气象灾害普查数据处理
2022-05-31高鹏付杰张春燕刘昊
高鹏 付杰 张春燕 刘昊

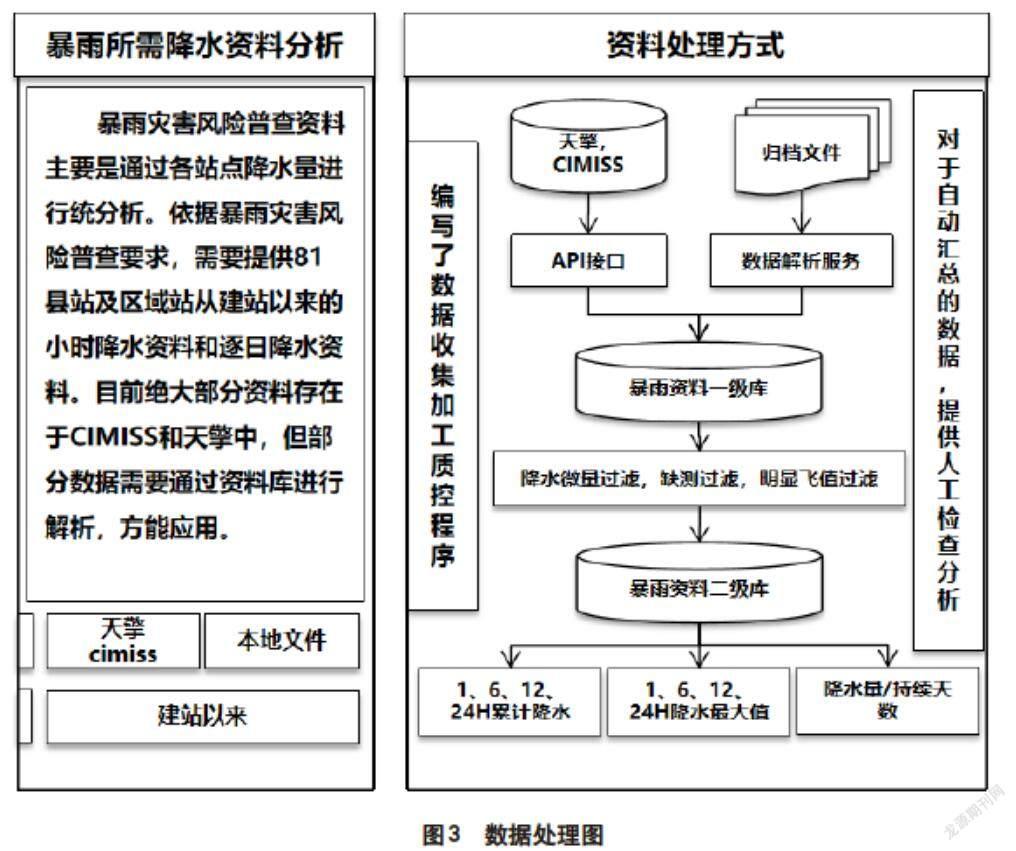
摘要:开展全国气象灾害综合风险普查是党中央、国务院安排部署,交由气象部门承担的重要任务,是国情国力调查的重要内容,是提升气象防灾减灾能力的基础性工作。开展建站至2020年甘肃省暴雨、大风、冰雹、雪灾所需的81个气象站点及区域自动气象站各要素(逐小时气温、降水、风速、风向;积雪、降雪日数、积雪深度、冰雹直径、最大风速、极大风速等)数据的统计分析。
关键词:灾害普查 数据分析 自动站 气象数据 数据处理
Meteorological Disaster Census data Processing
GAO Peng FU Jie ZHANG Chunyan LIU Hao
(Gansu Meteorological Information And Technical Equipment Support Center, Lanzhou, Gansu Province, 730000 China)
Abstract:Carrying out the national comprehensive risk survey of meteorological disasters is an important task arranged and deployed by the Party Central Committee and the State Council and entrusted to the meteorological department. It is an important content of the investigation of national conditions and national strength, and a basic work to improve the ability of meteorological disaster prevention and reduction. Carry out statistical analysis on the data of 81 meteorological stations and regional automatic meteorological stations (hourly temperature, precipitation, wind speed, wind direction; snow, snow days, snow depth, hail diameter, maximum wind speed, maximum wind speed, etc.) required for rainstorm, gale, hail and snow disasters in Gansu Province from the establishment of the station to 2020.
Key Words:Disaster survey; Data analysis; Automatic station;Meteorological data;Data processing.
