基于机器学习糖尿病并发视网膜病变风险预测模型的构建及验证
2023-05-13蔡菁菁李江涛杨雨婷洪中文张浩轩
蔡菁菁,肖 辉,李江涛,杨雨婷,洪中文,俞 越,张浩轩,陆 进
(蚌埠医学院 1.临床医学院;2.公共卫生学院;3.药学院;4.数字医学与智慧健康安徽省重点实验室,安徽 蚌埠 233030)
糖尿病(diabetes mellitus,DM) 是一种由胰岛素分泌障碍或作用受损,导致患者出现以血糖增高为主要临床表现的疾病。DM患者广泛分布于全球各地,其发病率有逐年增高趋势。国际糖尿病联盟(IDF)[1]最新研究表明,中国、印度和美国是目前DM患者(20~79岁)最多的3个国家,其患者数量分别是1.164亿、7 700万和3 100万,而且未来10年,中国DM患者或将超过1.4亿人。
DM可导致多系统并发症,如神经系统、心血管系统、免疫系统以及感觉系统等[2],严重影响患者的预后与生活质量。由于DM患者长期高血糖,可导致其微血管发生病变,如视网膜与肾脏病变等[3]。糖尿病视网膜病变(diabetic retinopathy,DR)是DM患者最常见的微血管病变,以2型糖尿病(diabetes mellitus type-2,T2DM)患者多见;而且,病程超15年的DM患者的视网膜病变发病率可高达75%~95%[4],是导致患者视力下降及致盲的主要原因[5-6]。因此,研究DR的危险因素,对DR进行早期预防、诊断与治疗具有重要的临床意义。
1 材料与方法
1.1 资料来源研究数据来源于中国人民解放军总医院的《糖尿病并发症预警数据集》[7]。资料内容主要包括以下几方面:(1)一般人口学资料:包括性别、年龄、民族与婚姻状态等。(2)一般体格检查:包括心率、收缩压、舒张压、BMI、身高、体重等。(3)实验室检查:包括血常规、尿常规以及生化指标等。(4)并发症:包括高血压、神经系统疾病、免疫相关疾病及肿瘤等疾病。
1.2 分析流程将原始数据整合到Excel表格中,并处理其缺失值、异常值、记录不一致等问题,采用SPSS 22.0软件对缺失值填补。见流程图(图1)。
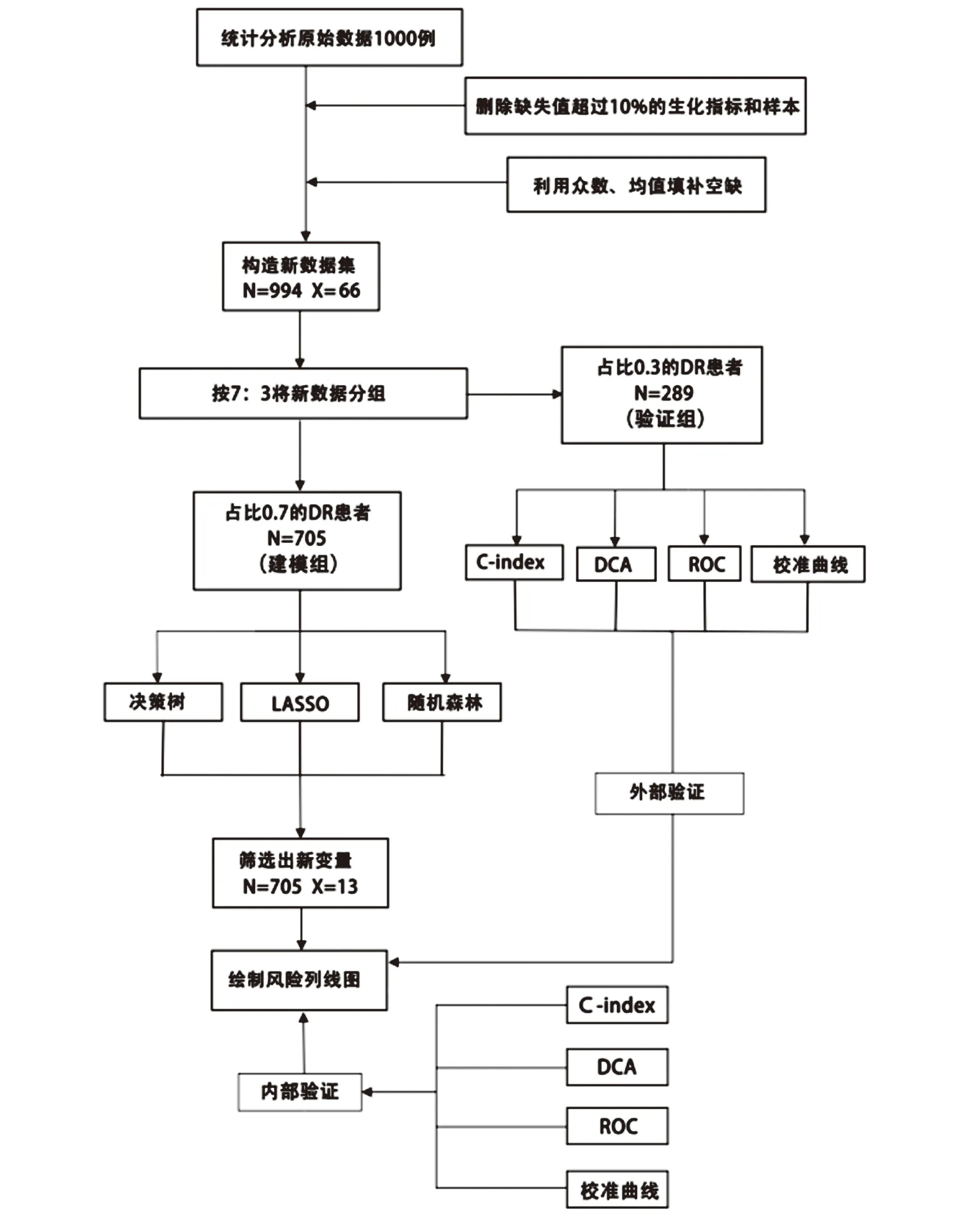
图1 流程图
1.2.1 数据剔除 变量删除:剔除缺失值超过10%的变量,共20例,见表1。个案删除:剔除缺失值超过10%的个案,共6例,其ID编号分别为175、330、611、786、939和998。数据删除:剔除严重偏离均值的数值。

表1 列删除的数据
1.2.2 数据填补 以是否发生DR为分组变量,分组进行数据填补:(1)对于分类变量,以众数进行填补;(2)对于连续性变量,以平均数进行填补;经整理后,共得到994例样本,68个字段(包括66个自变量,以及ID和label)。
1.3 模型构建与验证
