基于LSTM和IGA-BP的酒精度预测模型
2022-06-02张建华商建伟李克祥李祥利
张建华 商建伟 王 唱 赵 岩 李克祥 李祥利
(河北工业大学机械工程学院,天津 300401)
白酒是中国特有的传统酒种之一,仍保留着传统手工酿造工艺,摘酒是蒸馏过程中一道极为重要的工序[1-2]。分段摘酒是按照不同的酒精度区间将流酒过程中原酒划分为不同的阶段,进行分段存储。酿酒行业常用的摘酒方式为看花摘酒,摘酒工人通过流酒过程酒花的变化判断当前酒精度值,进行分段摘酒,完全依赖摘酒工的个人经验。
目前常用的酒精度检测方法有密度计法[3-4]、分析仪器法[5-8]和传感器法[9]等。Lachenmeier等[3]利用振荡式密度计法实现白酒酒精度检测,对低浓度酒检测精度较高。酒精度分析仪器包括近红外光谱仪[5]、气相色谱仪[6]、核磁共振氢谱仪[7]、拉曼光谱仪[8]等。Santos等[9]还设计了基于电磁传输线作为在线检测酒精含量的传感器,通过测量传输线内传播的TEM模式的电磁衰减来检测溶液中的酒精含量。此外,还有基于图像处理算法[10]实现自动摘酒的方法。上述研究工作对于酒精度的检测具有灵敏度高,结果准确等优点,但存在检测时间较长和受环境影响等问题,不适用于酒厂实际流酒过程检测。
研究拟通过检测音叉在不同模态不同浓度酒精溶液下的频率值,判断溶液酒精度值。采用LMS滤波算法和LSTM神经网络提高音叉检测频率稳定性和实现音叉频率动态补偿,基于改进遗传算法优化BP神经网络建立酒精度预测模型,以期为分段摘酒过程酒精度检测提供一种快速精准检测方法。
1 基于酒精度建模的分段摘酒系统
分段摘酒是通过采集流酒过程音叉频率值、音叉内置温度值和流酒温度值,通过PLC相关组件和酒精度计算模型实现酒精度在线计算,将酒精度数与控制系统预设酒精度数进行对比判断,控制各阶段电磁阀动作,使原酒流向不同的储存桶,分段摘酒系统流程示意图如图1所示。
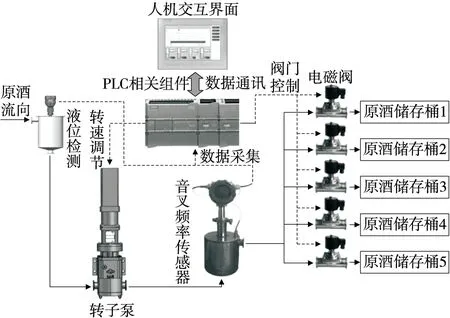
