数字人文视域下SikuBERT增强的史籍实体识别研究*
2022-09-23刘江峰冯钰童王东波胡昊天张逸勤
刘江峰,冯钰童,王东波,胡昊天,张逸勤
0 引言
中华文明源远流长,一本本典籍演绎着一幅幅绚丽的历史画卷。以人为鉴,可以明得失;以史为鉴,可以知兴替。从漫长的历史中获取知识与经验,是实现国家富强、民族复兴、人民幸福的制胜法宝。近年传统人文学科社科化、社会科学信息化的趋势日益增强,数字人文(又称人文计算)研究悄然兴起,为传统人文与社会科学研究提供了新的研究范式[1]。文本挖掘与可视化分析成为数字人文领域研究的重要技术,典籍文献的深度挖掘和利用成为可能。从研究的精细程度来看,文献信息处理主要分为词汇级、句子级、篇章级。古文词汇级研究主要包括自动分词、词性标注与命名实体识别[2]。其中,实体识别作为实体关系识别、知识图谱构建以及其他研究的基石,其准确性和效率尤为重要。
随着深度学习技术的发展,文学、地理、天文等领域均对命名实体识别进行广泛研究。机器学习时代,CRF模型能够融合上下文特征,被广泛应用于常见实体的识别,但存在过分依赖标注数据集的缺点,对较少见的实体名称,识别效果不够理想。近年来,深度学习技术日益成熟,诸如LSTM、BERT模型及其变体在命名实体识别领域均有很多成功的应用。由于语法上的独特性且与现代汉语、英语存在较大差异,汉语古文语料的分词、词性标注、命名实体识别难度较大。
2018 年Google 发布基于双向Transformer编码器表征的语言模型(BERT)。在BERT 模型中,一个已经过大量语料预训练的预训练模型能使模型的下游应用效率更高:只需一个额外的输出层就可对已有的预训练模型进行微调,并应用在各类领域任务中,无需根据特定任务对模型进行实质性修改。BERT发展了预训练-微调的语言模型研究新范式。当前常用中文预训练模型包括Google官方提供的BERT-Base-Chinese(以下简称“BERT-base”)、哈尔滨工业大学讯飞联合实验室提供的中文RoBERTa、北京理工大学提供的GuwenBERT等。其中,BERT-base和RoBERTa是基于中文维基百科的包含简体与繁体中文的预训练模型,GuwenBERT是基于殆知阁古汉语语料的简体中文预训练模型。相较于殆知阁古汉语语料,中文维基百科在语法上与典籍文献有较大差异;而GuwenBERT却是完全采用简体中文古文文献的预训练模型。可以预见,在繁体中文的典籍文献命名实体识别中,上述3个预训练模型皆有其各自的优缺点。
《四库全书》是我国古代最大的文化工程,完整呈现了我国古典文化的知识体系。近日由南京农业大学信息管理学院牵头、南京师范大学文学院参与,使用《四库全书》繁体版本语料分别在BERT-base和Chinese-RoBERTa-wwmext(以下简称“RoBERTa”)上进行继续训练的SikuBERT、SikuRoBERTa发布。该研究在基于《左传》语料的自动分词、词性标注、断句、命名实体识别等下游任务上作了简要验证,效果较上述3 个预训练模型均有不同幅度的提升。因此,本文尝试利用BERT-base、RoBERTa、GuwenBERT、 SikuBERT、 SikuRoBERTa 等BERT预训练模型,以《左传》《史记》《汉书》《后汉书》《三国志》等为实验语料,对人名、地名、时间词等3种历史事件的主要构成实体进行识别,进一步探究SikuBERT、SikuRoBERTa在不同典籍、不同规模、不同语体风格语料上的泛化能力并作可能的改进尝试。
1 研究回顾
1.1 数字人文视域下的古籍智能信息处理