1.3.1 分析方法 将使用SPSS 22.0整理后的994例样本数据按7∶3随机分为建模组和验证组(其中建模组705例,验证组289例);采用决策树、Lasso与随机森林三种机器学习算法对建模组数据进行特征变量筛选,并通过韦恩图确定最终的特征变量;分析特征变量在两组数据中均具有可比性,并绘制相应的DR风险预测列线图模型。
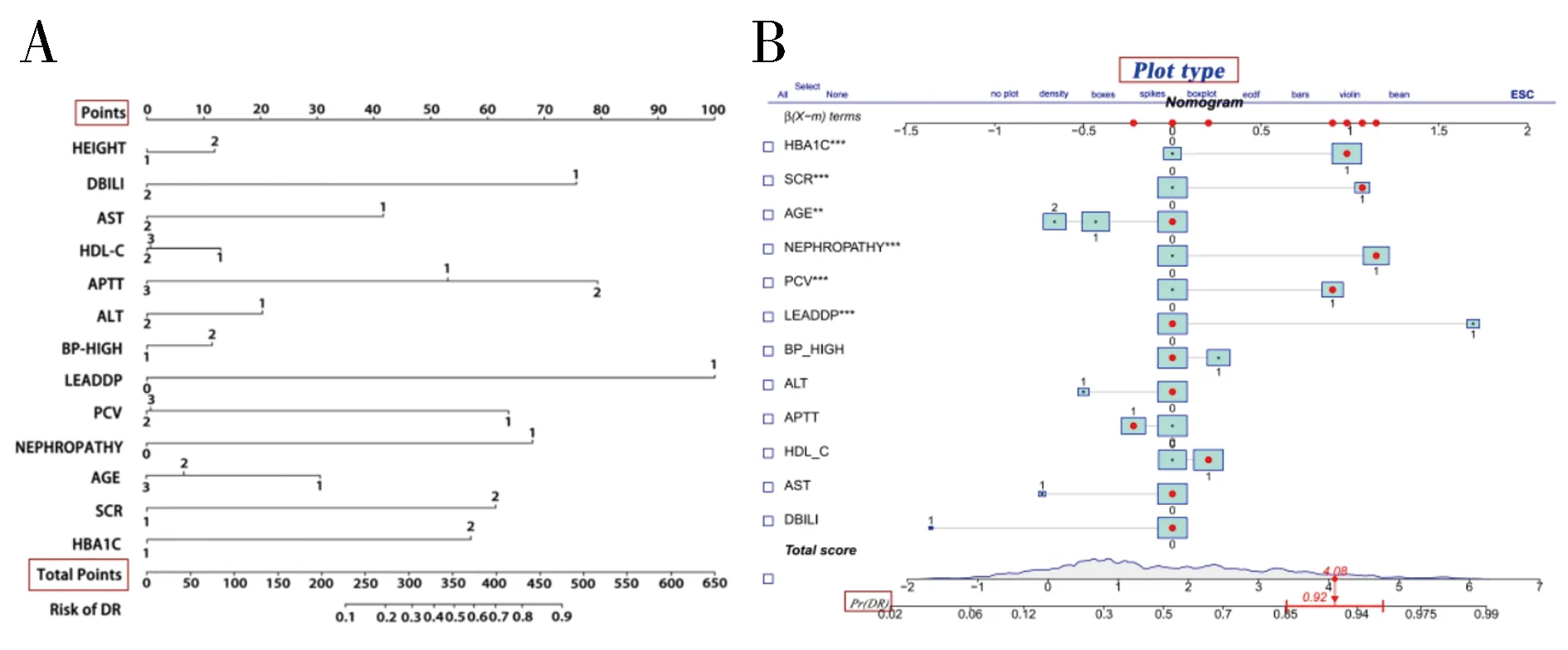
1.3.2 内部验证和外部验证 采用C指数(C-index)、校准曲线(Calibration Curve,CC)、受试者工作特征曲线(Receiver Operating Characteristic,ROC)下面积(Area Under Curve,AUC)以及决策曲线分析法(Decision Curve Analysis,DCA)四种方式,对建模组进行内部验证,对验证组进行外部验证,以检验列线图的效能:(1)C-index是指所有病人对子中预测结果与实际结果一致的对子所占的比例,可以估计预测结果与实际观察结果相一致的概率。一般认为,C-index在0.50~0.70为较低准确度;在0.70~0.90之间为中等准确度;而高于0.90则为高准确度。(2)校准曲线是预测风险和实际风险的拟合线,校准曲线与预测标准曲线越接近说明预测和实测发生率越接近,说明该模型越准确。(3)AUC是ROC曲线下与坐标轴围成的面积,当AUC=1时,即为完美分类器,但绝大多数预测的场合,不存在完美分类器;当AUC=0.5,模型没有预测价值;当0.5 1.4 统计学方法利用SPSS 22.0对数据进行删除、填补及随机分组等处理;使用SPSSPRO平台(https://www.spsspro.com/)进行决策树和随机森林模型的分析;统计分析使用R软件(4.2.1版,https://www.r-project.org/),R的“glmnet包”用于Lasso模型的构建;R的“rms包”用于列线图的绘制(使用“rms包”自带的“lrm函数”构建模型);R的“rmda”包用于DCA的绘制;R的“ROCR”包用于ROC的绘制;R的“rms”包用于校准曲线的绘制和C-index的计算。P<0.05被认为是有统计学意义。 2.1 特征变量筛选 2.1.1 决策树 对建模组数据采用决策树模型,得出相关变量与该模型之间的权重关系,变量重要性排序如表2。再根据权重进行划分,剔除权重小于0.01的变量,最后得到符合情况的相关变量共25个,包括:AGE、HEIGHT、BP_HIGH、A_S、NEPHROPATHY、LEADDP、GLU、HBA1C、TG、HDL_C、LDL_C、BU、SCR、SUA、PCV、PLT、DBILI、TP、LDH_L、ALT、AST、ALP、PT、PTA、APTT。 