基于聚类算法的窃电行为检测方法研究
2023-07-13王芳贺子洋张仕文魏雪川黄朝霞
王芳,贺子洋,张仕文,魏雪川,黄朝霞
(国网河北省电力有限公司石家庄供电分公司,河北 石家庄 050000)
0 引言
少数不法分子为了节省用电开支,采取各种手段进行窃电,这一违法行为不仅造成电能的流失,扰乱正常的供电网络,更重要的是这些窃电行为会给电网的运行带来严重的安全隐患.随着用电信息采集系统的广泛应用,不仅可以对用户用电量进行远程采集,还能对用户各时段的用电特点进行分析,这使得通过用户用电数据判断其用电是否异常成为了可能[1-2].
通过分析电力用户用电数据,可以及时发现非法用户窃电行为[3-5].李波等[6]从用户行为分析角度出发,利用用户的历史用电数据,结合粒子群算法和支持向量机算法,提高窃电检测分析精度.耿俊成等[7]提出了一种基于局部离群点检测的低压台区用户窃电识别方法,采用邻域查询优化技术提高计算效率,发现局部离群点因子越大的用户窃电嫌疑越大.Maamar等[8]采用K-means算法对用户进行了相似的用电模式识别,从而了解不同类型的正常行为.Manocha等[9]采用高斯混合模型(GMM)聚类对电力用户数据进行分类,并对分类模型进行了改进.杨学良等[10]将深度森林分类算法引入窃电行为检测领域,从电量、电压、电流、功率因数等数据提取的特征检测用户是否存在窃电嫌疑.吴霜等[11]提出的基于 CUDA的 K-means 电力负荷曲线聚类算法,研究表明其加速比高,适应性强,是解决海量负荷曲线聚类问题的好方法.Jokar等[12]分析了不同用户的用电行为,通过监测异常消费模式,识别出可疑客户.但总体说来,传统的聚类方法在检测疑似窃电用户数据时的精确度还不够.
本研究提出一种基于密度的改进DK-means聚类算法,运用改进聚类分析法对用户的用电负荷曲线进行分类,再将各用户的用电曲线与其进行匹配,从而更加准确筛选出疑似窃电用户,与传统K-means算法的计算结果对比显示,改进的DK-means算法能有效提高疑似窃电用户检测精度.
1 基于聚类算法的用电行为分类
1.1 K-means聚类理论虽然每个家庭的家用电器数量不一,用电习惯不尽相同,但表现在用户每天的用电量上,都会有一定特征,为此可以采用聚类算法对其进行分类.K均值(K-means)算法属于划分聚类算法,它将数据划分为n(n>2)个中心,每个中心代表一个簇,初始聚类数目和初始聚类中心对聚类效果的影响都很大[13-14].该算法虽然只能处理数值型数据,但处理数据的效率高.本研究中用户用电负荷均为数值型数据,因此可以采用K-means聚类进行分析.
K-means 聚类算法采用误差平方和最小函数作为其准则函数,即
(1)
式中:x表示待分析的数据,ci是第i个簇的样本平均值,S是数据库中所有样本平方误差的总和.
1.2 基于密度的改进DK-means算法由于在选取初始类簇中心点时,传统 DK-means 聚类算法的采用随机方法进行选取,因此算法稳定性较差,计算时容易陷入局部最优解.为此本研究综合考虑数据对象的密度信息和数据对象与已有类簇中心点距离信息,据此选取初始类簇中心点,从而提高聚类算法的稳定性.算法具体过程如下:
1)输入包含n个数据对象的目标数据集D,数据集待聚类类簇数k;
2)计算目标数据集D内所有数据对象之间的欧氏距离,将欧氏距离信息存入距离分布矩阵Dn*n中;
3)基于数据集中所包含数据对象的个数n,根据公式(3)计算Eps邻域的参数η和距离数组Dη:
(2)
(3)
4)利用公式(4)对数组Dη中的距离数据求平均,得到其邻域参数Eps;
(4)
5)统计Dη中数据对象的密度信息,将数据集D中的数据对象信息与对应数据对象的密度信息放入集合T,随机选取一个数据对象放入集合V,作为初始聚类中心点;
6)利用公式(5)计算集合T中数据对象与集合V中类簇中心点欧氏距离的最小值:
d(xi,V)=min(d(xi,vj))
(5)

