超长指令字DSP标量访存单元的设计与优化
2023-11-17陈海燕
郑 康,李 晨,陈海燕,刘 胜,方 粮
(国防科技大学计算机学院,湖南 长沙 410073)
1 引言
近年来,超大规模集成电路和计算机体系结构相关技术取得了前所未有的进步,计算系统的性能也随之不断提高。受制于工艺和器件特性,处理器和存储器的发展迈向了2个不同的方向:一个重在提高运算的速度;另一个重在提升容量,而访问速度的提升相对小很多。因此,处理器和存储器的速度之差越来越大,限制了整个计算系统的性能,这即是“存储墙”[1]问题。
数字信号处理器DSP(Digital Signal Processor)是一种专用微处理器,自问世以来便广泛应用于图像处理[2,3]、音频处理[4]、汽车电子[5-7]等领域。目前的高性能DSP,如TI公司的C66x和CEVA公司的XC16等,均采用超长指令字VLIW(Very Long Instruction Word)架构而非超标量。VLIW架构将指令间的相关性检测与调度等工作交由软件完成,可以减小硬件资源与功耗,更适合嵌入式低功耗场景。此外,随着AI(Artificial Intelligence)技术的发展与应用,VLIW在AI硬件加速器领域也显现出了活力:Intel在其视觉处理器Movidius Myriad 2上就部署了多个VLIW向量处理器[8,9];Habana公司在其Gaudi和Goya系列产品上广泛使用基于VLIW的SIMD(Single Instruction Multiple Data)张量处理器,用于加速AI训练和推理过程[10]。
由于DSP的架构和应用场景与通用CPU存在差异,DSP并不适合直接采用CPU的访存设计。针对DSP的架构和应用特点设计高效的访存单元,以满足其在访存实时性、顺序与固定延迟、高效数据一致性方面的需求,是提高DSP性能的关键。
DSP的应用非常广泛,涵盖了控制任务、实时处理、多线程等场景,处理实时数据的应用有着较高的实时性要求,采用CPU架构中单一的Cache访存设计将严重影响这类应用的性能。VLIW的多发射方式对访存指令的顺序和延迟有明确要求,硬件若违反此要求将导致程序执行错误。存在多条延迟不同的访存通路时,如何灵活、可靠地保证顺序与固定延迟要求是硬件设计与优化的要点。DSP通过软件维护多核Cache一致性,硬件提供Cache写回功能为软件提供支持,写回操作的性能是实现多核DSP高效数据一致性的关键。
本文从高性能DSP常见的存储结构出发,考虑VLIW架构和DSP应用场景的特点,设计了标量访存单元,主要工作如下:
(1)采用Cache、静态随机访问存储器SRAM(Static Random Access Memory)可配置的设计,满足访存实时性要求,以适应不同应用需求。
(2)提出了基于ID的顺序机制,保证访存指令的顺序与固定延迟,存储开销为87.5 B。
(3)通过寻找Cache状态位(Valid、Dirty)按位与后第一个1(“首1”)的位置,直接定位Cache中的有效脏行,加速一致性写回操作,提高了多核DSP数据一致性的效率。有效脏行占Cache容量25%,50%和75%这3种情况下,采用硬件“首1”写回所消耗的时钟周期数分别为272,528和785,为逐行扫描的26.4%,51.3%和76.2%,可见时间开销只与有效脏行数量成正比,与Cache容量无关。
(4)搭建了基于SystemVerilog的验证平台,并验证了设计实现的正确性。
2 相关工作
针对DSP的访存设计,有许多工作都考虑到了应用程序的不同特点,设计了适用性更高的各类Cache,应用程序贴合Cache架构特点时,可以获得更高的性能。
通过研究DSP应用中的计算模式和数据特征,可以指导高效的硬件设计。DSP因为高能效的乘加MAC(Multiply Accumulate)操作而广泛用于边缘卷积神经网络系统,卷积神经网络计算中存在大量为零的数据。据此,Lee等[11]提出了ZBS(Zero-Block-Skip)Cache,在写入全零数据时将其地址记录进ZBS Cache,后续读取若命中ZBS Cache,则直接返回全零的数据,这样可以降低DRAM访问。ZBS Cache在包含大量零数据时可以有效提高性能并降低功耗,但处理不符合该特征的应用时反而会引入额外的功耗,对不同场景的适用性支持不够。
