基于机器学习算法的缺损米粉块在线快速检测
2022-06-02谭卢敏冯新刚
谭卢敏 冯新刚
(江西理工大学应用科学学院,江西 赣州 341000)
米粉块是可食用块状干米粉,口感好且方便保存和运输,在中国南方地区深受消费者欢迎[1]。米粉块一般由自动生产流水线加工而成,在加工成型环节会产生缺损米粉块,如不及时发现并处理,会对米粉块批量生产带来质量下降的影响。目前,企业多采用人工检测,随着工作时间加长,工人疲劳度增加,检测效率和准确性大大下降[2]。机器学习是基于数据集合建立数理模型进行研究推理,并可以衍生独立的计算模式,被广泛用于解决工程应用和科学领域的复杂问题。如:张先洁等[3]运用支持向量机(SVM)识别番茄果实成熟阶段准确率高达94.27%;Zhu等[4]基于深度特征和支持向量机的胡萝卜外观质量识别准确率为98.17%。Laxmi等[5]多类别直觉模糊双支持向量机在植物叶片识别中的应用有较好的泛化能力。通过上述文献的学习,结合缺损米粉块形状各异,其特征参数无规律[6-7],研究拟提出运用机器学习对缺损米粉块进行检测,利用相机对传输带上的米粉块进行实时拍照,经图像处理后提取米粉块相关特征数据作为机器学习的检测数据[8-9],通过支持向量机分类算法,对数据进行分析后检测出缺损米粉块,以期实现缺损米粉块在线检测与分拣。
1 支持向量机分类
支持向量机(SVM)是基于统计学习理论中结构风险最小化原则提出的,适用于有限数据集下的样本分类和回归处理,是机器学习中一种有监督的学习模式[10-11]。SVM算法用于分类问题的基本思路是寻找两类线性样本中的一个最优分类面,使得该分类面到两类样本数据点的距离最大,对于线性可分样本数据,SVM找到合适的参数(ω,b),得到最优分类面函数,即为决策函数如式(1) 所示。
(1)
通过决策函数可以对线性未知样本进行分类判别。对于近似线性可分数据,以上最优分类面并不能把所有样本都正确分类,为此,引入松弛因子ξ和惩罚因子C,在经验风险和推广性能之间找到一个均衡点,让训练模型有一定的容错率,同时对未知样本的分类正确率满足设计要求。
对于非线性可分样本,SVM利用非线性变化核函数方法,用满足Mercer条件的核函数得到原始空间中非线性学习算法,通过该方法将原空间转换到某线性特征空间后进行处理。其中根据原样本数据特点选择合适的核函数对转换后特征空间的线性化程度有较好的帮助[12-13]。
2 米粉块数据分析
米粉块加工属于食品加工,对加工条件要求较高,所以对流水线加工的米粉块通过非接触式的工业相机拍照获取原始图像,经图像处理获得米粉块数据。通过相机拍摄获得的米粉块图片共160张,作为样本用于模型训练,部分图片信息如图1所示。

