基于管理层净语调与SMOTE 的上市公司信用风险评估
2022-11-04王文胜沈超
王文胜,沈超
(杭州电子科技大学经济学院,杭州 310018)
0 引 言
风险预警方式主要分为统计分析法和机器学习法,前者包括线性判别分析、概率模型等,后者包括支持向量机、随机森林等。这些模型在国内风险预警领域得到广泛运用,但存在共同缺陷,即模型的特征变量均以定量财务指标为基础,而忽视非财务指标的作用[1-3]。
风险预警领域往往存在数据严重不平衡,一般采用配对样本,但配对样本会忽略部分多数类样本信息,此外预测结果本身是相对于配对样本而言的,类似条件期望,缺乏普遍适应性。聂瑞华等利用SMOTE采样结合贝叶斯网络进行风险预警,证明SMOTE 抽样能提升模型的预测效果[4]。
本文研究贡献主要有两方面:一是将管理层讨论与分析反映的净语调纳入企业信用风险研究;二是以SMOTE 抽样取代配对样本,有效利用多数类样本信息,提高模型预测效力。
1 实证研究设计
1.1 实证方法的选择
1.1.1 Logistic 回归
信用风险预警领域,Logistic 回归模型较为常用,其对变量分布无具体要求,可解决非线性分类问题。其表达式如下:

其中P表示企业面临信用风险的概率,S表示Logit 回归值,α表示常数项,β表示参数估计系数,x表示影响信用风险发生的特征。P值越接近1,则表示企业面临信用风险越大;反之,信用风险越小。本文设定违约概率阈值为P=0.5。
1.1.2 支持向量机
支持向量机SVM 适用于二分类问题,其原理是寻找出一个区分类别的超平面,求解的最优化问题原问题表达如下:

对偶问题表示如下:

式中w表示法向量,决定超平面方向;b表示位移量,决定超平面与原点的距离;yi表示所属类别,φ(x) 表示输入空间到高维特征空间的非线性转换。当特征空间为高维时,φ(xi)Tφ(xj)内积计算较为复杂,需引入核技巧:

式中k(xi,xj)表示核函数,本文采用RBF 径向基核函数。
1.1.3 随机森林
随机森林以决策树为基分类器,通过bagging 集成算法,克服单一决策树偶然性大、复杂和易陷入局部最优等缺陷。通过bootstrap 重抽样技术,构建N棵决策树构成随机森林,最终通过投票法,对各决策树分类结果汇总归票。决策树由节点和有向边构成,遍历所有节点,以基尼指数选择最优划分属性,划分后对子集再进行划分属性的选择,直至划分前后集合纯度不变或者命中相应停止条件。基尼指数表示在样本集合中一个随机选中的样本被分错的概率,Gini 指数越小表示集合中被选中的样本被分错的概率越小,集合的纯度越高,反之,集合越不纯。样本的基尼指数如下:
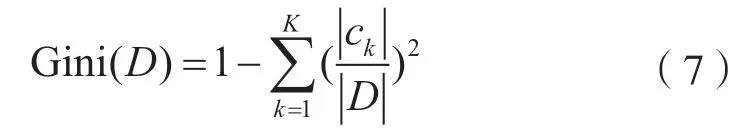
其中k表示样本集合中类种类数,ck表示k类别个数,D表示样本集合总数。
1.2 财务比率的选择
本文从偿债能力、成长能力、盈利能力、营运能力、资本结构五个方面选取18 个财务指标,具体包括净资产收益率、总资产报酬率、总资产净利率、每股收益增长率、营业收入增长率、营业成本增长率、毛利增长率、净资产增长率、资产负债率、权益系数、流动比率、速动比率、现金流量利息保障倍数、现金比率、存货周转率、应收账款周转率、应付账款周转率、总资产周转率。
1.3 管理层净语调计算
针对金融大数据文本语调分析,采用词袋模型法来度量管理层净语调。管理层讨论与分析(MD&A)分词采用Python 结巴分词模块,正面词汇、负面词汇字典以Tim Loughran and Bill McDonald(2011)为基础,再结合中文语境扩充、完善所得。文本分词完成后,统计其正面词汇词频(POS)和负面词汇词频(NEG),利用简单加权平均,计算管理层净语调Tone。

1.4 SMOTE过采样
针对信用风险领域的不平衡性,一般做法为配对样本,然而配对样本会丢失部分多数类样本的信息,因此,本文探究多种不平衡度下SMOTE 样本及配对样本的表现。SMOTE 算法如下:
a.根据不平衡状况确定需过采样的少数类样本数num。
b.针对每一个少数类样本,利用欧式距离计算出其k 个近邻点。
c.按式(9)合成新的少数类样本。

