试论Power Query M 语言在数据处理中的应用
2022-11-04王译庆
王译庆
(中国石油集团共享运营有限公司西安中心,西安 710018)
0 引 言
Power Query 是微软公司研发的一个数据处理引擎,目前它被内置到Excel、Power BI 等数据处理和分析软件中。Power Query 包含一个独立的图形编辑器界面和一个Power Query M 语言的解释器。用户在图形编辑器上操作,后台会自动生成对应Power Query M 语言的代码,同时图形编辑器提供对处理后的数据进行实时预览的功能。操作图形编辑器可以满足常见的数据处理转换需求,但是一些复杂的数据处理还是需要手工编写或修改Power Query M 语言代码。本文尝试对Power Query M语言的特性和应用进行讨论,以实现复杂的数据处理、转换、分析等业务。
1 Power Query M 语言特性
Power Query M 语言是一个用于数据处理的函数式语言,因此它与常见的命令式编程语言有着很大的不同,按照《Power Query M language specification》的说法,Power Query M 语言是“一个大致纯粹的、高阶的、动态类型化的、部分延迟的函数式语言”[1]。下面我们来讨论该语言的一些主要特性。
1.1 Let表达式
Power Query M 语言是一个用于数据处理的语言,在大多数情况下都是将数据读入,处理后输出。因此,一般情况下,Power Query M 语言程序的主体就是一个Let 表达式。该表达式的作用是完成一系列计算,然后指定一个变量进行输出。
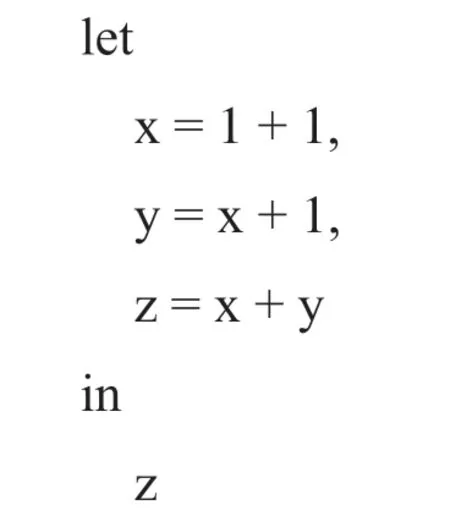
上边的代码进行了一系列计算,然后将计算出的z 变量作为结果输出。
1.2 数据类型
Power Query M 语言主要用于数据处理,它的类型偏向于各种数据的组合,主要类型如下。
1.2.1 Any 类型
该语言的任何类型都是从Any 类型派生出来的,如果没有显式地指定某个变量的类型,那么Power Query M 语言解释器就认为这个变量是Any 类型,即可以是任何类型。
1.2.2 基元类型
基元类型可以是单个值的类型,包括数字(Number),字符串(Text),日期(Date)等。基元类型可以构造出下文中要讨论的结构化类型。广义上讲,任何类型,包括Any 类型,也是基元类型,因为它们也可以构造出结构化类型(嵌套的结构化类型)。
1.2.3 结构化类型
由一个或多个基元类型构造出来的类型就是结构化类型,包含列表类型(List)、记录类型(Record)和表类型(Table)。
1.2.3.1 列表类型(List)
列表类型和其他编程语言的List 类型类似,是由一系列有顺序的元素构成,这些元素可以是任意不同的类型,包括其他的结构化类型来形成嵌套。Power Query M 语言的列表类型数据由一对大括号“{}”表示,中间的多个元素用逗号分隔。例如,{1,2,3,"AB",{4,"D"}},这个列表在Power Query 编辑器中呈现效果如图1 所示。
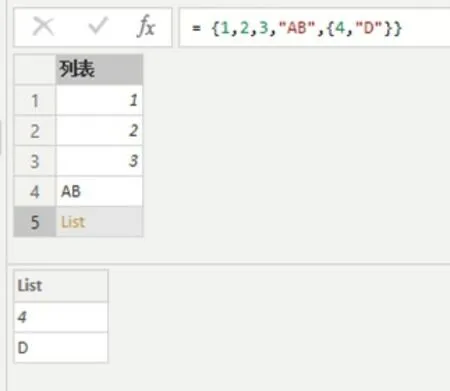
图1 列表类型示例
1.2.3.2 记录类型(Record)