图1 部分米粉块图片Figure 1 Pictures of some rice noodles
对样本图片进行图像处理后,获取米粉块轮廓的周长和面积、近似轮廓的周长和面积、近似轮廓点数、轮廓外接圆半径6个特征数据,并且给每个样本图片定义了分类标签,“0”表示合格米粉块,“1”表示缺损米粉块。
米粉块图像处理流程如图2所示。图像经过灰度化处理、二值化处理和图像形态学处理后滤除原图中的干扰信息,提高了米粉块特征信息提取的准确度。
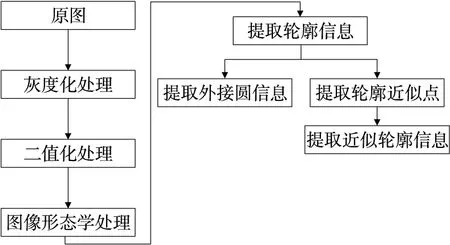
图2 米粉块图像处理流程图Figure 2 Flow chart of rice flour block image processing
经过图像形态学处理后得到清晰的米粉块二值轮廓图,用数字化二值图像轮廓扫描算法提取米粉块轮廓信息,根据轮廓信息进一步计算得到轮廓外接圆信息和轮廓近似点,轮廓近似点是根据Douglas-Peucker算法逼近原轮廓,得到更少的顶点数,再根据轮廓近似点获得近似轮廓信息,近似轮廓信息利用多边形逼近原始轮廓,进一步规范米粉块轮廓信息。
部分米粉块以各流程处理后的图片如图3所示。其中:轮廓信息图片的红色线是根据轮廓信息在原图上画出的米粉块轮廓线;外接圆信息图片的棕色线是根据外接圆信息在原图上画出的米粉块外接圆线;近似轮廓信息图片的紫色线是根据近似轮廓信息在原图上画出的米粉块近似轮廓线。

图3 部分米粉块图像处理流程各步骤处理结果Figure 3 Processing results of each step of image processing flow of some rice flour blocks
根据轮廓信息、外接圆信息和近似轮廓信息计算米粉块的周长、面积、外接圆半径等特征数据,对特征数据进行分析发现,单一特征数据对缺损检测不能提供准确的依据,比如由于加工的原因合格米粉块的轮廓面积会有一定差别,当缺损面积较小时其轮廓面积可能会大于合格米粉块的,因此会降低缺损米粉块检测的准确度。经过试验分析,采用米粉块的多特征数据进行检测,有利于提高检测准确度。
3 SVM机器学习检测缺损米粉块
使用SVM机器学习方法对米粉块的多特征数据组成的样本集进行分析,实现缺损检测。米粉块样本集如表1所示。
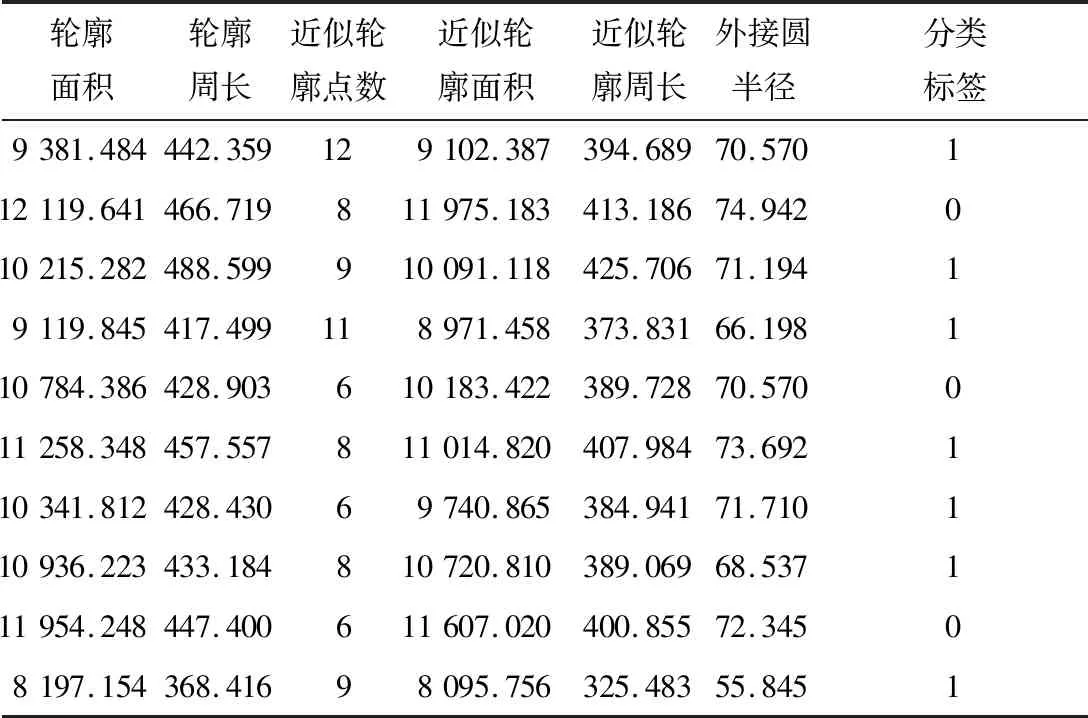
表1 部分米粉块特征数据集Table 1 Characteristic data set of some rice flour blocks
每个米粉块由6个特征数据和一个分类标签数据组成,通过对数据进行SVM机器学习,得到训练模型,从而实现米粉块的在线检测,其检测流程如图4所示。
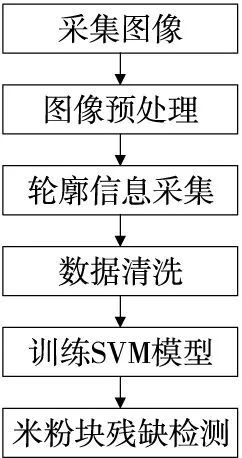
