基于深度分类的格网化公路桥梁裂缝检测技术研究
2023-06-07胡德辉
胡德辉
(佛山市公路桥梁工程监测站有限公司,广东 佛山 528000)
0 引 言
基于深度学习的桥梁裂缝检测技术需要使深度卷积神经网络能够识别出桥梁裂缝图像中属于裂缝的目标区域并将其在图片上标注出来。但是由于桥梁裂缝的无规则性和连续性,当前基于深度学习的目标检测模型候选框选取策略不适用于桥梁裂缝检测任务,直接应用时会存在严重的误检和漏检现象,故通过对桥梁裂缝的线性特征和基于深度学习的图像识别与目标检测的工作原理进行研究,设计适用于桥梁裂缝检测的深度学习检测方法。
1 基于深度学习的图像识别算法模型分析
1.1 AlexNet模型
AlexNet模型是基于深度学习的图像识别模型,识别准确率远超使用传统图像识别算法的模型,该模型相对传统模型在结构上进行了改进与调整。该模型将ReLU激活函数引入到卷积神经网络中,同时验证了ReLU激活函数度模型梯度消失问题的缓解效果;在GPU上进行卷积神经网络的训练,大幅度缩短了训练时长;在训练过程中随机抛弃部分神经元,有效提高模型训练效率,抑制模型过拟合;针对小样本数据集使用数据增强方法,如图像旋转、图像加噪等,缓解模型的过拟合问题;增大响应大的值与反馈小的值之间差距,增加模型的泛化性能。AlexNet相对最原始的卷积神经网络LeNet在性能方面有所提升,但模型参数量极为庞大,存储成本较高[1]。
1.2 VGGNet模型
VGGNet模型在图像识别任务中的识别准确率高达92.7%,主要包括VGG16和VGG19两种卷积神经网络模型。其中,VGG16模型包括3层全连接层与13层卷积层,神经网络层次共计16层,故将其命名为VGG16。VGG16模型删除了AlexNet中11×11,7×7,5×5尺寸的卷积核,全部使用3×3的小尺寸卷积核进行代替。在相同感受野的情况下,使用小尺寸卷积核层数更深,对图像特征提取的更完全,模型参数量也显著降低。
1.3 ResNet模型
随着网络的加深,VGGNet模型的精确性会有所提升,但在达到饱和后,模型的精确度会迅速下降,并且这种退化并不是由过拟合造成的。某浅层模型输入为x,输出目标值为F(x),在深度持续增加的过程中,因浅层模型用于传递而非运算,因此误差不会变化。ResNet模型的基本单元残差块便是根据这一原理构建的,一个残差块有两条路径F(x)和x,F(x)为拟合路径操作流程与传统卷积过程一致,x为恒等映射,在输入激活函数之前两者要进行与运算。
2 基于深度学习的目标检测
图像识别模型能够识别整幅图像的类别,难以对图像内部进行目标识别定位,目标检测模型则具备相应功能。目标检测模型根据其检测阶段数的不同可以分为单阶段目标检测模型和两阶段目标检测模型,重点研究这两类目标检测算法中较先进的检测算法FasterRCNN与YOLOv4的工作原理[2]。
2.1 FasterRCNN
图像输入后,该模型借助卷积神经网络获取特征图;然后,利用RPN来生成候选框,在特征图中投影候选框以此拉生成特征矩阵;基于ROIpooling层将各特征矩阵缩放到特征图(尺寸7×7),展平特征图后利用全连接层获取预测结果。
2.2 YOLOv4