记录类型类似其他编程语言的字典类型。用于表示有键值对(Key-Value Pair)的数据。Power Query M语言的记录用一对中括号 “[] ”来包含,每个键值对的键(Key)在左边,为没有引号的字符串,值(Value)在右边,可以是各种类型的值,按照其本身的表示法直接写出,键和值用等号连接。不同键值对用逗号分隔,例如“[学号=0000001,姓名=“张三”,出生日期=#date(1990,02,26)]”。
1.2.3.3 表类型(Table)
表类型数据就是通常意义的表格,这是Power Query 数据处理中最常见的一种类型,因为Power Query 本身就是被设计来处理表格数据的。通常情况下,大多数Power Query 查询都是从一个外部数据源中导入数据形成表格,然后使用各种函数(可以是内置的,也可以是自定义的)对表格进行数据转换和处理,然后最终输出一个处理后的表格。如果是用于技术研究和论证,也可以直接用Power Query M 语句来构建表格。方法是先定义标题行,然后是数据。例如,以下代码就定义了一个如图2 所示的表格。


图2 表类型示例
表格还可以看作是由一条条结构相同的记录组成的集合。通过集合项访问运算符“{i}”访问表格就可以得到单条记录。例如,上边的表格用过语句“表格{1}”访问可以得到该表格的第一行记录:“[学号=0000001,姓 名=“张三”,出生日期=#date(1990,02,26)]”[2]。
1.3 函数式语言特性
美国数学家阿隆佐·邱奇(Alonzo Church)发明的λ 演算,以变量绑定和替换的规则,研究了函数的抽象化定义、应用以及递归的形式系统。在1937 年,英国科学家艾伦·麦席森·图灵(Alan Mathison Turing)证明了λ 演算和图灵机是等价的[3],这说明λ 演算是图灵完备性的,因此成为了函数式编程语言的理论基础。而常用编程语言,例如C 语言是命令式编程语言,命令式编程语言和函数式编程语言在设计上有着很大的不同。随着信息技术的发展,部分语言虽然是以命令式编程语言为基础,但是它们吸收了函数式编程的一些理念,展现了多重编程范式的特性。例如,Python 语言和JavaScript 语言。纯粹的函数式编程语言,例如,Haskell、Scheme 等,一般用于教学和学术研究,在工业上的应用比起以命令式为主的多重编程范式语言相对要少一些,这些函数式语言在工业上主要用于数据分析、财务分析等领域[4]。Power Query M 语言就是一种大致纯粹的函数式语言,具有和其他的函数式语言一样的特性。
1.3.1 函数定义
Power Query M 语言的函数定义的写法是λ 表达式的写法:(x,y)=> x+y,这里“x”和“y”是参数,“x+y”是函数体。和其他函数式语言类似,Power Query M 语言的函数本身是一种类型,可以赋值给变量,也可以通过变量来调用。例如,下面的代码就是一个函数定义和调用的示例。

1.3.2 纯函数(Pure Function)
在计算机编程中,纯函数具有以下特征:第一,对于相同的参数,每次运行后,函数返回值总是相同的,不受上下文和环境的影响;第二,函数的运行不产生副作用(不影响上下文和其他模块的数据)。因此,纯函数是数学函数在计算机程序中的模拟,和其他函数式语言一样,Power Query M 语言的函数都是纯函数。
1.3.3 头等函数(First-class Function)和高阶函数(Higher-order Function)