中图分类号:P409 文献标识码:A
1总体框架
数据处理软件开发,主要5层架构进行设计,主要为资源层、支撑层、应用接口层、应用交互层和用户层构成,具体如图1所示。
系统架构图用以说明整个系统的组成部分,并从逻辑上说明了各层内部组成元素、层与层之间的逻辑关系,系统体系的构成包括用户体系、应用交互体系、应用接口体系、数据支撑层和资源存储体系,这些不同的组成部分,都具有明确的定位和分工,它们从不同方面、不同层次发挥着特定的应用作用,这些组成部分互相配合,共同协作完成整体应用功能。
2 主要功能
2.1 数据库设计
风险普查项目中数据库采用MySQL,采用MySQL 数据库原因为MySQL具有以下优势:
(1)使用C和C++编写,并使用多种编译器进行测试,保证源代码的可移植性。
(2)支持 AIX、FreeBSD、HP-UX、Linux、Mac OS、NovellNetware、OpenBSD、OS/2 Wrap、Solaris、Windows 等多种操作系统。
(3)为多种编程语言提供了API。这些编程语言包括C、C++、Python、Java、Perl、PHP、Eiffel、Ruby和Tcl等。
(4)支持多线程,充分利用CPU资源。
(5)优化的SQL查询算法,有效地提高查询速度。
(6)既能够作为一个单独的应用程序应用在客户端服务器网络环境中,也能够作为一个库而嵌入其他的软件中。
(7)提供多语言支持,常见的编码如中文的GB 2312、BIG 5,日文的Shift_JIS等都可以用作数据表名和数据列名。
(8)提供TCP/IP、ODBC和JDBC等多种数据库连接途径。
(9)提供用于管理、检查、优化数据库操作的管理工具。
(10)支持大型的数据库。可以处理拥有上千万条记录的大型数据库。
(11)支持多种存储引擎。
根据气象灾害综合风险普查业务需求,累计70年日资料一个站的理论记录数量约为25 600条,小时资料理论记录数量约为614 800条,由于各县项目需求中可能涉及到区域站数据,因此数据量级将会很大,为避免后续工作开展不受数据量级影响,数据设计采用分库分表存储[1-3]。
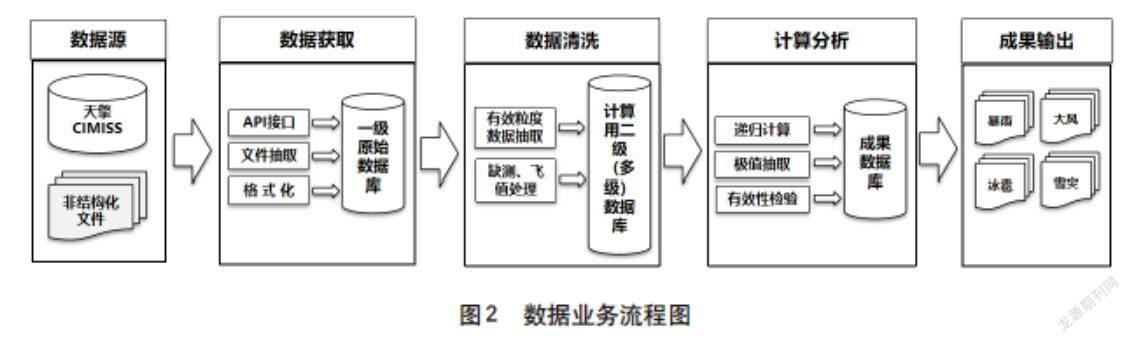
暴雨、大风、冰雹、雪灾相关数据产品服务工作采用SQLServer數据库技术,完成了以下4种资料数据库的建设工作,如图2所示。
第一,完成了全省所有气象站实时资料数据库:所有数据均由省局CIMISS平台提供,并通过MUSIC API数据接口实时获取,实现本地化数据沉淀存储。
第二,下载省局智能网格分布式数据,通过后台自动化调度任务实现动态获取。
2.2数据处理
由于各县气象资料需求不统一,数据处理无法做到程序自动化处理,所有需求均需要通过人工干预才能正常处理,因此,在该项工作中,安排了专人对各县提供的数据进行审核,将整理完的需求统一编码,同步开发数据下载及程序,完成数据入库工作。截至目前项目涉及到的数据有两大类,分别为CIMISS接口数据和闪电资料,由于数据无法做到程序自动校验,因此数据处理分为4个部分任务,分别为CIMISS数据下载入库任务、CIMISS数据输出任务、闪电资料解析任务及闪电资料数据输出任务,如图3所示。
2.3 数据检验
数据校验是本项目中占比最大的一部分,也是本项目中最重要的一个环节,由于数据检验无法做到程序自动校验,采用人工检验的方式对数據进行核验,对已入库的数据字段、缺失情况、一致性进行检查,检查下载的数据是否正常,有无缺失的数据。
2.4 数据输出及下发
对校验后的数据进行输出及下发,采用Excel表格文件格式进行文件输出,可能涉及到大量的区域站的数据,因此文件输出时采用分站的形式进行输出(即一个站一个Excel文件),防止数据因量大而出现数据丢失的情况。
3 关键技术
3.1 大数据处理技术Python
Python是数据科学家十分喜爱的编程语言,究其原因是Python语言简单易懂、语言通用,其内置了很多由C语言编写的库,操作起来更加方便,在大数据的处理方面具有先天优势,Python语言得益于它的简单方便,Python在数据分析和交互、探索性计算及数据可视化等方面都显得比较活跃,这就是Python作为数据分析的原因之一,python拥有numpy、matplotlib、scikit-learn、pandas、ipython等工具在科学计算方面十分有优势,尤其是pandas,在处理中型数据方面可以说有着无与伦比的优势,已经成为数据分析中流砥柱的分析工具,所以要做好数据分析,优先选择Python语言。
3.2 模块化的处理方式