硬件设计中,采用可配置的方式可以提高硬件对不同场景的适用性。Manjunatha等[12]设计了Cache组相连路数控制器,支持对Cache映射机制的动态调整,以便适应不同应用的特征。基于此,在Liang等[13]专为通信领域研制的一款DSP中,一级数据Cache为4路组相连,Cache容量可以配置,不同类型的应用可以根据自身的特点来配置Cache容量,未使用的Cache存储体会通过时钟门控的方法降低其产生的动态功耗。
在一款为移动应用设计的DSP中,Mohanmmad等[14]采用了路数可变的组相联L1D Cache设计,通过选择性地访问存储体来动态改变每组的路数,但Cache容量也会变化,路数减小则Cache容量也减小。数据的访问在Cache命中判断之后,只有命中的数据存储体才会被访问,借助时钟门控可以降低功耗。
上述方案虽然支持Cache容量和组相连路数的灵活配置,但这些变量都不影响存储器作为Cache的性质,对于数据复用性较差或实时性要求高的应用来说,性能提升十分有限。文献[15]采用的可配置设计虽然考虑了访存实时性,但其引入的仲裁逻辑面积占比为3.9%,有进一步提升空间。
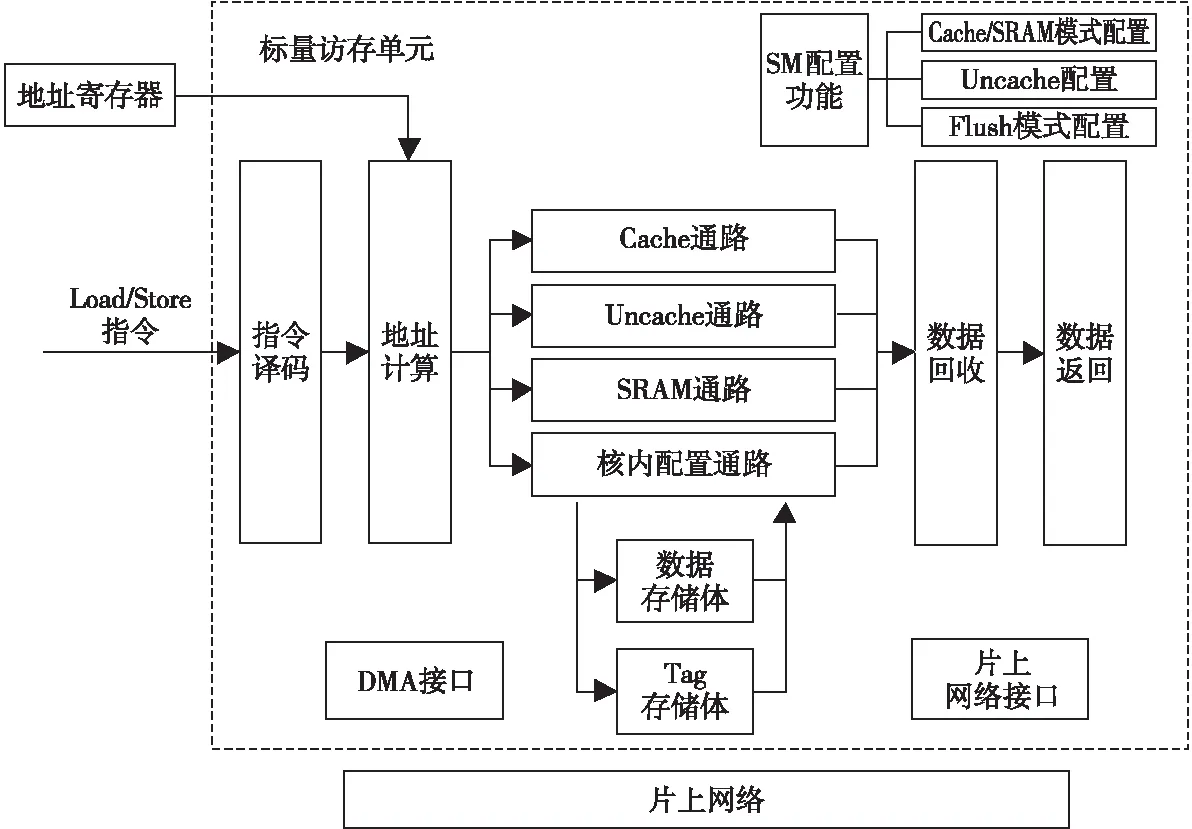
Figure 1 Overall structure of scalar memory unit图1 标量访存单元总体结构
3 标量访存单元设计
标量访存单元在DSP的存储层次中属于第一级数据存储,DSP核对核外、核内数据的访问都要经标量访存单元完成。标量访存单元内部实现了4条访存数据通路,其总体结构如图1所示,Cache通路与Uncache通路负责核外数据的访问,SRAM通路与核内配置通路负责核内数据的访问。为了满足DSP的访存实时性,通过可配置的设计使标量访存单元能够在Cache与SRAM之间切换,片上SRAM能够满足复用性差或实时性要求高的应用。在Cache/SRAM可配置的设计中,通过合理复用标量访存单元的数据存储体,能够有效降低SRAM模式带来的硬件开销。
标量访存单元的输入为Load、Store访存指令,支持Cache/SRAM 2种工作模式的配置,2种模式下均允许从字节到4字粒度的访问。在SRAM模式下,还提供了DMA接口以实现大量数据的快速搬移。发送给标量访存单元的访存指令经译码、地址寄存器访问、地址计算后得到访存地址,指令将根据该地址及当前所处模式流向4条不同的访存通路。针对核外数据的访问由Cache通路与Uncache通路完成:
(1)Cache通路。Cache模式下,访问核外可Cache数据的指令会流向此通路,若数据命中Cache则执行访存操作;若数据缺失则停顿流水线,并通过片上网络向下一级存储请求数据。缺失时,如需将Cache中某一行替换出来为缺失行提供位置,则根据最近最少使用LRU(Least Recently Used)算法选择被替换的行。
(2)Uncache通路。Cache模式下访问核外不可Cache数据的指令、SRAM模式下访问任意核外数据的指令都会流向此通路。该通路中,标量访存单元直接通过网络向下一级存储请求数据。
针对核内数据的访问由SRAM通路与核内配置通路完成:
(1)SRAM通路。SRAM模式下,访问核内数据的指令会流向此通路,片上SRAM相当于一个永远命中的Cache,此时流水线不会停顿,访存指令一定能直接执行。
(2)核内配置通路。标量访存单元内部有许多配置和状态寄存器,例如控制Cache/SRAM模式的配置寄存器和Cache模式下命中、缺失信息统计寄存器等。这些寄存器都统一映射到地址空间中,针对特定地址的访问会访问这些寄存器,相应指令也就流向此通路。
对于Load指令,从各个通路获得的数据将进入数据回收站,最后按照VLIW架构的顺序与固定延迟要求将数据返回。标量访存单元是DSP内核私有的,核外数据的访问主要在Cache模式下完成,核内数据的访问主要在SRAM模式下完成。
3.1 核外数据访问
核外数据的访问,如DDR(Double Data Rate)内的数据,主要在Cache模式下完成。在标量访存单元内部,存储体的组织结构设计优先考虑Cache模式。标量访存单元作为Cache时,大小为32 KB,采用2路组相连映射,共512组,每路大小为32 B。在Cache通路中,为了能在一个时钟周期内完成Cache命中情况的判断,需要同时检查2路Tag值,因此需要2个Tag存储体。数据也使用了2个存储体,数据访问在判断命中的下一个时钟周期,由于此时命中情况已知,至多只需访问其中一个数据体,另一数据体的使能信号可直接关闭,以降低功耗。