表2 变量与决策树模型之间的权重关系 表2续表 2.1.2 随机森林 对建模组数据采用随机森林模型,得出相关变量与该模型之间的权重,变量重要性排序如表3。再根据权重进行划分,剔除权重小于0.01的变量,最后得到符合情况的相关变量共24个,包括:AGE、HEIGHT、BP_HIGH、BP_LOW、NEPHROPATHY、CHD、MI、LEADDP、GLU、HBA1C、TG、TC、HDL_C、LDL_C、FBG、SCR、PCV、DBILI、LDH_L、ALT、AST、GGT、ALP、APTT。 表3 变量与随机森林模型之间的权重关系 表3续表 2.1.3 LASSO 采用Lasso算法,进行10倍交叉验证,调整到参数λ的最优解,可获得符合情况的相关变量共33个,见图2。包括:AGE、HEIGHT、BP_HIGH、HYPERTENTION、HYPERLIPIDEMIA、PANCREATIC_DISEASE、NEPHROPATHY、RENAL_FALIURE、CHD、RESPIRATORY_SYSTEM_DISEASE、LEADDP、HEMATONOSIS、RHEUMATIC_IMMUNITY、ENDOCRINE_DISEASE、MEN、DIGESTIVE_CARCINOMA、LUNG_TUMOR、HBA1C、TC、HDL_C、SCR、SUA、PCV、PLT、DBILI、TP、ALB、ALT、AST、GGT、PT、APTT、IBILI。 图2 Lasso模型选择变量 2.2 韦恩图对三种机器学习算法得到的特征变量进行韦恩图绘制,共得到13个特征变量,见图3。包括:DBILI、HDL_C、HBA1C、ALT、AST、PCV、APTT、BP_HIGH、SCR、AGE、HEIGHT、NEPHROPATHY、LEADDP。 图3 韦恩图 2.3 变量信息及赋值情况终筛选出的13个特征变量中既存在连续变量(11个)又存在分类变量(2个)。因此,将11个连续变量赋值,见表4。 2.4 特征变量分析筛选得到的13个特征变量在DR和无DR两组数据中的分析显示,除APTT外,均具有显著的差异统计学意义(P<0.05)(见表5);同时,建模组和验证组数据整体具有可比性 (见表6)。 表5续表 表5续表 表6 特征变量在两组数据中的相似性检验 表6续表 2.5 DR风险预测列线图的构建利用Lasso、随机森林与决策树三种机器学习算法筛选出13个特征变量,构建DR风险预测列线图模型(见图4)。在风险预测列线图的可视化A图中,Points表示变量(DBILI、HDL-C、HBA1C、ALT、AST、PCV、APTT、BP-HIGH、SCR、AGE、HEIGHT、NEPHROPATHY、LEADDP)对应的分数,不同的变量数值,对应的Points值不同(列线图模型的预测分组界值见表4)。