许多介绍函数式编程的文献会提到,在函数式编程语言中,函数是“一等公民”。具体来说,就是函数可以作为别的函数的参数、函数的返回值,函数本身还可以赋值给变量,这种语言特性被称为“头等函数”。头等函数特性使得函数的功能和设计非常灵活,能够极大简化映射、排序、遍历等操作。一些流行的编程语言,例如Python 和JavaScript 也引入了头等函数特性。一种编程语言,要具备头等函数的特性,就要用到高阶函数。高阶函数是可以将其他函数作为参数和返回值的函数。Power Query M 语言具有头等函数特性,同时,它内置的许多库函数都是高阶函数。例如对表格机型筛选的Table.SelectRows 函数,就是一个高阶函数,它的定义如下:
Table.SelectRows(table as table,condition as function) as table
可以看出,第一个Table 参数是要筛选的表格,第二个Condition 参数的类型就是一个函数,参数为表格中的每一条记录,返回值为逻辑值的函数,返回值是筛选后的表格。该函数的作用是将Table 参数的表格的每一行记录作为参数代入Condition 函数中,如果返回值为True,该行保留,否则,该行去除,最终返回筛选结果的表格数据。现在以表 1 为例,如果需要筛选出类型为“水果”的记录,可以写出如下代码:
筛选结果=Table.SelectRows(表1,(r)=> r[类型]="水果")
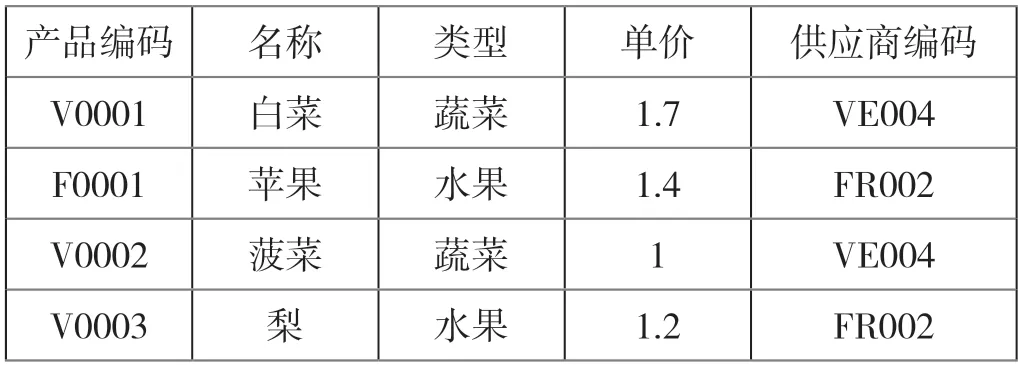
表1 示例数据-商品
运行结果见表2。在Power Query M 语言中,对于单个参数的函数,其参数可用下划线代替:“Table.SelectRows(更改的类型,(_)=> _[ 类型]=" 水果")”,这种写法可以使用“Each”关键字进一步简化:“Table.SelectRows(更改的类型,Each ([类型]="水果"))”,因此“Each”关键字相当于“(_)=> _”[5]。

表2 筛选结果
1.3.4 引用透明(Referentially Transparent)
引用透明是函数式语言的另一个重要特性。如果一个表达式可以被其对应的值替换(或者反过来)而不改变程序的行为,则该表达式称为引用透明[6]。要做到引用透明,一方面要求程序中的函数必须都是纯函数,另一方面,其变量必须是不可变的。许多命令式编程语言的函数既不是纯函数,其变量也是可变的,因此它们是引用不透明(referentially opaque)的。
在1.3.2 节中,我们讨论了纯函数,下面我们来讨论“变量的不可变性”。变量在许多编程语言中,都是一个十分重要的概念。对于命令式编程语言,变量可以在程序中通过赋值语句任意改变,这样的变量就是“可变的”。例如,下列的Python 程序,对变量“a”进行了多次赋值,它的运行结果是“2”:

对于函数式编程语言来说,变量经过一次赋值之后,就不能再赋值了,这种特性称之为“变量的不可变性”。从这个角度上讲,函数式编程“变量”应该叫做“常量”,之所以还叫“变量”,是由于历史习惯。对于Power Query M 语言这种函数式编程语言,变量同样是不可变的,将上面的Python 代码翻译成等价的Power Query M 代码,会出现如图3 显示的错误。

图3 Power Query M 语言变量的不可变性
对于习惯了命令式编程语言的开发人员来说,给变量重新赋值是一个常见的操作,像上文的“a=a +1”在程序设计中很常见,因此许多类C 语言为此提供了一个简化写法:“a++”。变量的不可变性似乎是一个功能缺陷,但是从数学的角度来讲,“a=a+1”这种写法显然是不成立的。引用透明的特性使得函数式语言比命令式语言更加贴近数学,更适合以数学的思维来解决问题,同时也能够让函数式语言的语句在不同的上下文环境中运行结果相同,且运行后也不影响上下文环境,在多线程、并行计算中比命令式语言更加有优势。