图1 分段摘酒系统流程示意图Figure 1 Process diagram of segmented wine picking system
2 多模态数据采集与自适应滤波
2.1 材料与仪器
2.1.1 材料与试剂
乙醇:分析纯,江苏强盛功能化学股份有限公司;
蒸馏水:江苏沭阳科泓商贸有限公司。
2.1.2 仪器设备
音叉频率传感器:GJM-801型,西安市高精密仪器厂;
恒温水浴槽:YTSC-15A型,上海叶拓仪器仪表有限公司;
温度传感器:PT100型,北京赛亿凌科技有限公司;
电子天平:AUY120型,岛津企业管理(中国)有限公司;
转子泵:PSA2型,北京帕普生泵业有限公司。
2.2 音叉频率传感器改进
音叉频率传感器内置温度传感器安装在机械支体内部,存在对液体温度响应不及时问题,为解决此问题,添加额外的液体温度传感器,用于测量溶液温度。将音叉频率传感器与液体温度传感器进行集成,通过RS485进行数据输出。为缓解音叉传感器存在的边界效应问题[11],提高检测精度,音叉频率传感器安装管径设计为DN160。
2.3 静态试验数据采集
利用岛津电子天平、恒温水浴槽、无水乙醇和蒸馏水配置20 ℃下不同浓度的酒精溶液。通过岛津电子天平测量溶液密度,利用PT100温度传感器检测溶液温度,查询《新编酒精密度浓度和温度常用数据表》[12],根据所测密度和温度得到所配溶液标准酒精度值,并进行标记。按照实际流酒过程酒精度分布区间,配置40%~80%vol的30个不同酒精度的酒精溶液样本,其中40%~60%vol,每个溶液样本递增2%vol,60%~80%vol,每个溶液样本递增1%vol。
将30个酒精溶液样本分别放入音叉频率传感器检测容器,在水浴槽进行不同温度区间恒温加热,记录每个酒精溶液样本在室温至40 ℃不同温度区间下的音叉频率值、音叉内置温度值和溶液温度值,每个温度区间递增1.5 ℃。待附加液体温度传感器数值稳定时,利用Matlab记录此试验条件下的数据,部分数据记录见表1。
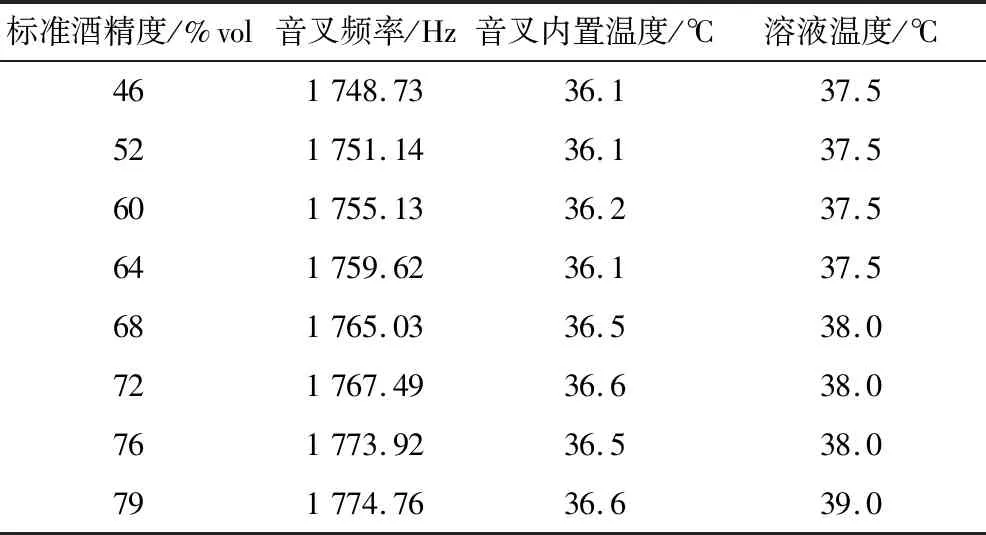
表1 部分数据记录表Table 1 Partial data record sheet
