基于CBAM和BiFPN改进YoloV5的渔船目标检测
2022-07-07张德春李海涛
张德春,李海涛,李 勋,张 雷
(1 青岛科技大学信息科学技术学院,山东青岛 266000;2 青岛西海岸新区海洋发展局,山东青岛 266200;3 青岛励图高科信息技术有限公司,山东青岛 266200)
渔船是确保渔业活动顺利进行的基础,但由于渔船因素的问题,如捕捞渔船数量的急剧增加、不合理的捕捞方式等[1],已严重影响到渔业资源的可持续发展[2]。渔船的海上生产是开放式的,管理人员力量不足且手段落后,无法对渔船动态进行实时掌控,更不能及时发现并消除伏季休渔期私自出海捕捞这种违规行为,对这些安全隐患存在监管盲区[3]。
基于深度学习的目标检测在近20年得到了飞速发展,主流的目标检测算法根据有无候选框生成阶段分为双阶段和单阶段目标检测算法两类。双阶段目标检测算法先对图像提取候选框,然后基于候选区域做二次修正得到检测结果[4],代表算法有R-CNN系列[5-7]、AlexNet[8];单阶段目标检测算法直接对图像进行计算生成检测结果,代表算法有SSD[9]和Yolo系列[10-14],其中Yolo检测框架在保证检测准确率的情况下同时满足实时检测的需求。船舶检测是目标检测应用领域的一种。Blosisid等[15]在大运河交通监控系统中,对航道中的船舶进行检测和跟踪。Kim等[16]利用Faster R-CNN网络和贝叶斯进行船舶检测和分类。戚超等[17]将一个8层卷积神经网络和支持向量机结合起来,提取卷积神经网络第一个全连接层的特征,训练支持向量机对运输船进行分类识别。闫河等[18]提出一种卷积神经网络(CNN)与极限学习机(ELM)相结合的分类识别方法。李兆桐等[19]提出一种基于全卷积神经网络的船舶检测算法SDNet进行船舶检测。宋娟娟等[20]提出基于深度学习的监控视频中船舶识别方法,降低了识别的错误率。
本研究以进出渔港的渔船为检测目标,采集1 900多张渔港高点监控图片,构建渔船检测数据集。基于YoloV5检测网络,首先通过Kmeans++算法对锚框重新聚类[21],选择适合渔船数据集的锚框尺寸;然后在YoloV5的骨干网络中融入CBAM注意力机制获取更多细节特征;再采用BiFPN加权双向特征金字塔网络代替原先的FPN+PAN结构,快速进行多尺度特征融合;最后在检测尺度上去掉大目标的检测尺度,增加更小目标的检测尺度,改用新的三个检测尺度,提高了模型对小目标渔船的检测精度。