1.3.5 递归(Recursion)
引用透明特性使得函数式语言无法具备命令式语言常见的For 循环和While 循环这类迭代功能。函数式语言中的迭代通常是通过递归来完成的。递归函数调用自己,让操作重复,直到它到达初始状态,然后计算出结果。例如,使用Power Query M 语言通过递归方式实现阶乘:

互递归的两个函数相互引用,如果直接放到Let语句中会引发循环引用的错误,对于函数式语言来说,函数也是一种数据类型,因此将它们放到一个列表中就可以解决这个问题。
1.3.6 惰性求值(Lazy Evaluation)
惰性求值,也叫做延迟求值,是许多函数式编程语言都有的特性。它是指一个表达式被赋值给变量后并不会被计算,直到确定需要得到结果(例如,需要输出结果)时才会计算出结果。与其相对的是“及早求值”,即遇到表达式就计算出结果,这是许多命令式语言所用的特性。对于Power Query M 语言来说,只有“列表”“记录”和“表”类型中的元素以及Let 表达式是惰性求值的,剩余的其他表达式都是及早求值,这样可以避免重复计算,提高了性能。
2 案 例
2.1 背景和需求
某工厂有A、B、C 三个特殊工作区域,在这些区域工作需要发放特殊津贴,每个区域的津贴标准都不相同,表3 是不同区域不同职位等级工作一天要发放的津贴标准(日标准)的对应关系。

表3 特殊津贴日标准
员工每天根据工厂生产安排,在特定的工作区域工作,每个月在不同区域工作天数都不相同,员工在不同区域的工作天数会被输入到人力资源系统的考勤模块中。人力资源系统在内部网络中提供了一个读取考勤数据的Web API 接口,调用后会返回一个Json 格式的数据,读取出的数据如表 4。
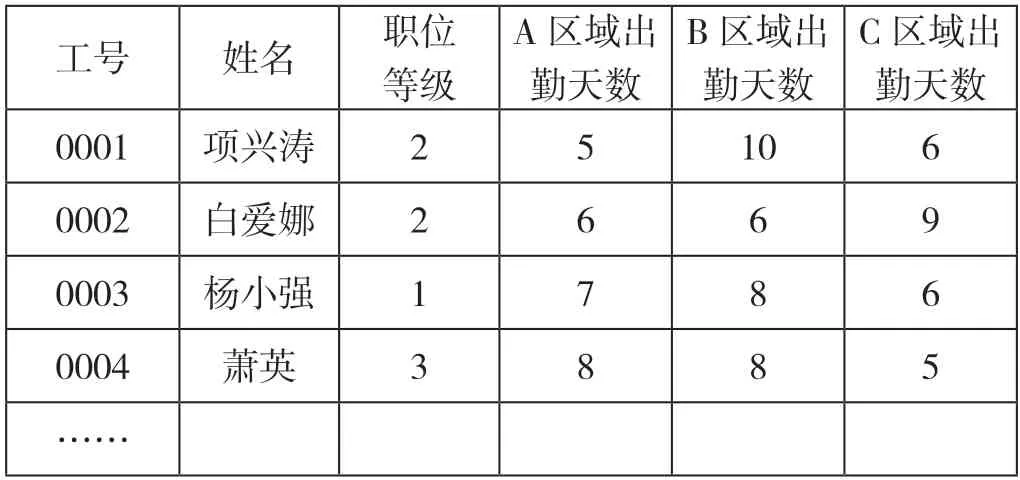
表4 考勤数据
根据以上数据,每个员工特殊津贴的计算方法为对应职位等级的区域日标准乘以该区域的出勤天数,然后分别相加,具体如公式(1)所示。
特殊津贴=∑区域日标准×该区域出勤天数(1)
因此,最后确定的需求是依据考勤数据读取接口中获取的数据来自动计算每个人的特殊津贴。考勤数据每月都会更新,所以考勤数据更新后,计算结果也要具备自动刷新的能力。
2.2 实 现
2.2.1 编写特殊津贴计算函数
根据特殊津贴计算规则,需要定义一个特殊津贴的计算函数,该函数使用考勤数据的四个字段作为参数,分别是职位等级和三个区域的出勤天数。特殊津贴的日标准可以直接从表3 获取。这样,就可以用Power Query M 语言来实现这个函数。


内置的Table.SelectRows 函数在1.3.3 节中已有介绍,Table.SelectRows 函数虽然完成了按照“职级”参数对表 3 进行了筛选,但是它返回的类型是表格,这时,就需要用内置的Table.First 函数将其转化为一条记录类型,以便直接计算结果。Table.First 函数的作用是将一个表格的第一行变成记录类型的数据,在此处,筛选出的日标准数据只有一行,符合这里的需求。
2.2.2 完成对考勤数据的计算
Power Query 可以直接读取Web 接口返回的数据,在本例中,考勤数据读取接口在内部网络的URL地址为:“http://hr.erp.fab/api/Attendance”。开发者在设置好读取来源后,Power Query 会自动生成数据导入部分的代码,导入的结果为表格类型。然后将计算函数的调用代码添加进去就可以完成最终的计算,最终完成的查询程序如下,运行结果见表5。