8)重复步骤 6)、7),直到集合V中的数据对象个数为k;
9)计算数据集D中每个数据对象与k个类簇中心点之间的距离,将数据对象存入欧式距离最近的类簇中心点所代表的类簇中;
10)取数据集D的均值作为新的类簇中心点,更新类簇中心点信息;
11)重复步骤 9)、10),当类簇中心点不再发生变化后停止迭代;
12)得到聚类结果为k个彼此独立的类簇:C={C1,C2,…,Ck}.
1.3 聚类数的选择研究表明,聚类数的选择会对聚类结果产生很大影响.为提高聚类效果,本文中采用加权有效性指标(weighted summation type cluster validity index,WSCVI)来确定最优的聚类数,其计算公式如下:
(6)
式中:n为指标个数,ωi为第i个指标的权重系数,Ci为第i个指标的值.
1.4 聚类有效性评价聚类时,如何判断数据记录是否属于同一类应该有一个评判标准,这个标准就是数据间的相似度.常用的相似度度量有欧氏距离、曼哈顿距离、相关系数r等.为对比更加全面起见,本文中选择上述3种方法作为相似度度量,以此评价两种聚类算法的有效性.
2 试验分析
2.1 试验样本数据本研究选取了河北省某地供电局用电信息采集系统中某一小区152 户居民从2020 年10 月~2020 年12月共3 个月的用电负荷数据,对样本数据采用离差标准化方法进行标准化,如图1所示.可见该样本数据非常凌乱,必须对这些曲线进行聚类分析.
2.2 确定聚类数采用了加权和聚类有效性指标来评价聚类结果并确定聚类数.聚类数的范围为2到20.经过试验,得到在不同聚类数下的WSCVI指标如图2所示.

图2 不同聚类数下的W指标
2.3 传统K-means聚类结果分析根据前述的聚类数分析结果,我们将用户的用电负荷行为分为6组,随后采用传统K-means算法进行聚类分析,最后获得各组用户的用电负荷特征曲线,如图3 所示.
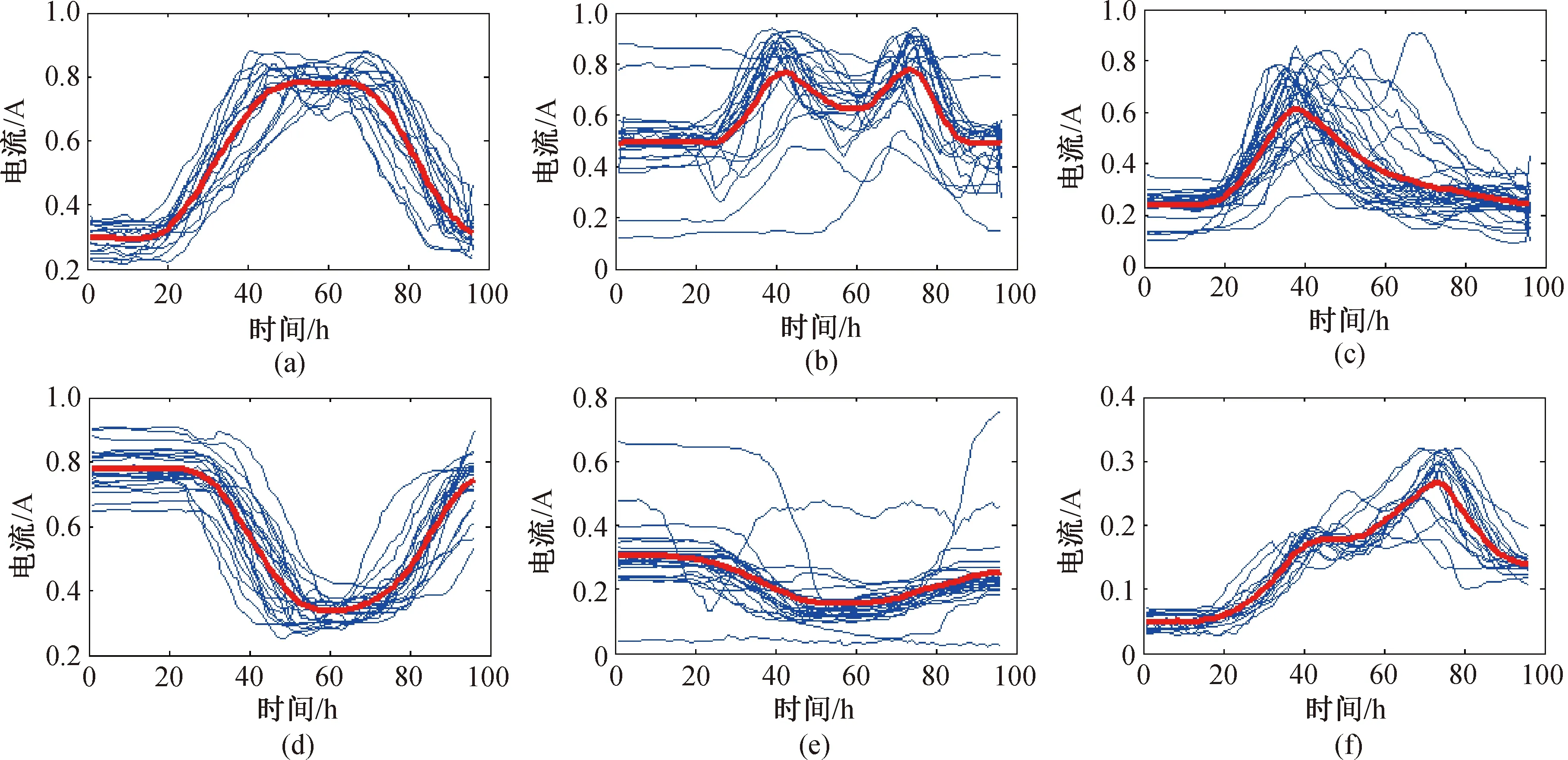
图3 居民用电负荷的K-means聚类结果
图(3)中红色曲线为聚类中心特征曲线,随后可计算出各用户负荷曲线与特征曲线的曼哈顿距离、欧氏距离、相关系数r,如图4所示.分析曼哈顿距离、欧式距离中的数据,可知这些值因各组用户用电数据的不同而上下波动,相关系数r中红线为设定的阈值r=0.8,图中可见,有17个用户用电曲线与聚类特征曲线的相关系数r低于0.8,说明该用户用电行为较为异常,可以作为疑似窃电用户进行标记.