数字人文(Digital Humanities)[3]为传统人文学科提供了新的研究方法,着眼于数字化文本计算,如“数字敦煌”项目[4]、青州龙兴寺遗址出土佛像保护项目[5]以及其他古籍修复[6]项目。近年随着各类资源数字化规模的扩大和机器学习、大数据等计算机技术的飞速发展,数字人文研究模式转变为采用数据密集型计算来服务人文学科领域[7]。在20世纪末期,我国古籍数字化研究就已取得一定成果,如1999年史睿[8]提出古籍数字化构建方案。21世纪初以来,我国逐步构建了大批古籍数据库[9],古籍数字化技术[10](如数字化输入技术、OCR光学识别技术、字处理技术、智能化处理技术)得到很大发展。近年文本挖掘技术的进步推进了古籍信息智能处理研究的不断发展,自然语言处理技术为更加方便地处理、利用古文文本知识提供了理论、方法和应用思路。其中,古文自动断句、古文词汇处理(分词、词性标注、命名实体识别等)是古籍智能处理的关键方向。
(1)古文自动断句。古文断句是根据古代汉语句子的组合原则,结合现代汉语的句读集合,通过自动和智能化的策略完成对古代汉语自动添加句读的功能,进而实现对古代汉语句子的断句[11]。目前古文自动断句技术主要分为两类。一是基于规则库的方法,主要由人工制定断句规则来进行匹配,如黄建年[12]构建了农业古籍的断句标点规则库,并设计出农业古籍断句标点的原型系统。再如,陈天莹等[13]提出了基于上下文的N-gram模型,用于古文断句。但这种方法由于规则的泛化能力较差、难以覆盖全面等原因,越来越不被学者使用。二是基于机器学习或深度学习的方法。一些学者[14-15]提出了层叠条件随机场模型,这一策略的性能比基于规则匹配的方法效果更优,更加适用于古文断句。王博立等[16]提出一种基于循环神经网络的古文断句方法,在大规模语料上训练后能获得比传统机器学习更高的准确率。俞敬松等[17]使用BERT+微调模型对《道藏》文本进行断句,模型的效果优于BiLSTM+CRF模型并拥有较好的泛化性。这类深度学习方法是目前主流的自动断句方法,拥有较大的研究空间和研究价值。
(2)古文词汇智能处理。古文词汇处理是指通过计算机算法,对数字化处理后的古代典籍文献进行自动分词、词性标注、命名实体识别等操作,从而开展词汇层面的知识挖掘[18]。由于汉语中词与词之间没有分隔,需要对句子进行词汇切分。自动分词技术可以使分词更为高效、准确,同时也是进行词性标注、命名实体识别的基础。基于机器学习的自动分词方法是目前的主流分词方法。比如,梁社会等[19]利用条件随机场模型和注疏文献对《孟子》进行自动分词;魏一[20]使用殆知阁古汉语语料进行BERT 模型训练,使用《左传》数据集进行模型测试,获得了泛化能力和稳定性较好的分词模型。
古文的词性标注是在分词的基础上,按照一定的规则为词语标注对应的词性,以进一步增强词汇的特征。目前词汇标注主要通过机器学习展开,有分词和词性标注分别进行和分词与词性标注一体化两种方式。例如,王东波等[21]使用条件随机场模型,并结合统计方法确定组合特征模板,得到具有较强推广性的先秦典籍词性自动标注模型。石民等[22]使用条件随机场模型对《左传》文本进行分词标注一体化实验,证明一体化方法可以提高分词和词性标注的精度。留金腾等[23]在上古汉语分词和词性标注的过程中,采用自动标引和人工校正相结合的方式,使用条件随机场模型并尝试调整特征模板进行分词和词性标注,有效提高了模型准确性,减少了后续人工校正的工作量。
命名实体识别是古文词汇处理过程中的关键环节,也是本文的研究内容。如皇甫晶等[24]以《三国志·蜀书》为实验文本,验证了基于规则匹配的方式进行实体命名识别的可行性;朱锁玲等[25]以《方志物产》为语料,采用规则匹配和统计学习相结合的方式,实现了物产地名的自动识别。诸多学者[18,26]在进行古籍命名实体识别研究时,使用隐马尔科夫模型(HMM)、最大熵模型(ME)、支持向量机(SVM)、条件随机场模型(CRF)等统计机器学习模型。近年随着深度学习技术的不断深入发展,各类深度学习模型被应用于各类命名实体识别任务。命名实体识别既是古文信息提取的重要任务,也是文本结构化的基本步骤。