2.4 动态试验数据采集
流酒过程不同时刻流酒速度和酒精度不同,对音叉频率值产生影响,导致音叉在不同模态下的相同浓度酒精溶液会有不同的振动频率。利用分段摘酒设备和酒精溶液样本采集动态试验条件下音叉在不同泵转速不同浓度酒精溶液下的频率值,音叉频率方差如图2所示,当泵转速较高时,音叉频率方差较大,音叉频率不稳定,泵转速较低时,音叉频率方差较小,音叉频率较稳定。
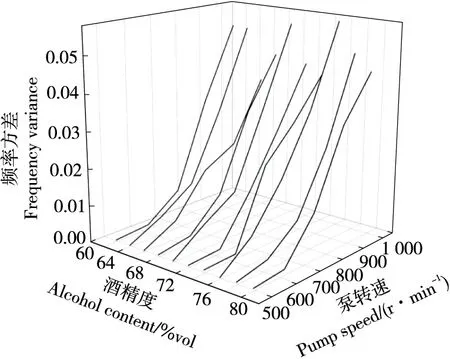
图2 泵转速—音叉频率方差图Figure 2 Variogram of pump speed-tuning fork frequency
2.5 数据处理流程
静态试验条件下不存在泵转速对音叉检测频率的影响,音叉检测频率稳定,且利用恒温水浴槽更容易测得恒温下音叉在不同浓度酒精溶液下的振动频率。因此将静态试验条件下数据作为酒精度标定数据,把静态试验条件下音叉在不同温度和浓度酒精溶液下的音叉频率值作为音叉在动态试验条件下的音叉频率补偿值。将动态试验条件音叉在不同浓度酒精溶液不同泵转速下的音叉频率平均值作为LMS自适应滤波音叉期望频率值。
研究采集不同模态、不同浓度酒精溶液下音叉动态频率值fd、音叉内置温度t1、溶液温度t2和动态试验条件下泵转速n。将音叉动态频率fd作为LMS自适应滤波的输入,输出为滤波后频率fl。将音叉动态频率fd、泵转速n、音叉内置温度t1和溶液温度t2作为LMS期望信号调整模型输入,输出为音叉在不同浓度不同转速下的音叉期望频率fq。将滤波后音叉频率fl、音叉内置温度t1、溶液温度t2和泵转速n作为LSTM音叉频率动态补偿模型的输入,输出为音叉频率补偿值fb。将音叉频率补偿值fb、音叉内置温度t1和溶液温度t2作为IGA-BP酒精度拟合模型的输入,输出为酒精度q,实现动态流酒过程酒精度在线计算,数据处理流程如图3所示。
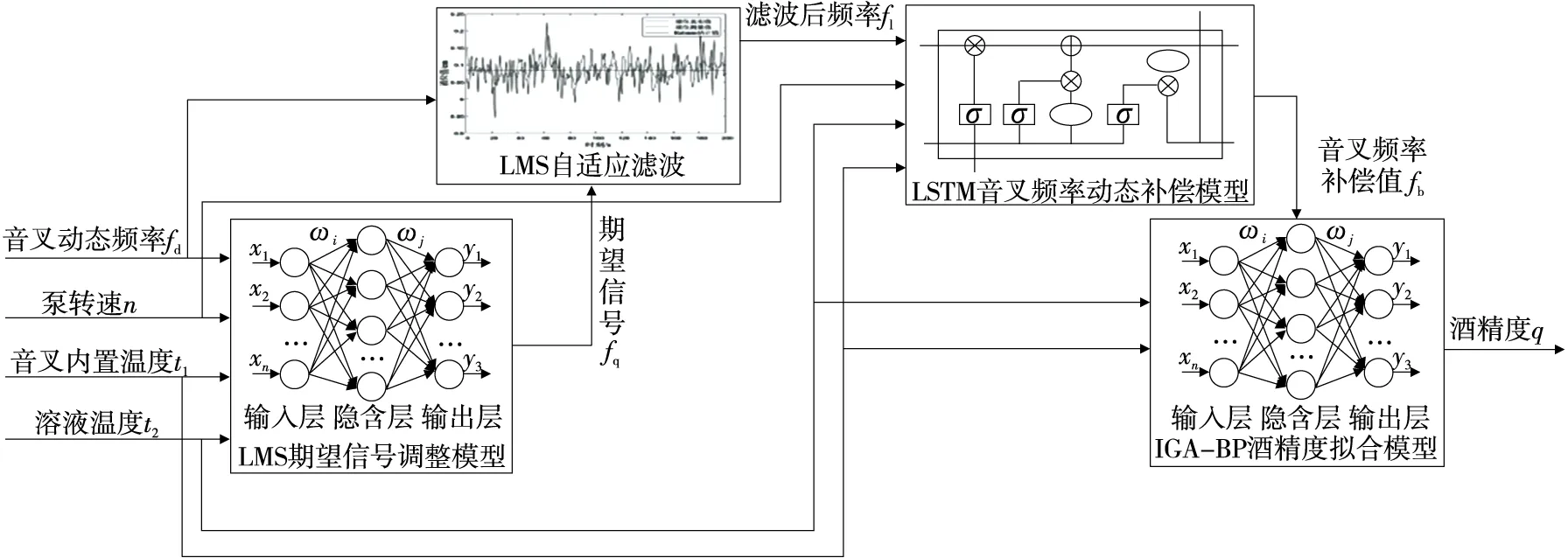
图3 数据处理流程图Figure 3 Data processing flow chart