1 YoloV5算法原理
YoloV5具有速度快、灵活性高的特点[12],由输入端、Backbone、Neck和Head四个部分组成。输入端的作用是对输入的数据集进行预先处理,包括Mosaic数据增强、自适应锚框计算等操作。Backbone使用CSPDarknet53网络,从输入图像中提取丰富的信息特征。Neck中的核心为特征金字塔(FPN)[22]和路径聚合网络(PAN)结构,实现不同尺度特征信息的融合。Head是YoloV5的检测结构,输出大、中、小三个不同尺寸的特征图,分别对应的是检测小、中、大目标。其中Backbone是YoloV5的骨干结构,包括Foucs、Conv、C3、SPP等模块。Focus模块将输入在纵向和横向间隔切片再拼接,Conv包含卷积、正则化和激活层,C3包含N个残差网络Bottleneck,输入的特征图先是经过1×1和3×3的卷积层,再将结果与输入的特征进行相加。SPP为空间金字塔池化层,SPP是进行三种尺寸的最大池化操作,并将输出结果进行拼接。
2 改进YoloV5渔船检测算法
2.1 改进YoloV5算法概述
为了在高点监控渔船目标场景中解决漏检和误检的问题,提出了一种基于改进YoloV5的渔船目标检测模型,模型网络结构如图1所示,本研究的主要改进为:锚框尺寸的确定由Kmeans算法改为Kmeans++算法;在骨干网络中添加CBAM机制加强特征提取;在Neck中由PANet网络结构改为BiFPN加强多尺度特征融合;将用于检测小目标的大尺度特征图取代原本算法中的检测大目标的小尺度特征图,提高对小目标的检测精度。
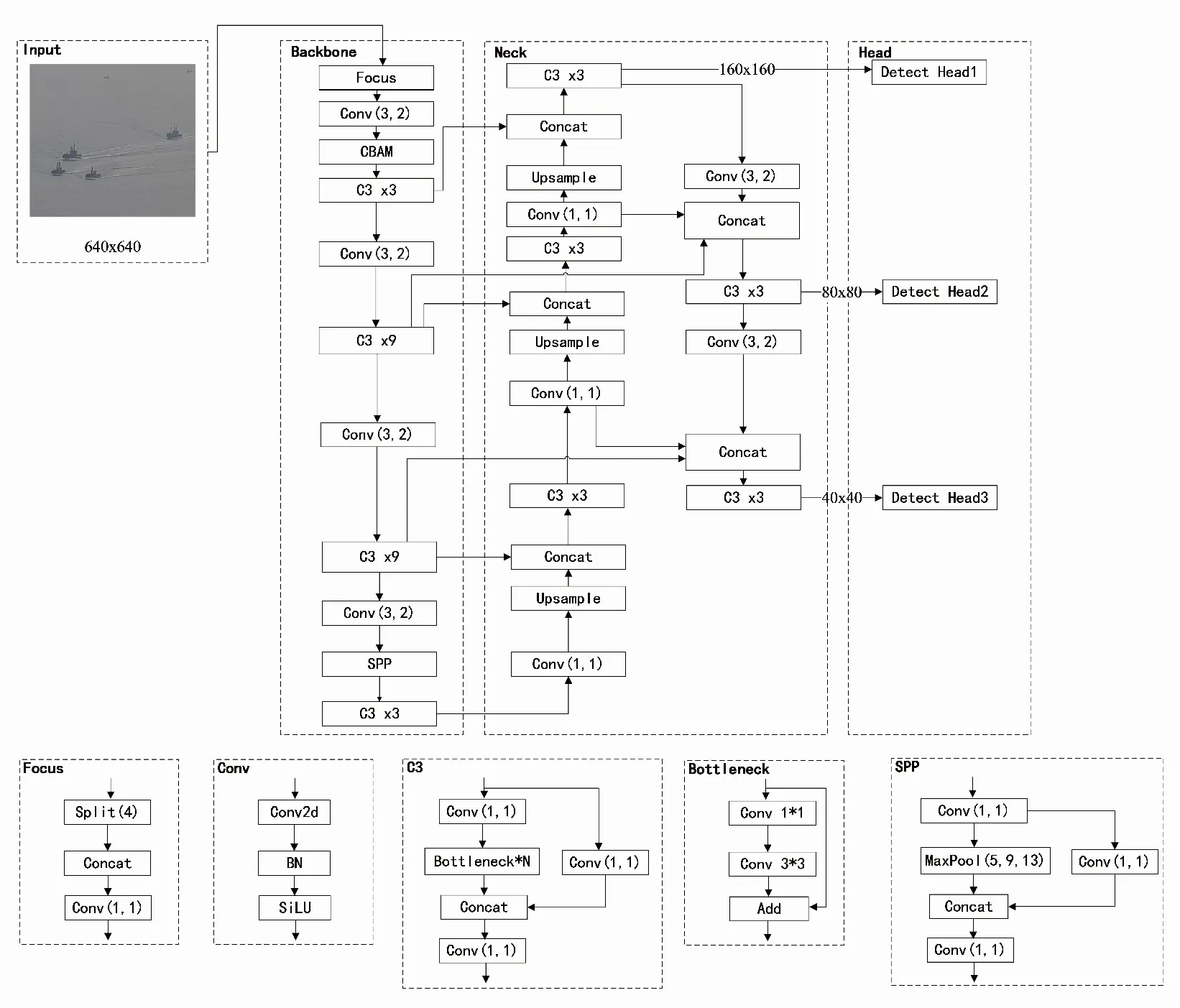
图1 改进YoloV5网络结构Fig.1 Network structure of imporved YoloV5 algorithm
2.2 骨干网络改进
在YoloV5的骨干网络中引入CBAM注意力机制[23],CBAM的通道注意力机制重点检测目标的内容,空间注意力机制重点检测目标的位置,通过两者结合可以使输出信息更聚焦于重点特征信息,抑制一般特征的干扰,从而达到提高模型准确率的目的。本研究将CBAM模块融入第一个卷积后,并在CBAM模块中先将特征输入到通道注意力模块再输入到空间注意力模块,得到最终生成的特征,如图2所示。改进后的骨干网络结构如图3所示。

图2 CBAM注意力模块结构Fig.2 Structure of CBAM