1.2 命名实体识别
以命名实体识别(Named Entity Recognition,NER)为代表的信息抽取技术研究,最早开始于20 世纪60 年代。MUC-6(Sixth Message Understanding Conference)会议提出,命名实体识别研究为信息抽取效果评测的重要指标之一[27]。按其历史发展进程,命名实体识别研究主要分为基于规则和词典匹配的命名实体识别、基于统计机器学习的命名实体识别、基于深度学习的命名实体识别等3类。早期的命名实体识别主要采用基于规则的方法,通过分析实体的特点及其在语言文本中的特征,构建一定数目的规则,从文本中匹配符合这些规则的实体。这些规则往往需要众多领域专家耗费较长时间来构造,且可移植性差。随着领域知识的发展,规则还需要不断更新。如今,这类方法在特殊语种(如阿拉伯语[28])的命名实体识别上尚有一定应用。
(1)基于机器学习的命名实体识别。20 世纪90 年代,基于统计机器学习的命名实体识别研究逐渐兴起。隐马尔可夫模型(Hidden Markov Models,HMM)、最大熵模型(Maximum Entropy Models,MEM)、支持向量机(Support Vector Machines,SVM)、条件随机场(Conditional Random Field,CRF)等统计机器学习模型成为该时期改进NER研究的重点。1999年Bikel等[29]使用HMM对日期、时间等实体进行识别,在英语、西班牙语的语料测试中取得较好的结果。Borthwick等[30]将MEM与其他基于规则的查找工具结合,提出一个最大熵命名实体(MENE)系统。Lee等[31]提出基于SVM的两阶段命名实体识别器,使用生物医学领域的GENIA语料进行测试,有效解决了语义分类的多类问题。Song等[32]使用CRF模型对生物医学语料进行命名实体识别,获得具有竞争力的系统POSBIOTM-NER。基于统计机器学习的NER研究,主要思路是将实体识别问题转换为序列标注问题。HMM的输出独立性假设使其无法考虑上下文特征,MEM弥补了这一缺陷,但其在每个结点都要进行归一化处理,只能获得局部最优解。而CRF模型不仅考虑上下文特征,还实行全局归一化,能得到全局最优值,较HMM、MEM等效果更优。因此,在众多机器学习模型中,CRF模型更受到学者的关注。
在CRF的模型训练方面,McCallum[33]提出一种自动归纳特征的方法,可以提升准确性、显著减少参数计数,并提高模型在命名实体识别实验中的性能。Cohn等[34]提出一种利用纠错输出码(ECOC)训练CRF模型的方法,发现纠错CRF训练消耗的资源更少,能有效缩短实体识别时间。在中文命名实体识别方面,向晓雯[35]以CRF为基本框架,采用层叠结构构建了适用于人名、地名的命名实体识别系统。何炎祥等[36]使用CRF模型进行地名识别,并加入规则库对实体进行召回,研究表明,设计合适的规则可以提升识别效率。郭剑毅等[37]提出一种旅游领域命名实体识别方法,能实现嵌套景点、特产风味等实体的识别,此实证研究表明,采用层叠CRF模型,比HMM和单层CRF模型的性能有所提高。CRF模型拥有灵活加入多种特征、克服标注偏置问题等优点,但随着深度学习技术的兴起和发展,命名实体识别领域的技术重心逐渐向深度学习偏移。
