基于注意力机制的LSTM液体管道非稳态工况检测
2021-10-27于涛张文煊
于涛,张文煊
(1.国家管网集团数字化部;2.昆仑数智科技有限责任公司)
0 引言
长输液体管道利用SCADA(数据采集与监视控制)系统实现远程调控运行,运行过程中对异常工况的发现处置,均由调控人员根据设备状态量报警信息及压力、流量等参数阈值分析确定。一般而言,液体管道的判断分析处置时间较短,对调控人员的业务技能、事件应急能力、工作状态等要求较高;尤其是对于泄漏等工况,若不能及时发现,将影响后续工况的识别和应急处置,从而危及管道运行安全,严重时可能产生较大的次生灾害,进而造成环境污染等问题。同时,工况实时检测是未来管道智能化的前提,只有实时性、准确性提高后,检测结果才可用于后续管道的工况智能识别和控制。
近年来,随着管道SCADA系统的推广应用,信息传送、数据收集存储等方面的完善提升,企业积累了大量的实际生产数据。长输油气管道生产数据具有工业大数据的“6V”特性[1],同时具有更强的专业性、关联性、流程性、时序性和解析性等特点。国内外学者利用数据驱动智能应用和控制,实现了工业设备监测[2]、工况识别[3-4]、参数预测等功能[5-6]。可见,探索基于数据驱动的算法模型,研究油气管道非稳态工况检测和智能识别是未来管道智能调控的方向[7-8]。
目前对于油气管道异常工况的研究多侧重于泄漏工况的识别与特征提取[9-11]。武瑞娟[12]通过实验模拟传感光纤主体在输油温度和应力变化环境中的监测稳定性、精度,实现管道泄漏的检测;陈志刚等人[13]提出基于多元支持向量机的管道泄漏诊断方法,并建立了识别模型,实现多种工况下对压力波动信号的分类识别,从而提高泄漏工况识别准确性。当前学者的研究成果主要针对特定设备与泄漏等工况,没有将管道非稳态工况作为整体纳入研究,无法应用于未来管道工况的智能识别与控制。本文利用 LSTM(长短期记忆网络)可学习并记忆序列长期信息的优点,提出了一种基于注意力机制的LSTM时间序列预测的算法,该算法可用于长输液体管道非稳态工况检测。
1 理论和方法
1.1 算法原理
1.1.1 LSTM网络原理
LSTM是RNN(循环神经网络)的一种变体,由于其弥补了RNN的梯度消失或爆炸,以及长期记忆不足的问题而被广泛使用于各个领域[14-16]。每个LSTM单元包括输入门i(t),遗忘门f(t),输出门o(t)以及两个神经元状态c(t)和h(t)。LSTM神经元的前向传播计算过程见式(1)~式(5),其中W和b为相应权重。
