考虑数据缺失类型的旅行时间填补方法研究
2022-03-29任毅龙王建斌
任毅龙 ,王建斌 ,付 翔
(1.北京航空航天大学交通科学与工程学院,北京 100191;2.综合交通大数据应用技术国家工程实验室,北京 100191;3.北京航空航天大学杭州创新研究院(余杭),浙江 杭州 310023)
1 概 述
丰富的监控设备提供了大量时空尺度的城市路网旅行时间数据,然而监控设备故障、信号干扰、恶劣天气、通信终端宕机等情况常常干扰数据采集,造成数据缺失问题[1]。旅行时间数据的缺失会直接影响路网运行状态评估的准确性,因此对缺失旅行时间数据进行准确填补十分必要。
目前聚焦缺失交通流数据填补的工作和研究主要分为以下几个部分:传统模型,统计模型和机器学习类模型。传统模型,主要通过基于历史或相邻数据的插值法和回归插值法进行数据的填补[2-5]。与传统方法相比,统计模型由于其较强的可解释性而被广泛应用于数据插补,例如基于贝叶斯主成分分析(BPCA)和概率主成分分析(PPCA)的交通流数据填补方法[6-7]。随着机器学习理论的发展,神经网络成为交通流填补和建模中常用的方法[8-10]。与神经网络相比,SVM表现出更好地拟合性能和泛化能力。而广泛用于数据分类和填补的高斯过程模型[11-12]相较于神经网络和SVM在模型结构上更为简单,且能效率和精确度更高。
上述方法大多采用时间序列模型将旅行时间以低维度形式输入,然而交通流数据具有天然的高维特征,仅以低维形式存贮不仅浪费了各维度数据间的潜在关联,甚至还会破坏交通流数据的数据结构[13]。
张量作为一种高维空间的数据存储模型,通过将旅行时间以张量的形式存储可以保留交通数据的原始空间结构与内部潜在信息,通过将张量分解再重构的张量分解算法可以基于已观测旅行时间实现对缺失旅行时间的推测,通过挖掘数据多维度之间的多重共线性,增强隐形知识发现过程,在高数据缺失率下相较于传统数据填补方法准确性更高[14-17]。Tan等[18]首次引入张量对交通数据进行四维建模,提出了一种基于Tucker分解的估算方法(TDI)来估算缺失的流量值。Zhao等[19]提出了一种朴素贝叶斯CP分解方法,可以自然地处理不完整且含噪声的张量数据。Wang等[20]利用三阶张量对不同路段不同时段的驾驶员行驶时间进行建模,利用上下文感知张量分解方法估计张量的缺失值。
尽管基于张量分解的交通数据补全方法研究众多,但大多没有考虑实际交通场景中复杂的数据缺失模式,没能充分挖掘不同数据缺失模式的数据结构特征,导致模型在不同缺失模式下表达效果不佳,甚至造成高数据缺失率时精度下降,为此,本文将张量数据结构与交通场景相关联,挖掘高频数据缺失场景,针对不同缺失场景构建张量分解模型,实现缺失数据的填充,具体的技术路线如图1所示。
针对上述问题,本文的主要贡献如下:
(1)进行张量缺失模式分析与交通场景映射论证,挖掘出两种高频数据缺失场景:随机缺失和纤维化缺失。
(2)针对随机缺失场景,构建考虑维度偏置的历史旅行时间张量,并提出一种考虑时间关联性的旅行时间填补方法,解决高数据缺失率下张量结构被破坏而导致精度低的问题。
(3)针对“特定日期特定路段长时间数据缺失”高频纤维化缺失场景,将时空相似路段数据融入张量分解模型,规范张量分解过程中因子矩阵迭代的方向与大小,解决传统张量分解忽略局部一致性导致的不适用纤维化缺失场景这一问题。
(4)基于实际交通流数据对本文所提出的旅行时间填补方法进行验证分析。
2 张量构建与数据缺失场景挖掘
2.1 张量理论基础