图4 K-means聚类评价指标
2.4 改进DK-means聚类结果分析运用DK-means聚类算法理论将样本数据进行聚类分析,最后获得各组用户的用电负荷特征曲线,如图5所示.
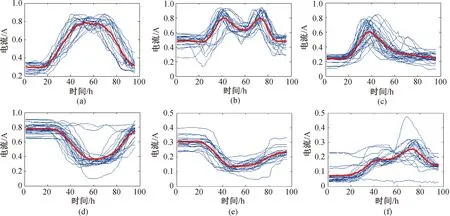
图5 居民用电负荷的DK-means聚类结果
同样地,可以运用欧氏距离、曼哈顿距离、相关系数r法计算出用户用电曲线与各组特征曲线的距离,如图6所示.

图6 DK-means聚类评价指标
2.5 聚类结果对比分析为了比较采用传统K-means聚类与DK-means聚类在对用户用电行为分析的效果,可以将其分组后的用户数量、各用户负荷曲线与聚类中心特征曲线的曼哈顿距离、欧式距离、相关系数以及相关系数值小于阈值的用户数量进行对比,其结果如表1所示.

表1 K-means聚类与DK-means聚类结果对比分析
通过对前述两种聚类方法的结果进行分析可知,DK-means聚类后各用户负荷曲线的曼哈顿距离总和降低了10.6%,欧式距离值总和降低了29.7%,说明DK-means聚类后各用户负荷曲线的距离与聚类中心的距离更短,聚类效果更好.DK-means聚类后相关系数r值总和只降低了0.4%,但低于阈值的用户数量少了29.4%,且发现该12条曲线均属于K-means聚类法提取出的17条曲线集合中,也证明DK-means聚类法有更好的聚类效果.
3 结论
本研究提出一种基于密度的DK-means聚类理论,运用此聚类理论,对某小区监测到的152户家庭的用电负荷数据进行聚类分析,获得6组特征曲线,再将各用户的负荷曲线与之进行对比,从而筛选出疑似窃电用户,与传统K-means算法的结果对比可知,DK-means聚类算法能更有效地提高窃电检测的精确性.
