报头保护。AEAD完成后,从报文号(packet number)字段开始往后第4个字节起,截取128 b的密文样本作为样本。获取报头保护密钥,使用AES_ECB算法对样本进行加密生成5 B的掩码。该掩码与报文头部的特定位进行异或(XOR),取第1字节最低有效5位(短报头)或者最低有效4位(长报头)以及报文号字段。以此实现对报头的保护。
4 性能评估
4.1 原型系统实现
原型系统采用主机+DPU设计模型实现,DPU采用Genesys 开发板,该开发板拥有接近16 Mb的BRAM,内部时钟频率达到450 MHz。主机配置为Intel®CoreTMi7-10510U CPU,1.8 GHz,8 GB RAM,操作系统采用Ubuntu18.04和Linux 4.18.0-25-generic。基于DPU开发板实例化多核Ariane CPU[26],使用默认的每核配置:16 KB的L1指令和数据缓存,512 KB的L2共享缓存。将eBPF作为BootLoader(引导加载程序)的第2阶段引导程序加载到SoC的内存中[27],作为运行时环境,一旦完成加载,前端(Front-end)服务器将信号首先写入CPU 0的软件中断寄存器,然后由CPU 0将信号写入系统中其他CPU的软件中断寄存器,最后跳转到DRAM的开头位置,开始执行XDP程序。
在保证程序调用接口通用的情况下,XDP的各个模块可在用户态通过BFP_maps动态加载到eBPF中,工作流程如图5所示。首先在用户空间,使用受限制的C库(eBPF库)对功能模块编程后,编译成BPF字节码(Bytecode),注入到DPU网卡后,会对BPF的安全性进行校验。在有事件触发的情况下,由特定于精简指令集(RISC)的JIT(Just-In-Time)编译器动态优化编译成RISC的操作码(Operation Code),该操作码存入DPU的缓存中,并在后续处理时由Ariane众核CPU并发解释执行。
4.2 实验设计与测试拓扑
QUIC采用的开源quant[28]代码,是一种使用Warpcore用户空间零拷贝的UDP/IP栈,支持Netmap快速I/O架构。对quant源码进行了相应的修改:(1)修改密钥存储方式,显性的将连接过程中生成的密钥和配置信息以文本的形式存入主机内存中。方便DPU处理器按照状态表中同步的信息路径直接获取。(2)将主机协议栈中AEAD操作进一步细化,对需要加密/解密处理报文的AEAD操作进行了旁路。(3)在报文处理的路径上添加条件调用语句,在接收到符合卸载条件的报文时,触发BPF代码中的处理逻辑,进行XDP流水线处理。
为了测试本文模型的性能优化效果,主要进行以下3个实验。(1)在本地场景中,使用千兆网线将2台主机(Server、Client)与DPU连接,以TCP的平均吞吐量为基准,测试模型在分别运行QUIC和TCP协议栈时的平均吞吐量占比,以评估模型的性能提升效果。(2)在基于docker的仿真网络场景(拓扑如图6所示)中,通过流量控制工具TC(Traffic Control)[29]设置瓶颈链路测试与TCP并存时(iperf持续发送TCP流量)的带宽占比,观察QUIC协议与TCP在瓶颈链路下的公平性。(3)在实验(2)的基础上,通过调整QUIC协议的缓冲区大小,确保2种协议之间的公平性。3个实验均测试协议栈(quant_nomal、quant_offload)在传输不同大小文件(512 KB、1 MB、5 MB和10 MB)时的下载完成时间,从而计算各类协议的传输带宽以及带宽比。
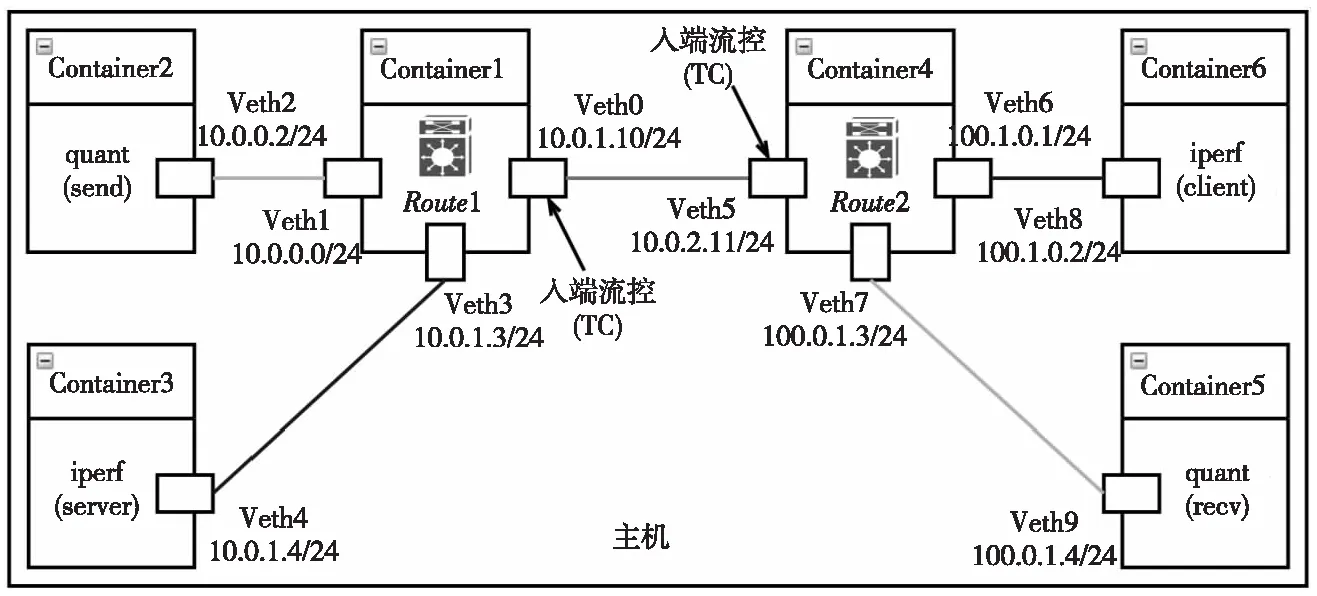
Figure 6 Container-based test topology图6 基于容器的测试拓扑
4.3 测试结果与分析
4.3.1 网络吞吐率对比