(2)基于深度学习的命名实体识别。2006年Hinton等[38]提出深度学习的概念,开启深度学习在学术界和工业界的应用浪潮。近年深度学习通过模拟人脑的识别处理能力,成为热门的技术研究方向。在命名实体识别研究中,深度学习逐渐取代基于统计机器学习的方法。其中,主流深度学习模型有卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和最近提出的Transformer。
卷积神经网络(CNN)是一种前馈神经网络,主要由输入层、卷积层、池化层、激活层以及顶端的全连接层、损失函数层组成[39],模型参数小,表达能力强。在命名实体识别中,Collobert等[40]首次使用CNN 与CRF 结合的方式来实现NER,发现加入CRF层后NER的效果有了明显提高。Strubell等[41]提出了DI-CNN模型,通过在卷积核中增加空洞,扩大上下文的接收宽度,使模型获得更好的泛化能力。Zhu等[42]同时使用字符嵌入和单词嵌入,提出GRAM-CNN模型,用于生物医学领域的实体识别。
循环神经网络(RNN)是一种链式连接的递归神经网络,其最大的特点就是对输入信息有记忆功能,但RNN存在梯度消失等问题;于是出现了RNN的变体长短期记忆模型(Long Short-Term Memory, LSTM), 以及实现双向上下文模型训练的BiLSTM。其另一变体——门控循环单元 (Gated Recurrent Unit,GRU),则是对LSTM的简化。在命名实体识别中,Chiu等[43]使用BiLSTM和CNN混合结构模型来自动检测字符级特征,减少了人工构造特征的需要。Lample 等[44]使用添加了CRF层的BiLSTM模型,对英语、荷兰语、德语和西班牙语语料进行命名实体识别,均取得较好的效果。王仁武等[45]提出面向中文实体识别的实体—属性抽取方法,使用GRU 与CRF 结合的模型提高识别能力。
2017 年 Vaswani 等[46]提 出Transformer 模型,摒完全依赖于self-attention机制,并凭借其高效性和易训练性在自然语言处理领域获得了巨大的成功。2018 年Google 提出了采用双向Transformer 结构的模型BERT(Bidirectional Encoder Representations from Transformers),在当年11 项NLP 任务中取得了令人瞩目的成绩,成为目前最好的突破性技术之一[47]。Kim等[48]训练了多语种BERT模型,并在韩语临床实体识别数据集上进行测试,证明BERT的识别结果显著优于字符级BiLSTM-CRF 模型。杨飘等[49]构建BERT-BiGRU-CRF模型,用于表征语句特征,实现了表征字的多义性,并在MSRA语料上取得了较高的F值。岳琪等[50]使用基于实体Mask 的BERT 词向量,构建BERT-BiLSTMCRF模型,进行中文林业领域的实体识别,发现使用BERT模型能更加充分地提取语义特征。
2 数据与方法
2.1 研究框架
作为中华优秀传统文化的重要载体,史籍文献一直占据着重要地位。如图1所示,本研究以“前四史”(《史记》《汉书》《后汉书》《三国志》)以及《左传》共5本史书为研究对象,基于深度学习模型识别其中的命名实体(包括人名、地名、时间词)。
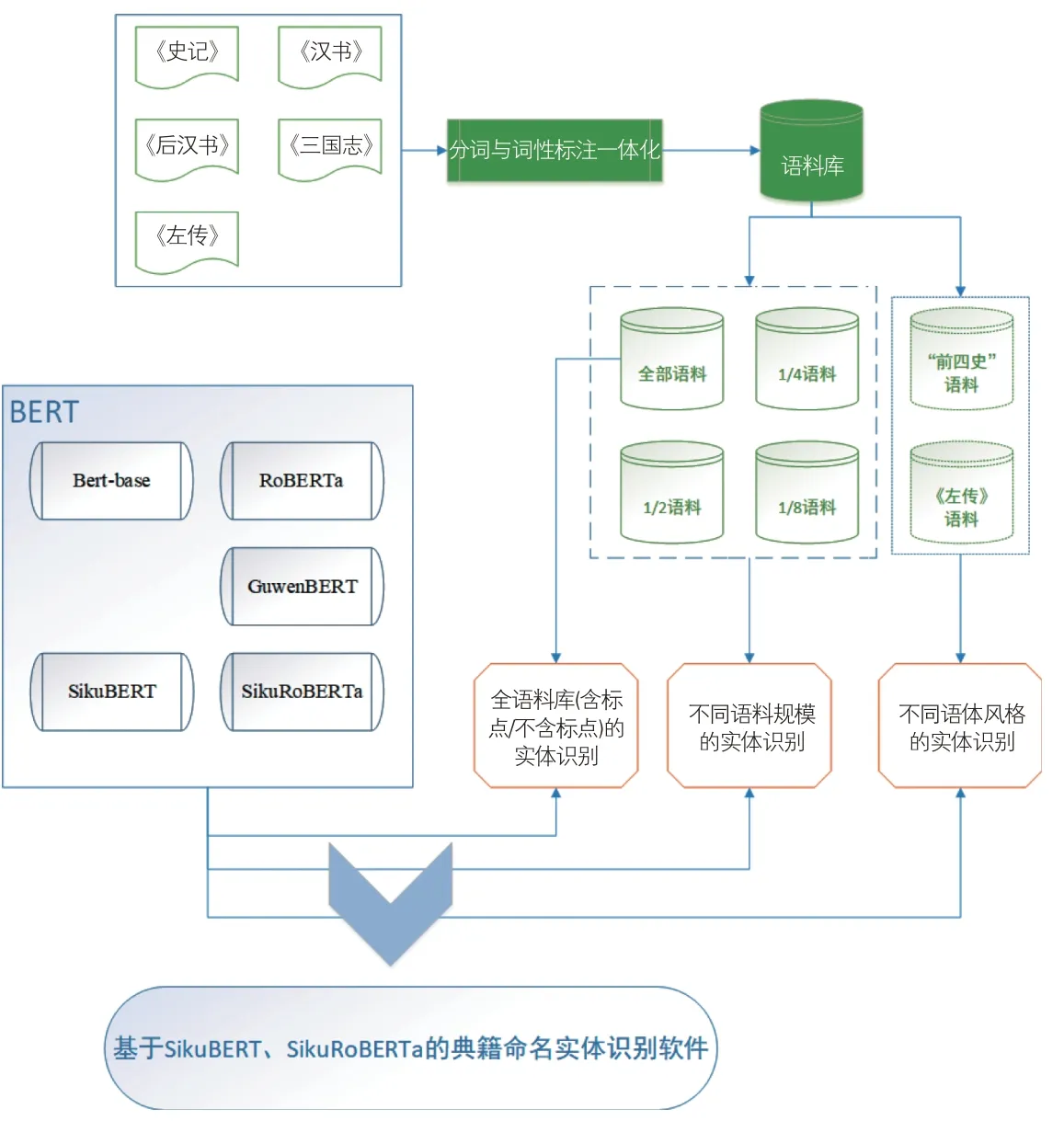
图1 研究框架
2.2 数据
(1)语料库简介。《左传》以比较原始的材料,相对全面地反映了春秋时期的政治、经济、文化等情况,是现存有关春秋时期历史社会的最珍贵史料。《史记》《汉书》《后汉书》《三国志》合称“前四史”,是对中国各民族进行系统记录与研究的重要史籍,其民族传记开创了统一多民族中国历史的叙事范式,最早揭示了各民族之间的矛盾、交流和交融,对于后世有着重要而深远的影响[51]。本研究所采用的训练语料是基于人工分词和词性标注并经过多轮校对的上述5种典籍文献,语料中包含标点符号。