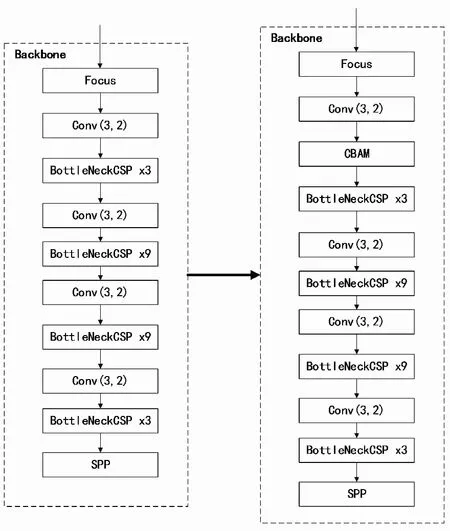
图3 融合CBAM模块的YoloV5结构Fig.3 YoloV5 incorporating CBAM Modules
2.3 特征金字塔改进
BiFPN是加权双向特征金字塔[24],BiFPN主要思想有两点:一是高效的双向跨尺度连接,二是加权特征图融合。运用双向融合四项,构造自上而下、自下而上的双向通道,对来自主干网络不同尺度的信息,在不同尺度间进行融合时通过上采样和下采样同一特征分辨率尺度,并在同一特征的原始输入和输出节点之间添加横向连接,在不增加成本的情况下融合更多特征,另外将BiFPN视作一个基本单元,即BiFPN中一对路径视为一个特征层,然后重复多次以得到更多高层特征融合,网络结构如图4所示。
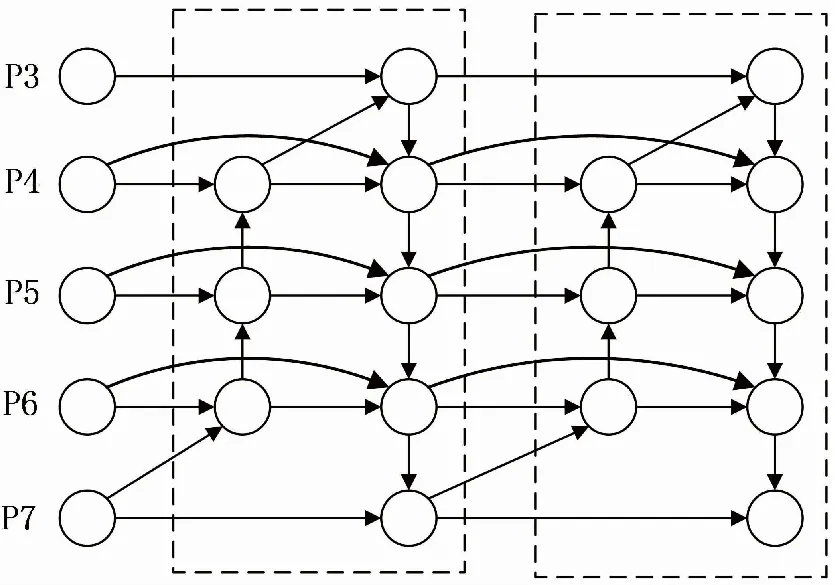
图4 BiFPN结构Fig.4 Structure of BiFPN
2.4 锚框优化
YoloV5的先验锚框参数是基于COCO数据集进行Kmeans聚类算法进行设定,不满足渔船检测的实际需要,所以要重新设计先验锚框的大小,本研究改用Kmeans++聚类算法对先验锚框大小重新设计,与传统的Kmeans聚类算法[25]相比,Kmeans++优化了初始聚类的中心选取的方式,能显著改善分类结果的误差以获得更好的聚类效果,获得更适合小目标数据集的锚框尺度,提高小目标检测的精度。本研究中针对大、中、小尺度分别取3个锚框,共9组锚框数据,因此聚类簇数k取9,再进行了2 000次迭代之后,得到新的先验锚框尺度,经过归一化后如表1所示。
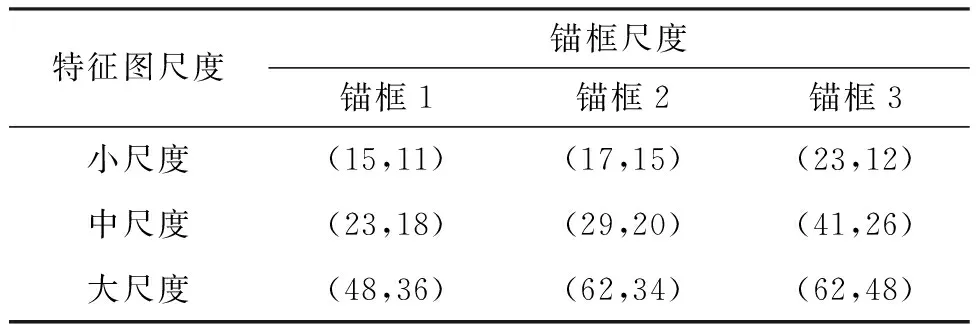
表1 先验锚框尺度Tab.1 A priori anchor frame size
锚框尺度计算的算法如下所示:

算法:锚框尺度优化。

输入:训练集的标签 (标签结构:宽、高、类别)。
输出:锚框的宽、高数据。
1)对人工标注的标签文件进行解析,得到训练集包含的所有锚框的宽、高,写入数组N。
2)开始遍历所有的训练集样本N。
3)读取样本的锚框对应的图像,得到图像的宽、高。
4)将图像的宽、高写入数组M。
5)结束遍历。
6)//Kmeans++算法参数依次是所有样本的宽高数组M、聚类类别数9、迭代次数2 000次。
7)Kmeans++(M,9,2000)。
8)Return 9组锚框的宽、高。
算法:Kmeans++。