在时间序列分析中,深度学习通常由多层LSTM单元来实现,即每一层的输出作为下一层的输入。循环神经网络的训练通过基于时间的反向传播算法实现,包括以下几步:①前向传播计算神经网络的输出;②计算误差并在深度和时间两个方向上反向传播至每个神经元;③计算每个权重的梯度;④根据梯度更新权重。求解过程可以由多种梯度最优化算法实现,如,随机梯度下降 AdaGrad、Adam、RMSProp等。
1.1.2 注意力机制
针对 LSTM的 Encoder-Decoder(编码-解码)框架因中间码保存的信息量有固定上限,当输入信息量大于中间码时,导致信息丢失解码准确度下降,陶云松等学者引入注意力机制用于图像处理[17],其本质是对感兴趣的特征中的每个特征用 softmax函数打分。通常注意力机制的输入是当前状态h(t)和侧重关注的f=(f1,f2,···,fn),输出是对n个特征的softmax打分s=(s1,s2,···,sn),在后续处理中,使用该打分功能进行过滤[18]。
增加注意力机制可看成在单独的编码、解码器框架上,增加了一个单层RNN,输出数据对应输入数据的注意力权重,不仅受输入数据的隐藏层决定,还取决于前一个数列的隐藏层,通过softmax获得概率值,如式(6)~式(8)和图1所示。
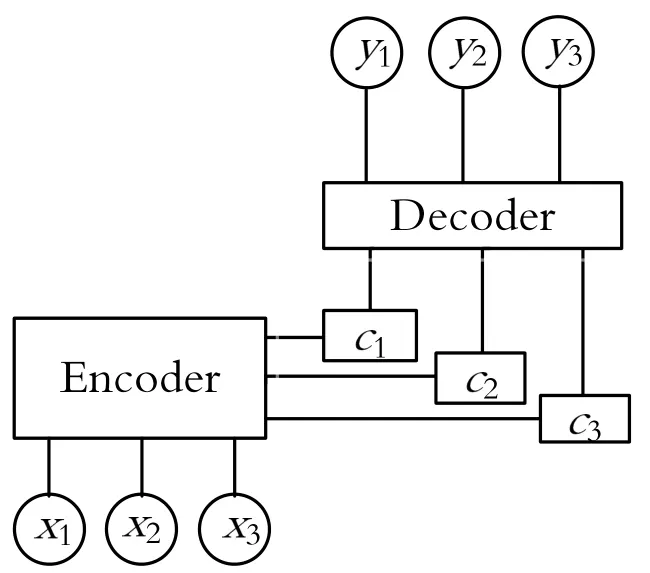
图1 包含注意力机制的编码、解码框架
首先,单独计算si-1与每个隐层状态h一个数值,再通过softmax获得i数据对应的Tx个编码时隐层状态内的注意力权重分配,从而求出ci分配向量权重。如式(9)~式(11)和图2所示:


图2 编码器解码器结构图
1.2 非稳态工况检测模型架构
根据液体管道SCADA系统数据特点,非稳态工况检测研究架构如图3所示。

图3 非稳态工况检测模型结构图
非稳态工况检测模型包含两部分:一是使用一个基于LSTM的时间序列预测模型学习正常数据的行为模式,并对未来数据给出时间序列预测;二是通过建立注意力机制调整模型输出值,对预测数据与实际数据的误差进行评分,给出是否异常的分类。基于注意力机制的LSTM网络结构如图4所示,其具体实施过程如下:
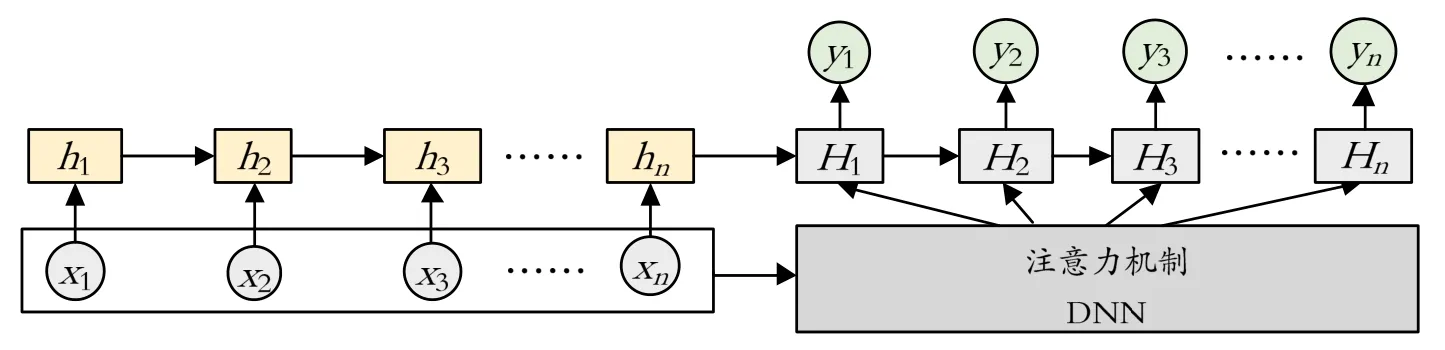
图4 基于注意力机制的LSTM网络结构
