基于近期文字极性分配的学习子句评估算法
2023-11-17冯心妍吴贯锋张丁荣王恪铭
冯心妍,吴贯锋,张丁荣,王恪铭
(1.西南交通大学信息科学与技术学院,四川 成都 611756; 2.西南交通大学系统可信性自动验证国家地方联合工程实验室,四川 成都 611756; 3.西南交通大学数学学院,四川 成都 611756;4.西南交通大学计算机与人工智能学院,四川 成都 611756)
1 引言
布尔可满足性问题(Boolean Satisfiability Problem),简称SAT问题,是逻辑学中的一个基本问题,也是理论计算机科学和人工智能研究中的核心问题。SAT问题是第一个被证明的NP完全问题NPC(Nondeterministic Polynomial Complete problem)[1]。在过去的几十年中,SAT问题在工程技术、军事、工商管理、交通运输及自然科学研究领域得到了广泛的应用。从人工智能规划到密码学,现代SAT求解器已经被证明了能够处理包含数百万个变量和子句的庞大公式,因此致力于寻找求解SAT问题的快速而有效的算法,对理论研究和许多应用领域都具有极其重要的意义[2]。
现代基于冲突驱动子句学习算法CDCL(Conflict Driven Clause Learning)的SAT求解器已成功地用于解决各种工业实际问题,并且随着多核处理器的广泛应用,越来越多的并行求解器也得到发展[3]。在这种情况下,SAT求解器的进步归功于核心组件的不断改进和各个功能模块的有效结合,包括:变量与分支的选择和决策、冲突分析、内存管理和重新启动等。
SAT求解器在求解工业级规模的问题时,往往会通过冲突分析产生指数级别的学习子句,但保留过多的子句会过度消耗内存资源,增加执行单元传播过程的时间,大大减缓了求解速度。因此,SAT求解器运行过程中往往会删除大部分学习子句,仅保留部分对求解过程有益的子句,从而维护一个多项式大小的学习子句数据库[4]。
目前主流的基于CDCL的SAT求解器都是通过删除被认为与下一次搜索无关的子句来动态地减少学习子句数据库。其中,最具有里程碑意义的MiniSAT求解器采用了变量状态独立衰减和VSIDS(Variable State Independent Decaying Sum)评估策略[5]。但是,这种方式在求解的初期无法正确评估子句的活跃程度,可能会造成误删部分未被使用的子句,也可能出现部分无用的学习子句由于反复碰撞而造成的持续被保留的现象。在此基础上,基于文字块距离LBD(Literals Blocks Distance)的评估策略在Glucose求解器中被提出并得到广泛应用[6],针对求解器中子句评估策略现存的缺陷而进行改进,Glucose使用LBD的静态度量方式来量化学习子句的质量。
在现代SAT求解器的发展过程中,也出现了很多使用混合算法进行子句评估的策略,从而避免单个评估指标可能造成的缺陷。在MapleComsSPS求解器中提出了新的学习比率分支决策算法LRB(Learning Ratio Branching)[7,8],同时结合了VSIDS和LBD算法进行子句质量评估,即在求解的前2 500 s采用LBD评估方式对子句进行周期性删除,之后再采用VSIDS的策略评估学习子句。在LingeLing求解器中也采用了VSIDS与LBD混合的评估策略[9],通过分析学习子句的LBD值分布情况,在LBD值分布不均时切换为VSIDS评估方式。
基于VSIDS和LBD的评估方式都存在评估指标单一的问题,在周期性删除子句时可能会误删一些对求解过程有用的子句,从而导致反复地推导求解。在并行SAT求解中,目前存在的策略和启发式算法还未能充分发挥学习子句在并行节点间的剪枝能力,且并行程序设计中存在任务划分、负载均衡和数据一致性等难题,并行节点间如何有效地动态选择共享的信息还有待深入研究。