输入:所有样本的宽高数组M,聚类类别数9、迭代次数2 000次。
输出:锚框的宽、高数据。
1)从输入的数据集中随机选取一个样本作为初始聚类中心ci。
2)首先计算每个样本与当前已有聚类中心之间的最短距离,用D(c)表示[26]。
4)重复第2、3步骤直到选出9个聚类中心。
5)针对数据集中每个样本ci,计算它到9个聚类中心的距离并将其分到距离最小的聚类中心所对应的类中[27],并更新聚类中心。
6)重复第5步,直到锚框的大小不再发生改变或迭代2 000次。
7)Return 9组锚框的宽、高。
2.5 检测尺度改进
将检测尺度进行调整,YoloV5的检测尺度是取20×20、40×40、80×80特征层作为检测Head,Head是YoloV5的检测结构,输出大、中、小三个不同尺寸的特征图,分别对应的是检测小、中、大目标。如图5所示,本研究对检测Head做了调整,在80×80特征层之后继续增加卷积层和上采样,再将上采样特征层与160×160特征层进行融合,得到160×160特征图,作为检测Head1[28]。在检测时,去掉20×20特征图,取80×80特征图作为Head2,取40×40特征图作为Head3,继续保持3个检测尺度的Head结构,如图5所示,原算法的结构如图5a所示,改进后算法的结构如图5b所示。

图5 改进的检测尺度结构与原检测尺度结构Fig.5 Structure of imporved detect head and default detect head
2.6 试验平台
试验是在Linux操作系统下,基于GPU、Pytorch和CUDA框架完成的,参数具体见表2。

表2 试验平台参数Tab.2 Test platform related configuration
3 结果与分析
3.1 试验数据集
数据集采用在渔港建设的高点监控摄像头拍摄的数据,因本研究的主要目标是渔船,但数据采集过程中发现,还有部分舢板和执法船等其他船只进出渔港,所以将目标分为3类:渔船、舢板和其他船只。共采集照片数量1 965张,如图6、7所示,按照8∶1∶1的比例,分别是训练集、验证集和测试集。训练集照片1 572张,标记对象2 200多个,如图6a所示,表示标记对象的数量;图6b表示标注框的可视化,因为标注数据是经过归一化处理的,将所有标注框中心点设置为(0.5,0.5),取前1 000个框进行可视化表达;图6c表示标注框中心点坐标(x,y)的分布情况;图6d表示经过归一化过的标签高度和宽度分布图。