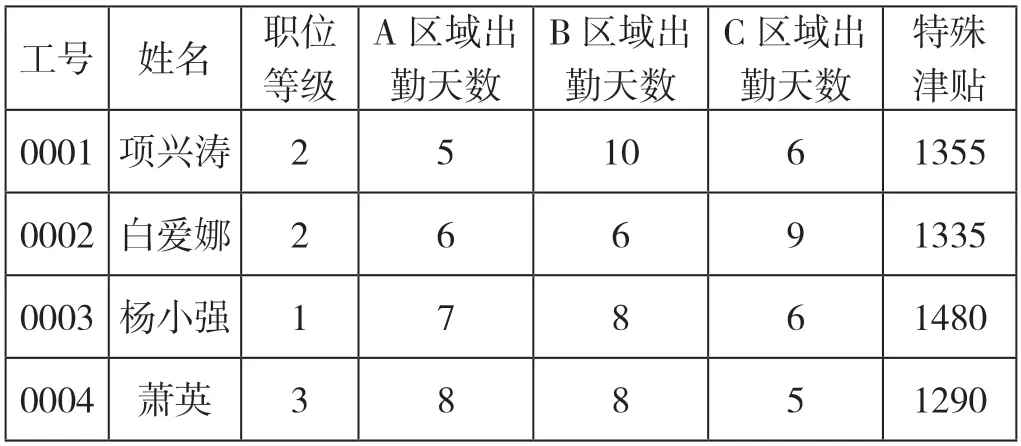
表5 运行结果
let
源=Json.Document(Web.Contents("http://hr.erp.fab/api/Attendance")),
转换为表=Table.FromList(源,Splitter.SplitBy Nothing(),null,null,ExtraValues.Error),
展开=Table.ExpandRecordColumn(转换为表,"Column1",{"工号","姓名","职位等级","a 区域出勤天数","b 区域出勤天数","c 区域出勤天数"},{"工号","姓名","职位等级","A 区域出勤天数","B区域出勤天数","C 区域出勤天数"}),
导入的考勤数据=Table.TransformColumnTypes(展 开,{{" 工号",type text},{" 职位等级",Int64.Type},{"A 区域出勤天数",type number},{"B 区域出勤天数",type number},{"C 区域出勤天数",type number}}),
//以上代码是Power Query 数据导入模块生成的,完成了考勤数据接口的调用
调用津贴计算函数=Table.AddColumn(导入的考勤数据,"特殊津贴",each 特殊津贴计算函数([职位等级],[A 区域出勤天数],[B 区域出勤天数],[C 区域出勤天数]))
in
调用津贴计算函数
在上述查询程序中,我们使用了内置的Table.AddColumn 函数,它的定义是:
Table.AddColumn(table as table,newColumnName as text,columnGenerator as function,optional columnType as nullable type) as table
该函数的作用是给table 参数所指向的表格增加一列,newColumnName 参数是新增的列标题,columnGenerator 参数需要传入一个函数,其参数是table 参数中的每一列。上述查询程序中columnGenerator 参数使用了“each”关键字进行了简化,如果完整写出其等价语句则是:
调用津贴计算函数=Table.AddColumn(更改的类型,"特殊津贴",(r)=> 特殊津贴计算函数(r[职位等级],r[A 区域出勤天数],r[B 区域出勤天数],r[C 区域出勤天数]))
通过以上的工作,我们成功建立了一个根据考勤数据自动计算特殊津贴的查询程序。如果考勤查询接口的数据更新了,我们只需要重新运行一下查询程序,计算结果就会自动更新。
3 结 语
通过以上的讨论,可以看出Power Query M 语言作为Power Query 数据处理引擎的开发语言,具有函数式开发语言的优良特性,在数据转换、分析、计算等领域具有非常大的优势。数据处理程序编写完成后,Power Query 从数据源获取数据后就可以直接输出结果,不需要人工干预。用户既可以从Power Query工具中自动生成Power Query M 语言代码来完成一些简单常用的数据转换操作,也可以手工编写Power Query M 语言代码完成复杂的数据分析处理操作,满足了业务上的不同需求。