2.6 音叉动态频率自适应滤波
为提高动态流酒过程音叉频率稳定性,基于最小均方(Least Mean Square,LMS)算法实现音叉动态频率自适应滤波。LMS滤波算法基于维纳滤波算法,采用随机梯度下降的方法实现代价函数最小化,具有计算复杂度低、无需统计数据的先验知识和均值无偏地收敛到维纳解等优点,在信号滤波方面得到广泛应用。LMS自适应滤波器的结构如图4所示,包括横向滤波器和LMS算法两部分。
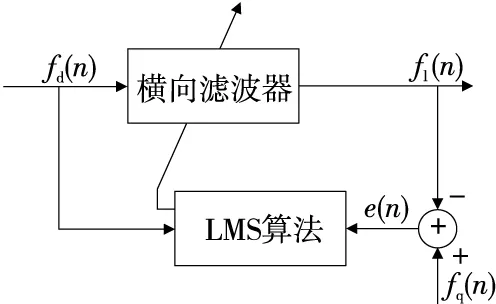
图4 LMS自适应滤波器框图Figure 4 Block diagram of LMS adaptive filter
横向滤波器本质是FIR结构的维纳滤波器,LMS算法根据期望信号fq(n)与输出信号fl(n)的误差e(n)调整横向滤波器的权系数向量,适应随机信号的时变统计特性[13]。基于BP神经网络建立LMS自适应滤波期望信号调整模型,设定神经网络隐含层神经元个数为6个,设定最大训练次数为1 000,学习速率为0.1,目标误差精度为0.001。滤波结果如图5所示,音叉检测频率方差由0.022 54降为0.002 17。
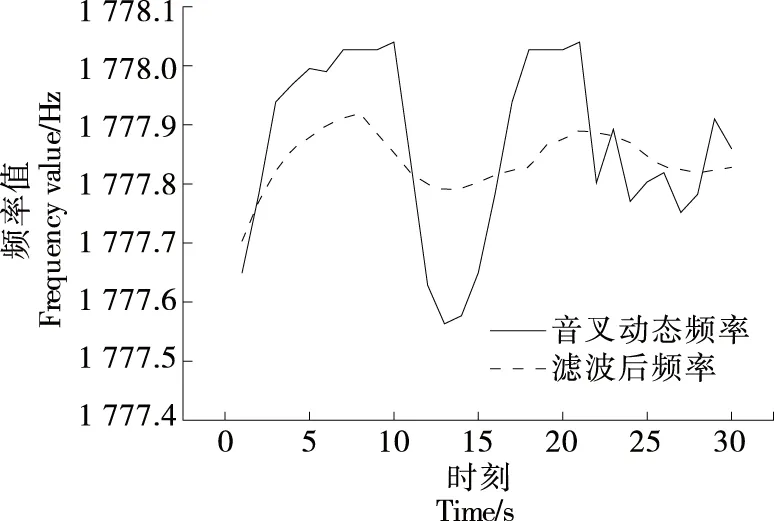
图5 音叉频率自适应滤波结果Figure 5 Tuning fork frequency adaptive filtering results
3 酒精度预测模型及结果分析
3.1 基于LSTM的音叉频率动态补偿模型
流酒过程音叉频率补偿值受历史时刻工况的影响,对于音叉频率补偿值预测问题,传统神经网络的输出是由当前时刻的输入决定,而忽视了历史时刻的影响。循环神经网络(recurrent neural network,RNN)是在隐藏层神经元上添加指向自己的反馈回路,使得上一时刻隐藏层状态也作为下一时刻的输入,从而将历史信息考虑在内,达到短期记忆的目的[14]。LSTM网络是一种特殊的RNN,它包含一个或多个记忆单元(cell)以及遗忘门(forget gate)、输入门(input gate)和输出门(output gate) 3个控制门,LSTM神经元使其能够存储并传递长期记忆和短期记忆,克服了传统RNN的长期依赖问题。