首先,LSTM作为时间序列预测模型,使用当前时间的前一时间点作为输入值,后一时间点作为输出值,输出层的维度与管道的数据集特征维度相符。由于模型用于回归问题的训练,本文使用线性激活函数,并使用MSE作为损失函数。
其次,使用深度神经网络实现注意力机制,利用注意力机制调整模型输出,增强模型应对多种数据变化模式的能力。深度神经网络由3层全连接层构成,维度与 LSTM模型的神经元输量一样,使用 Sigmoid函数作为激活函数,并使用MLE(极大似然估计法)作为损失函数。
最后,模型输入参数5个维度,隐藏层100节点个数,循环50次数,学习率0.001。
工况检测模型的训练基于如下假设:一是利用稳态运行数据训练的LSTM模型,模型工况检测时,在工况数据区间上给出的预测误差应比正常数据上的误差更大,从而可使用平均对数误差对预测误差进行评估,指导调整 LSTM输出结果;二是模型的预测误差符合高斯分布。
1.2.1 算法步骤
将样本数据分为四组进行训练和验证:①训练集N,仅包含正常数据;②验证集VN,仅包含正常数据;③验证集VA,同时包含正常与异常数据;④测试集T,同时包含正常与异常数据。
(1)N被用来训练检测模型;
(2)使用验证集VN防止训练早期出现模型的过拟合;
(3)对N上的预测误差使用注意力机制进行训练,并使用MLE对误差进行评估;
(4)对检测模型的预测结果在VA上再次进行训练,并更新注意力机制的权重;
(5)根据模型的输出结果设定非稳态工况阈值,对输出进行二值化处理;
(6)使用测试集T估计模型的效果。
在算法中,使用 Adam优化器对模型超参数进行训练,并根据模型效果对训练集的大小与窗口进行调整与优化。
1.2.2 MLE估计非稳态工况得分
假设时刻ti非稳态工况得分pi随重建误差ei呈高斯分布[19],即p~N(μ,Σ)利用MLE在数据集NV1上对参数μ,Σ进行估计。MLE参数估计步骤如下:
(1)假设异常概率p与重建误差e呈高斯分布,则时刻ti正常的概率pi如下:

(2)对似然函数取对数并求和如下:
(3)对H(μ,Σ)求偏导:
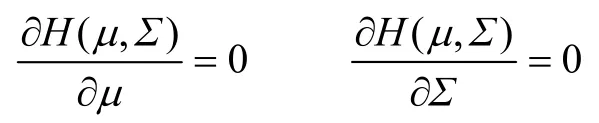
(4)求解获得参数数据估计值如下:

(5)非稳态工况得分如下:
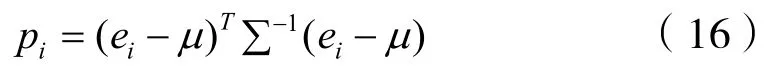
1.2.3 非稳态工况判定
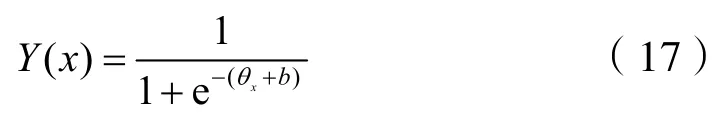
