如何正确运用χ2检验
——秩和检验与SAS实现
2021-11-04胡纯严胡良平
胡纯严 ,胡良平 ,2*
(1.军事科学院研究生院,北京 100850;2.世界中医药学会联合会临床科研统计学专业委员会,北京 100029*通信作者:胡良平,E-mail:lphu927@163.com)
在对单因素资料进行差异性分析时,若发现资料不满足参数检验的前提条件,宜选用适用面宽的非参数检验。其中,秩和检验可能是常被选用的方法之一。本文将介绍两样本资料秩和检验[1-6]、多样本资料秩和检验[1-6]以及前述两种情形下都可能会用到的10种评分方法[1]。
1 两样本资料秩和检验
1.1 简单线性秩检验
1.1.1 未分层资料的简单线性秩检验
未分层资料的简单线性秩检验的检验统计量[1]见式(1):

在式(1)中,z是一个服从标准正态分布的检验统计量(即随机变量),S、E0(S)和Var0(S)分别代表未分层资料的“简单线性秩统计量”“简单线性秩统计量的期望值”和“简单线性秩统计量的方差”,定义分别见式(2)、式(3)、式(4):

在上述三式中,各变量的含义如下:Rj是第j个观测或个体的秩;a(Rj)是基于第j个观测的秩的得分(注意:评分的具体方法有多种,将在后文介绍);Cj是指示变量代表第j个观测所在的组;n代表总观测数(即总样本含量);n1代表第1组(较小样本含量)样本含量;n2代表第2组样本含量;是平均得分。
基于标准正态分布理论和式(1)计算所得到的z值,可计算出与z对应的正态分布曲线下尾端的概率P值,右单侧概率、左单侧概率和双侧概率分别见式(5)、式(6)、式(7):

连续性校正:当基于Wilcoxon和Siegel-Tukey评分且进行渐近双侧检验时,SAS/STAT的NPAR1WAY过程将默认进行连续性校正,即当式(1)分子的计算结果大于0时,分子减掉0.5;当式(1)分子的计算结果小于0时,分子加上0.5。若想取消连续性校正,需要在“PROC NPAR1WAY”语句中增加选项“CORRECT=NO”。
1.1.2 分层资料的简单线性秩检验
若资料中有一个分层因素(通常称其为重要非试验因素),设其有K(K>2)个水平,在分层因素的每个水平下,试验因素均有两个水平(即两个对比组)。于是,分层资料的简单线性秩检验的检验统计量[1]见式(8):
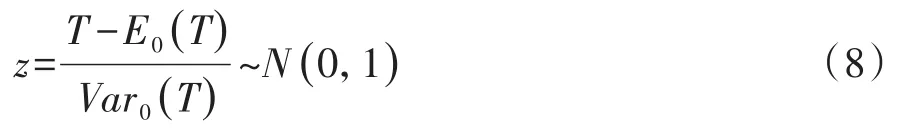
式(8)中,z是一个服从标准正态分布的检验统计量(即随机变量),T、E0(T)和Var0(T)分别代表分层资料的“简单线性秩统计量”“简单线性秩统计量的期望值”和“简单线性秩统计量的方差”,其定义分别见式(9)、式(10)、式(11):
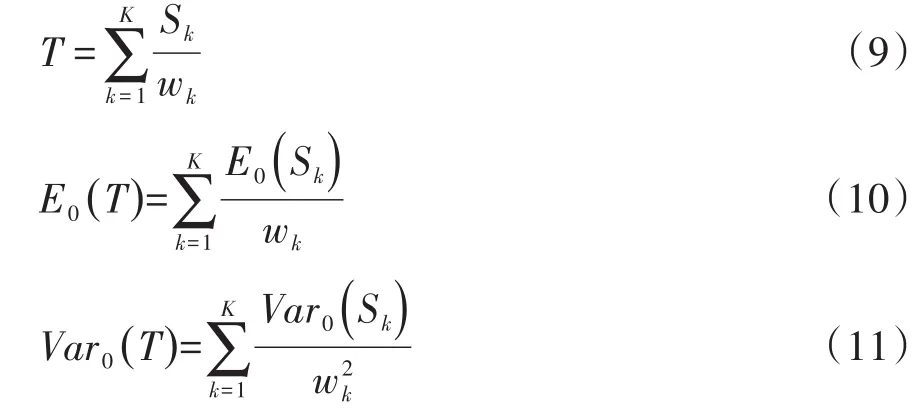
在以上三式中,Sk为第k层的“简单线性秩统计量”,wk为第k层的权重,其定义见式(12):