吴贯锋等人[10,11]通过分析学习子句出现的频率,进一步将学习子句频率与LBD算法相结合,以此作为一种新型混合子句评估方式。该混合算法不仅反映了冲突分析中学习子句的分布情况,也充分利用了文字信息。大量实验结果表明,这种混合算法在SAT求解器的串行和并行版本中都比LBD评估算法具有优势,且能进一步增加求解问题的数量。
进度节省(Progress Saving)是由Pipatsrisawat等人[12]提出的一种基于字面极性的启发式方法,通过为每个变量动态保存最后使用的极性,从而达到防止求解器多次求解相同的可满足子公式的目的。Shaw等[13]在进度节省的基础上提出了一种新的类似于VSIDS的启发式策略,称为文字状态独立衰减和LSIDS(Literal State Independent Decay Sum),即捕获分配给变量的最近极性加权趋势和相应的文字活动,作为非时间序列回溯的相位选择启发式,其研究结果也论证了子句中文字活动的趋势与近期极性分配的相关性。
因此,在求解器中,识别高质量的学习子句,提出新的有效的学习子句评估算法,对SAT求解器的进一步提升与改进能起到关键的作用。本文通过研究求解器中的文字活动趋势与近期极性分配情况之间的关系,将其量化为一种评估学习子句有用性的指标,通过改进求解器在周期性删除策略中的评估方式,验证这种新的子句评估策略的有效性,并将其应用在串行和并行求解器上,以提高SAT求解器的效率。
2 相关工作
2.1 SAT基础知识
在布尔可满足性问题中,文字(Literal)是指命题变量v或它的否定形式v[14]。如果布尔公式F表示子句集的合取(∧),且其中每一个子句都由文字集的析取(∨)构成,则F被称为合取范式CNF(Conjunctive Normal Form)。公式F的真值赋值定义如式(1)所示:
V→{True,False}
(1)
其中,V是F的变量集。F中每个变量映射到真值True或False后,F取值0或1。如果F=1,则称F可满足分配或存在解。SAT问题旨在寻求是否存在F的可满足分配。若给定公式F为可满足,则SAT求解器返回其可满足分配作为问题的解,否则给出不满足证明。

Figure 1 Process of SAT solver solution图1 SAT求解器求解过程
CDCL算法是在DPLL(Davis Putnam Logemann Loveland)算法的基础上改进而来的,并且用于几乎所有的现代SAT求解器。CDCL针对DPLL算法中存在的缺陷,进行了学习冲突子句和非时间回溯的改进。其关键组件如图1所示,包含:布尔约束传播、分支变量决策、子句冲突学习、重新启动和子句数据库周期性删除等[15]。
CDCL算法由算法1所示。
算法1CDCL算法
输入:CNF公式F。
输出:SAT或UNSAT。
1Δ=∅;//Δ:学习子句数据库
2While(true)do{
3if(!propagate())then{
4if((c=analyzeConflict())==∅)then
returnUNSAT;
5Δ=Δ∪{c};
6if(timeToRestart())then
backtrack to level 0;
7else
8 backtrack to the assertion level ofc;
9 }
10else{
11if((l=decide())==null)then
returnSAT;
12 assertlin a new decision level;
13if(timeToReduce())then
clean(∅);
14 }
15 }
