基于互联网的爬虫程序研究
2022-02-16郭银芳韩凯郭峰明等
郭银芳 韩凯 郭峰明等
关键词:聚焦爬虫;搜索策略;scrapy框架;全站爬取;分布式爬取
中图法分类号:TP39.3 文献标识码:A
1引言
假设有一个需求——需要得到一个电影介绍网站上的所有电影信息。由于不可能通过手动方式获取大量的数据,因此需要通过分析网页、编写程序进行网页数据的抓取。互联网信息多种多样,如果能够及时了解职位的需求信息,就可以明确学习方向,就业率就会提高。本文以拉勾网为研究对象,对职业信息数据进行爬取并以可视化的结论说明就业需求。
2爬虫的原理及其技术研究
2.1网络爬虫的原理
网络爬虫主要有两种:一般爬虫和聚焦爬虫。一个完整的爬虫一般包含如下三个模块:网络请求模块、爬取流程控制模块、内容分析提取模块。对于聚焦爬虫来说,这一过程所得到的分析结果还可能对以后的抓取过程给出反馈和指导。相对于通用网络爬虫,聚焦爬虫必须解决三个问题:对抓取目标的描述或定义、对网页或数据的分析与过滤、对URL的搜索策略。
2.2网络爬虫技术的分析
2.2.1发送请求
确定要爬取的网页,然后发送请求,就会得到相应回应,其核心的几个要素是:请求header和内容,响应header和内容,url。爬虫首先需要一个初始的url(也可以说是一个网页),将网页的内容爬取后,如果要继续爬取,则需要解析里面的链接。如同一棵树形的结构,以初始url为根节点,其中每一个网页又是一个节点。
在Scrapy中,需要在start_url中写入待发送请求的url:https://www.lagou.com/wn/jobs?px=new&pn=1&kd=Java,并且使用浏览器的网页抓包工具,在服务器的响应header中进行查找,以此确定是否有要获取的信息。
2.2.2 Http请求
一个请求头中包含很多信息——以简单爬取为例,只需要写上User?Agent。以下是浏览器请求头的一部分,“User?Agent”:"Mozilla/5.0(WindowsNT6.1;Win64;x64)AppleWebKit/537.36(KHTML,likeGecko)Chrome/90.0.4430.93Safari/537.36。"2.2.3 Cookie
一般在用户登录或者进行某些操作后,服务端会在返回包中列出Cookie信息要求浏览器设置Cookie。如果没有Cookie,会很容易被辨别出来是伪造请求;由于基于该网站不需要登录操作也可以获取到需要的信息,可以不进行登录操作。
2.2.4 JavaScript加密操作
2.2.5流程控制
所谓爬取流程,就是按照什么样的规则顺序去爬取。在爬取任务量不大的情况下,爬取的流程控制不会太繁琐,很多爬取框架都事先帮用户完成了上述步骤,如Scrapy,只需要自己输入解析代码。
在拉勾网中也有很多ajax技术,由于不是主要信息,在此不做分析。本文主要对html文档本身的信息进行抓取,如Html文档本身包含内容、JavaScript代码加载内容。
处理动态网页可以使用selenium模块,使用该模块可以得到一个浏览器对象,该对象会打开浏览器,并且可以得到网页的全部源码,而且对于处理ifram之类的动态模块也可以简单的切换串口来实现。
2.3 Scrapy概述