式中:Y——决策值;x——特征值。对于常见二分类,逻辑回归通过一个区间分布进行划分,即:如果Y值大于等于0.5,则属于正样本,如果Y值小于0.5,则属于负样本。判别函数如下:

建立模型的目标是保证各类工况的检测率,同时尽量筛选出更多的稳态工况数据,即在其他工况召回率100%的情况下,尽量提高正常运行数据的召回率。
1.3 实验过程
1.3.1 数据准备
本文使用SL原油管道SCADA系统实际生产数据作为模型训练验证样本,数据点包括各个站场重点监控的变量,包括各站的进出站压力、流量以及主泵汇管的进出压力,管道站场设置及数据采集点如表1所示。各管道数据采集自2018年2月至11月,选取记录两个管道操作较少的时间段:5:00—6:00和19:00—20:00,每次持续1 h,采样频率为1 s,由业务人员对数据进行梳理,剔除异常值及稳态工况值,提升数据的质量。
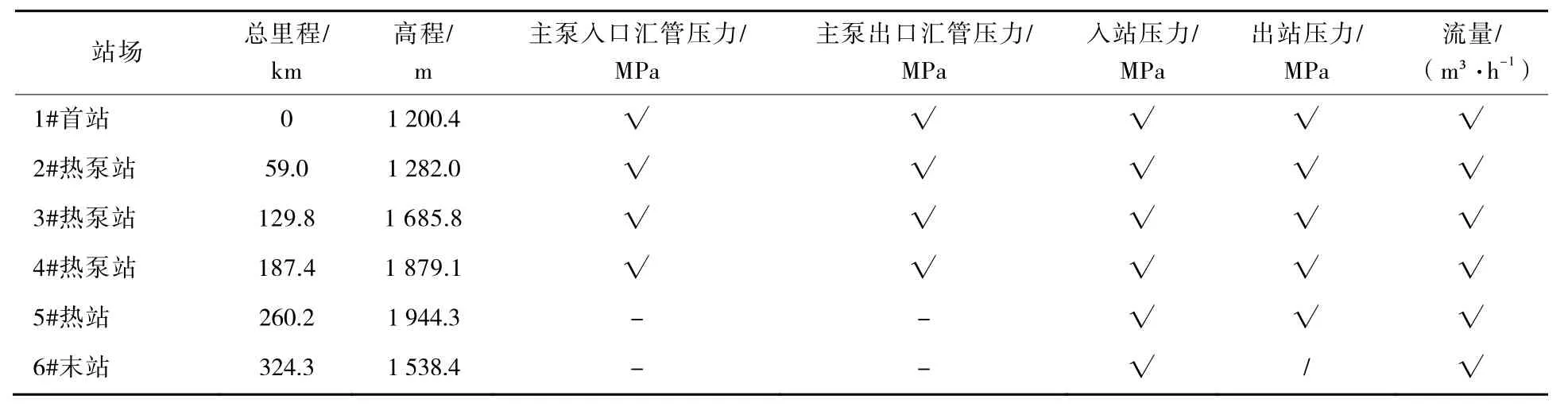
表1 SL原油管道站场参数及数据采集点
1.3.2 数据预处理
由于采集数据的分布随时间差异较大,首先进行数据标准化。具体过程为,将各变量映射至零均值、单位标准差的分布上,计算公式如下:

式中:μ和σ取样本x当月及所在昼夜对应样本集的均值和标准差。通过此标准化过程,保证数据分布在不同时间段大体相似。
1.3.3 模型评价标准
本文采用Recall(召回率)作为模型性能评价指标,表示的是样本中的正例有多少被预测正确,即:使用所有样本数据作为分母,检索到的作为分子,计算公式如式(20)。利用Accuracy(准确率)表示预测结果的准确度,针对预测结果而言的,表示预测为正的样本中有多少是真正的正样本,计算公式如式(21):
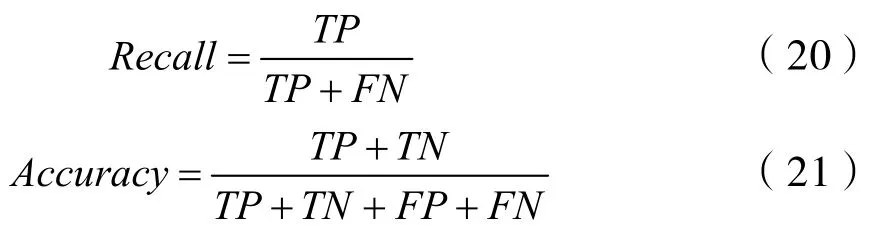
式中:TP——正类预测为正类数目;FP——负类预测为正类数目;TN——负类预测为负类数目;FN——正类预测为负类数目。使用分析速度作为模型效率评价指标,反映若模型在部署至真实环境下时所需的系统资源开销以及可能带来的延迟。
2 结果和讨论
2.1 模型测试分析
使用实际生产数据验证预测模型,并与RNN、one-class SVM与IF(孤立森林)等在机器学习领域常用的非稳态工况检测模型进行对照实验。各模型均使用表1的数据进行训练,选择使用SL原油管道在2019年6月的生产运行数据进行测试。测试结果如表2所示,其包括下载燃料油、切罐及甩泵等工况数据,实现管道压力快速剧烈变化和较小变化的捕捉,通过下载燃料油模拟管道泄漏工况,利用模型将不同工况非稳态的水力特点与正常工况进行识别区分,实现压力的异常检测。