在CDCL算法主循环的每一步,都会先执行单元传播propagate()[16,17]。如果发生冲突,则通过冲突分析analyzeConflict()函数导出一个新的断言子句,若导出的子句为空集,则该公式被返回UNSAT,即公式F不可满足(第4行)。否则将导出的子句添加到学习子句数据库Δ中(第5行)。如果循环过程中不需要重启,则回跳到学习子句的断言级别(第8行),否则它将回跳到搜索的初始级别(第6行)。如果在执行单元传播下产生空子句时,算法将选择一个新的文字作为决策文字。如果该决策文字存在,则在新的决策级别中进行断言(第12行),反之求解器则找到公式的可满足模型(第11行)。
当学习子句数据库需Δ要被缩减时,则执行timeToReduce()函数(第13行)。由于保留过多的学习子句会放缓单元传播过程,增加求解器遍历子句的时间,而删除太多学习子句则会破坏整体学习的结果对求解的有用性,因此该组件对CDCL求解器的性能至关重要。
综合分析,识别与证明学习子句质量的好坏仍然是一个重要的挑战。第一个子句质量度量的方式是在基于活跃度的VSIDS启发式成功后提出的,这种删除策略假定过去有用的子句将来也可能是有用的。更准确地说,如果学习子句频繁地参与最近的冲突,则认为它与证明学习子句的质量好坏更加相关。之后Glucose使用一种称为LBD的更准确的度量方式来估计学习子句的质量[18],从而提出了比以往更好的子句管理策略。
2.2 已有的学习子句评估算法
基于LBD的学习子句评估算法[5]:学习子句的LBD值表示该子句中包含的不同决策级别的数量,即子句中变量所在不同决策层次的个数。LBD的值是一个正整数,如果LBD(c)=k,则学习子句c包含k个传播模块,每个块都在相同的分支中传播。具有较低LBD值的学习子句往往具有更高的质量,LBD值为2的学习子句被称为glue子句,这些子句有可能在部分赋值下快速传播真值,并且被认为是质量最好的学习子句。基于LBD的评估算法在几乎所有CDCL类的SAT求解器中用于学习子句质量度量。子句的LBD值在求解过程中随着时间的推移而变化,并且每次完全分配子句时都需要重新计算。
VSIDS评估算法[6]:VSIDS评估算法在MiniSAT和现有大多数CDCL求解器中使用,其步骤描述如下:
(1)每个文字都附有一个计算活跃度的变量,每发生一次冲突,所生成学习子句中的所有文字的活跃度增加1,该过程称为碰撞(Bumping)。
(2)在发生冲突后,系统中所有文字的活跃度会被乘以一个小于1的常数,从而随着时间的推移使文字的活跃度衰减。该算法利用文字的活跃性,在选择变量的过程中优先考虑与冲突更相关的文字。
3 基于近期文字极性分配的子句评估算法改进
3.1 基于近期文字极性分配评估学习子句的有用性
变量决策模块是SAT求解器中的核心组件之一,其中包含了决策变量和决策级别。求解过程中,变量决策模块从一组未分配的变量中选取一个决策变量v,并为该决策变量v分配一个真值[12]。在SAT求解器的求解过程中,除了引导学习子句外,求解器还寻求撤销当前部分分配的子句,该过程称为回溯。为此,在冲突分析子程序中计算回溯级别dl,接下来求解器会删除所有决策级别大于dl的变量的赋值。
在目前普遍使用的VSIDS启发式文字活跃度评估方法中,选择下一个决策变量时通常要考虑文字的字面极性。在一般情况下,每次分配决策文字变量时,都会定义并使用默认的极性。但是,在SAT求解器求解过程中存在的重新启动和回溯过程可能会导致求解重复的子公式,因此,进度节省方法的提出有效地避免了求解器多次求解相同的可满足子公式,且该启发式方法在现代SAT求解器中被广泛使用。
为了进一步研究近期文字极性的分配与学习子句有用性之间的相关性,本文以2种最先进的CDCL求解器Glucose 4.1和lstech_maple为基准进行分析。Glucose 4.1的出现使得LBD评估算法在现代求解中被广泛使用,并多次在SAT Competition中获奖。MapleLCMDistChronoBT-DL求解器在2019年的SAT Competition的主轨道中取得了第1名,且其搜索方式在后来的发展过程中得到了改进,改进后的lstech_maple求解器在2021年的SAT Competition中取得了第2名[1]。