(2)数据标注。本研究中,对典籍文献的标注采取分词与词性标注相结合的方式,使用“/”进行分词,使用人民日报标注语料库(PFR)的词性标记标签标准,其中所需的人名、地名、时间词标记如表1所示。标注示例:董仲舒/nr以為/v先/n是/r四國/n共/d伐/v魯/n,/w大/v破/v之/r於/p龍門/ns。/w
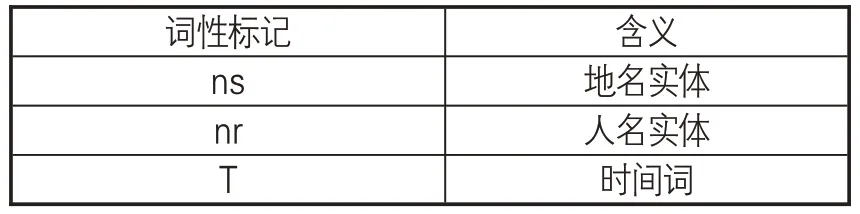
表1 命名实体词性标记对照
(3)语料库数据统计。表2展示各部典籍的句子数、字数、标点数、句长等,在统计字数、句长时没有计算语料中的标点。总体而言,相较于《左传》而言,“前四史”语料的句子数更多、平均句长更长、字数/标点数的比值更大。而《左传》语料较小,却拥有更多标点等特殊符号。
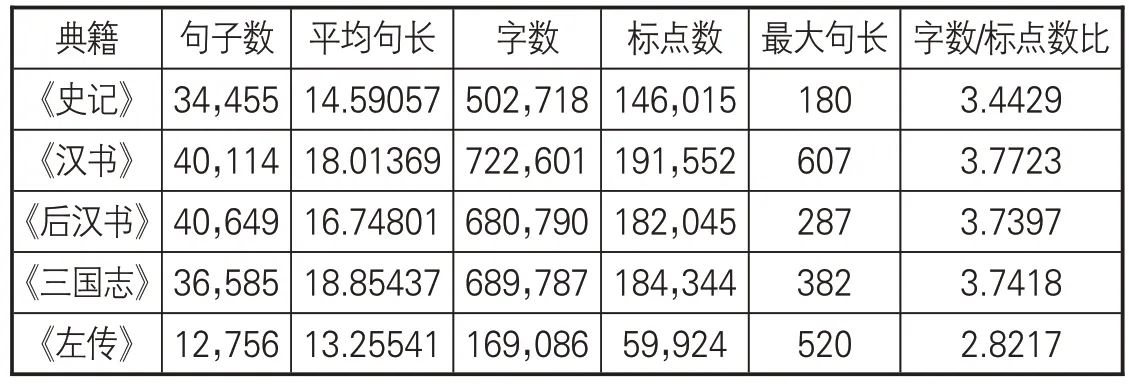
表2 典籍语料句子、字、标点统计数据
2.3 模型
BERT(Bidirectional Encoder Representation from Transformers)是一种双向语言表征模型,采用基于自注意力机制的Transformer 结构,最先由Google自然语言处理团队于2018年提出[52]。基于BERT的自然语言处理主要包含两个步骤:模型预训练(Pretraining)和微调(Fineturning)。BERT的预训练模型是基于大量语料进行自监督训练而形成的语言模型,在执行BERT具体任务时,可以选择对应的预训练模型,在此基础上进行微调即可。本文采用的预训练模型包括 BERT-base、RoBERTa、GuwenBERT、SikuBERT、SikuRoBERTa。各类预训练模型的基本情况见表3。其中,BERT-base①是Google提供的中文BERT预训练模型。RoBERTa②是更具鲁棒性的预训练模型,用动态掩码机制替代原BERT 预训练模型的静态掩码机制,去除效果不佳的下一句预测任务(Next Sentence Prediction,NSP),且采用更大的预训练语料库、Batch-Size(每次训练的样本数)和词表。Ro-BERTa 采用全词遮罩(Whole Word Masking,WWM)技术,将文本中的词作为mask对象,相较于BERT-base以字为粒度的切分方式,其识别效果更优。
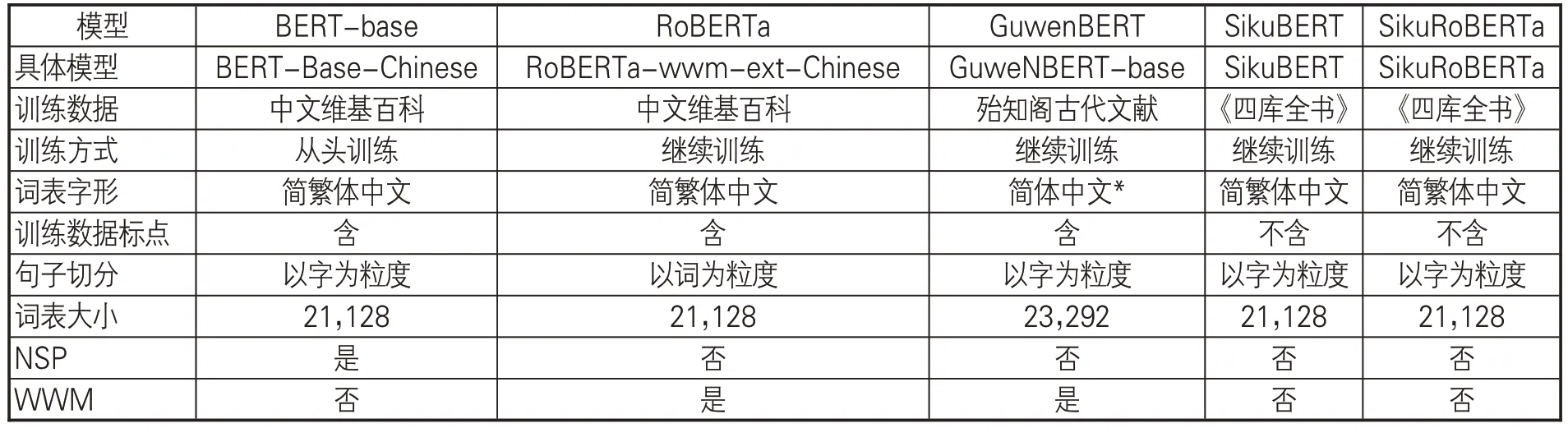
表3 5种BERT预训练模型简介
GuwenBERT③由北京理工大学提供,是基于殆知阁古汉语语料的古文预训练模型,使用RoBERTa相同的技术并结合现代汉语RoBERTa权重与无监督古文语料进行继续训练。SikuBERT和SikuRoBERTa④是南京农业大学、南京师范大学等提出的使用繁体《四库全书》语料分别在BERT-base和RoBERTa上进行预训练的古文预训练模型。与原始BERT 相比,SikuBERT、SikuRoBERTa 的预训练过程仅保留掩码语言模型(Masked Language Model,MLM)任务,去除对性能提升表现不佳的NSP任务。SikuRoBERTa在保留RoBERTa使用的全词遮罩(WWM)技术的基础上进一步从5 亿多字的《四库全书》语料上进行学习,一定程度上弥补了RoBERTa较少在繁体中文上训练的缺憾。
3 实验
3.1 实验设计
(1)数据的预处理。实验数据在前期手工分词与词性标注的基础上,进一步进行命名实体识别实验。此时,需要将语料转换为序列格式,因而对实体采用BIESO的单字标注方式:使用S标识单独由一个字组成的实体,使用B、I、E分别标识由多个字组成的实体的开头、中间、结尾字,使用O标识非实体字。标注示例见表4。