图6 数据集类别实例(船舶类别)Fig.6 Dataset class instances(Ship category)

图7 数据集的样例图片Fig.7 Sample image from dataset
3.2 评价指标
本研究主要采用精确度(Precision,P)、召回率(Recall,R)、平均精确度(Averge Precision,AP)、平均精度均值(mean Averge Precision,mAP)和每秒检测帧数(FPS)作为模型评价指标。
将测试结果按表3混淆矩阵划分为真阳性(True Positive,TP)、真阴性(True Negative,TN)、假阳性(False Positive,FP)、假阴性(False Negative,FN)[29]。
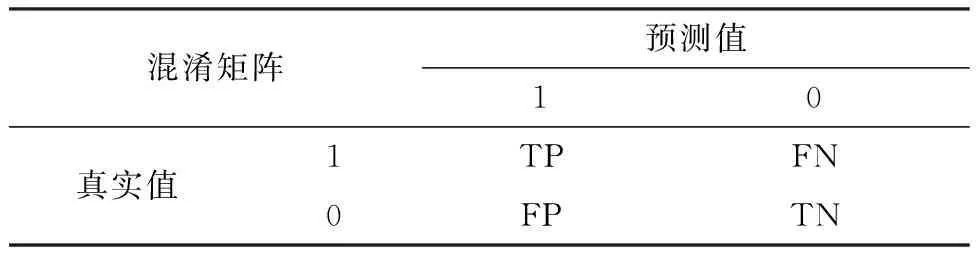
表3 混淆矩阵Tab.3 Confusion Matrix
召回率的计算如公式(1)所示,精确度的计算如公式(2)所示。
(1)
(2)
式中:Tp代表正确识别到渔船的数量,FN代表把渔船识别成非渔船的数量,R代表渔船目标检测的召回率,Fp代表把非渔船识别成渔船的数量,P代表渔船目标检测的精确度。
平均精确度的计算公式如(3)所示。mAP是对平均精确度(AP)在所有类别下取均值,计算公式如(4)所示。

(3)
(4)
式中:XAP代表平均精确度,XAPi代表第i类目标检测的平均精确度,K代表标记的类别,mAP代表平均精确度的均值。
mAP@0.5定义为在交并比(IOU)阈值为0.5的情况下,对每一类分别计算XAP,然后取均值,计算如公式(5)所示:
(5)
式中:XAP@0.5i代表交并比阈值为0.5的情况下,第i类目标的平均精确度,K代表标记的类别,mAP@0.5代表交并比阈值为0.5时平均精确度的均值。
mAP@[0.5:0.95]定义为在不同交并比阈值(从0.5以0.05的步长增至0.95)上mAP的均值[22],计算如公式(6)所示:
mAP@[0.5:0.95]=
(6)
式中:mAP@0.5代表交并比为0.5时平均精确度的均值,mAP@0.55表交并比为0.55时平均精确度的均值,以此类推。mAP@[0.5:0.95]代表在不同交并比阈值(从0.5以0.05的步长增至0.95)上mAP的均值。
每秒传输帧数(Frames Per Second,FPS)是指画面每秒传输帧数,本研究选择FPS作为检测速率的评价指标。