基于CDCL的SAT求解器利用进度节省的概念,旨在将给定变量v的极性动态地存储在polarity[x]中,且该极性是通过最近一次决策或传播分配给子句所得到的。因此,在研究过程中以polarity[x]作为所捕获的文字近期极性分配的信息。并且利用该存储信息与当前子句的极性分配进行逻辑与的操作,再与决策变量v的极性取交集,以此利用近期文字极性分配情况推断学习子句与未来搜索之间的相关性。
定义1使用LitPol(Literal Polarity)衡量近期文字极性分配与学习子句有用性之间的关系,其计算如式(2)所示:
LitPol(c)=|polarity[v]∩(polarity[c[i]]∧
sign(c[i]))|,i∈[0,c.size())
(2)
其中,polarity[v]表示决策变量v的极性分配情况,polarity[c[i]]表示在决策和传播过程中存储的子句c中第i+1个文字的极性信息,sign(c[i])表示子句中第i个文字的极性符号。
LitPol的值是一个正整数,是一种基于进度节省的质量度量,LitPol值等于当前学习子句中的文字极性分配与近期变量极性分配相同的文字数量。如果LitPol值很小,表示该子句可能是经过冲突分析后导出的学习子句,并且与当前决策变量极性的集合交集很小,因此推断具有较小Litpol值的子句在后续的搜索和求解过程中是更有用的。LitPol度量是高度动态的,由于保存的文字极性集polarity[v]在搜索过程中会发生变化,因此给定子句的LitPol值也会发生变化。
以CDCL求解器为基准进行分析,在其求解过程中加入计算学习子句LitPol值的功能,并将其应用在子句的周期性删除中。每次调用周期性删除reduceDB()函数时,先计算当前所有学习子句的LitPol值,并按照子句周期性删除策略的原则删除一半的学习子句。
在保留原有利用LBD作为评估指标的策略中,选取了2021年SAT Competition中的3个竞赛实例(20-100-lambda100-65_sat.cnf,crafted_n10_d6_c4_num15.cnf和bv-term-small-rw_1492.smt2.cnf)进行观察。通过对比调用reduceDB()函数前后的学习子句的LitPol值,观察发现,具有较小LitPol值的学习子句被保留了下来。
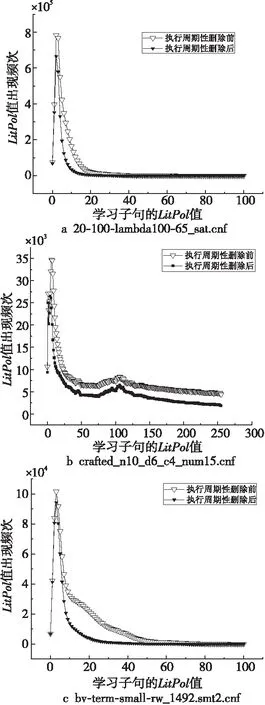
Figure 2 LitPol of the learnt clauses before and after periodic reduce under the LBD evaluation strategy图2 LBD评估策略下执行周期性 删除前后的学习子句的LitPol
首先在LBD评估策略下,对比分析执行周期性删除前后学习子句LitPol值的频次分布情况。通过计算得出,LitPol的取值在0~255,图2a和图2c曲线服从重尾分布。本文为了突出显示,截断了后续线条重叠部分,仅保留LitPol值在前100的频次分布。
实验结果表明,LitPol值小于25的学习子句在整个数据库中所占的比例较大。并在执行reduceDB()后,LitPol值小于25的学习子句基本被保留,LitPol值较大的学习子句则基本被删除。
因此,推断具有较小LitPol值的学习子句是与未来搜索更相关的,能够在一定程度上缩小搜索空间;相反,具有较大LitPol值的子句在当前搜索空间可能不太有用,且与后续的求解过程无关。
3.2 基于LitPol的学习子句评估算法