表2 模型对比分析
由表2可知,RNN与one-class SVM两种模型对下载燃料油的预测误差较大,切罐和甩泵的准确率和召回率均较好,说明RNN和one-class SVM对于稳态工况数据的学习效果较好。但对于下载燃料油工况这两种模型的准确率较低,实验过程中尝试多种窗口和批量大小,仍然无法改变两种模型对下载燃油工况的判断精度,经分析主要原因可能在于下载燃料油的持续时间过长,以及压力、流量变化相对平缓,导致无法将下载燃料油工况的开始阶段与正常运行数据有效区分。Isolation Forest对工况检测的检测精度最低,无法实际应用。
相比其他模型,基于注意力机制的 LSTM模型不仅能够更好地记忆稳态工况的状态与模式,还不受长时间工况与复杂变化的影响,模型对数据的变化状态与正常工况进行比较和计算,最终达到准确率100%的效果。
2.2 模型实际应用
利用构建的工况检测模型,识别SL原油管道甩泵、下载燃料油工况,其工况趋势图和预测偏差,如图5、图6所示。
由图5、图6可知,将基于注意力机制的LSTM工况检测模型用于实际工况检测,通过设定实际值与模型预测值的偏差阈值(本实验的阈值为0.03 MPa),可实现工况的实时准确检测。
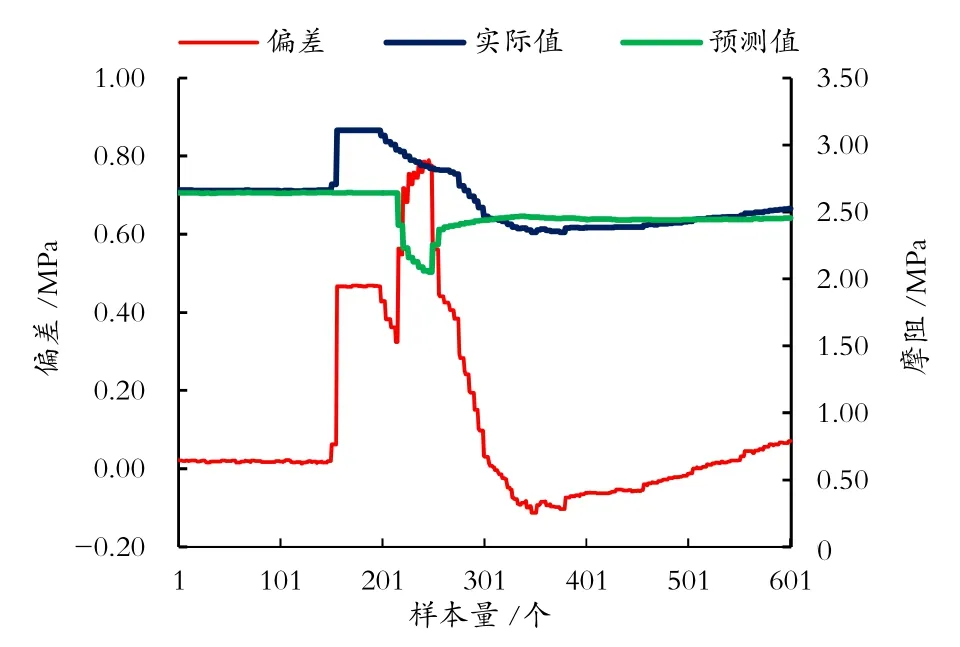
图5 SL管道2#泵站甩泵工况
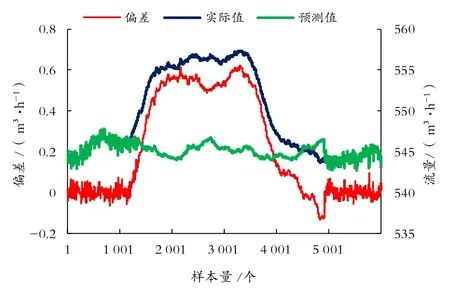
图6 SL管道2#泵站下载燃料油工况
3 结论
根据原油管道工况发生后的数据特点,提出了利用LSTM神经网络对参数重建的工况检测方法。针对LSTM神经网络在输入信息量大于中间码时,导致信息丢失解码准确度下降等问题,提出了利用注意力机制提高模型准确性的方法。使用LSTM神经网络预测管道的未来数据,利用注意力机制调整模型输出值,对预测数据与实际数据的误差进行MLE评分,设定评分阈值,利用二分法区分阈值实现工况的实时检测,最终研究建立了基于注意力机制的LSTM工况检测模型。
基于注意力机制的 LSTM网络结构既保证了稳态工况的数据可以长时间不受复杂变化的影响,同时还可以有效的对非稳态工况数据进行比较计算,提升预测准确率。
非稳态工况检测模型实现了稳态工况和非稳态工况的有效区分,模型的准确应用是工况智能识别的研究前提,其可有效降低工况智能识别模型的系统资源开销,提高模型运行效率。