YOLOv4是在YOLOv3的基础上提出的,其检测准确率更高,检测速度更快。YOLOv4网络结构主要分为了输入层、骨干网络、颈部以及头部这4部分,其中输入层,主要负责输入待检测的特征图像,骨干网络为CSPDarknet结构主要负责特征提取工作,颈部主要包含了SPPNet和PANet,主要负责对主干网络提取到的特征信息进行池化下采样以及特征融合操作,头部则为YOLOv4网络的输出层,负责对检测结果进行输出的作用。当图像输入进YOLOv4网络结构时,网络首先会把图像的大小调整为416×416的大小,再将调整后的图像进行分割,划分为13×13、26×26以及52×52的网格。当图像中需要被检测的特征信息的中心点在某一个网格上时,那么就由这个网格来完成对该特征信息的检测[3]。
3 格网化处理与裂缝检测方法
该方法应用过程中,需要重采样原始图像,为确保所划分网格能够将整幅图涵盖在内,需要将原始图像转化为正方形。图像采样变换后,利用n×n的正方形网格将图像均匀分割,每个网格的位置定义为Pij,其中i,j为横纵坐标,借助位置代号对图像中公路桥梁裂缝的分布进行规范化管理。最后,在分类模型中输入格网化处理的图像,识别并标注裂缝所在网格的位置,实现对裂缝位置的快速检测[4]。在公路桥梁图像格网化处理过程中,n的取值不同,最终模型的应用效果也有所不同,为确保所选n值的合理性,可以通过遍历正整数区间的方式进行综合评估。一般而言,如果n值较小,在定位图像中裂缝位置时将存在精度不足的问题;如果n值过大,则大幅度增加模型运算量,工作效率将难以满足用户需求。因此,建议将n的遍历正整数区间设定为[5,10]。为确定n的最优取值,可以应用Sn准确率公式对最优取值进行评定,准确率计算公式如下
式中:n为网格行列数,n为正整数且取值范围为[5,10],T为模型能准确区分背景图像与裂缝图像的数量。
在桥梁裂缝检测之前,工作人员需要对公路桥梁图像格网化处理,将图像均匀分割为n×n个正方形网格,并为每个网格定义位置代码。在此基础上,将各网格图像作为输入量利用深度分类模型进行处理,模型提出图像特征并在样本标记空间映射所提取特征,确定背景或裂缝区域的概率。最终,根据预先分配的位置信息在原始图像中标记裂缝位置,实现桥梁裂缝检测。
4 图像分类模型与目标检测模型实验分析
4.1 实验准备
(1)数据集采集
初始数据集是使用的高清照相机在某广东公路桥梁区域采集,采集时调整相机镜头与桥梁裂缝表面近似平行,保持拍摄高度在30 cm左右,为保证采集到的桥梁裂缝图片易于被深度学习模型训练与学习,挑选光照良好且裂缝特征明显的位置拍摄采集,拍摄存在裂缝区域的公路桥梁高分辨率照片500张,通过数据增强方法扩充数据集,最终得到裂缝图像40 000张作为实验数据集[5]。
(2)评价指标
为精准评估深度分类格网化公路桥梁裂缝检测模型的应用效果,在模型评价过程中应用的多种指标,分别为模型结构复杂度、模型参数量、F1得分、召回率R、精确度P。其中,召回率R与精确度P计算公式为
式中:TP为正确样本正确识别数,FN为正确样本错误识别数,FP为错误样本错误识别数。
F1得分是一种兼顾召回率R与精确度P的指标,其计算公式为
(3)实验环境
使用深度学习模型进行裂缝检测任务时,因算法结构复杂,为方便程序运行需要调用开源的第三方库,实验所用的软硬件环境配置如表1所示。
表1 软硬件配置数据
4.2 实验分析
(1)图像分类识别算法模型对比分析
基于深度学习的格网化桥梁裂缝检测技术主要依靠图像识别模型对其中分属不同格网的图像进行识别来展开的工作,所以图像识别模型的选择对于整个检测过程的实施十分重要,分别对当前具有代表性的图像识别模型AlexNet,VGG16,ResNet34进行实验,根据检测结果精确度,模型参数量,结构复杂度对模型性能进行综合分析,选择最适用于桥梁裂缝检测的模型作为格网化桥梁裂缝检测模型的深度分类模型。