3.3 网络训练
在改进后的模型训练中,将迭代次数设置为100次,批训练数据量为64,初始学习率设置为0.01,权重衰减系数为0.000 5,训练动量为0.8,优化器(optimizer)选用Adam,Adam可以自动调整学习率,在梯度稀疏或梯度存在很大噪声的情况下表现较好。训练损失变化如图8所示。
图8 改进后网络模型收敛情况Fig.8 Convergence of improved network model
3.4 改进后模型的性能分析
改进后模型的精度-回归曲线(Precision-Recall,P-R)如图9所示。改进后的模型性能如表4所示,改进后算法对所有类别的检测精准率、召回率、mAP@0.5和mAP@[0.5:0.95]分别达到98.1%、97.8%、98.6%、75.4%,并且在渔船的识别精度上mAP@0.5的值是98.7%。

表4 改进后模型的性能Tab.4 Performance comparison and analysis of improved models
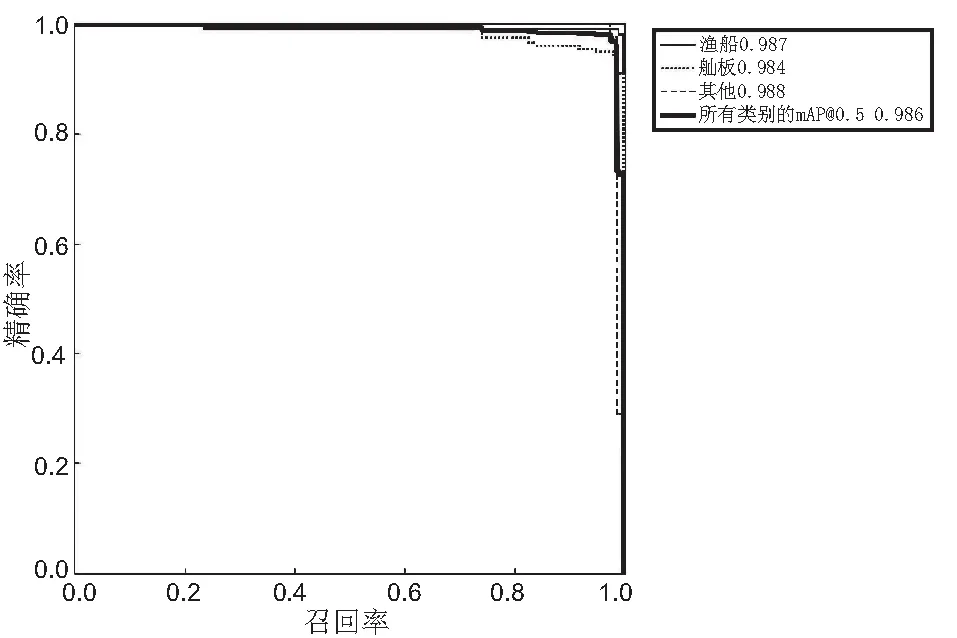
图9 精度-回归曲线图Fig.9 PR-curve
试验结果证明,改进算法对渔船的识别取得了较高的识别精度。
3.5 消融试验
为了更好地验证改进算法对原算法优化的有效性,进行了消融试验,共验证5组网络,使用同样的渔船数据集,试验结果如表5所示,加粗字体为算法最优值。
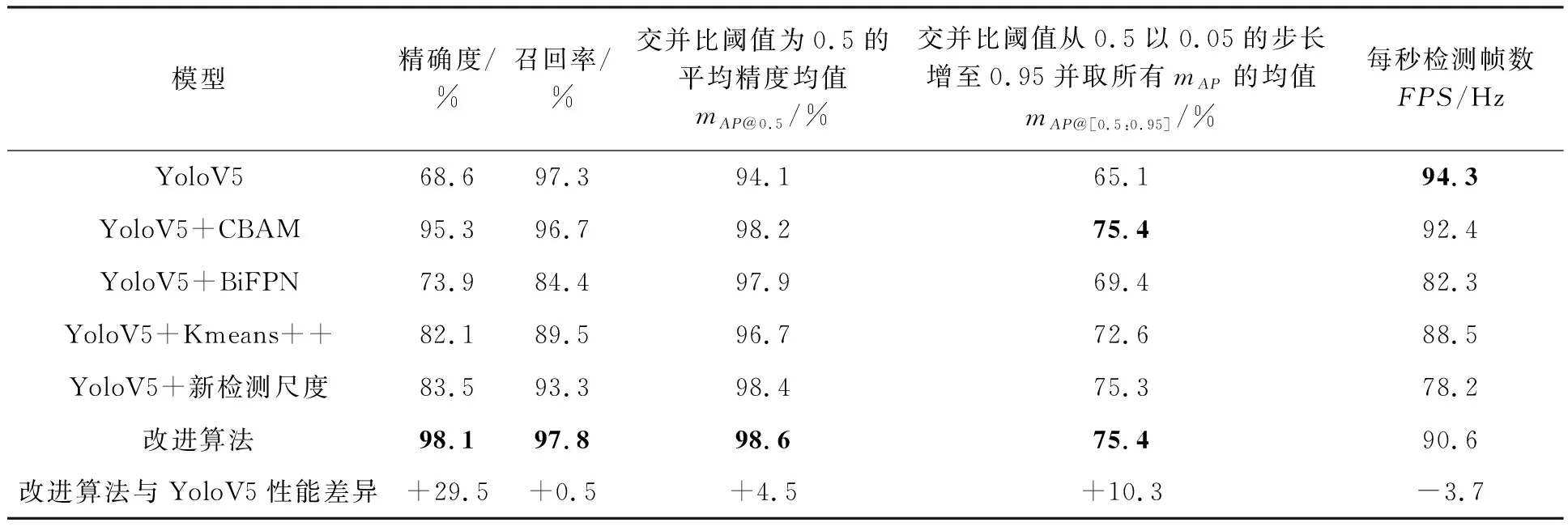
表5 消融试验Tab.5 Ablation experiments
由表5数据可知,在YoloV5骨干网络中融合CBAM模块比YoloV5的mAP@0.5值提高了4.1%,检测速度FPS降低了1.9;将YoloV5的PANet替换为加权双向特征金字塔BiFPN,mAP@0.5值提高了3.8%,FPS降低了10;在模型预测时,改用3个新的检测尺度,去掉大目标的检测尺度,增加更小目标的检测尺度提升模型检测精度,mAP@0.5值提高4.3%,FPS降低了16.1。试验结果表明,改进算法的每个措施在性能方面均有所提升,与YoloV5相比,mAP@0.5值提高4.5%,精确度、召回率和mAP@[0.5:0.95],分别提升29.5%、0.5%、10.3%,虽然检测效率FPS降低了3.7,但FPS大于90,对视觉影响不大,而且检测精度得到较大的提高,基本满足高点监控渔船目标场景下的检测要求。