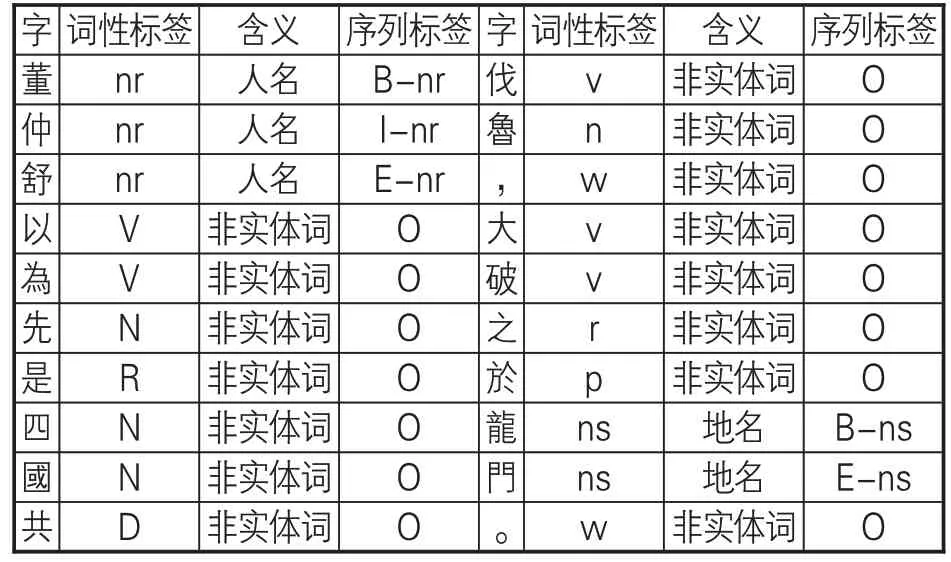
表4 序列数据的单字标注示例
(2)评价指标。为科学评价实验结果的有效性,采用准确率(Precision,P)、召回率(Recall,R)、调和平均值(F1-score,F1值)这3个指标作为评价模型性能的标准。评估中的混淆矩阵见表5,指标计算采用公式(1)-(3):
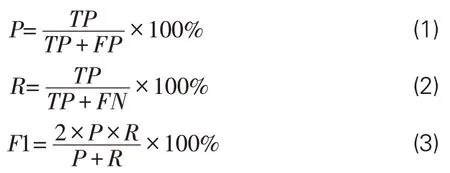
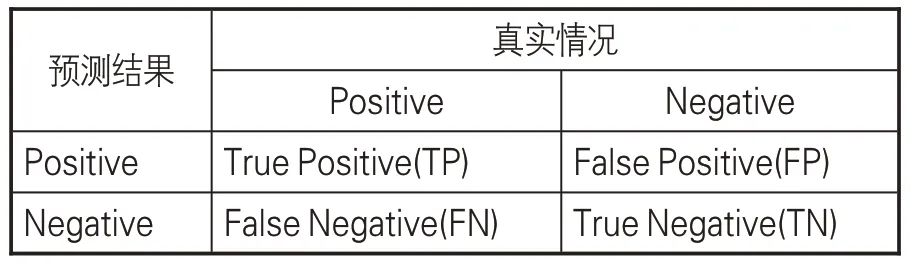
表5 混淆矩阵
(3)实验环境与模型参数设置。由于一般CPU无法满足神经网络模型在训练过程中所需的大量并行计算,因而本实验采用高性能的NVIDIA Tesla P40处理器来完成实验。计算机配置如下:操作系统为CentOS 3.10.0;CPU为48颗Intel(R)Xeon(R)CPU E5-2650 v4@ 2.20GHz;内存 256GB;GPU 为 6 块 NVIDIA Tesla P40;显存24GB。SikuBERT和SikuRoBERTa模型和用于对比的 BERT、RoBERTa 和 GuwenBert 均采用相同的结构进行预训练,即实验以统一的超参数进行实体识别任务,设置见表6。
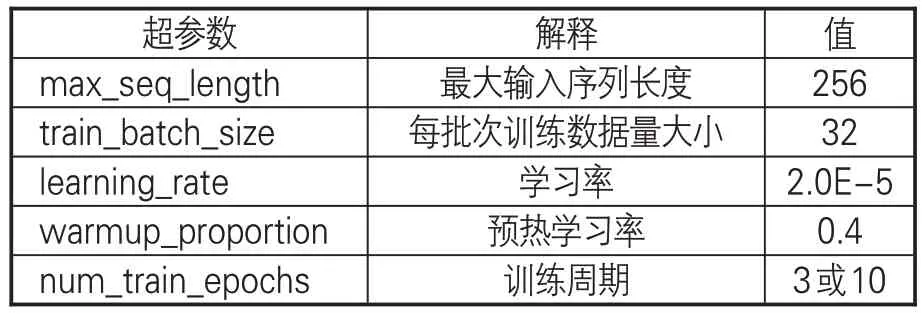
表6 实验主要超参数设置
3.2 实验结果
实验基于BERT模型对典籍文献中的人名、地名、时间名作识别。研究对数据集以整句为单位,按照9∶1划分训练集和验证集。
3.2.1 全语料库数据的实体识别
经过语料库处理与模型构建,基于全部语料(包括含标点、不含标点两种)训练得到各类BERT 预训练模型测试效果(如表7 所示)。从表7 可看出,在未进行任何人工操作情况下,有4 种BERT 预训练模型在含标点的全部语料上取得不错的效果,而GuwenBERT 由于其词表中不含繁体中文,训练效果略为逊色。在5 种预训练模型中,BERT-base 效果最优,训练三轮次调和平均值F1 就能达到89.74%,SikuBERT、SikuRoBERTa的F1值略低,分别为89.03%、88.74%。经过十轮训练后,SikuBERT和SikuRoBERTa的效果均有略微提升。在去除标点的全部语料上,SikuBERT效果最好,三轮次调和平均值F1 能够达到85.95%,其次是SikuRoBERTa,达到85.58%;十轮次后的训练效果也得到略微提升。全语料库数据实体识别效果的具体情况如下。
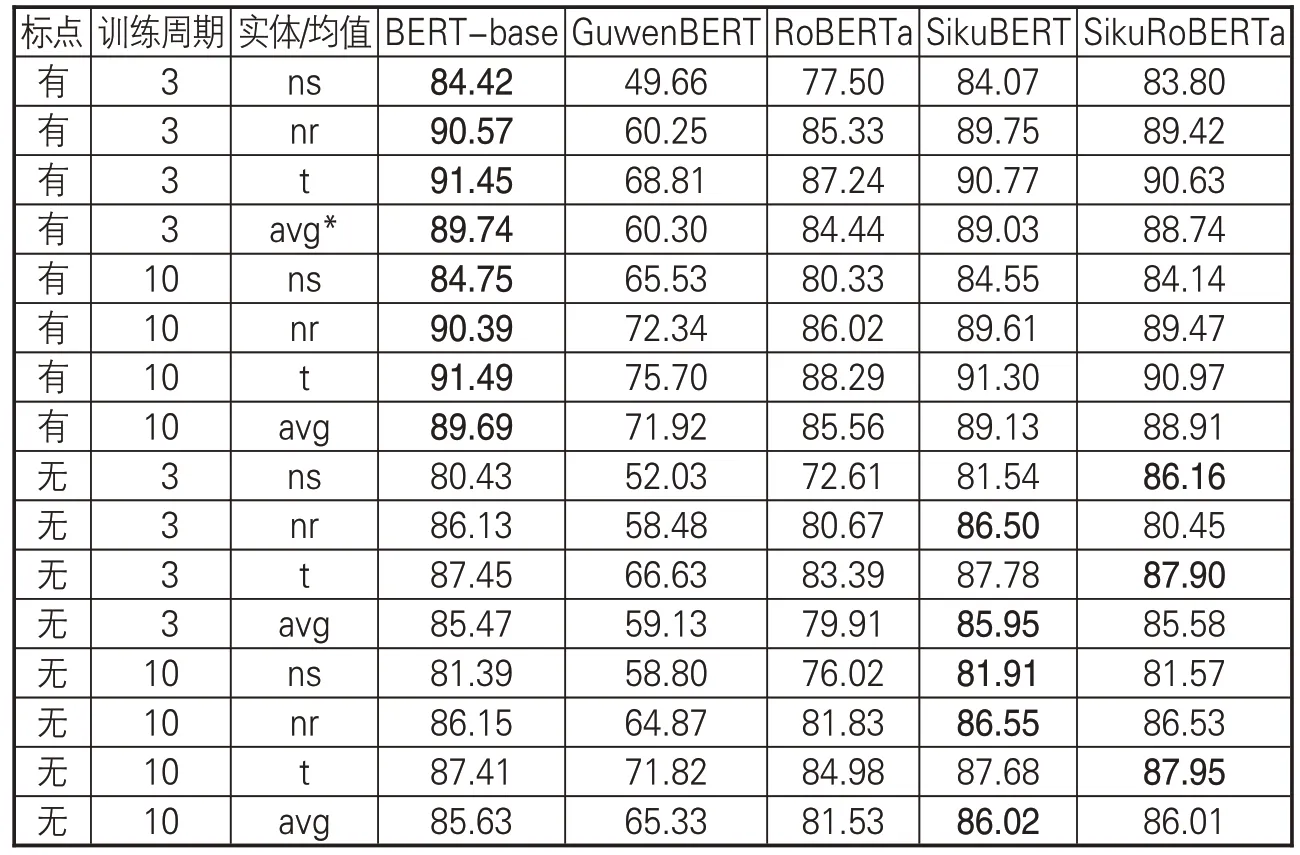
表7 全语料库数据实体识别效果(F1值)
(1)总体上,无标点语料在各预训练模型的测试效果均低于含标点语料的测试结果。这是由于标点符号在一定程度上反映了语言的句读,而较为规则的句读有助于深度学习模型习得语言特征。然而,传统意义上的古籍均不含标点,因此在无标点语料上的测试结果对于古籍研究者而言更为重要。
(2)在去除标点的语料上,SikuBERT、SikuRoBerta 的效果超过了BERT-base。这可能是由于这两个预训练模型是在大量繁体无标点的《四库全书》语料上进行训练。在语料来源、语体风格上,相较于有标点的中文繁体维基百科等知识库,无标点的繁体《四库全书》训练语料在结构及语言上可能与上古典籍文献更为相似,因而效果略优。
(3)RoBERTa预训练模型的效果低于BERT-base。这可能是由于RoBERTa 在BERT-base基础上进行继续训练时,采用大量简体语料,使模型中繁体字的权重下降。而SikuRoBERTa是在RoBERTa 基础上,采用大量繁体《四库全书》语料继续进行预训练的模型,因而其整体效果有所提升。