LSTM神经网络由时序数据输入层、隐含层和输出层组成,常用的序列预测法主要有单步法和多步法[15]。单步法是以固定时间步的历史数据预测下一时刻的值,每次预测网络的输入均为已知实际观测值,预测精度高,利于观测短期内性能的波动。多步法是指以固定时间步的历史序列预测未来多个时间步的序列值。实际流酒过程中,音叉频率补偿值受历史网络补偿值的影响,为提高预测精度,采用单步预测法。单步预测以不同浓度酒精溶液在动态试验条件下固定10个时间步的泵转速、滤波后音叉动态频率、音叉内置温度、溶液温度作为LSTM网络单步预测的输入,将试验酒度在此温度下的静态试验音叉频率值作为LSTM网络下一时刻的预测输出。设置LSTM网络隐含单元数目为200,训练次数为2 000次。滤波后音叉频率和音叉频率补偿值时序数据图如图6所示。
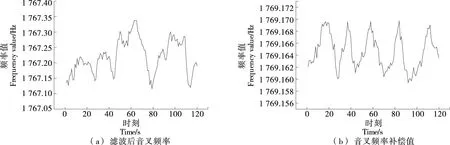
图6 样本数据时序图Figure 6 Sample data timing diagram
3.2 音叉频率补偿结果及对比分析
LSTM神经网络音叉频率动态补偿模型和BP神经网络音叉频率动态补偿模型预测输出如图7所示。由图7可以得出,LSTM神经网络预测值与期望值的最大误差为0.004 5,最小误差为0,平均预测误差为0.001 3;BP神经网络预测值与期望值最大误差为0.008 4,最小误差为0.000 4,平均预测误差为0.002 8。对比发现LSTM网络对音叉频率补偿值预测精度较高且更符合实际频率变化规律。
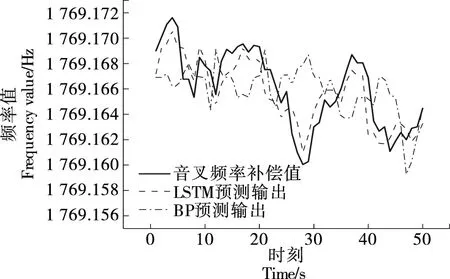
图7 音叉频率补偿值预测结果Figure 7 Tuning fork frequency compensation value prediction results
3.3 基于IGA-BP神经网络的酒精度预测模型
