在Matlab R2015中定制词云图
2021-09-29史文崇
史文崇
(河北科技师范学院 数学与信息科技学院,河北 秦皇岛 066004)
0 引言
“词云”一词由美国学者Rich Gordon提出,曾称“标签云”,也有人称作“字云”[1].词云图是近年来兴起的数据可视化工具之一,可以直观地反映科技文献中许多关键词的出现频次的对比情况.某词条文字越大,说明其出现频度越高.目前许多技术可以生成特殊轮廓的词云图,如地图形、动物轮廓形、人物头像形等.生成词云图的途径或工具也有很多:电脑版的有WordArt、Wordle、图悦网、易词云网、优词云网、微词云网等;手机版的有字云生成器、美字云、字云等软件;一些大型软件如Python、Matlab等,近年来也纷纷推出词云库或词云函数[2-3].这些途径生成的词云一般密度较大[4],但多有词条文字套叠现象.一些词云图工具只侧重审美和艺术化[5],忽视了其原本的统计学意义;有的只有词频大小排序,却没有具体词频数据[6];有的甚至连词频大小顺序也无须输入,已演变成游戏、娱乐活动[7].必须指出,密度过大、文字套叠严重,致使词条不易辨认或词条重复、词条被拆散的,已经失去了统计学使用价值;而词条文字显示残缺,词条过少或过于松散,其艺术性和实用性都不复存在.
为了提高词云图的统计学使用价值,词条首先要易于辨认.不是越密越好,不能为了提高密度刻意使文字套叠,牺牲可辨识性[8].保持适当的间隔是必要的,只需防止过于稀疏即可.另外,在词云图中,虽通过词条字体大小表示其频度,但当两个词条词频差异较小时,仅靠文字大小已不易辨识,还应通过其位置、颜色等属性辅助表征其不同频度;同时必须杜绝文字残缺、显示不全的现象.要达到这些目的,一般以圆形轮廓词云图更易于实现,也更便于使用,即中心点的词频最高,越是远离中心点的词条,其频度越低.
1 基本思路
本文研究在Matlab中生成词云问题.Matlab是优秀的大数据处理和机器学习软件之一,也有优秀的绘图功能,尤其是其图形(图像)色彩处理、图形中的文字处理功能非常强悍[9-10].Matlab自2017年版(仅可在64位机运行)起已有词云函数wordcloud.首先尝试用该函数得到词云图.现有关于某项研究的关键词词频统计数据,内含76个关键词——有二、三、四字中文词汇,也有英文词汇和缩略语.词频最高的为“字云”,最低的为“框架”.实验表明,即使将wordcloud.m文件复制到低版本的Matlab软件(如32位机可安装的最高版本Matlab R2015b)的相应文件夹,也不能得到词云图,说明该函数的软、硬件局限性;而在Matlab R2018环境中,用wordcloud函数绘出的相应词云图,如图1.不难看出,该词云图色彩单调,看不出艺术价值;有些词条已经小到难以识别;一些词条文字大小相同,很难辨别哪个频度更高——统计学价值也明显不足.总之,该函数的实用性不能令人满意.

图1 用Matlab 2018的wordcloud函数生成的词云图
这里尝试在Matlab R2015b环境(32位机)生成较为理想的词云图.Matlab R2015b可轻松实现词频数据的批量导入,自动排序,其text函数可按指定位置、大小、色彩、旋转角度显示指定文本内容,为生成词云图提供了便利.设定中心点为频度最高的词,其他词绕其顺时针(或逆时针)旋转,在其外围依次出现,随词条频度降低,字号逐渐减小,颜色发生改变.依此原理生成词云图,问题的核心是各个词条显示位置、文字大小、旋转角度、颜色的确定.难点在于既要防止重叠,又不能使得分布过于松散稀疏;要使得词云图轮廓形成平滑的圆形;文字应呈现五彩缤纷的颜色,以增强其美感.
2 分析与实现
2.1 各词条输出位置的确定
因为词云图采用圆形轮廓,可定义从内到外每个圆周呈现的词条数,内圈点位用完后,逐渐拓展到外圈,随着圆周半径增大,词条数增加.如此循环若干周,直至处理完所有词条.