张量是一种高维的数据存储模式,通常被认为是低维数据的高维扩展。张量分解领域广泛应用的两种算法为CP分解以及Tucker分解,Tucker因其更灵活的分解结构可以实现更小的模型误差,因此在本文中选择Tucker分解作为基础分解框架。
2.2 数据预处理及旅行时间张量构建
交通管理部门在城市关键路段部署卡口监控系统,获得海量的交通数据。在使用该数据进行建模时,由于采样频率、设备故障等原因往往导致数据质量问题,需要进行数据预处理:
2.2.1 剔除异常值
计算机视觉技术的误差会导致车牌号识别错误或无法识别,车辆在变道会导致相同时间节点记录同一车辆多条轨迹记录,以上两种情况产生的异常数据需要剔除。
2.2.2 滤波降噪
由于突发事件、司机临时停车等问题导致行程实际旅行时间偏大,本文采用滑动平均滤波法对数据中的离群点进行剔除,改善数据的连续性与平滑性,有利于后续的张量分解计算。
本文采用三维张量形式进行旅行时间张量建模,张量的三个维度分别为:路段、日期、时间窗。旅行时间张量定义为Xr∈RN×M×L,其中N为路网中的路段总数,M为日期天数,L为在一天时间内选取的时间窗口的数量,由时间窗口长度决定。张量中的元素xijk代表在车辆在j天k时段内通过道路i的平均旅行时间。
2.3 张量数据缺失模式与场景挖掘
旅行时间数据缺失类型大致分为三类[21-22]:随机缺失,即缺失的元素随机散布在数据结构上;纤维化缺失,在数据结构上表现为缺失的数据沿着张量中任意一个维度呈纤维化延伸;系统性缺失,由于服务器故障等系统性问题导致的数据大范围失真失效,学者们一般不将这种缺失模式列入研究范围内。
本文将对纤维化缺失进行实际的场景化分析,如图2所示缺失数据沿着不同的维度延伸对应的缺失场景分别为“特定路段、特定日期长时间数据缺失”、“特定路段在每天固定的时间段数据缺失”、“在特定日期特定时间路网内所有路段数据均缺失”。“特定路段特定日期长时间数据缺失”场景在实际生活中时常发生(例如卡口监测设备长时间故障导致的数据缺失),故本文针对该场景的旅行时间数据填补问题为例进行重点分析。
3 考虑数据缺失模式的旅行时间填补方法研究
3.1 随机缺失场景的旅行时间填补方法
本节基于交通数据的时间关联性,通过历史张量与原始张量合并建模,完善数据结构,解决随机缺失高缺失率场景下旅行时间填补精度低的问题。
3.1.1 考虑维度偏置的历史旅行时间张量构建方法
本小节通过构建历史旅行时间张量Xh来弥补原始张量Xr中的空缺。历史旅行时间张量Xh的各维度数据均与原始张量Xr相同,历史张量中元素Xh(i,j,k)代表车辆在相同工作日j的第k个时间窗通过第i条路段的旅行时间平均值。
原始张量三个维度上的旅行时间相较于历史平均值可能存在偏差[23]。本小节提出一种自适应标定不同维度历史旅行时间偏差的方法,通过梯度下降的方式迭代求解修正系数,以保证历史数据可以最大程度表征当前的数据状况。历史张量修正值计算方式如下式所示:
3.1.2 考虑时间关联性的旅行时间填补方法建模
本文基于Tucker分解框架提出了考虑历史数据特征的改进张量分解模型,在分解过程中融入历史张量约束项,规范因式迭代的方向,模型的目标函数如所下式所示:
目标函数以分解结果与原张量的差最小为导向,主体分为三部分:‖Xr-G×1U×2V×3W‖2表示的是旅行时间原始张量Xr与估计旅行时间张量的差值的范数;其中×k为张量与矩阵的k模态积远算符,表示的是旅行时间历史张量与估计旅行时间张量的差值的范数,用以弥补因原始数据缺失导致的数据稀疏性问题;‖G‖2+‖U‖2+‖V‖2+‖W‖2为正则项,用于防止分解过程过拟合;λ1,λ2为公式中各项的权重系数。