Figure 2 Arbitration of SRAM requests图2 SRAM请求的仲裁
出现缺失时,整个流水线会停顿,由硬件状态机完成向下一级存储器请求数据的过程。写入下一级返回的新数据时,替换策略采用LRU算法,因为Cache中1组只有2路,每组只需要添加1位LRU位,每次访问后将LRU位置为本次未访问的那一路,便可实现LRU算法。若被替换的旧数据是脏的,则还需将旧数据写回到下一级,以保证数据的正确性。
Cache模式下还支持对核外某些地址范围的数据是否可Cache进行配置,同样由标量访存单元内的配置寄存器实现。对于可Cache数据,其访问由前述Cache通路完成;对不可Cache数据,其访问由Uncache通路完成,计算出地址后就直接通过网络向下一级存储发出请求。Uncache通路中,若为读操作,则停顿整个流水线,待数据返回时再恢复;若为写操作,则流水线不会停顿,且只要网络不繁忙,针对Uncache数据的写支持连续执行。
标量访存单元配置为SRAM模式时也可以访问核外数据,此时数据体全部负责核内数据的存储,因此针对核外数据的访问全部进入Uncache通路,按照前述Uncache的方式处理。
3.2 核内数据的访问
核内数据的访问主要在SRAM模式下完成,此时标量访存单元对应着地址空间中固定分配的32 KB核内数据空间,对该空间的访问都会流向SRAM通路。Tag体将被忽略,2个数据体各负责16 KB,按高位交叉编址。
计算出访存指令的地址后,先根据地址高位确定要访问的数据落在哪一个数据体,再访问被选中的数据体,此时另一个数据体的使能信号同样可以关闭,以降低功耗。SRAM无需进行任何Cache管理,因而可以做到连续不断地访问,能满足实时性。
作为SRAM时,为实现快速搬移大量数据,添加了DMA接口,包含读、写2个通道。若DMA读、DMA写以及访存指令同时访问数据,由于数据存储体只有一个端口,可能会出现冲突,需要进行仲裁。仲裁逻辑的规则如下:
(1)Load、Store指令优先。访存指令来自于程序的执行,为了保证程序的正常执行不受影响,访存指令的优先级最高。不论访存指令访问哪个数据体,不论是否有DMA请求与其冲突,无条件执行访存指令。
(2)DMA任意通道与访存指令不冲突且DMA通道之间也不冲突时,可响应该DMA通道的请求。此种情况见于一个数据体由某一DMA通道访问,另一数据体由访存指令(或另一通道)访问,2个数据体的访问可以并行执行,互不影响。当另一数据体出现访存指令与DMA冲突时,访存指令无条件优先。
(3)DMA与访存指令不冲突,但2个DMA通道之间冲突时,通过轮询的方法进行仲裁。此种情况见于DMA读、DMA写访问同一数据体(访存指令不访问)时。若上次冲突时读优先,则此次写优先;若上次冲突时写优先,则此次读优先。硬件通过1位寄存器记录下次优先的通道,每次仲裁后将寄存器取反即可。
图2列出了上述仲裁情形,虚线表示本次仲裁成功的请求。
标量访存单元内部实现了许多核内配置和统计寄存器,这些寄存器都统一映射到地址空间中,可通过Load、Store指令直接访问。在Cache、SRAM 2种模式下,针对核内寄存器的访问都将流向核内配置通路,完成对寄存器的读写操作。
3.3 可配置的Cache/SRAM
Cache是缓解“存储墙”问题的有效方案,其应用相当广泛,几乎所有的计算设备都包含Cache。Cache利用程序执行的时间局部性和空间局部性,将当前常用的数据存在一个容量小但速度快的存储器中。这样能够快速响应大部分访存指令,只在少数情况下访存延迟较高[16]。
大部分的应用程序,如执行控制任务、处理静态数据或复杂计算等,程序本身就拥有较好的局部性,在Cache的加持下可以取得较好的性能。但是,在处理流媒体数据、无线信号等场景下[17,18],程序访存的时间和空间局部性较差,Cache缺失率会显著增大,维护Cache所导致的时间开销也会增加,从而严重影响程序性能。此外,出现Cache缺失所耗费的时间也难以满足对实时性要求较高的场景。对于这类应用,片上SRAM比Cache更贴合其特征,针对SRAM的快速访问与数据是否复用无关;由于不用维护任何Cache性质,没有缺失,SRAM可以满足实时性的要求。
