基于逻辑回归树和旋转森林模型的滑坡易发性评价
2021-09-14李宇新邓念东马建全崔阳阳
李宇新,邓念东*,马建全,周 阳,崔阳阳
(1.西安科技大学地质与环境学院,西安 710054;2.陕西省地质调查院,西安 710054;3.陕西省水工环地质调查中心,西安 710068)
随着社会经济的快速发展,地质环境逐渐恶化,衍生出一系列地质灾害。汉中市汉台区地处陕南汉中盆地中心,由于土地资源不合理利用、开垦山坡等人类工程活动,该区域地质环境遭到严重破坏,特别是滑坡对人类生命财产造成巨大威胁。科学高效地进行区域滑坡易发性评价是防灾减灾的有效措施,也是近些年来滑坡预防与土地规划的热点。
从20世纪80年代起,中外学者对滑坡易发性展开研究,其核心是评价指标和评价模型的确定。根据前人研究,评价指标主要根据区域地质环境条件进行选择,尚未达成统一共识。评价方法主要可以划分为确定性模型和非确定性模型[1]。确定性模型主要依靠专家经验确定各类成灾因素的权重值后进行叠加,取得了较好的预测效果,但过度依赖经验判断以及结论缺乏继承性。随着统计学习理论研究和计算机科学的发展,非确定性模型被广泛应用到滑坡易发性评价中,主要包括信息量[2-3]、确定性系数法[4]、证据权法[5]以及一系列数据挖掘与机器学习方法,比如逻辑回归[6]、决策树[7]、人工神经网络[8]、支持向量机[9]、随机森林[10]、朴素贝叶斯[11]等。其中,以决策树算法为基础的一系列集成模型也被应用至滑坡易发性评价中,如J48算法[12]、随机森林模型、旋转森林模型[13]、逻辑回归树模型[14]等,该类模型主要以决策树算法或多种分类器为基础,采取不同的特征选择和剪枝方式进行模型构建,提高模型分类正确率,同时一定程度上减少训练样本过拟合。研究表明,集成模型往往比单一机器学习模型预测能力更高。为进一步探索集成模型在我国滑坡易发性评价的适用性,分析汉中市汉台区滑坡分布趋势以及获得较高精度的滑坡易发性图,本文采用逻辑回归树和旋转森林模型进行该区域的滑坡易发性评价。
1 研究方法
1.1 逻辑回归树
逻辑回归树模型(logistic model tree, LMT)是结合决策树学习理论与逻辑回归的集成模型[14],使用LogitBoost算法在树的节点上生成逻辑回归模型,同时使用分类与回归树算法对树进行剪枝。LMT模型通过交叉验证进行大量迭代,采用递增逻辑回归计算分类LC,即是否为滑坡。最后使用线性逻辑回归计算得到每个叶节点的后验概率值P,作为该模型滑坡易发性评价结果。LC、ρ的计算公式分别为
(1)
(2)
式中:βi为因子的系数;xi为各评价因子;n为因子数量;D为分类数量,D=1,2。
1.2 旋转森林
旋转森林(rotation forest, ROF)以决策树为基分类器,构建包含滑坡因子属性以及类别标签的样本集x=[x1,x2,…,xn]T,选择L个基分类器{D1,D2,…,DL},随机将特征集F划分为K个不相交的子集,每个子集均有M个特征。对特征子集进行主成分分析,旋转换后得到大小均为M×1的向量子集,同时存储主成分系数组成Ri矩阵[式(3)]。根据式(4)计算Di决策树分类器的平均概率值[15-16],即代表评价单元滑坡发生的概率。
Ri=
(3)
(4)

2 研究区概况及数据源
研究区位于陕西省西南部汉中盆地中心,地理坐标为东经106°51′40″~107°10′25″,北纬33°01′40″~33°22′00″,总面积为556 km2。属北亚热带湿润季风气候区,气温受地形影响差异明显,降雨主要集中在6—9月。地形地貌从南到北依次为平原区、丘陵区、中低山区。其中,平原区地势平坦,地质环境问题较少;丘陵区膨胀土发育,发育膨胀土滑坡灾害;中低山区山坡陡峻,山背狭长,陡坡处基岩裸露,缓坡残坡积土覆盖,在降雨充沛时易发生残坡积层滑坡。区内出露地层为震旦系、寒武系、石炭系及第四系。受构造作用影响,岩层褶皱变形强烈,岩石破碎,岩体内部结合力较差。岩体以花岗岩、碳酸盐岩、变质岩为主。较坚硬-较软变质岩易风化产生破坏变形而产生滑坡。研究区人类工程活动剧烈,例如开垦山坡、道路建设开挖边坡、矿山弃渣不合理堆放等,为滑坡发育提供了条件。
在前人进行区内1∶50 000地质灾害详查的基础上,笔者通过遥感影像解译与实地调查进行对比,共圈定40处滑坡。为更加便捷高效地获取滑坡相关属性信息,在划分滑坡周界与对比核查属性信息后,通过ArcGIS软件提取其质心作为滑坡属性点,得到区内滑坡编目图(图1),为后续评价研究奠定基础。