目标函数(3)的求解是一个非线性凸优化问题,无法直接求解,所以本文使用随机梯度下降的方法求解目标方程,得到各个变量的更新公式如下,其中令,可得:
式(4)为核张量G的更新方法,式(5)~(7)为因子矩阵U,V,W的更新方法,在算法迭代终止后,可以得到各因子矩阵的最终值,此时可以通过张量重构的方式计算最终的推断旅行时间张量,计算方式如下式所示:
在重构推断旅行时间张量过程中,会导致原始张量中未缺失路段的数据也相应改变,因此需要将推断旅行时间张量中这部分数据调整为原始数据,调整公式如下所示:
原始张量中未缺失路段的数据集合为φ={(i,j,k)|Xijk≠ 0},缺失路段数据集合为={(i,j,k)|Xijk=0}。
3.2 纤维化缺失下旅行时间填补方法
本节通过对时空特征相似路段数据进行挖掘并融入张量分解算法,解决传统张量分解忽略局部一致性导致的不适用纤维化缺失场景这一问题,以提高算法的准确性。
3.2.1 基于K-means算法的空间相似性挖掘
本小节采用基于划分的聚类方法根据道路长度等物理属性对道路进行聚类,并通过轮廓系数指标评价聚类效果的优异,轮廓系数越大,表示簇内实例之间紧凑,簇间距离大,聚类效果越好。轮廓系数计算公式如下式所示:
式中a(i)为向量i到同一簇内其他点不相似程度的平均值,b(i)为向量i到其他簇的平均不相似程度的最小值。
3.2.2 基于改进LCSS算法的时间相似性挖掘
本小节提出一种自适应的阈值设定方法,通过设定相似比例,利用两条路段交通量的平均值近似表征路段的交通状况,其与相似比例的乘积代替传统LCSS方法中的固定阈值,这种处理方式可以使算法中相似阈值随交通状态动态变化,当两个比较点的路段流量差小于动态阈值时,则认为二者相似。改进LCSS算法如下式所示:
式中A与B分别代表两条路段的交通流量序列,长度分别为n与m,at与bi分别代表A与B中的序列点,两个比较点间的流量差用dist(at,bi)表示,计算方式如下式所示:
相似阈值θ的选择是模型精度与所挖掘相似路段数量的博弈过程,若选取阈值过小,则极有可能出现模型无可行解的情况,在本文中选取θ=0.2。
基于上述公式,最长公共子序列的相似度公式如下式所示:
通过计算同一簇类的其他路段与数据缺失路段间的交通流时序向量轨迹相似度DLCSS,选取其中轨迹相似度最大的路段为最终的相似路段。
3.2.3 考虑时空相似度的旅行时间填补方法建模
为了发挥相似路段的靶向作用,增强对缺失数据的隐形知识以及局部一致性的发现过程,设计Tucker分解目标函数如下式所示:
目标函数以分解后结果与原张量的差最小为导向,‖Xr-G×1U×2V×3W‖2表示的是旅行时间张量Xr与估计旅行时间张量的差值的范数,其中×k为张量与矩阵的k模态积运算符,k=1,2,3;F为相似路段的交通流量序列,用其表征相似路段的时空特征,T为系数矩阵,‖F-WT‖2用来保证分解后的时间因子矩阵与相似路段的交通流量序列结果相近,通过这种方式控制分解过程中极大程度保留了缺失路段的时空特征。
目标函数(14)的求解是一个非线性凸优化问题,使用随机梯度下降的方法求解目标方程,得到各个变量的更新如式(15)~(19)所示,其中令δ=Xr-G×1U×2V×3W;可得:
式(15)为核张量G的更新方法,式(16)~(18)为因子矩阵U,V,W的更新方法,式(19)为系数矩阵T的更新方法,并通过式(8)和式(9)计算得到最终的推断旅行时间数据。
4 实例验证及分析
本章节使用瑞安市卡口数据及所构建的旅行时间张量,验证旅行时间填补方法的有效性。
4.1 数据处理