上述2类程序都属于DSP的应用场景,因此DSP的访存设计应当兼顾这2类程序的特征,可配置的Cache/SRAM能够以较小的开销满足需求。相比于同时包含Cache和片上SRAM,其硬件更简单,资源和面积消耗小,2种不同模式可以共用同一存储器件,利用率较高。此外,DSP很少有通用CPU的多用户、多任务场景,其运行环境更为单一,在Cache和SRAM之间切换的频率很低,也适合这种可配置的设计。
标量访存单元内部利用一个模式控制寄存器(SMMCR)完成Cache/SRAM模式的配置。SMMCR与其他寄存器一样被映射到地址空间中,程序通过Load、Store指令访问其地址即可对其进行读写。图3所示为Cache/SRAM模式切换过程。

Figure 3 Process of mode switching图3 模式切换过程
(1)SMMCR=1时为SRAM模式,软件先执行一条栅栏(fence)指令,再向SMMCR写入0即可切换至Cache模式。栅栏的功能是排空标量访存单元内正在执行的所有指令,保证切换前的指令都能正确执行。
(2)SMMCR=0时为Cache模式,软件先执行一次写回(flush为写回宏)操作,再向SMMCR写入1即可切换至SRAM模式。由于Cache中缓存的数据可能被修改过,故需要先执行写回操作以确保数据一致性。
4 面向VLIW与数据一致性的优化
为确保VLIW架构所要求的顺序与固定延迟,并实现多核DSP高效数据一致性,本文提出了2种优化方法:
(1)基于ID的顺序机制。通过循环计数器为指令分配ID,利用ID队列确保指令顺序,根据ID与计数器值确保指令延迟,在多条延迟不同的通路汇聚时能有效解决乱序到达、提前到达的问题,灵活、可靠地满足VLIW架构的需求,存储开销为87.5 B。
(2)数据一致性加速。通过对Cache中Valid、Dirty状态位进行按位与得到有效脏行向量,利用硬件查找向量中的第一个1(即“首1”)快速定位待写回行,加速了一致性写回操作,提高了多核DSP数据一致性的效率。
下面详细介绍这2种优化方法。
4.1 基于ID的顺序机制
VLIW架构将指令间的相关性检测和调度工作交给编译器静态完成,这就要求指令执行的时间(即延迟)在编译时就必须确定。对Load指令而言,其取回的数据必须在固定的时间有效。为了固定指令的执行时间,微架构实现上通常采用锁步的方式,任意功能单元停顿将造成整个DSP核停顿,让所有功能单元经历的非停顿节拍数相同。标量访存单元接收到Load指令后,经过约定好的非停顿拍数才能返回数据,不能提前也不能推迟。为了方便讨论,以图1中的地址计算站为起点,标量访存单元必须在计算完Load地址后的第6个非停顿节拍准时返回数据,这是固定延迟要求。此外,先执行的Load指令应当先返回数据,后执行的后返回,这样才能保证寄存器状态的修改符合汇编程序的语义,这是对顺序的要求。
在图1所示的流水线中,Load指令取回的数据会出现提前到达或乱序到达的情况。对SRAM通路而言,由于片上SRAM的访问1拍即可完成,无需用完6拍就能返回数据;Uncache通路中,收到访存请求后立即置位停顿信号,等到网络返回数据后再清除停顿,也是不到6个非停顿节拍就能得到数据。如果数据提前到达后直接返回,就属于提前返回,不满足固定延迟要求。
在Cache模式下,假设未命中Cache的Load1指令紧跟访问Uncache空间的Load2指令。Load1进入Cache通路经过判断命中之后才能将停顿信号置位,而此时Load2已经进入了Uncache通路,向网络请求数据并置位停顿信号。Load2停顿整个内核时,Load1也卡在Cache通路中不再流动。当网络返回Load2数据后,Load1才继续在Cache通路中流动。这种情况下,Load2的数据已经返回而Load1还在处理,Load2数据比Load1数据先到达数据回收站,出现了乱序到达,直接返回将违反顺序要求。
为了保证VLIW架构的顺序与固定延迟要求,设计了基于ID的顺序机制,如图4所示。该机制中最重要的3个部件为:
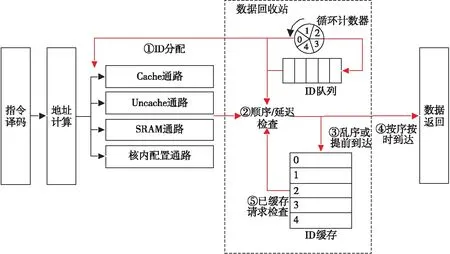
Figure 4 ID-based ordering architecture图4 基于ID的顺序机制架构
(1)循环计数器。循环计数器对非停顿节拍数进行计数,停顿时其值保持不变,非停顿时自增,当计数到4便跳回0。Load指令流向不同通路时,将当前节拍计数器的值作为其ID。