3.2.2 不同语料规模数据的实体识别
对于深度学习模型而言,大量的文本数据可以帮助其掌握更多的上下文文本特征,用于实体识别,从而有效降低学习过程中过拟合情况的发生。为研究不同语料规模对模型效果的影响,探究在小样本数据上模型的实验性能,本研究开展对比试验。结果表明,相较于其他几种典籍,《史记》的实体识别效果最好,因而本节仅以《史记》为语料进行实验。本节将语料库规模划分为全部和1/2、1/4、1/8,实验结果的调和平均值F1如表8所示。
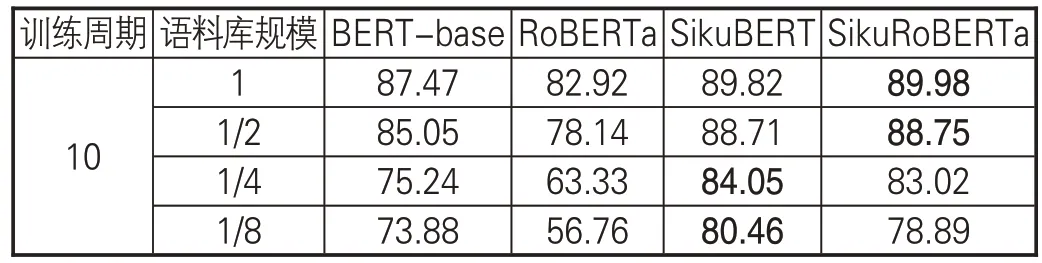
表8 不同语料规模的《史记》命名实体识别效果(F1值)
上述实验结果显示,语料库的规模对于模型的效果有较大影响。(1)随着语料库规模的不断减小,RoBERTa 预训练模型的微调效果急剧下降,而 SikuBERT、SikuRoBERTa 的 F1 值下降幅度较小。虽然RoBERTa采用WWM全词遮罩技术,能更好地学习文本的语体风格等,但从百科知识、社区平台上获取的具有现代风格的语言知识在小规模繁体古籍的命名实体识别中劣势明显。(2)SikuRoBERTa模型的效果在语料规模较小时或epoch 训练轮次较小时,往往效果不如SikuBERT,但随着语料规模的扩大与训练轮次的增加,其效果逐步提升并能在某些实体类型或语料的识别上接近或超过SikuBERT。SikuRoBERTa 是基于RoBERTa 继续训练而获得的预训练模型,这表明在大规模语料上RoBERTa采用的WWM全词遮罩技术具有先进性。(3)从1/8 语料到1/4 语料再到1/2 语料时,BERT模型的性能提高得很快;而从1/2语料到全部语料,模型效果的提升并不明显。这说明BERT模型在大规模文本上的性能更为稳定,大规模数据集更适合BERT模型。
本节进一步论证了SikuBERT、SikuRoBERTa预训练模型在典籍命名实体识别,尤其是小规模语料上的优势。
3.2.3 不同语体风格数据的实体识别
“前四史”陆续成书于汉以后,《左传》则成书于战国中前期,在语体风格上具有一定差异。为探究不同语体风格对模型实验的影响,本节分别在“前四史”、《左传》(均去除了标点等特殊字符)上进行实验,实验结果(调和平均值/F1值)如表9所示。
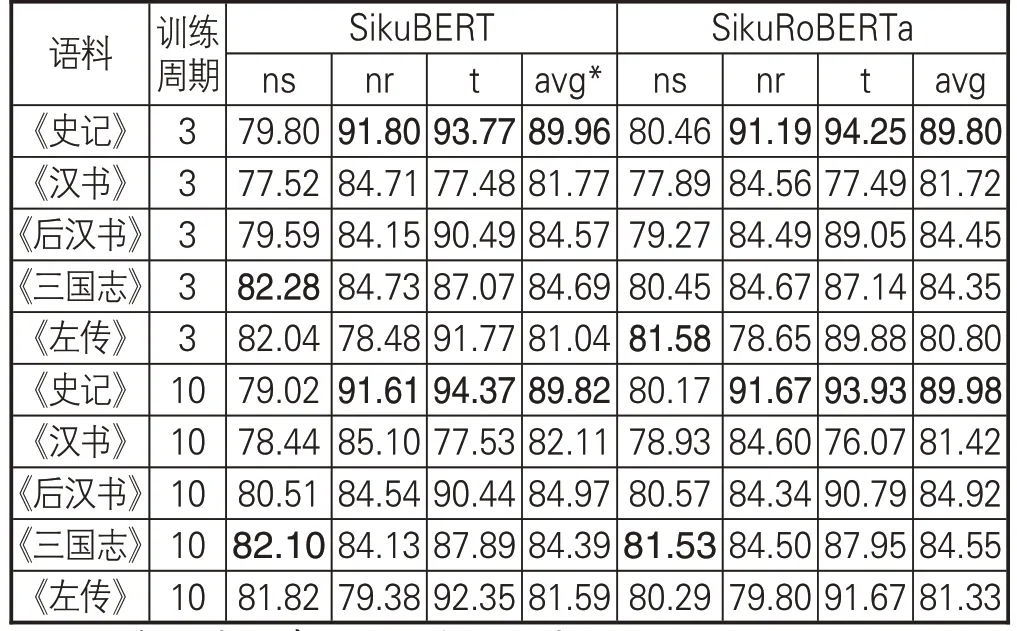
表9 不同语体风格的单一典籍命名实体识别效果(F1值)
根据本节实验数据,可以发现语体风格对实验结果存在一定影响。模型在字数最多的《汉书》和字数最少的《左传》上,识别效果最差。而上节对不同规模数据的对照试验表明,当语料达到一定大小时,模型的识别效果将变得相对稳定,语料规模的进一步扩大对实体识别性能的提升并无较大帮助。在本节中,《汉书》《后汉书》《三国志》的语料规模均大于《史记》,但三者的实体识别效果均低于《史记》。其中,模型在《汉书》上的识别效果最差,较《史记》约低8个百分点,《后汉书》《三国志》则约低5 个百分点。出现上述差异的影响因素包括:一是语料标注的规范性程度。规范不统一的标注、错误标注、漏标注等因素,都会造成模型识别性能的弱化。本实验语料经过多轮人工校对,最大程度降低了错漏标注的可能。二是各典籍在语体风格、时代文化背景上存在较大差异。《左传》成书于战国中期,《史记》成书于西汉前期,《汉书》成书于东汉时期,《后汉书》成书于南朝宋,而《三国志》成书于西晋时期。这些历史时期相距较为遥远,文学的风格也各有不同,与模型预训练语料的语体风格相似度有所差异,因而可能会对模型识别造成影响。
4 基于SikuBERT的命名实体识别软件构建