经LMS自适应滤波和LSTM神经网络音叉频率动态补偿模型解决了因泵运动导致的音叉频率检测不稳定及频率补偿问题。实际流酒过程音叉频率、音叉内置温度、溶液温度和标准酒精度之间的计算是一种非线性、时变性多因素复杂系统的数据预测问题,神经网络在数据预测领域得到广泛应用。
BP神经网络具有良好的非线性数据预测能力,但存在收敛速度慢、易陷入局部最优等缺陷,无法得到全局最优解。引入具有良好全局搜索能力的遗传算法(Genetic Algorithms,GA),并对传统遗传算法中交叉和变异概率进行改进,得到改进遗传算法(Improved Genetic Algorithms,IGA),寻优得到BP神经网络的最佳权值和阈值,提高BP神经网络的收敛速度,减少BP神经网络陷入局部最优的可能。
在传统的遗传算法中,交叉概率和变异概率为常数,但在实际遗传算法的进化过程中,进化前期和后期所需要的交叉和变异程度不同。在遗传算法的前期,因为个体的适应度较差,需要较大的交叉概率值扩大算法的全局搜索范围,较小的变异概率来保存个体优良基因;而在后期,个体的适应度高于平均的适应度值,需要较小的交叉概率来降低全局搜索能力,较大的变异概率来增强局部搜索能力,改进后的交叉概率Pc和变异概率Pm公式[16]如下:
(1)
(2)
式中:
Fmax——交叉的两个个体的最大适应度;
Fmean——种群个体平均适应度值;
F——种群中父代染色体的适应度值;
m——遗传算法当前的迭代次数;
mmax——最大迭代次数。
根据交叉和变异概率取值范围,设初始值Pc,max为0.9,Pc,min为0.4,Pm,max为0.09,Pm,min为0.005。
利用不同试验模态下数据采集结果,基于改进遗传算法优化BP神经网络建立以音叉频率补偿值fb、音叉内置温度t1、酒精溶液温度t2为输入变量,标准酒精度数q为输出变量的酒精度预测模型,标准酒精度q计算公式为:
(3)
式中:
x1——标准化后的音叉补偿频率,Hz;
x2——标准化后音叉内置温度,℃;
x3——标准化后溶液温度,℃;
n——隐含层神经元个数;
ωm,i——经改进遗传算法优化后BP神经网络输入层与隐含层的连接权值;