本文选取浙江省瑞安市一个局部路网作为数据采集区域,区域内卡口数据采集设备共35个,共计覆盖路网内108个路段,如图3所示(图中白色圆点代表卡口检测系统安装位置)。卡口数据采集自2016年 5月 16日 00:00:00至 2016年 6月 5日 23:59:59,共计21天的交通流数据。当车辆依次通过不同卡口时,卡口会记录下过车时间,通过过车时间的差值即可以计算出车辆这段道路的旅行时间。
在数据预处理基础上,以30 min为时间窗长度构建旅行时间张量,张量中元素总计108864个,表示为 Xr∈ R108×21×48。
4.2 随机缺失填补方法效果分析
为了模拟数据在不同缺失率下的数据表现,构造一个与原始张量Xr相同结构的0-1分布张量B∈R108×21×48,张量中的元素只为0或1,通过设定张量B中0元素的分布概率控制完备张量X0(未发生数据缺失)的数据缺失概率,从而计算得到实验需要的不同缺失率下的原始张量Xr,计算方式如下式所示:
4.2.1 随机缺失填补方法精度分析
本文中选取数据缺失率从10%~40%的场景,各个模型在不同缺失率下的精度指标表现如表1所示。
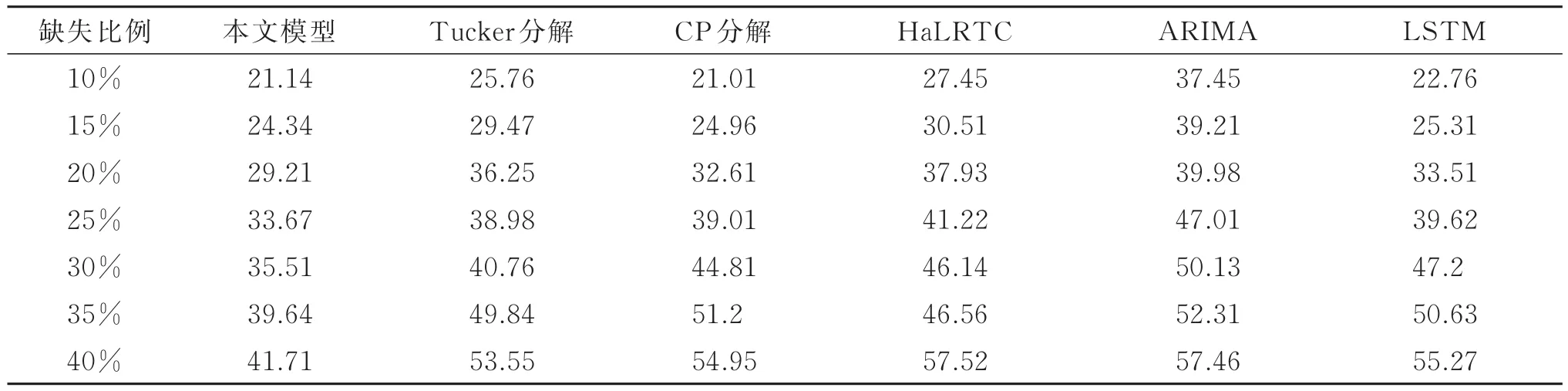
表1 随机化缺失下不同模型RMSE误差/s
图4表示不同模型精度指标的点线图。
整体来看,在低缺失率下几种模型的效果大致相当,在较高的数据缺失率下本文所提出的模型填补效果更为显著,精度提升明显,这是由于在高数据缺失率下,融合历史数据张量可以更好的辅助隐形特征挖掘过程。且随着数据缺失率的提高,传统模型的误差大多在30%数据缺失率处存在拐点,在此处模型误差明显的提高,而本文所提出的模型曲线增长相对平稳,对于数据缺失率的鲁棒性更优。这个实验结果论证了前文的观点,张量分解模型可以通过挖掘交通数据多维度的隐式特征实现高精度的数据填补。
4.2.2 随机缺失填补方法敏感度分析
本小节通过选取不同时间窗长度不同缺失条件进行模型敏感度分析,分析结果如表2所示。随着标定时间窗长度的减小,本文模型的拟合精度逐渐降低。针对同一数据缺失率而言,模型精度存在先增长后降低的趋势。

表2 不同时间窗下模型RMSE误差/s
4.3 纤维化缺失填补方法效果分析
4.3.1 纤维化缺失填补方法精度分析
由图5可以看出,本文所提出方法的散点大致紧密分布在y=x这条直线上,数值在[0,250]区间皆有不错的拟合效果,相较于其他模型方法有着更高的填补精度。
4.3.2 纤维化缺失填补方法鲁棒性分析
为验证所提出模型的鲁棒性,依次模拟原始张量在10%,20%,30%,40%纤维化缺失条件下的数据情况进行实例验证,结果如图6~9所示。
红色线表示车辆通过“缺失的纤维化张量结构”所对应的路段在该日各个时段的实际平均旅行时间,蓝色线表示模型所推断的平均旅行时间。总体而言,本文所提出的模型在受到数据缺失的扰动下,仍能保持较好的拟合效果,尤其是在10%~30%的数据缺失场景下。
5 结 论
本文通过将张量数据缺失结构与实际交通场景映射,挖掘出随机缺失和纤维化缺失两种场景。针对随机缺失场景,构建历史旅行时间张量及其修正方法,并将历史数据修正结果融入张量分解框架,提出一种考虑时间关联性的旅行时间填补方法,解决了高数据缺失率下张量数据结构被破坏而导致模型精度低的问题。针对纤维化缺失高频场景,提出了挖掘与缺失路段时空特征相似路段的方法,在张量分解目标函数内融合相似路段的时空特征,规范张量分解中的因子矩阵迭代的方向与大小,使模型收敛方向逼近纤维化缺失数据。实例结果表明,本文的模型方法精度更高,且受原始数据缺失率影响较小,模型鲁棒性强。
在未来的研究中,将深入探究纤维化缺失下更精确、科学的时空相似路段挖掘方法,期望得到精度更高的旅行时间填补结果。