风险普查数据是一项集成、动态、复杂的应用性工作,为了最大限度地重用数据处理工作中的公共功能,并提供灵活的方式进行功能扩充和工具集成,采用基于插件技术的可扩展的应用框架技术进行数据处理模块建设,可以显著地缩短模块的开发周期,提高数据处理质量和重用程度。
3.3 利用标准方差快速质控
风险质控数据均属于长序列,且具有一定的数据标准,诸如温度等数据,本次工作将引入标准差(方差),从总体上描述一组数据的稳定性,因为标准差能反映出一个数据集的离散程度。平均数相同的,标准差未必相同。标准差是反映一组数据离散程度最常用的一种量化形式,是表示精确度的重要指标。
3.4 引进DPF框架,建立数据清洗模型
风险普查数据属于大量且集中化的数据,本次数据处理主要对四类异常数据进行处理;分别是缺失值(missing value),异常值(离群点),去重处理(Duplicate Data)及噪音数据的处理。
为了实现完成数据清洗工作,将在本次工作过程中,引进DPF框架,尽最大可能建立一些数据模型实现数据的处理,提升数据处理的效率,提高数据处理的质量。
DPF的理念很简单,利用不靠谱的数据训练一个模型,这个模型在训练集上准确度通常都很低(如果训练集上已经完美拟合,那这个方法就不能直接用了)[4-6]。用训练好的模型把最不靠谱的那些数据(预测与实际差得最远)删掉,然后利用剩下的数据训练新的模型,之后再用新模型把剩下数据里最不靠谱的一些数据删掉,如此重复,直到模型在训练集上达到较高的准确度。这时候被筛完剩下的数据可能比较少了。为了召回一些被早期模型误过滤掉的样本,把最新的模型应用到原始的全量数据上,这样去除最不靠谱的数据后会留下更多的数据用于接下来的迭代[7-10]。之后的迭代逻辑和前面的相同,利用模型清除最不靠谱的数据,再用清洗后的新数据训练新模型。
4 结语
大多气象灾害所要求的数据均需要进行汇总分析,因此,要求本系统能提供一套灵活、可配置的汇总算法,实现由原始数据派生出新的数据集,或者由同一资料加工成不同时间尺度资料的多元算法。本次工作对于暴雨过程数据需要提供降水累计、平均、小时降水量总数,过程中每个整点过去1h、3h、6h、12h降水值。小时降水则需要基于每个整点整理统计过去1h、3h、6h、12h、24h的降水累计。冰雹数据需要利用灾情数据,还需要结合A文件的天况数据等。
对于处理完成后的基础数据,仍然存在不可预知的问题,在利用之前,必须要对所有原始数据集进行清洗,形成原始数据分析结论,真正做到每一类资料存储情况可知、可控。数据清洗主要是对各类原始数据中存在的异常值、空值、非法值进行处理,处理方式是要求按照不同气象资料种类建立该类数据对应的一种或多种质控方案,主要包括阈值质控,无效值等质控等。对于非连续性的数据集,根据其特征,采用插值等算法完成数据连续性补充工作。
参考文献
[1] 张翔,韦燕芳,李思宇,等.从干旱灾害到干旱灾害链:进展与挑战[J].干旱气象,2021,39(6):873-883.
[2] 刘云,康卉君.2002—2019年江西省省级地质灾害气象预警分析[J].华东地质,2020(4):416-424.
[3] 刘云,康卉君.江西崩塌滑坡泥石流灾害空间时间分布特征分析[J].中国地质灾害与防治学报.2020(4):107-1121.
[4] 王亚俊.考虑属性交互的气象灾害治理能力评价建模研究[D].南京:南京信息工程大学,2021.
[5] 孙大为,张广艳,郑纬民.大数据流式计算:关键技术及系统实例[J].软件学报,2014,25(4):839-862
[6] 任芝花,张志富,孙超,等.全国自动气象站实时观测资料三级质量控制系统研制[J].气象,2015,41(10):1268-1277.
[7] 王秀珍.玉溪烤烟气象灾害风险及作物模型适用性研究[D].南京:南京信息工程大学,2021.
[8] 张国华,何学文.江西省吉安县地质灾害气象预警研究[J].华东地质,2021,42(4):373-382.
[9] 周江,王伟平,孟丹,等.面向大数据分析的分布式文件系统关键技术[J].计算机研究与发展,2014,51(2):382-394.
[10] 李秀萍.河北省气象灾害应急联动机制研究[D].南京:南京信息工程大学,2021.
基金项目:甘肃省气象局气象科研项目(项目编号:Ms2022-05);气象大数据支持与服务:甘肃省气象局创新团队(项目编号:GSQXCXTD-2021-01)
作者简介:高鹏(1987—),男,硕士,工程师,研究方向为气象大数据、云计算等。
通信作者简介:付杰(1987—),男,硕士,工程师,研究方向为气象大数据,综合监控等,E-mail:fujiede2021@163.com