2 样本和数据
2.1 样 本
本文参照石晓军[5]的做法,以ST 作为风险标志,利用上市公司t-2 年财务数据和MD&A 文本数据预测其是否会在t年出现信用风险。数据选择方面,从CSMAR①CSMAR 网址:https://cn.gtadata.com/(原国泰安金融数据库)中选取2016—2018年期间上市制造业企业ST 样本95 条,相应的上市制造业企业非ST 样本3 792 条。
2.2 数据描述
本文采用Wilcoxon-Mann-Whitney 检验ST 企业和非ST 企业之间差异显著性。财务指标方面,除应收账款周转率以外,其余17 个财务比率均可显著区分ST 企业和非ST 企业;净语调方面,非ST 企业的净语调均值为0.386,ST 企业净语调均值0.257,检验Z 值为-9.064,非ST 企业净语调显著高于ST 的企业,表明企业年报传递的管理层净语调与企业信用风险发生概率存在联系。
3 实证结果分析
为明确管理层净语调在上市企业风险预警方面的作用,采用逻辑斯蒂回归、支持向量机、随机森林建模,并根据AUC、准确率、查准率、召回率、Fscore 五个指标判断。为防止多重共线性,将方差膨胀因子阈值设置为10,从原始变量中剔除总资产收益率、总资产净利率、速动比率和现金比率。为对比各不平衡度下SMOTE 样本和配对样本的效果,按照1∶1、1∶2、1∶5、1∶10、1∶20的比例选取样本,每组样本中ST 企业数均为95。除配对样本外,其余不平衡数据样本均采用SMOTE 过采样至1 ∶1。为简化表示,将样本表示为10 类,即Group 1~Group 10。Group 1、Group 6 分别表示未加语调和加入语调的配对样本;Group 2~Group 5、Group 7~Group 10 分别表示未加净语调和加入净语调的不平衡度为2、5、10、20但已SMOTE 过采样处理的样本。基于建模稳定性,各不平衡度SMOTE 处理重复50 次,每组样本进行建模时采用10 折交叉验证法,超参数选取利用贝叶斯优化[6]取代传统网格搜索。
3.1 基于Logistic回归的分析
通过Logistic 回归构建的上市企业风险预警模型预测结果及分析如下。首先,Group 6~Group 10 的AUC、准确率均优于Group 1~Group 5,组平均AUC从89.35%提升至91.03%,组平均准确率从82.13%提升至84.01%,说明管理层净语调对模型效力有所提升。其次,Group 1~Group 5 的AUC、准确率、召回率、F-score 逐步提升。原因可能在于不平衡度越高,在ST 样本数固定为95 条件下,纳入的多数类样本即非ST 样本数更多,多数类样本中包含了风险预警的部分信息,使得模型对于少数样本的识别率提升。再次,Group 6~Group 10 的AUC 不断提升,但准确率呈现先上升后下降情况,原因可能是高不平衡度下模型分类阈值需要重新调整,也有可能是在引入非财务指标净语调之后,高不平衡度增加SMOTE 产生噪点的概率,从而影响模型准确率。最后,不论是否添加净语调指标,随着不平衡度升高,纳入的多数类样本增多,各项指标均有提升,但提升效果逐渐减弱。Group 1~Group 5 中,AUC 最高提升2.27%,最低提升0.28%;Group 6~Group 10 中AUC 最高提升2.49%,最低提升0.12%。
为进一步厘清净语调对于上市企业风险预警的关系,本文将被ST 公司即风险公司记为1,非ST 公司记为0,构建Logit 回归模型:

其中STi,t为企业信用风险指标;自变量为净语调Tonei,t;控制变量为入选的财务变量;本文采取上市公司样本均为制造业,但年份不一致,为控制年份影响,添加年份虚拟变量Yeari,t。结果显示,β参数估计值为-0.019,在1%显著性水平下为负,表明净语调数值越大,公司发生信用风险的概率就越小;反之,发生信用风险的概率越大。
3.2 基于支持向量机的分析
通过支持向量机构建的上市企业风险预警模型预测结果及分析如下。首先,Group 1、Group 6 均为配对样本,Group 6 加入净语调之后模型指标显著差于Group 1;剔除Group 1、Group 6,未加语调组平均AUC 为92.27%,添加语调组平均AUC 为92.98%;未加语调组平均准确率为87.15%,添加语调组平均准确率为87.10%。添加净语调指标对于模型效力的提升不明显。其次,SMOTE 样本组指标均优于配对样本组,同时Group 2~Group 5、Group 7~Group 10,随着不平衡度升高,其AUC、准确率指标有所提升。原因可能是纳入多数类样本量增多,提升了模型的预测能力。值得注意的是,Group 7、Group 9 的准确率低于Group 2 和Group 4,原因可能是新纳入的净语调会使得SMOTE 产生噪点概率提高。最后,不论是否添加净语调指标,随着不平衡度升高,纳入的多数类样本增多,AUC 均有提升,但提升效果逐渐减弱。Group 1~Group 5 中,AUC 最高提升1.10%,最低提升0.45%;Group 6~Group 10 中AUC 最高提升3.58%,最低提升0.53%。
3.3 基于随机森林的分析
通过随机森林构建的上市企业风险预警模型预测结果及分析如下。首先,配对样本中,Group 1的AUC 略高于Group 6,但其他四项指标均低于Group 6;Group 7~Group 10 的各项指标优于Group 2~Group 5。未加语调组平均AUC 为94.15%,添加语调组平均AUC 为94.45%;未加语调组平均准确率为88.32%,添加语调组平均准确率为88.67%。表明净语调对于模型的预测能力有所提升。其次,Group 1~Group 5、Group 6~Group 10 的AUC、准确率不断提升,表明纳入更多多数类样本量可提升模型预测能力,且SMOTE 样本效果普遍优于配对样本。最后,不论是否添加净语调指标,随着不平衡度升高,纳入的多数类样本增多,AUC 均有提升,但提升效果逐渐减弱。Group 1~Group 5 中,AUC 最高提升2.38%,最低提升0.13%;Group 6~Group 10 中AUC 最高提升2.88%,最低提升0.24%。
通过随机森林得出特征重要性,为进一步风险预警的指标选择提供参考。以Group 4、Group 9 为样本所得重要性排序图为例,前者未加净语调,后者添加净语调。两者头部特征高度相似,重叠特征为净资产收益率、基本每股收益增长率、现金流量利息保障倍数、权益系数和总资产周转率,并且Group 9 中显示净语调重要性高于总资产周转率。
4 研究结论与启示
管理层讨论与分析(MD&A)是上市公司年报的重要内容,其中包含一些定量财务数据无法反映的增量信息,通过对管理层讨论与分析的文本挖掘,能更好的预测公司信用风险。首先,本文将公司年报管理层讨论与分析的净语调和财务比率相结合,采用逻辑斯蒂回归、支持向量机和随机森林构建风险预警模型,并采用贝叶斯优化超参数,对模型加入净语调的预测能力进行实证检验。其次,针对信用风险样本的不平衡情况,使用SMOTE 过采样处理,对比配对样本及不同平衡度SMOTE 抽样的训练效果,主要结论如下。
第一,添加MD&A 的净语调后风险预警模型的预测能力有所提升,不论配对样本还是SMOTE 样本都成立,表明企业年报中MD&A 存在信用风险预警的增量信息,且Logit 回归分析得出,净语调越大,企业发生风险概率越低。
第二,考虑配对样本挑选存在主观性、会丢失部分的多数类信息等缺陷,采用SMOTE 方式处理不平衡数据。对比多种不平衡度下SMOTE 样本训练效果,发现SMOTE样本训练模型各项指标较配对样本更优,且不平衡度越高,SMOTE 样本的指标效果更明显,从侧面反映纳入的多数类样本更多,模型风险预警能力越强。
第三,随着不平衡度提高,SMOTE 过采样样本建模的指标一直是变好的,但提升幅度逐渐减弱甚至为负。原因可能是过高不平衡度下SMOTE 过采样生成的新少数类样本存在信息重叠或者引入噪点,对于模型的效力甚微或无提升效果;净语调会提升高不平衡度下SMOTE 生成噪点的概率。综合逻辑斯蒂回归、支持向量机和随机森林预测结果,认为在不平衡度为5~10 时,采用SMOTE 过采样便可得到满意的分类效果,不需纳入全部多数类样本。
在财务指标选取方面,不管是否引入净语调,头部特征存在高度重叠性,之后研究可以着重分析净资产收益率、基本每股收益增长率、现金流量利息保障倍数、权益系数和总资产周转率;其分别对应财务比率选择五大指标,印证财务比率选择的合理性。在模型选择方面,随机森林>支持向量机>逻辑斯蒂模型,原因可能在于支持向量机可通过核函数达到高维非线性可分,而随机森林更是通过集成学习克服单一分类器的偶然性。