吞吐率占比随传输文件大小的变化情况如图7所示。从与TCP在平均吞吐率的对比来看,传输小文件(0.5 MB)时,由于使能了QUIC的0-RTT等特性,最大可获得19%的性能提升。此外,由于传输的文件过小,不足以触发大量的加密/解密卸载进程,所以quant_offload比quant_ normal增加了6%平均吞吐率。从图7可以看出,quant_offload对比quant_normal的优势随着文件的增大而提升,在传输大文件(10 MB)时,可获得13%的吞吐率提升。同时也发现,quant对比TCP的性能优势随着传输文件的增大而进一步减弱,最后在传输大文件(10 MB)时,要稍低于TCP的,这主要是因为传输时间较长,0-RTT建立的优势并不明显,且quant作为实验阶段的协议栈,相比TCP其传输性能的优化程度还比较低。
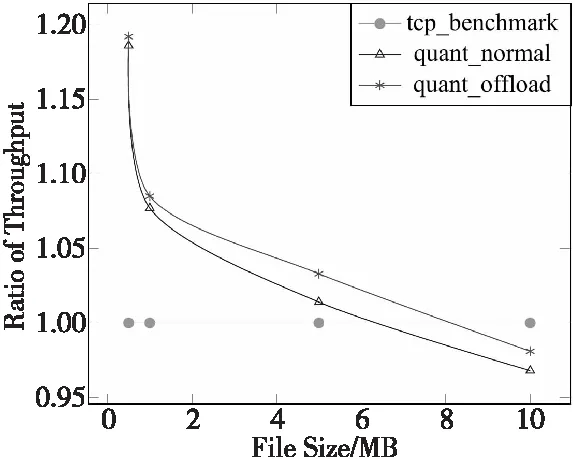
Figure 7 Occupancy ratio of throughput图7 平均吞吐率占比
4.3.2 链路带宽占比
在瓶颈链路(B=5 Mbps,RTT=50 ms)上的带宽占有率对比如图8所示。由于TCP流量采用iperf[30]软件持续发包,在启动QUIC协议之初,TCP占据了绝大部分的带宽,随着传输文件的增大,QUIC的带宽占比逐渐增加,最后达到阈值0.66(quant_normal)和0.68(quant_offload)。而QUIC协议带宽占比较高的原因在于其滑动窗口值增长较快,该问题可以通过动态调整拥塞控制算法的配置(缓冲区大小)来解决[8,9]。从图8可以看出,quant_offload由于数据处理性能更高,滑动窗口增加的速度更快,更早达到阈值。
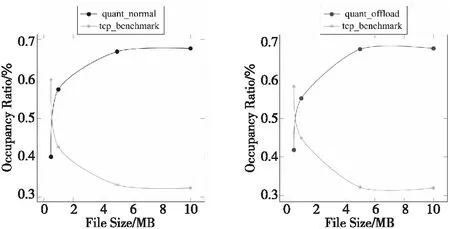
Figure 8 Bandwidth occupancy ratio图8 带宽占比
4.3.3 链路公平性
瓶颈链路(B=5 Mbps,RTT=50 ms)上的带宽占比显示了QUIC与TCP协议的不公平性(如图8所示),通过文献[8,9]可知,其不公平性与协议缓冲区大小相关。本节考虑2种QUIC代码在设置不同的缓冲区大小(13 KB,30 KB,60 KB)时,分别测试传输10 MB文件时与TCP的带宽占用。如图9所示,对于13 KB缓冲区,QUIC占据近3倍的TCP链路带宽。对于30 KB缓冲区(=带宽×延迟),大约为1.5倍的TCP链路带宽。而对于60 KB的缓冲区,被认为是过度缓冲,TCP和QUIC公平地分享瓶颈链路。通过以上评估和分析,验证了基于NanoBPF的加密/解密卸载模型既能有效地提升QUIC协议的报文处理性能,又能通过动态调整协议的缓冲区大小来保证与TCP在瓶颈链路上的公平性。

Figure 9 Bottleneck link bandwidth occupancy图9 瓶颈链路带宽占用
5 结束语
QUIC作为一个新型的传输协议,在设计上针对TCP的不足进行了优化。现有测量数据表明,QUIC在计算资源紧缺的网络设备中,QUIC的性能不如TCP的。其瓶颈主要在于强制的加密/解密虽然带来了比TCP+TLS1.2更高的安全性能和更低的握手时延,但是大量的计算资源被报文保护操作占用,限制了QUIC协议栈潜在的性能优势。针对这一问题,本文进行了协议优化的相关研究,借鉴XDP协议栈优化以及RISC众核并行的方法,设计了基于DPU中RISC众核的协议卸载模型——NanoBPF,基于RISC Ariane众核CPU实现并行处理,将QUIC协议栈中的AEAD操作以XDP程序的形式进行卸载,在PISA流水线设计基础上,添加了基于QUIC传输逻辑的硬件传输模块,负责报文的收发控制。实验评估结果表明,采用NanoBPF加密/解密卸载以及优化模型,提升了13%的协议栈传输性能,且在与TCP共存的瓶颈链路条件下能够实现与TCP协议的公平性。