最理想的做法是初始圆半径和初始旋转角度均按某种规律递增.但由于每个词条的字数往往并不一致,如在同一圆周呈现词条较少,词云会显得过于稀疏;如词条偏多又会造成个别词的重叠;处理不当甚至是有的地方稀疏,有的地方重叠.鉴于这种情况,考虑到实用性,尝试人为定义每周的圆半径r0i和每周的词条数n0i.这里,i=1-N.N为总周数(正整数),可由系统求出.
也就是说,除了圆心点外,共用N个圆周呈现所有词条,从内圆到外圆,每个圆周分布的词条数构成n0矩阵,每个圆周的半径构成矩阵r0.不难计算同一周内每个词条所在圆周的半径数据构成的矩阵为:Ri=r0i*ones(1,n0i),i=1-N.
由此可构成各个圆周上各个点的半径数据矩阵.假如有5个圆周,即:R=[R1,R2,R3,R4,R5].
为便于浏览词云图,假定每一周的第一个词条从正上方(圆心角π/2处)开始逆时针分布,则同一圆周内每个词条所在位置的圆心角可构成矩阵:
ti=(0:2*pi/n0i:2*(n0i-1)*pi/n0i)+pi/2
由此可构成各个圆周上各个点的圆心角数据矩阵,如为5个圆周,即:T=[t1,t2,t3,t4,t5].同时亦可确定各个点的坐标数据矩阵为:X=R.*cos(T),Y=R.*sin(T).(“.*”是Matlab运算符,与“*”作用不同.)这决定了各词条的显示位置,而它们与初始的r0和n0矩阵密切相关.用plot函数,画出各个分布点并按顺序连线.图2显示出各个词条出现的顺序呈螺旋状;图3显示出最终呈现的轮廓,很明显最外层已接近圆形.

图2 各词条出现顺序
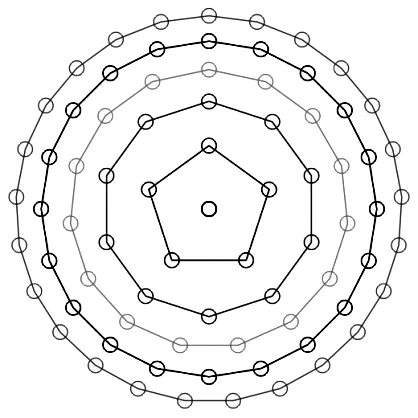
图3 各个词条的位置分布与总轮廓
可见,只要初始r0和n0矩阵数据得当,生成圆形轮廓的词云图不成问题.欲用text函数显示各个词条,各词条初始坐标可由X、Y确定.
2.2 各个词条的精确定位与旋转
text函数在输出文本时,默认设置是水平方向左对齐,垂直方向基线对齐,不旋转.极不利于维持词云图的圆形轮廓.需设置水平方向居中对齐,垂直方向居中对齐,并按所在位置旋转角度.转换为角度矩阵,即rot=T*180/pi-90.这里,由于系统默认的0度(弧度)始于水平向右方向,减去90度,可使每一周的第一个词出现在正上方.text函数的相应属性值设置见表1.

表1 text函数的关键属性设置
2.3 字体的大小与词条频度的相关性
在词云图中,总是用词条文字的大小直观地反应其频度,字的大小为其频度的增函数.绘制词云图之前,各个词条的频度必已获知(可导入相应数据文件).从理论上说,文字显示大小(磅数)可以和频度数字相等,或是其若干倍.但在实际的词频矩阵中,出现频度最高的词条的词频可能达到数百次,而最低词频可能只有一两次.二者相差悬殊.文字显示过大极易造成彼此重叠,文字显示过小会造成不易辨认,都不利于词云的视觉效果.为此,只要文字大小是其频度的增函数,可做相应的函数变换.假如词频矩阵为D,其第一列为各词条文本,第二列为各词条的频度,则有:
F(i)=fix(D{i,2}/k1)+k2
其中,F(i)是每个词的显示的字体的磅数,k1、k2均为正整数,使用fix函数旨在取整,而之所以加k2是为了防止取整后为0.k2实质上就是各词条最小的显示磅数(如5磅),以便识别.