Scrapy使用了纯python语言,实现了爬取网页数据、解析数据、持久化存储,为网络爬虫提供了非常便捷的模板。在请求网页方面,也有类似于request或者urllib中的getpost请求。其中,网页分析工具有etree对象中的xpath方法,而且比etree更加方便——可以在得到一个网页的源码之后,直接.xpath使用xpath表达式进行定位。在持久化存储方面,使用管道存储会更加方便。总的来说,此框架继承了多个模块,使得爬虫程序更加高效、方便。
2.4 Scrapy框架爬虫系统的实现
首先创建一个工程,进入工程目录后,再创建一个爬虫文件,然后在爬虫文件中编写想爬取的起始网页。由于一般的网站都会搭载UA检测的反爬检测程序,所以基本上每个爬虫都应该进行爬虫伪装。
在新建的爬虫文件中,我们会发现该文件属于爬虫类,它继承了Scrapy的spider类,在类中可以增加相应的属性。然后,在爬虫文件的parse方法中,可以进行解析数据等相关操作以及使用xpath表达式。
在完成數据解析后,可以获得想要的数据,此时要进行持久化存储。同时,需要用到工程中的item对象,在item对象中写入对应的属性,然后在parse中把数据包装为item对象,然后通过yield关键字进行提交,提交的数据会到达Scrapy中的管道类,最后在管道类中进行存储。
3 基于拉勾网的Scrapy爬虫实现的具体操作
3.1 拉勾网的网页分析
首先,对起始url进行分析。通过浏览器对起始url进行访问之后,可以利用浏览器抓包工具中的网络模块对网页返回的源码进行检查——观察是否有想要的数据。而通过搜索,可以发现在网页源码中有需要的标题、工资及学历要求。
因为是进行全站爬取,所以需要找到所有页面的url。通过在网页源码中进行寻找,可以发现url是隐藏的,由于不能在网页中得到它,所以无法使用crawlspider进行爬取,此时可以使用spider进行直接爬取。为了得到网页的所有url,通过分析可以发现,每页只有一个参数pn不同,因此可以设置一个记录page的变量。通过format可以得到所有的url,然后在parse中进行递归实现。而在start_url中,放入同一层级的url就可以得到所有的url。
url的结构都大致相同,所以可以使用同一个parse方法。
3.2具体代码实现
要爬取拉勾网中的职位、工资和学历要求,可以在pycharm中创建爬虫工程,然后在爬虫文件中进行以下主要代码的编写。
文件:lg.py
importscrapy
from lgPro.items import LgproItem
classLgSpider(scrapy.Spider):
name='lg'
allowed_domains=['www.xxx.com']
start_urls=['https://www.lagou.com/wn/jobs?
px=new&pn=1&kd=Java']
url='https://www.lagou.com/wn/jobs?px=
new&pn=%d&kd=Java'
page_Num=2
def__init__(self):
foriinrange(1,31):
self.start_urls.append(format(self.url%self.page_
Num))
defparse(self,response):
div_list=response.xpath('/html/body/div/div
[1]/div/div[2]/div[3]/div/div[1]/div')
fordivindiv_list:
title=div.xpath('./div[1]/div[1]/div[1]/a/