(2)ID队列。Load指令流向不同通路时,其对应的ID同时发送到数据回收站中的ID队列。Load指令是按序发送的,也将按序进入队列,ID队列记录了Load指令的正确顺序,队首ID就对应下一个应当返回的Load。
(3)ID缓存。提前到达、乱序到达的数据,由于不能直接返回,因此需要将其暂存,这就是ID缓存的任务。ID缓存包含5条记录,编号为0~4,与ID号一一对应,需要缓存的Load会被缓存至其ID对应的位置。
一条Load指令A经地址计算、ID分配后流入相应通路(①),经执行后其数据到达数据回收站,将接受顺序和延迟检查(②)。
ID队列按序存放了流出指令的ID值,若A的ID值不等于队首ID值,说明A不是下一条应该返回的指令,它是乱序到达的,因此需要将A的数据暂存至ID缓存,其在ID缓存中暂存的记录编号等于其ID号(③)。若A的ID与队首ID相同,说明A确实是下一条应当返回的指令,顺序正确,还需进行延迟检查。由于所有Load都要在非停顿的第6拍给出数据,A只有在非停顿的第5拍到达数据回收站才可以不暂存。若A在第5拍之前到达,则属于提前到达,违反了固定延迟,仍需要暂存至ID缓存(③);若A恰好于第5拍到达,此时A按序按时到达,可以直接准备下一拍输出(④)。
Load指令的ID值源自于非停顿节拍计数器,利用ID值和到达数据回收站当拍的计数器值即可确定该Load是否按时到达。若Load指令及队首的ID为0,说明该Load是0时刻流出的,其非停顿第5拍时计数器应当为4,则ID为0与计数器值为4对应。其他ID值按同样方法推导便可得到延迟检查表,如表1所示。
除了对新到达的Load指令进行处理外,也要检查已经暂存至ID缓存中的Load指令。若发现某条Load指令满足顺序和固定延迟,则下一拍就将其返回(⑤)。所有已暂存指令和新到达指令的处理过程是并行执行的,且两者的比较原理和流程是一致的,如图5所示。

Figure 6 Execution of two load instructions图6 2条Load指令的处理
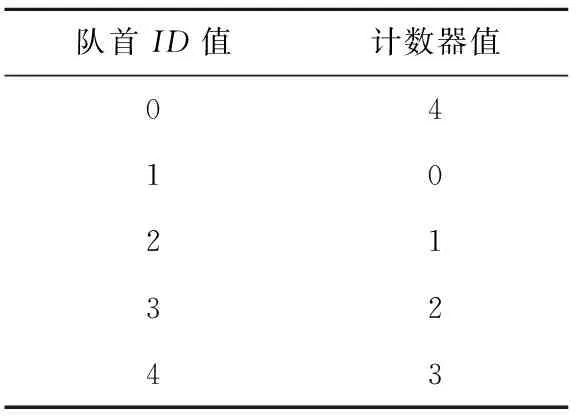
Table 1 Delay checking table
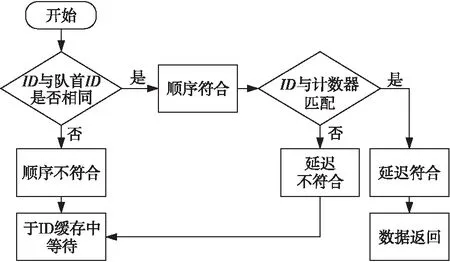
Figure 5 Check flow of load instructions图5 Load指令检查流程
图6以未命中的Cache访问紧跟Uncache访问为例,说明该机制的工作流程。内核停顿及等待片上网络响应的时间在图6中已略去。以下按照时间先后描述图6中各事件:
①访问可Cache数据的Load指令发出,记为Load1,其ID为1,目的寄存器(图中Rd)为5。
②访问Uncache数据的Load指令发出,记为Load2,其ID为2,目的寄存器为6。
③Load2率先到达数据回收站,此时指令顺序已乱,Load2将进入ID缓存,不会被直接返回。
④Load1到达回收站,此时Load2依然未返回。
⑤Load1先返回,写目的寄存器5,循环计数器为1,恰好为Load1发出后的第6拍;随后Load2返回,写目的寄存器为6,循环计数器为2,为Load2发出的第6拍。
可以看出,2条顺序发出的Load指令,乱序进入数据回收站,最终又顺序返回,且返回时间符合固定延迟要求。基于ID的顺序机制,将不能直接返回的Load进行暂存,待其满足条件后再返回数据,保证了VLIW所要求的顺序和固定延迟,存储开销为87.5 B。
4.2 数据一致性加速
在通用CPU中,多核Cache一致性通常由硬件负责,硬件采用Snoop、Directory等协议来实现一致性。一致性协议会让Cache控制变得十分复杂,资源、面积和功耗等开销也比较高,不太适合于嵌入式低功耗领域。为了让硬件更简单,DSP通常只提供写回功能,可以将特定地址范围内的数据从Cache作废或者写回到下一级存储器。多个DSP核共享数据时,软件需要利用写回功能来维护多核DSP数据一致性。如图7所示,核H1写入某个共享变量后,应当将数据写回到下一级存储器;核H2读取该共享变量时,需要先将其作废,再发出读请求,出现缺失时向下一级存储器请求最新的值,从而避免读到旧值。在基于多核DSP搭建的雷达[19]、声呐[20,21]等系统中,图7所示是常见的数据共享方式。