2.4 各个词条的文字色彩控制
当两个词的词频相同时,它们显示的大小必然相同.鉴于上文关于文字大小的处理,当不同词条的词频差异不大时,文字可能以相同大小显示.为了便于区分,应使之显示为不同色彩.这在Matlab处理起来极为方便,Matlab提供了多种色图(colormap)序列.只要按照需要的效果和色彩数目选择即可.这里可采用lines序列,因为中心点外围有m(总词条数)个词,定义色彩矩阵co,可令co= lines(m).在输出各个词条时,按其顺序获取色彩三元组co(i,:)即可(表1).
由此,可创建生成词云图的函数如下:
functionwcchart(D,n0,r0) %三参数为词云矩阵,各圈点数、半径矩阵
R=[];T=[]; %半径、角度矩阵初始为空矩阵
J=sum(n0);%计算总的词条数
%以下定义各词条点位及转角(弧度)矩阵
fori=1:length(n0) %保证圈数
R0=r0(i)*ones(1,n0(i)); T0=(0:2*pi/n0(i):2*(n0(i)-1)*pi/n0(i))+pi/2;
R=[R,R0];T=[T,T0]; %重组R、T矩阵
end
rot=T*180/pi-90;%中心角矩阵转化为角度
X=R.*cos(T);Y=R.*sin(T);
figure('color','w'); hold on;%背景白色,持续画图
D1=sortrows(D,-2); %对原始词云矩阵按照词频降序排列
F00=D1{1,2};%获得最大的词频值
F0=fix(D1{1,2}/5)+8;%定义字号
%以下在中心点输出词频最高的词
text(0,0,D1{1,1},'fontname','SimSun','fontsize',F0, 'color', 'b', 'HorizontalAlignment',
'center',
'verticalAlignment','middle', 'FontWeight','Bold')
co= lines(J);%定义色图序列
%以下依次输出各个词条
fori=1:J
F(i)=fix(D1{i+1,2}/5)+8; txt=D1{i+1,1};
text(X(i),Y(i),txt,'color',[co(i,:)], 'fontname','SimSun','fontsize',F(i), 'HorizontalAlignment','center','verticalAlignment','middle', 'rotation',rot(i),'FontWeight','Bold')
end
axissquare;box on; %等比例尺、图幅为正方形,显示边框
set(gca,'xtick',[],'ytick',[],'looseinset',[0 0 0 0]) %不显示坐标轴刻度,边界尺寸为0.
3 实验与效果
下面基于与图1相同的基础数据(已存入data.mat文件),用上述自制的词云图函数wcchart画词云图.因词条不足100个,考虑在五个圆周呈现所有词条,设置各周的词条数和各圈的半径,如N=[5,10,15,20,25];r=[2.0,3.4,4.4,5.3,6.1]; 再依次执行以下命令,可得到词云图(图4).
loaddata.matD;%装入词云数据文件,数据转移给矩阵D
wcchart(D,N,r);%调用自定义的词云函数
axis([-6.6,6.6,-6.6,6.6]);%%设置坐标轴范围

图4 本文生成的词云图
4 结论
该词云图函数代码简短(不及Matlab R2018中提供的wordcloud函数的1/3),其调用不受词条数目限制,调用时只需调整N、R矩阵数据即可,使用方便.由于没有刻意追求文字套叠效果,与目前一些词云图相比,该词云密度较低,局部可能较为稀疏,这主要是由于各个词条字数不等,为防止彼此重叠而留有余地.由于已知词条是按词频大小从里到外逆时针出现,可以轻松看出“信息流”的频度高于“机器学习”“可视化”的频度高于“大数据”等.与图1相比,既美观,又实用.
实践表明,该词云图函数在32位、64位机均可运行,普适性好;可实现词频数据的批量导入和自动排序;可实现各词条的有序、定位输出,既具有统计学价值,又兼顾了美观,在许多方面已超越了高版本Matlab自带的wordcloud函数,是一种较为实用的词云图定制方案.