再将每一变量对应的得分相加,即获得Total points。以此类推,每位患者的Total points对应的DR风险可以从下方的Risk of DR上读出;此外,我们还可以从风险预测列线图的可视化B图中选取项目(Plot type),即可以直观得到准确的患病率(Pr (DR)),有助于实现临床DR的个体化预测。 图4 DR的风险预测列线图 2.6 DR风险预测列线图的验证采用ROC曲线下面积AUC、C-index、DCA以及CC四种方式,对模型进行内部验证与外部验证,得到风险预测模型的效能:(1)内部验证与外部验证的AUC均为0.818,显示该预测模型的区分能力较好(见图5);(2)内部验证与外部验证的CC揭示DR的预测概率和实际情况之间吻合度良好,显示预测模型的准确性(见图6);(3)内部验证与外部验证的C-index分别为0.822和0.805,显示DR的实际概率和预测概率的一致性较好。(4)内部验证与外部验证的DCA曲线表明,在预测DR的概率时,不同阈值概率下(内部:3%~95%;外部:1%~91%)该预测模型均显示出较好的临床净收益,证实了其实用性(见图7)。 图5 ROC曲线图 图6 校准曲线 图7 DCA曲线图 机器学习是基于统计学与其它多学科知识并结合计算机技术对大数据进行处理的一门交叉学科,是人工智能的一部分。利用机器学习算法,可从海量的数据中筛选出研究所需要的特征变量,有效提高学习效率。目前,机器学习已广泛应用于医学领域,特别是在影像组学与病理图像分割方面,而在临床疾病的风险预测方面还有待深入研究。因此,本研究利用决策树、LASSO与随机森林三种机器学习算法,筛选DR的风险因子,并构建风险预测模型,同时对模型进行内、外部验证,以检验其准确性、可靠性、适用性以及临床应用价值,为DR的预防、治疗以及预后提供可靠的数据支持。 有研究[8]发现,低年龄患者发生DR的风险相较于高年龄患者发生DR的风险更高,提示了高龄可能是DR的保护因素,与本研究结果一致。而Yin L[9]等人发现,DM患者的年龄是DR的风险因素,年龄越大则患者病情加重的可能性越大,发生DR的风险越高。研究结果差异的原因,可能是由于样本量、统计分析方法、采样地区经济与文化发展的差异以及健康素养观等不同造成的。同时,本研究结果显示,APTT的延长为DR的保护性因素,与Palella E[10]等的研究结果具有一致性。DM患者体内常伴随着一系列的代谢紊乱,而异常的代谢会损伤视网膜血管内皮细胞,导致微血管病变;同时损伤会导致体内凝血系统的激活,即表现为APTT的缩短。因此,可以推测DR患者更容易发生血栓事件[11],具体机制除了凝血过程改变外,可能还与内皮功能障碍以及炎症等有关。Zhang[12]等通过纳入6978例DM患者的研究发现,DM组的PCV水平较血糖正常组明显降低,提示PCV可能是DR的保护因素,与本研究结果相同。