依据前述研究,本实验构建了一个基于SikuBERT、SikuRoBERTa的命名实体识别应用系统,集成了分词、词性标注、断句、实体抽取、自动标点等常见古籍智能信息处理功能。该系统旨在帮助古籍研究学者更好地快速了解典籍,以推动研究的深化。通过使用PyQt工具包,结合Mysql数据库存储方式和其他开发技术,完成基于Siku 系列BERT预训练模型的“SIKU-BERT典籍智能处理系统”的构建。该系统具有两种语料输入模式:单文本模式和语料库模式,见图2。单文本模式可以即时输入和处理文本,语料库模式能对多个语料文件进行识别。SIKUBERT典籍智能处理系统可以识别人名、地名和时间词3类经典实体,能更好地帮助使用者掌握事件发展脉络,进行特定类别事件的筛选,挖掘文本特征和规律,提高研究效率,并对后续古籍资源的利用提供帮助。

图2 SIKU-BERT典籍智能处理系统首页
图6 语料库模式实体识别
点击相应模式进入主功能页面。单文本模式见图3,在左侧“原始文本”栏输入待处理语料,系统在右侧“处理结果”栏输出结果;语料库模式见图4,单击右侧“浏览”按钮,指定语料输入路径和结果输出路径,下方“信息提示”栏中会显示输入语料的详情。该系统将自动分类、自动分词、实体识别、词性标注和自动断句等功能集中罗列在主(功能)页面的下方,方便操作。

图3 单文本模式主功能页面
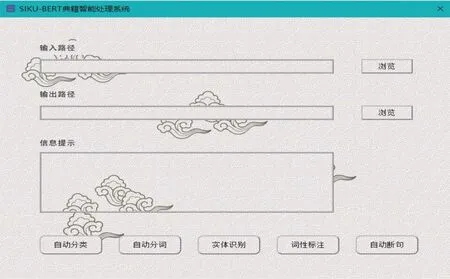
图4 语料库模式主功能页面
单击“实体识别”功能按钮,系统自动调用模型对语料进行实体识别,并输出结果。单文本模式直接在右侧显示处理结果,而语料库模式则在“信息提示”栏显示处理进度,任务完成后,将结果写入txt文档存储在输出路径中(见图5-6)。

图5 单文本模式实体识别
在实体识别功能中,该系统使用SikuBERT和SikuRoBERTa 模型对输入语料进行实体识别,并返回带“<>”标签的结果(见图7)。比如,输入序列:“二年冬十月,省徹侯之國。”输出序列:“,省之國。”

图7 语料库模式实体识别效果
SIKU- BERT 典籍智能处理系统基于SikuBERT、SikuRoBERTa模型,能较为精准地实现古籍语料的命名实体识别任务,并且集成了自动分类等其他处理功能,界面简洁、操作简便、直观易用,能更好地为学者提供帮助。
5 结语
基于自然处理技术的古代典籍命名实体识别对进一步分析挖掘和利用典籍文献具有重要意义。本文基于SikuBERT 和SikuRoBERTa 构建典籍命名实体识别模型,模型在“前四史”、《左传》等5种史籍中的表现,较文中其他3类基线模型更优。研究论证了深度学习模型应用于大规模古籍文本实体识别的可行性,探究不同预训练模型、语料规模、语体风格对于典籍文献实体识别的影响,进一步论证了BERT 引领的“预训练-微调”深度学习新模式的优越性,为探究及构建更适合特定领域语料的预训练模型提供参考。
下一步的研究将从以下方面开展:(1)以《四库全书》为基准构建词表,从头开始训练预训练模型而非基于BERT-base或RoBERTA 进行训练;(2)基于已有典籍知识图谱构建BERT模型,以提高模型在专业性典籍自然语言处理任务中的泛化能力;(3)使用近期各研究机构提出的一系列能将外部知识融于预训练语言模型的改进模型框架,基于《汉语大词典》构建典籍词表,并融入Siku系列预训练模型,以提升现有识别效果。
注释
①参见:https://github.com/google-research/bert.
②参见:https://github.com/ymcui/Chinese-BERT-wwm.
③参见:https://github.com/Ethan-yt/guwenbert.
④参见:https://github.com/SIKU-BERT/SikuBERT.