ωj——经改进遗传算法优化后BP神经网络隐含层与输出层的连接权值;
bi——隐含层的阈值;
B——输出层的阈值。
经改进遗传算法寻优得到的BP神经网络最佳权值和阈值如表2所示,表2中ωm,i(m=1,2,3;i=1,2,…,8)分别表示3个输入对隐含层的连接权值。
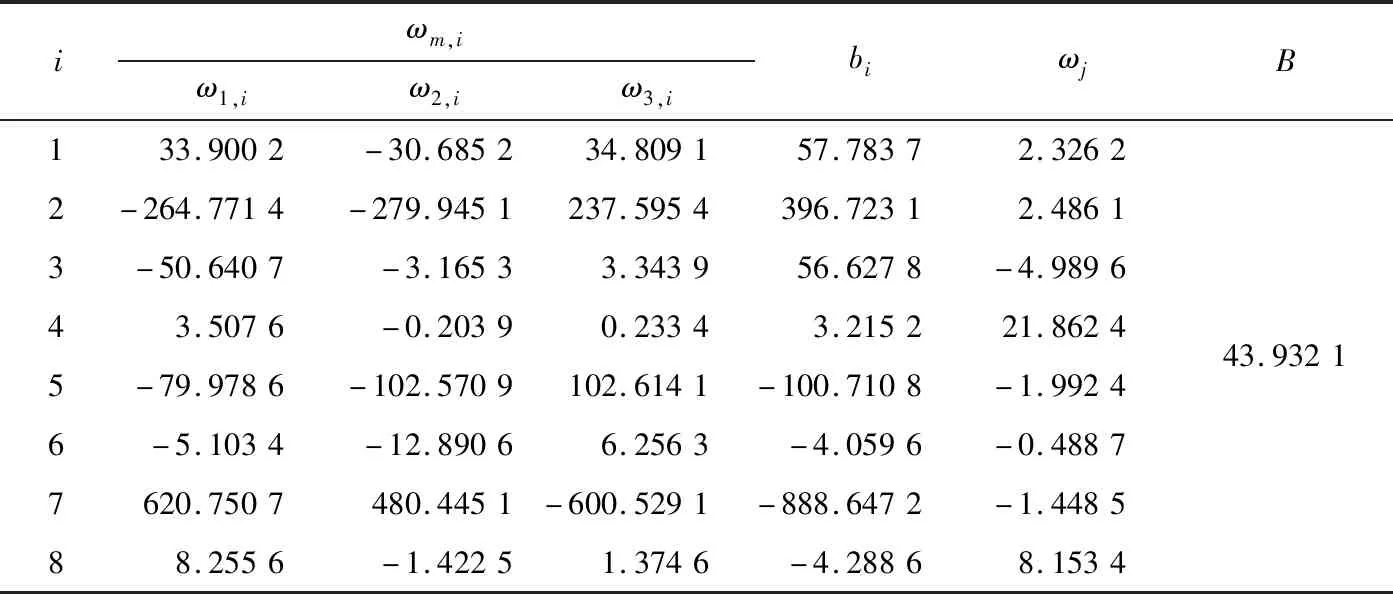
表2 BP神经网络最佳权值和阈值Table 2 Optimal weights and thresholds of BP neural network
基于改进遗传算法优化BP神经网络建立酒精度预测模型,设置遗传算法初始种群大小为30,迭代次数为60。BP神经网络输入为音叉频率补偿值、音叉内置温度值和酒精溶液温度值,输出为标准酒精度值,隐含层神经元个数设置为8个,设定最大训练次数为1 000,学习速率为0.1,目标误差精度为0.000 1,酒精度预测模型结果如图8所示。
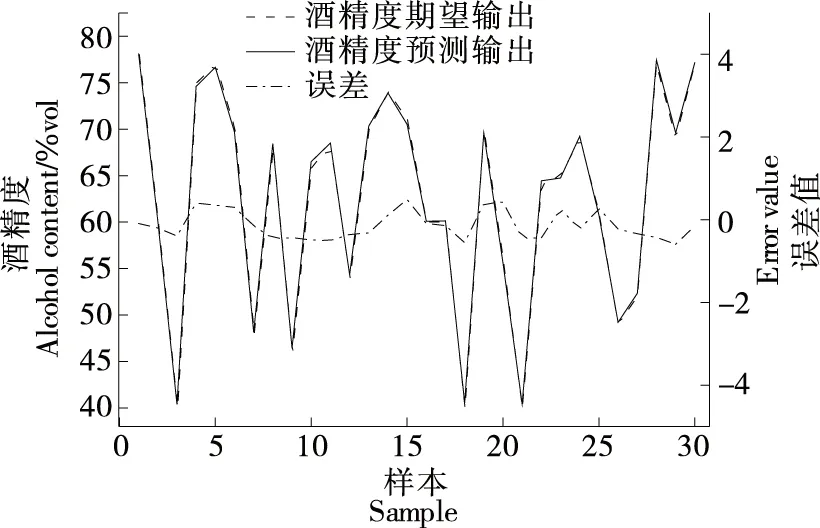
图8 IGA-BP酒精度预测结果Figure 8 Prediction results of IGA-BP alcohol content
3.4 酒精度预测模型结果及对比
改进遗传算法和传统遗传算法最佳个体适应度变化曲线如图9所示。由图9可以看出,改进后遗传算法在进化24次时适应度曲线稳定,而传统遗传算法在进化50次时适应度曲线尚未稳定,说明改进后的遗传算法能较快地搜索到合适的权值和阈值。
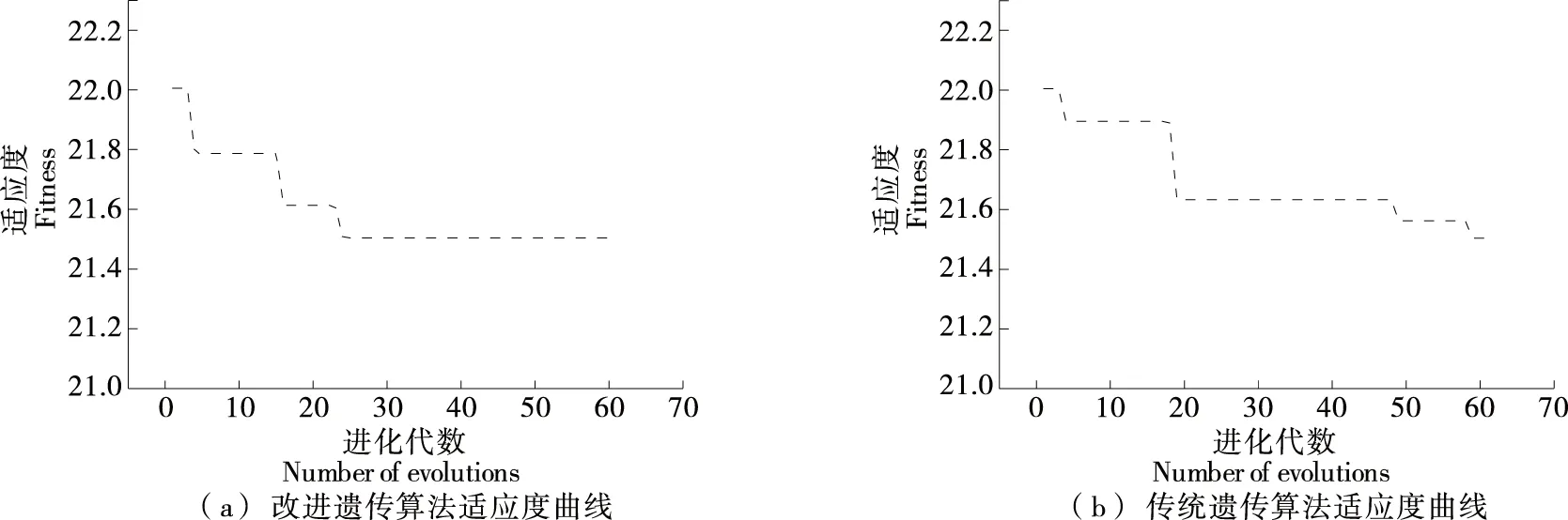
图9 两种遗传算法适应度曲线Figure 9 Two genetic algorithm fitness curves
GA-BP神经网络和IGA-BP神经网络酒精度预测模型训练结果曲线如图10所示。由图10可得,经遗传算法优化BP神经网络需30轮达到最优解,经改进遗传算法优化BP神经网络需11轮达到最优解。结果表明,改进遗传算法能够找到较优的权值和阈值,有效提高BP神经网络收敛速度和减小网络误差。