图4 SVM方法实现检测米粉块缺损的流程图Figure 4 Flow chart of detecting rice flour block defect by SVM method
从表1可以看出,米粉块的特征数据大小不一,在进行分析之前需要进行数据清洗,采用min-max标准化对样本数据进行归一化处理,如表2所示。
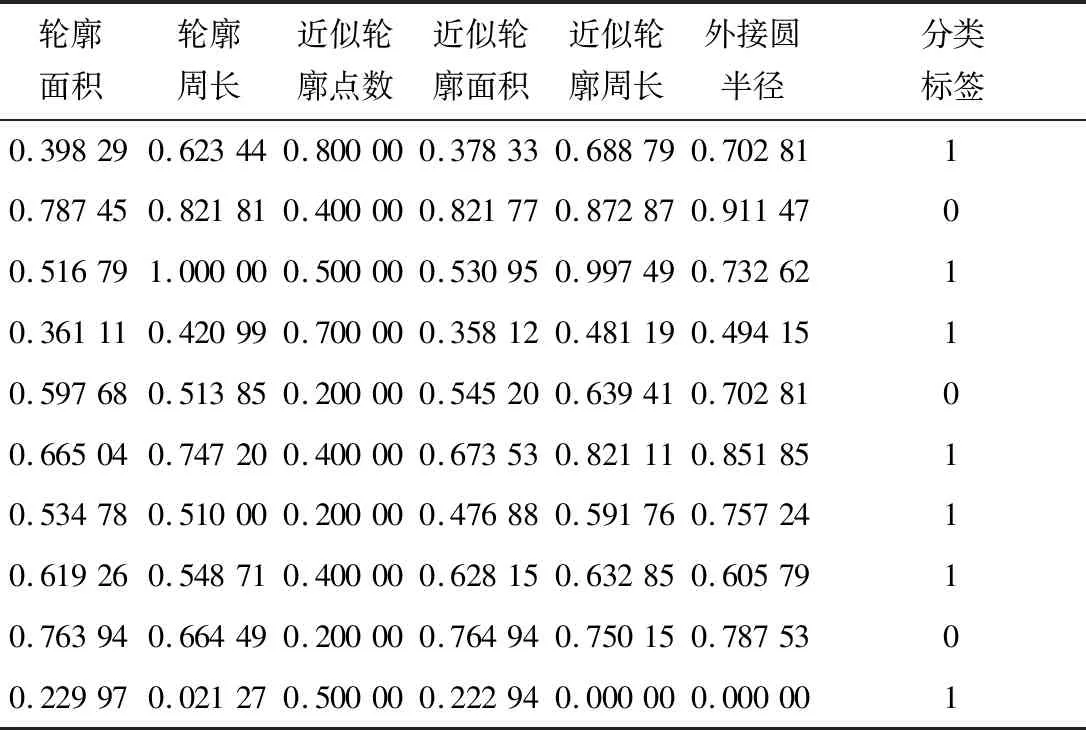
表2 部分米粉块min-max标准化后特征数据集Table 2 Characteristic data set of some rice flour blocks after min max standardization
处理后的样本数据随机分为训练数据集和测试数据集,两个数据集中的样本数按照7∶3的比例进行分配,代入SVM模型中进行训练和测试。
其中为了确定合适的核函数,分别选择rbf核函数、linear核函数、poly核函数,对训练集进行训练,用交叉验证法寻找最优模型参数,得到各自的优化模型,然后把测试集分别代入这些模型进行分类测试并记录分类准确率和测试用时,如表3所示。
由表3可知,rbf核函数准确率最高,用时较少;poly核函数准确率在3种核函数中最低同时用时较长;linear核函数虽然用时最短,但是准确率没有rbf核函数高,用时与rbf核函数相差不大;通过数据比较,选择rbf核函数的SVM模型。

表3 不同核函数下SVM模型的平均准确率和平均用时Table 3 Average accuracy and average time of SVM model under different kernel functions
为了进一步检验该模型的优势,以相同米粉块样本数据集在相同条件下用其他分类算法进行训练,并对测试集进行分类分析,结果如表4所示。通过对比,SVM分类算法的平均准确率最高,平均用时最短。
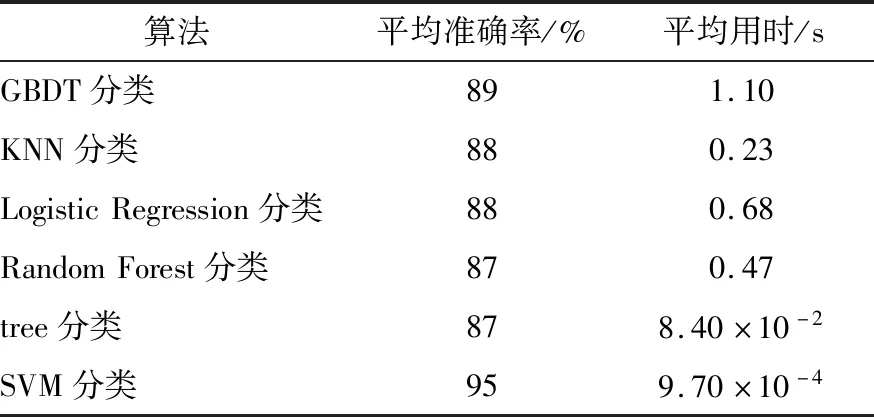
表4 不同分类算法的平均准确率和平均用时Table 4 Average accuracy and average time of different classification algorithms
4 结论
研究结果表明,用SVM分类算法进行米粉块缺损检测相比GBDT、KNN、Logistic Regression、Random Forest和tree 5种分类算法准确率高,用时短,有利于实现缺损米粉块的在线快速检测。但该研究对样本数据的先验信息特征研究不够深入,仅用3种常用核函数进行试验分析,后续可以利用隐含在数据中的先验信息选择更合适的核函数,进一步提高米粉块缺损检测的准确率。