因此,对DM患者定期进行APTT与PCV等常规检查,对于提早发现DR具有重要意义。 此外,本研究结果提示,NEPHROPATHY是DR的独立危险因素。DR与糖尿病肾病(DN)作为最主要的糖尿病微血管病变,具有相似的危险因素和病理基础。有研究认为DR可能早于DN的发生[13],肾脏的受累即预示着视网膜病变的发生或进展,两者的病变与受损程度在一定程度上呈正相关。而LEADDP虽然不是DM的特异性并发症,但糖尿病足通常伴发LEADDP[14]。因此,DM患者发生LEADDP的危险性较非DM患者明显增加,且起病早、病情严重、预后较差。2013版中国2-型糖尿病防治指南[15]指出,在475例DM截肢患者中,DM截肢患者合并视网膜病变率为25.9%。因此,动态监测血糖、肾功能等相关指标,对于早期发现DR及其他DM相关并发症具有重要价值。 目前,临床上广泛应用筛查DM的指标有HBA1C,它能够反映机体过去6~8周血糖水平,是诊断DM的金标准[16]。而本研究显示HBA1C含量异常增高也是DR的危险因素,与Su[17]等的研究成果具有一致性。陈婕[18]等认为,HBA1C升高会介导血管内皮细胞损伤,并引发白细胞在血管内皮细胞表面粘附,促进血栓形成;而高糖诱导的氧化应激产物和(或)炎症状态,通过对血管壁及血管基质的影响,进一步加重血管内皮及组织损伤,共同参与DR的发生与发展。因此,HBA1C增高的患者,发生DR的风险会明显增高。Huang[19]等研究发现BP-HIGH是DR的危险因素,与本研究结果一致。其影响机制可能是:BP-HIGH的升高会引起视网膜小动脉的损害,诱发小动脉痉挛与硬化,出现动静脉交叉处压迫[20];同时增加血流速度,使得视网膜始终处于异常高灌注状态,而高灌注易造成大量糖元堆积于视网膜,对视网膜毛细血管内皮细胞、毛细血管壁以及周围组织等产生损害[21],导致毛细血管渗漏和视神经乳头水肿等病理改变,进而加重DR。同时,DM患者常伴有血脂代谢异常,以往研究大多集中于血脂代谢异常与DM大血管病变的关系,而对DM微血管病变的研究较少。目前,国内外对于血脂相关指标与DR关系的结论并不一致。本研究结果显示,HDL-C的升高是DR的保护因素,与李荣成[22]的结果具有一致性。而钱[23]等通过对576例DM患者的研究发现,血脂相关指标与DR无明显相关性,与本研究结果有所区别。但由于本研究缺少患者的治疗方案以及治疗的依从性等数据资料,故不能消除相关的偏倚。 总之,通过机器学习的方法,筛选DR发病的重要临床特征,并构建DR的风险预测模型,同时进行内、外部验证,检验所构建模型的临床价值,从而为DR的早期预防、诊断和治疗提供重要依据,有利于提高DR患者的预后和生活质量,具有重要的临床现实意义。2 结果













3 讨论