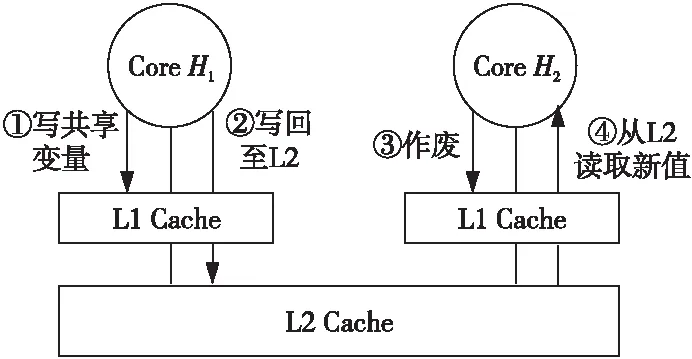
Figure 7 Sharing data consistency through write back图7 利用写回实现共享数据一致性
执行一致性写回时,一种方法是对目标地址空间中的每一行都进行判断,检查其是否在Cache中,若在Cache中且为脏则写回,否则便跳过。该方法的时间开销与地址空间的大小成正比,当地址空间范围很大时,如1 MB,需要检查的行数是非常多的,时间开销无法接受。当地址空间范围超过Cache容量时,可以不对地址空间进行扫描,转而对Cache逐行扫描,Cache中处在地址空间内的脏行将会被写回,其余行则跳过。这样,一致性写回操作时间开销的上限就由Cache的行数决定。对标量访存单元而言,逐行扫描整个Cache的时间开销至少为1 024个时钟周期。
上述方法虽然在大地址空间时降低了时间开销,但逐行扫描整个Cache依然要消耗不少时钟周期。当Cache中有较多无效行或非脏行时,针对这些行的扫描完全是无效操作,因为它们不可能是写回的对象。为进一步提高多核数据一致性的效率,设计了硬件查找“首1”的写回方法,写回时跳过Cache中的无效行和非脏行,使整个操作的时间大大减小。
一致性写回操作关注的对象是Cache中的有效脏行,利用Cache中现有的Valid、Dirty状态位进行与操作便可得到表示有效脏行的位向量,记为VD。通过当前写回行的位置,可以直接定位到下一有效脏行,关键步骤如下:
①利用当前行的位置信息,可以得到一个mask向量,在这个向量中当前行及其之前的行为0,之后的行为1。
②用mask向量与VD向量进行与操作,则可以在VD中屏蔽掉当前行及其之前的所有行。
③针对屏蔽后的VD,利用硬件找出第一个1的位置,即为下一有效脏行,中间的无效行、非脏行均已跳过。

Figure 8 Consistency write back speed up图8 一致性写回加速
图8说明了上述一致性写回操作的加速过程,其中最关键的部分为mask向量的生成和硬件查找“首1”,这两者的计算原理如图9所示。

Figure 9 Computation of mask and leading one图9 mask与“首1”的计算
已知某一行的位置时,将位置向量按位取反再加1,该位置之前会不断进位至第一个0处,恰好为该位置,之后利用初始位置向量对该位置进行屏蔽即可得到mask向量。硬件查找“首1”通过二分法实现,以寻找4位向量中的“首1”为例,记输入为一个4位向量VD,输出为2位的索引index。先将VD分为2组,相邻2位为一组。index的高位代表着“首1”出现在哪一组,这可以通过判断每组是否为全0来实现。通过组内先非后与逻辑计算出代表每组是否全零的向量zero,若第1组为全0则index高位为1,否则为0。index的低位代表“首1”在某一组内的偏移,对组内低位取反即可得到该偏移,具体选择哪一组的偏移由index高位控制。
向量长度较大时,通过多级二分法对向量进行分解,分解后的各部分之间能够并行执行,避免关键路径。硬件查找“首1”的机制,跳过了Cache中的无效行和非脏行,转而只对其中的有效脏行进行处理,大大减小了一致性写回操作的时间开销,提高了多核DSP数据一致性的效率。
5 实验和结果分析
5.1 验证方案
为确保设计的正确性,使用SystemVerilog语言搭建了模块级验证环境,并在Linux环境下进行前端仿真、验证,验证环境如图10所示。

Figure 10 Verification environment图10 验证环境
图10中,LDST驱动负责生成随机访问的Load、Store指令,DMA驱动生成随机的DMA请求。访存指令和DMA请求送往标量访存单元处理的同时,也会发给黄金模型,黄金模型通过软件方法采用与标量访存单元相同的机制来处理访存指令和DMA请求。内存模型利用了SystemVerilog中的关联数组,模拟了一个片上网络和下级存储的环境。Load指令及DMA读通道从标量访存单元和黄金模型读出的值会进入记分牌进行比较,如果出现结果不一致将报告错误。此外,SVA断言不断检测一些设计特性是否满足,如一条Load指令是否在非停顿第6拍给出数据,若不满足也会报告错误。
在Cache和SRAM 2种模式下,针对每条数据通路、核内核外空间都进行了百万次激励验证,均已通过,可配置设计下的各数据通路访问工作正常。