通过分析学习子句的LitPol值在执行周期性删除前后的分布情况,本文选择保留LitPol值较小的学习子句,并以此作为子句评估的标准,即在求解器的周期性删除模块中利用LitPol的评估方法对学习子句的质量进行评估。
基于LBD的评估算法已经被广泛地证明了其有效性,因此应保留LBD算法在冲突分析方面评估的优势,即在每次发生冲突调用冲突分析analyzeConflict()函数时,利用LBD判断是否需要将子句标记为“可以被删除”。而利用LitPol的评估策略主要用于评估学习子句的有用性,将该度量方法集成到周期性删除中作为判断条件,为释放学习子句占用的内存提供依据,具体过程如算法2所示。
算法2LitPol评估算法
Step1调用LitPol值计算函数,计算学习子句中文字极性与近期变量极性赋值情况相同的文字数量。
Step2执行删除条件判断:对于任意一个学习子句,如果其LitPol值大于阈值,且子句长度大于2,且在单文字子句传播过程中未使用,则删除该学习子句,否则标记该学习子句,并在下一次循环中删除。
图3为在同一实验环境下的对比结果。实验中随机选取了5个CNF测试例文件作为实验样本,这5个CNF测试文件的平均文字数为153 142,平均子句数为2 723 495。对3.1节中ReduceDB执行前后的子句LitPol值的分布情况进行分析,LitPol值较小的子句在周期性删除策略执行后被保留下来,因此在LitPol评估策略中,本文选择设置较小的LitPol阈值来保留对求解过程有用的学习子句。
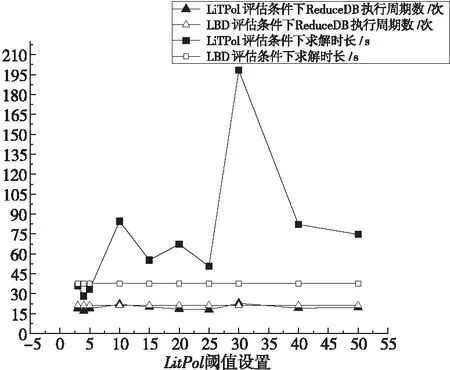
Figure 3 Setting different LitPol thresholds as the clause deletion strategy and performance comparison of solving CNF files under the LBD clause evaluation strategy图3 设置不同的LitPol阈值作为子句删除策略 与LBD子句评估策略下求解CNF文件的表现对比
实验过程中对同一测试示例设置10种不同的LitPol阈值,分别为3,4,5,10,15,10,25,30,40和50,并统计求解过程中执行ReduceDB的次数和求解所用时长,最终得出一个平均的结果并将其与LBD评估策略下的求解表现进行对比。从实验结果可以看出,当LitPol值作为子句删除的阈值时,Litpol值设置得较小能够在求解过程中减少ReduceDB的执行次数,一定程度上起到了节省进度的作用,且该算法应用上述策略时的求解速度优于使用LBD值作为子句评估策略时的求解速度。
实验结果表明,在这种基于进度节省的利用近期文字极分配性的评估策略中,通过使用LitPol值作为判断是否删除学习子句的条件,可以保留合适的学习子句,从而有效地节省求解进度,提高求解速度。
4 实验与结果分析
本次实验的实验环境为:Windows 10 x64, Intel®CoreTMi7-7700 CPU主频为4.2 GHz,内存为32 GB。
2021年SAT竞赛为主轨道和并行轨道提供了相同的400个测试实例,其中139个SAT,139个UNSAT,122个UNKNOWN。而在Main Track ALL中获得第一名的典型CDCL求解器Kissat_MAB在规定时间内求解出了296个测试实例,剩余104个测试实例则超时未被求解。
为了以合理的时间成本进行测试,本次实验选取了Kissat_MAB中求解速度排名前200的测试实例进行测试,该选取标准与CNF文件的子句规模大小无关,求解时长限时4 000 s,所有的测试结果均在同一软硬件环境下得出。前述的实验分析结果表明,LitPol的阈值设置得较小,所得实验结果效果更好,因此本次实验中LitPol值的阈值取4,该阈值是根据实验获取的经验值所设置。将LitPol评估算法应用在Glucose、Glucose-Syrup和lstech_maple中,并行求解器默认使用4个线程。
