基于语义网技术的海量数字档案智能挖掘方法
2021-10-22谢晖
谢 晖
(菏泽医学专科学校,菏泽 274000)
在文化的传承和社会发展中,档案记录与保存有着重要意义。随着时代的变迁,档案记录与保存也在不断变化与发展,逐渐形成了现今这种分类体系明确的不同等级档案馆[1-3]。档案不仅包括个人的学籍资料和人事资料等,还包含企业公司信息文件。档案文件种类繁多,纸质档案的保存形式已经不能满足现今档案记录产生的速度,因此,各级档案馆均已开展数字化工作,建立了相应的电子档案库以及档案网站供公众使用,但是能做到全文检索的少之又少[4-5]。对于这种情况,国内外研究学者研究数字档案智能挖掘方法,利用高新技术在海量数字档案中挖掘出有价值的档案,如遗传算法和支持向量机的应用,但是这两种技术的应用局限于简单的电子化,在理解关键词中只能理解词语的概念,难以发现词语之间的潜在逻辑,导致挖掘的数据之间关联性不强[6-8]。因此,可以应用语义网技术,设计基于语义网技术的海量数字档案智能挖掘方法。语义网是一种智能网络,利用该技术更深层地理解关键词之间的逻辑关系,可以使挖掘的数据关联性更强,使交流变得更有效率和价值。
一、基于语义网技术的海量数字档案智能挖掘方法
(一)聚合数字档案资源
数字档案资源种类繁多,各类资源之间存在较强的语义关系。通过语义网技术挖掘出各种不同类别档案的内在联系,并将存在关系的档案通过语义网技术连接在一起,实现资源聚合[9]。数字档案涉及的种类比较多,以学科电子档案为例,档案资源有科研团队、条件设施和规章制度等。这些资源之间具体联系,如图1所示。

图1 学科电子档案各类资源关系
从图1中可以看出,电子档案各类资源之间存在较强的关联,这些关联关系的存在,使得电子档案资源的语义关联和聚合成为可能。在对数字档案资源的语义关系和聚合与服务的支撑技术分析的基础上,利用关联数据框架实现数字档案资源的聚合,如图2所示。
图2中显示的框架能够引导数字档案数据的创建与发布,在聚合框架中,借助档案语义描述的本体或词表,实现资源的语义关联,再利用档案资源关联数据创建、聚合数字档案资源[10]。采用图2显示的聚合框架流程,按照从底层到顶层的顺序,基于关联数据逐层实现数据资源的聚合,从而完成整个数字档案资源的聚合。在聚合完成后,基于语义网技术构建档案知识库。

图2 数字档案资源聚合框架
(二)构建档案知识库
构建档案知识库的主要目标是借助本体技术将数据库内知识概念化,通过语义网挖掘出档案记录中各个项目的内在联系,如事件和任务。在已知各类档案记录内在联系的基础上,即可根据关联程度形成具有知识关联网络的知识库。通过档案知识库,能够更好地帮助用户获取和利用档案知识,也能享受到资源共享的知识库服务[11]。
构建的档案知识库采用分层架构体系结构,主要分为资源层、知识组织层和应用层,分层的主要依据是档案知识库中数据的流向和数据的处理。档案馆馆藏资源原始数据再经过知识抽取本体组织得到互联的知识网,再利用语义网技术将用户检索需求与知识库内容相匹配,通过可视化技术将数据呈现给用户[12]。
馆藏资源层中包含很多含有语义解释的档案数据和资源,这些档案数据和资源有不同的种类,是通过拍照或扫描等方式处理后获得的,通过数字化技术转化为数字资源存储在数据库中。数据中包含档案源文件数据库以及音视频数据库[13]。依据知识库的分层体系结构,可知馆藏资源层是整个体系结构中的数据来源,通过结构中的知识组织层处理档案数据,如语义分析、关系抽取等,处理完成后将资源传递给功能应用层。应用层中包含档案资源的属性特征,主要表现为网状知识结构,档案资源本体在对档案数字资源进行映射后,形成符合知识本体框架结构的实例库。根据用户的实际需求和数字档案管理的实际需求,在应用层中开发出相应的功能块和应用接口,实现对档案数字资源的调用与管理[14]。
在档案资源数据检索中,主要利用知识本体和推理规则实现。其中,知识本体明确了档案记录的种类、属性和内在关系,通过计算检索词与知识概念间的相似度,即可实现数据检索,将符合检索条件的内容呈现给用户。但是这时返回给用户的结果中可能存在部分无用数据,因此通过挖掘后将关联性较强的数据再传递给用户。
(三)挖掘数字档案
根据现有档案知识库,使用决策树算法实现数字档案挖掘,依据离散属性—值对,将档案知识库中的数据分割成若干个小型样本数据集。将决策树结点改造成能够满足样本数据集需求的结构,将改造完成后的决策树结点分为贝叶斯结点和普通叶结点[15]。
在挖掘数字档案资源过程中,根据档案资源数据生成叶结点,为避免出现匹配过度的情况,设置一个阈值,计算划分前的结点差异值的度量,将计算结果与阈值相比较,若大于阈值,则进行进一步挖掘;反之,计算结果小于阈值,则生成叶结点。重复上述过程,如果有i个实例数据要规划到当前结点,并且其中有i1个实例属于分类k,它们最可能的分类是G,则可以得到G与i1的关系:

此时生成初始决策树,将获得的实例集合G作为输入,分别计算结点的差异度,并与阈值相比,选择集合中分布期望做小的属性—值对B,返回一个与其对应的样本数据集合并输出,该集合即为挖掘的数据集合。
在上述过程中,算法会不断将新的档案实例与决策树中划分的属性相匹配,判断该实例是否正确划分,若已经被准确划分,则进行下一例,重复上述过程。直到所有实例均已划分完成,实现数字档案挖掘。若实例划分错误,则结合该实例对该节点的贝叶斯参数进行更新修正,如此不断地更新修正,直到实例划分正确,完成挖掘。至此,设计的基于语义网技术的海量数字档案智能挖掘方法完成。
二、海量数字档案智能挖掘方法实验研究
(一)实验准备
在海量数字档案智能挖掘方法实验研究中,选取某省档案馆馆藏某劳动厅全宗作为研究对象,主要包含各个不同时期的档案资料,共计400多个卷宗。档案馆对这些档案的分类方式以年度—问题方式为主,主要包括综合性档案、劳动保护、劳动工资等内容。
基于原有的档案,构建出档案本体,因本体范围较大、类目层级过多无法构建全部档案,考虑实验的实际需求,从多个类别选择部分档案构建本体。主要从主题、责任者、时期、地域、日期和档案资源格式这六个方面构建,将构建完成的数字档案作为实验对象。使用不同的数字档案智能挖掘方法挖掘档案中的数据的关联性。计算档案数据之间的支持度和置信度,并利用第三方软件输出某关键数据的并发性。通过以上结果分析不同的数字档案智能挖掘方法的实际性能。支持度和置信度计算公式如下:
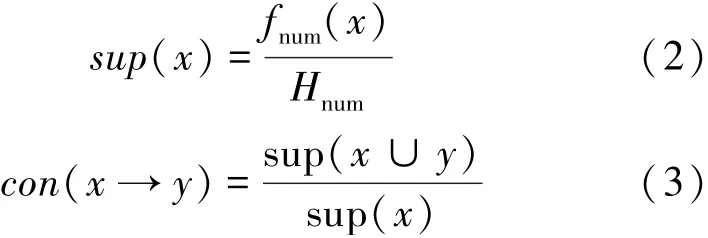
公式中sup(x)表示数据x的支持度,con(x→y)表示数据x与y的置信度,fnum表示数据x在挖掘出的档案数据中出现的次数,Hnum表示挖掘出的数据总量。通过上述公式计算出不同挖掘方法数据的支持度和置信度,结合数据的并发性分析挖掘方法关联水平的高低。
(二)支持度与置信度实验结果与分析
随机选取档案中关键词,使用不同的挖掘方法挖掘出相关数据,计算该关键词的支持度与置信度,结果如表1所示。
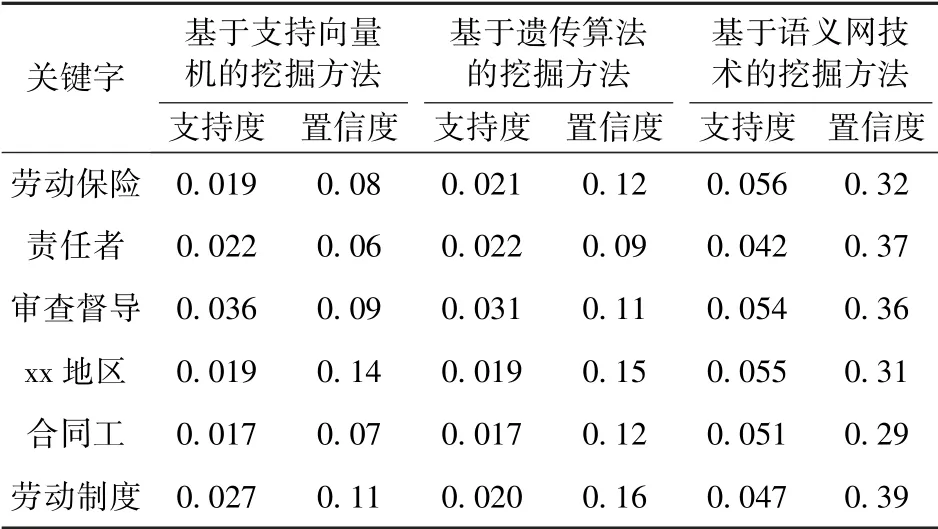
表1 支持度与置信度计算结果
观察表1中数据,支持度表示挖掘方法中挖掘数据在整体数据集中的比率,置信度表示挖掘的数据与选择的关键词之间的关联程度。从表1数据可以看出,在不同的关键词中支持度和置信度较高的都是基于语义网技术的挖掘方法,两个指标均高于另外两种方法,这是因为语义网技术的应用解决了以往使用的挖掘方法中的问题,在数据之间建立较强的联系,挖掘出的数据关联性极强。
(三)并发性实验结果及分析
在上述实验的基础上,随机选择某一关键词,利用第三方软件将不同挖掘方法的该关键词的关联关系展示出来。
图3中显示的点表示与关键词相关的数据,线段的长短表示并发性。从图3中的结果可以看出,基于语义网技术的数据挖掘方法关联的数据点更多,并发性更强。结合支持度与置信度数据可知,设计的基于语义网技术的海量数字档案智能挖掘方法关联性更强,挖掘出的数据更能满足实际应用的需求。

图3 不同挖掘方法的数据并发性实验结果
三、结语
随着互联网络的飞速发展,档案数字化逐渐完善,海量数字档案的智能挖掘成为当前研究的重点。在本文研究中,利用语义网技术发现数据中潜在的逻辑关系,构建档案知识库,在档案数据间建立更加牢固的关联,保证挖掘结果的可靠性和适用性。但是研究中依然存在不足之处,如语义研究中很大一部分是基于本体,受到的限制比较多,在后续的研究中仍然需要投入更多的精力研究这一问题。