text()').extract_first()
salary=div.xpath('./div[1]/div[1]/div[2]//
text()').extract()
salary="".join(salary)
salary_and=salary.split('/')
salary=salary_and[0]
edu=salary_and[1]
print(title,salary)
item=LgproItem()
item["title"]=title
item["salary"]=salary
item["edu"]=edu
yielditem
在lg.py中进行请求和解析操作后,可以将得到
的数据提交到管道中。
在items,py中:
importscrapy
classLgproItem(scrapy.Item):
#definethefieldsforyouritemherelike:
title=scrapy.Field()
salary=scrapy.Field()
edu=scrapy.Field()
Pipeline:
fromopenpyxlimportWorkbook
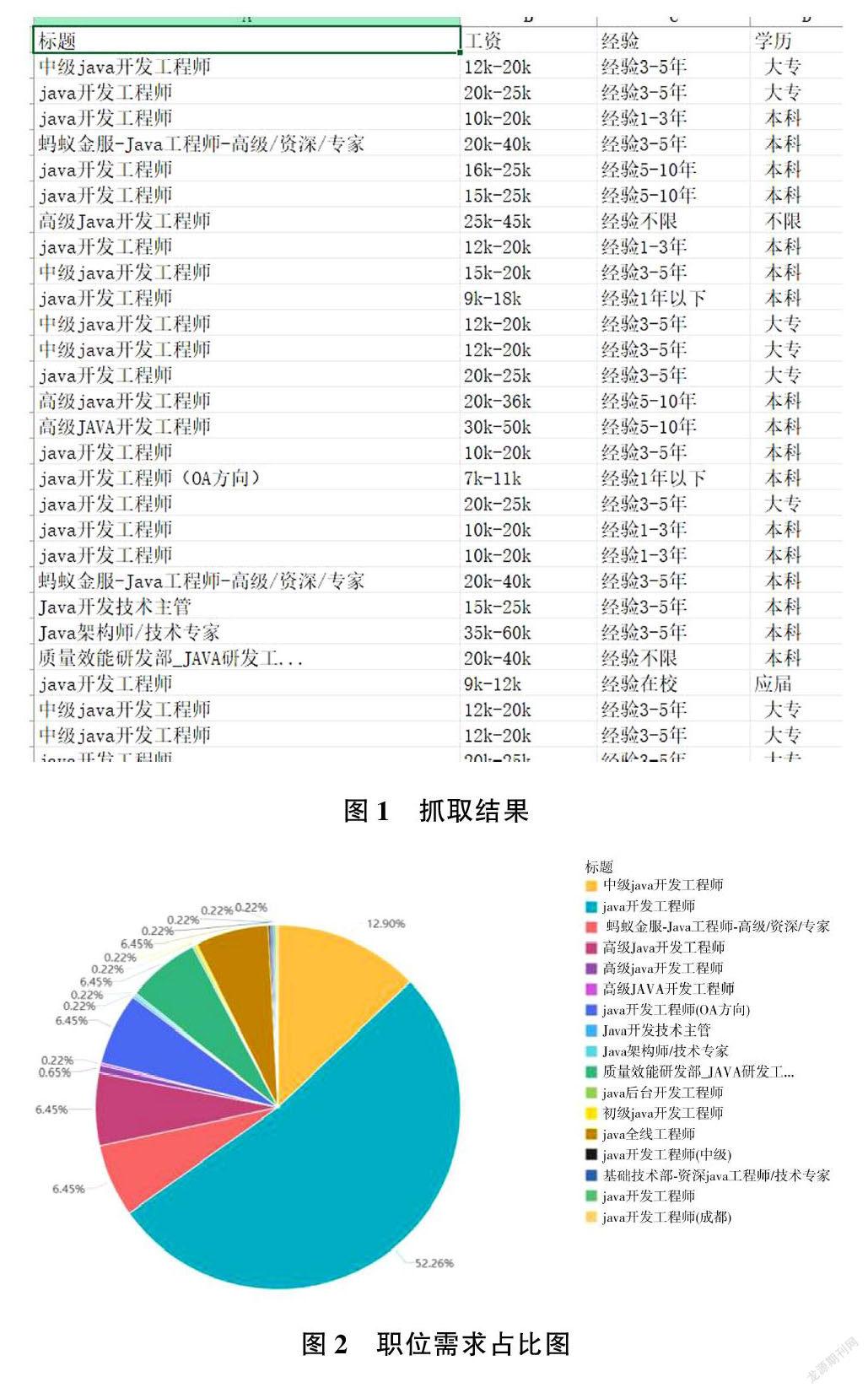
最后,得到爬取结果——数据见图1。
3.3数据可视化
使用百度智能云提供的工具,可以对数据进行可视化操作——结果见图2。
3.4优化
如涉及大规模的抓取,需要有良好的爬虫设计。一般而言,很多开源的爬虫框架都有限制,因为中间涉及很多其他问题——数据结构、重复抓取过滤等。当然,最重要的是要把带宽利用满。
如果对一个较大的网站进行爬取,只用一台机器的效率非常低。此时,可以创建一个分布式机群,据此对这一组资源进行分布联合爬取。同时,需要安装scrapy?redis组件(这是一个被嵌入在Scrapy框架中的数据库)。此外,使用scrapy?redis可以给原生的scrapy框架提供被共享的管道和调度器。如果调度器和管道都是共享的,那么就可以实现多台机器对同一个资源的爬取,并且能够统一存储。
所以,分布式抓取很重要。分布式抓取最重要的就是多台机器不同线程的调度和配合,通常会共享一个url队列,这个队列可以在每台机器上进行抛出。
4结语
从以上分析数据来看:对于Java方面的职业需求,开发工程师占很大的比例,架构师和技术主管则占很小的比例。
将爬取的数据进行可视化操作后,可以得到更加直观的信息。而且数据量越大,数据就越精确。但在爬虫的过程中,或许会遇到三个问题:交互问题,有些网页会判断发出请求是一个程序还是一个正常的用户,由于添加了验证码(滑动滑块之类的验证),爬虫程序遇到这种情况会比较难以处理;ip限制,有的网站会对请求频率进行检测,如果程序请求频率过高,超过了服务器对某个ip的访问次数限制,那么可能会对ip地址进行封禁,这也是一种反爬机制。后台在进行爬取时,由于机器和ip有限,很容易达到上限而导致请求被拒绝。目前,主要的应对方案是使用代理,这样一来ip的数量就会多一些,但代理ip依然有限;在网页源代码中,难以获得更详细的网页url,如果想进一步提取到每个职位的详情信息,需要继续分析。
总之,按照Scrapy的爬虫流程、基于网页的分析,我们得到了想要的数据,证明基于拉勾網的爬虫是可以实现的,而且使用的代码并不算多;基于数据进行分析,我们得出了就业方面的需求。但就出现的问题,仍需继续研究、探讨。
作者简介:
郭银芳(1976—),硕士,副教授,研究方向:数据挖掘。