5.2 逻辑综合
在12 nm工艺下对整个标量访存单元进行综合,其总面积开销为183 978.954 2 μm2,功耗为61.332 4 mW,时钟门控率达93.90%。图11列出了主要模块的单元面积占比。
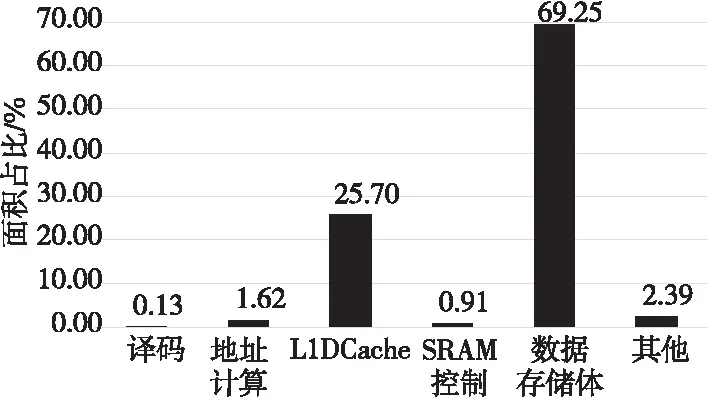
Figure 11 Area occupation of main modules图11 主要模块面积占比
与文献[12-14]的相比,可配置的设计使得标量访存单元适用的场景更加广泛,能够满足访存实时性需求。从图11可以看出,SRAM控制逻辑的面积仅占总面积的0.91%,较之[15]的进一步降低。
5.3 基于ID的顺序机制
4.1节介绍了基于ID的顺序机制及其主要结构与工作流程,现对该机制的功能正确性进行证明,并分析其存储开销与优势。
如图12所示,设VLIW架构的固定延迟要求为指令发出后的第T+2(T≥0)个时钟周期返回数据(包含发出与返回这2个时钟周期,故至少为2)。循环计数器与ID值在0~T,计数器可以看作进行模T+1加法运算,故对任意的ID值,ID与(ID+T)mod(T+1)延迟匹配。设访存流水线中共有N条通路,并记第i条通路的延迟为delayi,且0≤delayi≤T。

Figure 12 Case of N paths图12 N条通路的情况
现有2条指令i、j,指令i于第Si时钟周期发向通路i,其ID值为IDi,应当于第Si+T+1时钟周期返回;指令j于第Sj时钟周期发向通路,其ID值为IDj,应当于第Sj+T+1时钟周期返回。假设指令i先发出,即:
Si (1) 2条指令发出后,ID队列的状态为(IDi,IDj),且2条指令到达数据回收站的时间如式(2)所示: (2) 当指令i到达回收站时,记循环计数器的值如式(3)所示: Cnti=(IDi+delayi)mod(T+1) (3) 以下对指令i不晚于指令j到达(Ei≤Ej)、指令i晚于指令j到达(Ei>Ej)2种情况分别进行讨论。 5.3.1Ei≤Ej Ei≤Ej时,对应指令i不晚于指令j到达的情况。对指令i而言,由于ID队列队首为IDi,因此指令i的顺序满足。 (1)若delayi=T,由式(3)知此时计数器值为Cnti=(IDi+T)mod(T+1),与IDi恰好匹配,因此指令i将于下一时钟周期返回。由式(2)知其返回时间为Ei+1=Si+T+1,符合延迟要求,故指令i按序、按时返回。 (2)若delayi [(IDi+T)mod(T+1)- (IDi+delayi)mod(T+1)]mod(T+1)= (T-delayi)mod(T+1)=T-delayi (4) 根据该剩余等待时间及指令i的到达时间Ei即可得到i的返回时间,如式(5)所示: T-delayi+Ei+1= T-delayi+Si+delayi+1= Si+T+1 (5) 可见指令i的返回时间依然符合固定延迟要求。因此,无论delayi取何值,指令i总能按序、按时返回。下面考虑指令j。 (3)若指令j到达时指令i已经返回,此时ID队列队首为IDj,指令j的处理过程将与指令i完全一致,故此时指令j也能按序、按时返回。 (4)若指令j到达时指令i仍在等待,由于ID队列队首依旧是IDi,故指令j也将进入ID缓存等待,且此时有式(6)成立: Ej=Sj+delayj≤Si+T (6) 式(6)表示指令j到达时指令i最多处于最后一个等待时钟周期,还未返回。联立式(1)与式(6),可得式(7): delayj (7) 故指令j与(2)中的指令i相同,其到达后应等待T-delayj个时钟周期。指令i于Si+T+1返回时,ID队列队首变为IDj,指令j才有机会返回,此时指令j已等待的时间如式(8)所示: Si+T+1-Ej= Si+T+1-(Sj+delayj)= T-delayj+(Si-Sj+1)≤ T-delayj (8) 可见指令i返回后,指令j的实际等待时间不超过应等待时间,指令j仍需要在ID缓存等待延迟匹配。将式(8)中的已等待时间计入通路延迟,指令j等价于经过了一条延迟为T+1+Si-Sj的更长通路到达回收站,并且到达时指令i已经返回,由(3)可知指令j能按序、按时返回。 综合上述4种情况的分析可知,当Ei≤Ej时,任意指令i、j都能按序、按时返回。 Ei>Ej时,对应指令i晚于指令j到达的情况。