在式(12)中,nk为第k层的样本含量。如果在“STRATA”语句中,指定“WEIGHTS=STRATUM”,则wk=1/(nk+1 );如果指定“WEIGHTS=EQUAL”,则wk=1。
1.2 Fligner-Policello检验
1.2.1 概述
Fligner和Policello于1981年提出的比较两组定量资料中位数的检验方法[1],被称为“Fligner-Policello检验法”。该法假定每组定量资料服从对称分布,但不要求两组定量资料具有相同的分布,也不要求两组定量资料的方差相等。该法是基于Orban和Wolfe于1979年提出的“配置得分”而构建。设有X与Y两个组,来自X组的观测Xi的配置得分记为P(Xi),其取值定义如下:P(Xi)=Y组中取值小于Xi的数据个数;如果遇到相等的数值,需要对P(Xi)进行校正,即在已知P(Xi)的基础上增加Y组中取值等于Xi的数据个数的一半。对来自Y组的观测Yj的配置得分记为P(Yj),其取值定义与P(Xi)相同。
1.2.2 配置得分的定义
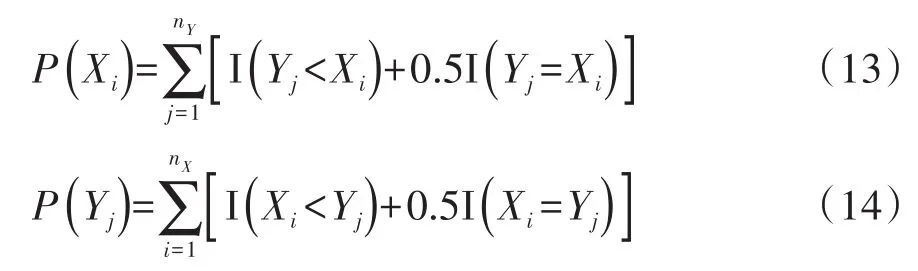
在式(13)、式(14)中,nX和nY分别代表X组与Y组的样本含量;I(·)是指示函数。于是,两组各自的平均配置得分的计算公式分别见式(15)、式(16):

1.2.3 Fligner-Policello检验统计量
Fligner-Policello检验统计量见式(17):

在式(17)中,z是一个服从标准正态分布的检验统计量(即随机变量);VX和VY的计算分别见式(18)、式(19):
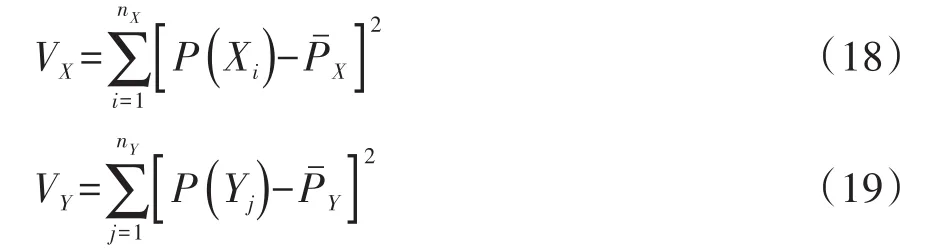
X和Y与两个组的配置得分的标准差分别见式(20)、式(21):