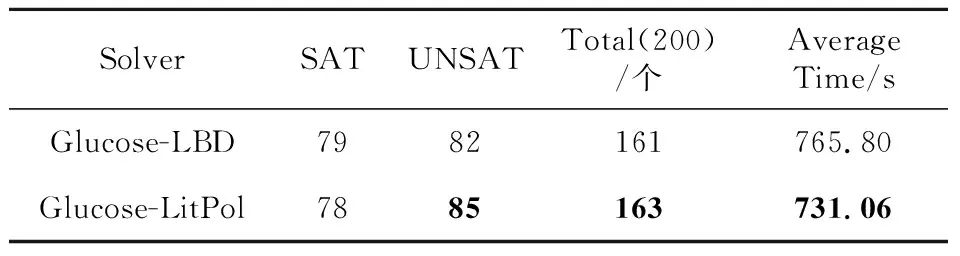
Table 1 Results comparison of Glucose serial solution 表1 Glucose串行求解结果对比
表1中,使用了LitPol作为子句周期性删除策略的求解器为Glucose-LitPol,在求解个数上Glucose-LitPol比Glucose整体多了2个,可满足问题求解个数减少了1个,不可满足问题求解个数增加了3个,求解平均时间比Glucose的缩短了34.74 s。
另一方面,采用了LitPol作为子句周期性删除策略的并行求解器为Syrup-LitPol。如表2所示,与原始的求解器相比,求解总数相同,求解时间缩短了13.72 s。

Table 2 Results comparison of Glucose-Syrup parallel solution 表2 Glucose-Syrup并行求解结果对比
上述实验结果表明,将这种利用近期文字极性分配趋势的子句评估策略应用在目前主流的CDCL串行和并行求解器上,能够有效地提高求解器的求解效率,增加求解个数的同时还能够将单个CNF文件的平均求解时间缩短13~34 s。
为了进一步验证利用LitPol作为学习子句评估条件的有效性,选取lstech_maple求解器进行进一步测试。
表3中,使用了LitPol作为子句周期性删除策略的求解器为lstech-LitPol。lstech-LitPol在求解问题个数上比lstech_maple整体多了2个,其中可满足问题和不可满足问题各增加了1个,求解平均时间比lstech_maple缩短了13.79 s。

Table 3 Results comparison of lstech_maple solution 表3 lstech_maple求解结果对比
对表3中lstech_maple和lstech-LitPol求解器的求解时长进行分析:对于lstech_maple求解耗时较长的问题,lstech-LitPol能够有效地加快其求解速度,并求解出了部分lstech_maple在4 000 s内未能解决的问题。具体对比如图4所示,其中未得出解的文件求解时长标为8 000 s。国际竞赛中常用的惩罚平均运行时长PAR-2(Penalized Average Runtime-2)是一种用于评估求解器性能的指标,其运算方式是对求解器的求解时长进行求和,并将超时未得出结果的问题的求解时长乘2进行惩罚,最后相加得到指标评估数据。通过使用PAR-2对上述2种求解器的性能进行评估,可知lstech- LitPol具有更好的求解性能。

Figure 4 Duration comparison of solving CNF files图4 求解CNF文件时长对比
5 结束语
通过一系列的实验分析可以得出,利用相位保存和近期文字极性分配情况对学习子句的质量进行评估的方式,可以在每次删除数据库中一半的学习子句时能有效地保留对求解过程有用的学习子句,从而达到节省求解进度的目的。
实验结果表明,上述策略能够在一定程度上达到且超越原有求解器的效果,并进一步提高串行和并行SAT求解器的求解速度,提高SAT求解器的整体求解效率。
不足之处在于评估学习子句时阈值的选择。不同的求解实例有不同的最佳临界标准,在动态地计算阈值时需要尽量减小额外的计算开销。另外,在并行求解器子句共享模块中还需要更好地应用改进的子句评估策略,实现不同线程间信息的有效共享,更高效地保留对求解过程有用的学习子句。
后续研究中计划进一步将相位保存和近期文字极性的分配情况与求解器的其他关键模块更好地结合,并结合SAT求解实例的特性实现更精确的分析,实现改进求解效率的目的。