对指令j而言,由于ID队列队首为IDi,因此指令j将进入ID缓存。 待指令i到达时,其处理与Ei Sj+delayj (9) 再由式(1)和式(9)可得式(10): delayj (10) 这说明此时指令j的应等待时间仍为T-delayj,且指令i仍然于第Si+T+1时钟周期返回,故式(8)仍然成立,其结论也仍然成立,指令j能按序、按时返回。 综合Ei≤Ej和Ei>Ej的结果可知,基于ID的顺序机制可以保证任意2条指令之间的顺序与延迟。 5.3.3 灵活性与硬件开销 在基于ID的顺序机制中,最主要的硬件开销为图4中的ID缓存。假设数据宽度为B,当具有N条访存通路、延迟要求为T+2时,ID缓存的大小为B(T+1),与通路条数N无关。 当N增加但T不变时,若直接根据流水线结构,对2N种可能到达情形加以辨别、处理,硬件逻辑将十分复杂,且容易出错。但是,在顺序机制中,计数器与ID位宽、ID缓存大小等均无需改变,硬件只需增加一些处理逻辑即可,具有较好的灵活性。在标量访存单元中,基于ID的顺序机制存储开销为87.5 B。 为评估数据一致性的性能提升效果,对标量访存单元的一致性写回操作耗时进行了实验与统计。实验中,标量访存单元配置为Cache,片上网络带宽设为足够大(每个时钟周期都能接收一行),在有效脏行数据量为Cache容量的0%,25%,50%,75%和100%这5种情况下,对逐行扫描写回和硬件“首1”写回的耗时分别进行了统计。表2为2种写回方式耗时的统计结果。图13是以逐行扫描为基准的归一化结果。 采用逐行扫描方式写回整个Cache,其基本时间开销为1 030个时钟周期,即便没有有效脏行,也依然需要消耗大量无效时钟周期进行检查。当有效脏行占比为100%时,总耗时为1 037个时钟周期,多余部分为处理网络写响应的开销。写回时,网络返回的写响应需要得到处理。若实际写回最后一脏行后,还要进行许多无效检查,则网络的写响应处理隐藏在了无效检查的时间内。若写回最后一脏行后不再进行无效检查,等待并处理网络写响应的时间就无法隐藏,将计入总耗时。 Table 2 Time consumption of write back 表2 写回耗时 Figure 13 Normalized time consumption of write back图13 归一化写回耗时 采用优化后的硬件“首1”写回,在无有效脏行时,只需8个时钟周期即可完成判断并结束写回。在有效脏行占比为25%,50%和75%这3种情况下,硬件“首1”消耗的时钟周期数分别为272,528和785,为逐行扫描的26.4%,51.3%和76.2%。写回整个Cache时,耗时1 041个时钟周期,比逐行扫描仅多了4个时钟周期。 与逐行扫描相比,“首1”式写回需要使用更多的寄存器资源,查找“首1”的硬件逻辑也带来了更多的资源消耗。一致性写回操作需要输入并修改Cache的Valid、Dirty状态位,由于Cache行数较多,与状态位相关的处理将使用较多的寄存器。采用流水化的逐行扫描方法时,状态位与数据缓存带来的寄存器消耗为4 608 bit,“首1”式写回则需要5 120 bit,增加了11.1%。“首1”式写回引入额外的查找“首1”硬件及11%的额外寄存器资源,将一致性写回操作的耗时改进为只与有效脏行数量成正比,与Cache容量无关。跳过无效行、非脏行,可以避免无效扫描,加速了一致性写回操作,提高了多核DSP数据一致性的效率。 本文针对超长指令字DSP在访存实时性、顺序与固定延迟、高效数据一致性方面的需求,设计了适用于DSP的标量访存单元。采用可配置Cache/SRAM的方式以较低开销满足访存实时性;基于ID的顺序机制确保超长指令字架构对返回数据的顺序与固定延迟要求;硬件查找“首1”的方法加速了Cache一致性写回操作,实现高效数据一致性。在RTL级实现后,搭建了验证环境以验证功能的正确性,分析并证明了基于ID的顺序机制的正确性,同时在不同有效脏行占比下测试了优化后数据一致性的性能提升。 标量访存单元针对Uncache数据支持连续的写,考虑到多核共享数据时,数据生产者对共享地址几乎只进行写,未来的工作可以在Cache管理策略方面展开。通过硬件检测DSP核对某个地址范围是否只写,如果只写则直接写到下一级存储,配合Uncache对连续写的支持以获得更好的性能,避免了写分配、写替换的时间开销。5.3.2 Ei>Ej
5.4 数据一致性加速评估


6 结束语