为了更加直观地看出改进算法和原算法之间的区别,随机选取渔船图片作为验证集,分别对原算法和改进后的算法进行验证,部分检测结果如图10所示,其中“fishBoat”代表渔船、“sampan”代表舢板、“o”代表其他船只。在Image1的检测上可以发现本研究改进算法在识别精度上有所提升;在Image2的检测上原YoloV5算法在其他船只的识别上有错误,将其他船只识别为舢板,而改进后的算法检测正确且检测置信度也提高了;在Image3的检测上,原YoloV5算法漏检了远处小尺寸的舢板,改进的算法将其识别了出来。通过以上多种检测结果比较可知,改进后的YoloV5算法在小目标的渔船、舢板的检测效果较好。

图10 检测结果Fig.10 Detection results
3.6 对比讨论
对比检测口罩佩戴[30-31],本研究的检测环境更加复杂、难度更大,尤其是遇到在大雾、水面反光等情况时,检测难度增加;对比检测安全帽佩戴,基于改进YoloV4的算法平均精度是91.17%[32],基于改进YoloV3算法的精确度是96.5%[33],本研究的基于改进YoloV5算法精确度高达98.6%,同样在背景环境复杂、光线因素影响的情况下,本研究在渔船目标的检测平均识别准确度上略高于安全帽的佩戴检测准确度;对比同样基于监控视频进行船舶目标的检测,基于回归深度卷积网络的船舶检测[34],在视频检测中每秒钟检测的帧数为78~80,本研究的基于改进YoloV5算法每秒钟平均检测帧数为90.6,在检测速度上更有优势。但本研究也有不足之处,比如缺乏在强逆光和海浪影响的环境下[35]渔船目标检测的研究和分析,下一步要扩充不同天气环境下的数据集,研究分析恶劣的海况下渔船目标检测性能,提高模型的鲁棒性,使之适用更复杂多变的海况。
4 结论
改进YoloV5算法首先通过Kmeans++算法对锚框重新聚类,选择适合渔船数据集的锚框尺寸;然后在YoloV5的骨干网络中融入CBAM注意力机制获取更多细节特征;再采用BiFPN加权双向特征金字塔网络,快速进行多尺度特征融合;最后在检测尺度上的改变,提高了模型对小目标渔船的检测精度。研究表明,在渔船检测效果上,改进算法平均精度均值能达到98.6%,平均检测时间为0.011s,能够获得较好的检测准确度和比较快的检测速度,基本满足休渔期管控期间渔船检测的准确性和实时性的需求。未来将继续探索在恶劣天气时模型的泛化能力,提高模型的鲁棒性。
□