【说明】P值的定义与式(5)、式(6)、式(7)相同,此处从略。
2 多样本资料秩和检验
2.1 概述
对多组定量资料进行比较的秩和检验法常有下面两个名称,第一个叫做“单因素ANOVA检验”;第二个叫做“Kruskal-Wallis检验(采取Wilcoxon评分法)”。其实,它们本质上都属于“χ2检验”。当对多组定量资料进行整体比较时,其检验假设为“H0:各组之间没有差别”。
2.2 多组之间的整体比较
设有一个具有r个水平的试验因素,对定量资料进行r组之间的整体比较时,所需要的检验统计量[1]见式(22):
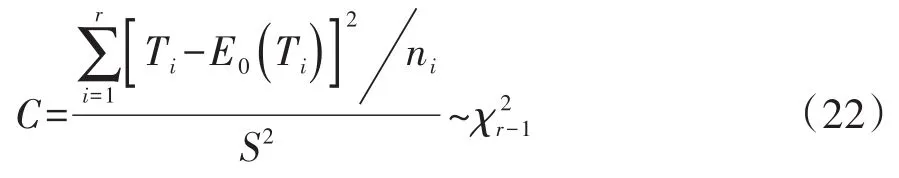
在式(22)中,C是一个服从自由度为df=r-1的χ2分布的检验统计量;ni是第i个水平组的样本含量;Ti是第i个水平组的得分之和;E0(Ti)是在H0成立的条件下第i个水平组的期望秩和;S2是得分的样本方差。Ti、E0(Ti)和S2的计算公式分别见式(23)、式(24)、式(25):
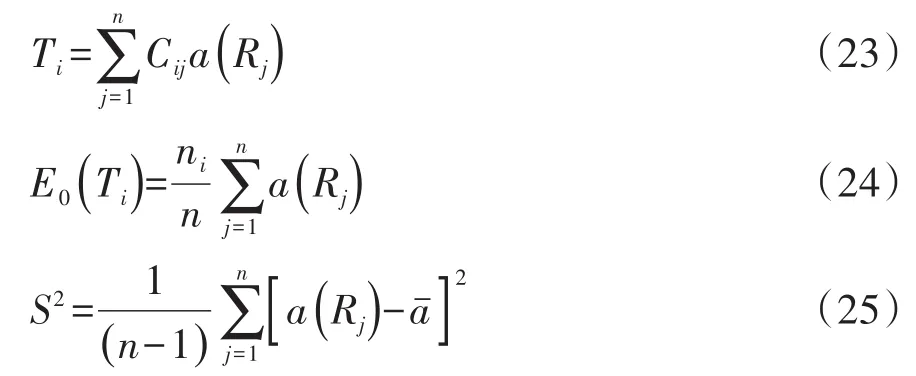
2.3 多组之间的两两比较
2.3.1 概述
由Dwass、Steel、Critchlow和Fligner提出的多重比较方法,简称为“DSCF检验法”。此法从r(r>2)个组中每次抽取两组进行比较,故总共需要比较r×(r-1)/2次。每次比较都基于标准化的威尔科克森检验统计量,即采取威尔科克森法评分,并采用式(1)计算z统计量。
2.3.2 DSCF检验统计量
基于标准化的威尔科克森z检验统计量构造出DSCF检验统计量见式(26):

在式(26)中,z是采取威尔科克森法评分,并采用式(1)计算的结果(注意:每次比较只涉及两组定量资料);而DSCF是一个近似服从于“r个标准正态变量的学生化极差分布”的检验统计量。两样本DSCF比较的P值可以通过下面的方法求出,即将DSCF统计量的值视为学生化极差分布的百分位数,从而,基于学生化极差分布下特定百分位数计算出分布曲线下尾端的概率,即为所求的P值。
3 秩和检验中的评分方法
3.1 概述
秩和检验的一个特点就是不直接利用原始数据,而是先根据原始数据的大小给它们编秩。所谓编秩,就是给每个原始数据赋予一个自然数,代表每个原始数据在一组和整个资料中的“相对位置”。然后再依据不同的数学原理,对每个“秩”进行“评分”或“赋值”。SAS/STAT的NPAR1WAY过程[1]中介绍了十多种评分方法,现呈现其主要内容。
3.2 用于位置比较的评分方法
3.2.1 威尔科克森(Wilcoxon)评分法
威尔科克森评分是观测的秩,可用公式表示如下:

在式(27)中,Rj是第j个观测的秩,而a(Rj)是第j个观测的评分。
【说明】在两样本资料的线性秩统计量中采用威尔科克森评分产生Mann-Whitney-Wilcoxon检验的秩和统计量;在多样本资料的单因素ANOVA统计量中采用威尔科克森评分产生Kruskal-Wallis检验的秩和统计量;对于logistic分布的位置改变来说,威尔科克森评分是局部最有效能的。
3.2.2 中位数(Median)评分法
当资料中的观测值大于中位数时,则该观测的中位数评分等于1;否则,中位数评分等于0。依据观测的秩,中位数评分的定义见下式:

【说明】在两样本资料的线性秩统计量中采用中位数评分产生两样本中位数检验的秩和统计量;在多样本资料的单因素ANOVA统计量中采用中位数评分产生Brown-Mood检验的秩和统计量;中位数评分用于尾部抬高且对称分布时,效能特别高。
3.2.3 Van der Waerden(正态)评分
Van der Waerden评分是标准正态分布的分位数,也被称为分位数正态评分。该评分的计算公式见式(29):

在式(29)中,Φ是标准正态分布的累计分布函数。对于正态分布而言,这些评分的效能极高。
3.2.4 Savage评分
Savage评分是来自指数分布的顺序统计量的期望值,通过减掉1使评分的中心位于0附近。该评分的计算公式见式(30):
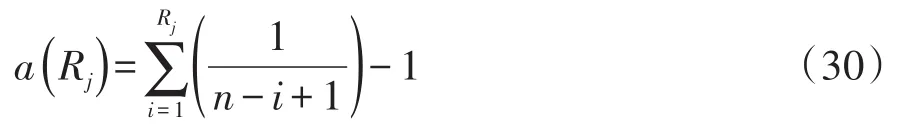
Savage评分在以下两种情形中具有高效能,其一,在指数分布中比较尺度差异;其二,在极值分布中比较位置变化。
3.3 用于尺度比较的评分方法
3.3.1 Siegel-Tukey评分
Siegel-Tukey评分的定义如下:
a(1)=1,a(n)=2,a(n-1)=3,a(2)=4
a(3)=5,a(n-2)=6,a(n-3)=7,a(4)=8,…
这里得分值按此模式朝着中间连续增加,直到全部观测中的每个观测都被赋予一个得分值为止。
【说明】当进行Siegel-Tukey两样本检验的计算时,SAS/STAT中NPAR1WAY过程默认需要进行校正;如果用户不想进行校正,需要在“PROC NPAR1WAY”语句中增加选项“CORRECT=NO”。
3.3.2 Ansari-Bradley评分
Ansari-Bradley评分为对应的极端秩赋予相同的得分,其定义如下:
a(1)=1,a(n)=1,a(2)=2,a(n-1)=2
a(3)=3,a(n-2)=3,a(4)=4,a(n-3)=4,…
等价地,Ansari-Bradley评分可用如下通式表示:
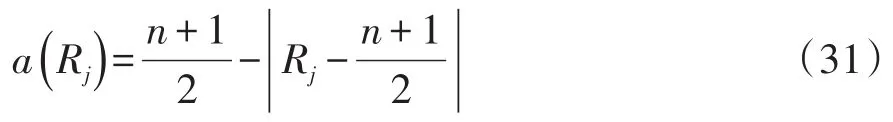
3.3.3 Klotz评分
Klotz评分是Van der Waerden评分的平方,其定义如下:

在式(32)中,Φ是标准正态分布的累计分布函数。
3.3.4 Mood评分
Mood评分按照观测的秩与平均秩之差量的平方进行计算,其定义如下:

3.4 用于位置和尺度比较的评分方法
Conove评分是基于观测值与其样本算术平均值之离差绝对值的秩的平方,对于第j个观测而言,其定义如下:

在式(34)中,Uj的计算见式(35):

在式(35)中,i代表第i个样本(组);j代表第i个样本中第j个观测;Xj(i)代表第i样本中第j个观测的观测值;i代表第i个样本的算术平均值;Uj代表第i个样本中第j个观测的秩。
【说明】Conove于1999年提出,若在第i个样本的全部Uj中出现了相同的数值(称为“ties”),则先按无相同数据编秩(即给予编号),再求那几个相同数据所对应秩的算术平均值,并以此平均值作为它们的“秩”。Conove评分检验也被称为“方差的平方秩检验”。
4 实例与SAS实现
4.1 问题与数据
【例1】某地59例女性类风湿性关节炎患者参加了一项临床试验[1],她们被随机分配进入试验组(n=27)与安慰剂对照组(n=32)。结果变量有5种不同的取值,即“疗效特好=5”“疗效尚好=4”“疗效中等=3”“疗效一般=2”和“疗效差=1”。记录每位患者所接受的处理和疗效的具体取值,临床试验结果以频数表形式呈现,详见后面的SAS程序,此处从略。试对两组有序资料进行秩和检验,以评价两种治疗方法的效果差异是否有统计学意义。
4.2 SAS实现
4.2.1 对例1的SAS实现
【分析与解答】设所需要的SAS程序如下:


【程序说明】“从ab到fp”这10个选项是秩和检验中的10种评分方法;其中,“fp”是前文介绍的Fligner-Policello检验法。
【SAS输出结果及解释】因篇幅所限,以下仅呈现“威尔科克森检验结果”,其他检验方法输出的结果从略。

以上是威尔科克森检验输出的第1部分结果,即输出两组描述性统计量的计算结果,治疗组的平均秩为37.00分,对照组的平均秩为24.09分。

以上是威尔科克森检验输出的第2部分结果,即以标准正态分布为理论根据计算得到的结果,双侧检验的P=0.0046<α=0.05。

以上是威尔科克森检验输出的第3部分结果,即以χ2分布为理论根据计算得到的结果,P=0.0031<α=0.05。
【统计结论与专业结论】由输出结果可知,前4种检验方法和第10种检验方法给出的检验结果均为P<0.05,说明治疗组与对照组疗效的“平均秩”或“中位数”之间差异有统计学意义;由于治疗组的“平均秩”或“中位数”大于对照组的“平均秩”或“中位数”,又因评分值越大标志着疗效越好,故可以认为“active”治疗方法的效果优于安慰剂。
第5~8种检验方法的检验结果均为P>0.05,说明治疗组与对照组疗效的“离散度(即尺度参数)”之间差异无统计学意义,即两组有序资料的变化范围接近一致。
第9种检验方法的检验结果为P>0.05,说明治疗组与对照组疗效的“位置参数”和“离散度(即尺度参数)”综合的指标之间差异无统计学意义。
5 讨论与小结
5.1 讨论
秩和检验有两个优点:其一,对资料的要求不高;其二,选择不同的评分方法可以分别实现“位置参数(如平均值、平均秩、中位数)”“尺度参数(如标准差、分位数间距)”和“位置参数以及尺度参数”的比较。其缺点在于:不适合分析多因素资料。为了保留对资料要求不高的优点,又能够处理多因素资料,需要选择复杂的非参数统计分析方法[6-8]。
5.2 小结
本文介绍了适用于分析单因素资料的秩和检验方法,包括分析单因素两水平设计资料的“简单线性秩检验”和单因素多水平设计资料的“单因素多水平ANOVA检验”。详细介绍了在前述两类检验中都不可缺少的10种评分方法。通过一个实例并借助SAS软件,实现了单因素两水平设计资料的简单线性秩检验,呈现了10种评分方法计算所得到的结果,对输出结果作出了解释,并给出了统计结论和专业结论。