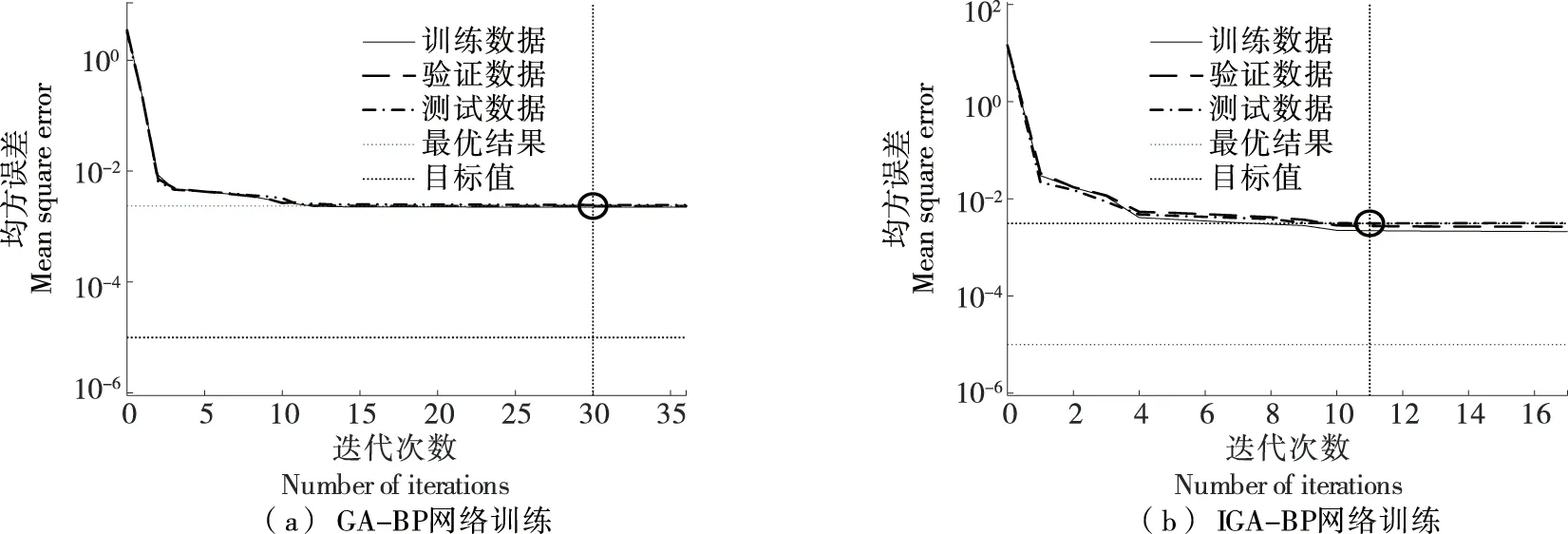
图10 神经网络训练结果Figure 10 Neural network training results
为评价模型预测效果,引入均方根误差和决定系数进行评价,均方根误差越小,决定系数越大,预测结果越准确。BP神经网络、GA-BP神经网络和IGA-BP神经网络标准酒精度预测模型结果对应的均方根误差和决定系数如表3所示。由表3可得,IGA-BP神经网络酒精度模型预测结果最准确。
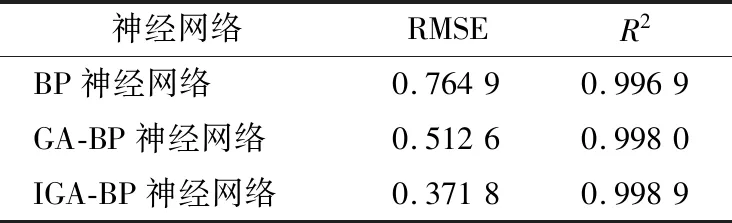
表3 酒精度预测模型对比Table 3 Comparison of alcohol prediction models
IGA-BP、GA-BP和BP神经网络酒精度预测误差结果如图11所示。由图11可以得出,IGA-BP神经网络酒精度预测模型预测误差最大值为0.61,平均预测误差为0.381,GA-BP神经网络酒精度预测模型预测误差最大值为1.09,平均预测误差为0.548,BP神经网络酒精度预测模型预测误差最大值为1.39,平均预测误差为0.74。结果表明,IGA-BP神经网络酒精度预测模型在预测精度上优于其他两种酒精度预测模型。
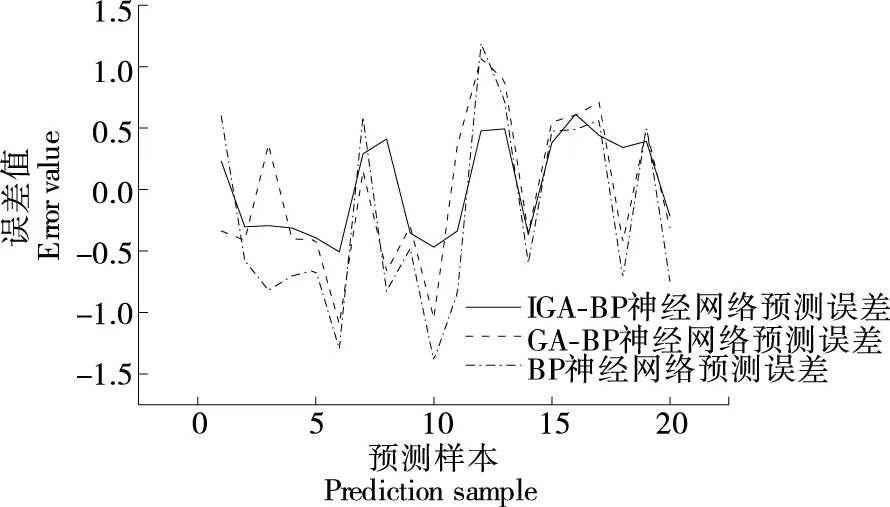
图11 酒精度预测误差Figure 11 Alcohol prediction error
4 结论
针对目前酒精度检测方法存在的问题,提出了一种酒精度快速检测的方法。采集音叉在不同模态、不同浓度酒精溶液下的试验数据,采用LMS滤波算法提高了音叉检测频率稳定性,LSTM神经网络音叉频率动态补偿模型平均预测误差较传统神经网络预测结果提高了53.6%,基于改进遗传算法优化BP神经网络建立酒精度预测模型,模型在迭代次数和预测精度上优于传统遗传算法优化BP神经网络和BP神经网络建立的酒精度预测模型。酒精度检测方法具有较高的精度和适用性,后续工作应深入研究动态环境下音叉检测不稳定问题,提高酒精度检测精度。