实验期间,初始学习率设定为0.0002,每批次样本训练数量为32,应用Adam优化器,进行50次迭代处理。使用预先准备分类完成的40 000张桥梁裂缝数据集,划分其中75%作为数据集,15%作为测试集,分别训练和测试AlexNet,VGG16,ResNet34t。实验结果如表2所示。
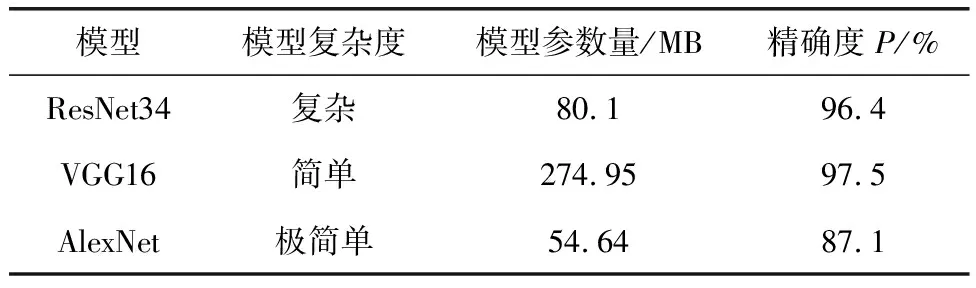
表2 深度学习图像分类算法模型对比
由表2可以看出,在精确度方面AlexNet模型的精确度最低,仅为87.1%,VGG16模型在桥梁裂缝图像识别任务中精度最高,达到了97.6%,在参数量方面AlexNet的参数量最小仅为54.64 mB是其中参数量最大的模型VGG16的1/5,但是AlexNet由于其结构过于简单对于图像特征提取不完全导致图像识别的精确度较低。VGG16模型数据结构堆积位置明显,在对模型进行优化时操作简便,通过轻量化处理改进后可以在保持精确度不变的情况下,大幅减少模型参数。综上所述,考虑模型识别精度,参数量,结构复杂度,建议选择VGG16模型为基于深度学习的格网化桥梁裂缝检测中的深度分类模型。
(2)目标检测模型对比分析
为研究分析所提出基于深度分类的格网化公路桥梁裂缝检测算法模型的应用效果,选择将该模型与YOLOv4单阶段目标检测以及FasterRCNN两阶段目标检测这两种模型进行对比,从F1得分、模型参数量、召回率、精确度几个方面进行综合评比。在对比研究过程中,选择应用6 000张提前标注完毕的目标分类与检测数据集进行实验测试,数据集中的1/4用作测试集,3/4用作数据集,对比三种算法模型的几种指标。模型训练期间,设定初始学习率为0.000 2,分别进行50次迭代。格网化处理方法应用过程中,随着n×n网格中n取值的增加,网格分割的精细化程度将进一步增加,但大量划分网格或减少各网格图像中裂缝特征量,进而对精度造成影响,而且大量网格也会导致计算量大幅度增加。n取值如果较小,则会影响图像中裂缝的定位精细化程度,本次实验选择n取值为10进行分析,得到数据对比结果如表3所示。

表3 桥梁裂缝检测模型数据对比
由表3可知,精确度P和召回率R都远高于基于深度学习的目标检测模型,识别精度相较于FasterRCNN高了3.3%,比YOLOv4更是高了25.9%。在召回率方面,M_model的召回率相较于FasterRCNN高了44.1%,相较于YOLOv4高了63.9%。证明了设计的格网化处理方法相比于目标检测模型的先验框选取策略更适合应用在桥梁裂缝检测任务中,为更客观的评价设计模型,应用F1得分指标对模型效果进行对比。结果表明,格网化算法模型的F1得分为0.97,远高于其余两种模型,进一步验证了所提出算法的实用性。
5 结 语
综上所述,对ResNet34、VGG16、AlexNet三种常见的深度学习图像识别算法模型与YOLOv4、FasterRCNN两种目标检测算法模型的原理进行了研究分析,提出了针对公路桥梁裂缝检测的深度分类格网化算法模型,通过试验对比的方式验证了VGG16模型在图像识别中的应用优势,验证了基于VGG16模型、格网化处理进行桥梁裂缝检测的可行性。此外,研究期间,工作人员发现VGG16模型存在模型参数量较大的问题,在实际应用过程中需要对其进行轻量化改造,进一步提升算法模型的实用性。