图1 研究区位置与滑坡编录图
主要通过以下方式获取研究区相关数据。
(1)从“地理空间数据云”平台中ASTER GDEM获取研究区数字高程模型(digital elevation model,DEM)数据,获得坡度、坡向、平面曲率、剖面曲率、归一化植被利用指数(normalized difference vegetation index,NDVI)和地形湿度指数(topographic wetness index,TWI)因子。
(2)从1∶50 000地质图矢量化生成地形地貌和岩土体类型数据。
(3)根据研究区气象观测站数据生成研究区年均降雨量因子。
(4)通过Bigemap地图软件获得研究区水系、道路矢量数据。
3 影响因子的选取与分析
结合研究区地质灾害详查报告及相关资料,研究区内滑坡受中低山地形貌控制,由于沟谷发育、斜坡高陡、降雨集中,以及强烈的人类工程活动为滑坡的发育提供条件。因此选取高程、坡度、坡向、年均降雨量、地形地貌、岩土体类型、TWI、NDVI、距水系距离、距道路距离、平面曲率和剖面曲率共12类因子进行评价。
3.1 影响因子分级
根据汤国安经验公式和研究区地质图比例尺大小,选择30 m分辨率栅格单元进行评价,共计614 117个栅格[17]。依据上述数据源生成12类因子数据,对连续型因子分别采用Jenks自然间断法和等间距法进行分级;离散型因子根据二级因子类型进行划分,各类因子专题图层见图2。采用频率比对各分级下滑坡进行统计,表1显示区内滑坡主要分布于高程在672~964 m、岩土体类型为石英片岩、坡度为7.37°~17.10°、平面曲率为-4.34~-0.50、年均降雨量在740~760 mm、坡向为东南以及NDVI为0.34~0.43的区域。

表1 各因子分级下滑坡频率比
3.2 因子多重共线性与贡献率分析
评价模型的数据之间往往存在一定的多重共线性关系,当多重共线性较大时,会严重影响到模型分类的辨识能力[18]。为有效避免这一影响,本文选择方差膨胀因子(variance inflation factor,VIF)与容忍度(tolerance,TOL)进行分析。VIF反映多元线性回归模型中多重共线性严重程度,表示回归系数估计量的方差与假设自变量间不线性相关时方差相比的比值,其中TOL为VIF的倒数。一般认为VIF>10或TOL<0.1时,数据之间存在着严重的共线性,需要进行部分剔除与修正[19]。根据表2结果,所选12类因子之间共线性较弱。
因子贡献率表征着与研究区滑坡发生的相关程度,一方面有利于滑坡发生机理分析;另一方面,贡献率为0的因子对模型的分类预测不仅没有帮助,反而容易会造成数据冗余,降低预测精度[20]。相关属性评估(correlation attribute evaluation,CAE)通过计算影响因子与标签属性之间的相关性来评估因子的重要程度,其结果包括平均贡献率(average merit,AM)和标准差(standard deviation,SD),根据贡献率降序排列见表2。结果显示,12类因子对研究区滑坡发生均有促进作用,其中贡献率排列前三的影响因子分别为地形地貌(AM=0.258)、平面曲率(AM=0.223)以及岩土体类型(AM=0.225)。

表2 影响因子共线性分析与贡献率
4 滑坡易发性评价
从滑坡范围以外区域随机提取等量的非滑坡点作为负样本数据进行模型数据构建,按照7∶3比例随机划分为训练集(56处)和验证集(24处),并提取12类影响因子属性值。本文通过Weka3.8软件进行LMT和ROF模型的构建。通过十倍交叉验证进行训练,然后代入验证集进行测试,最后将整个研究区的属性集代入上述两种模型,得到分别基于LMT和ROF模型的滑坡易发性指数(landslide susceptibility index, LSI),通过ArcGIS的重分类工具将LSI值划分为5类:极低易发区、低易发区、中等易发区、高易发区和极高易发区,得到两种模型的滑坡易发性分区图(图3)。

图3 研究区滑坡易发性图
图3表明LMT与ROF模型分区结果基本一致,研究区滑坡高-极高易发区主要分布于中部丘陵区和北部中低山区。中部丘陵区岩性主要为第四系黏土,受降雨影响膨胀土变形加剧,黏性土滑坡最为发育。北部中低山区滑坡高易发区沿线状分布,这是由于西北侧人工扩建公路,频繁开挖坡脚,以及石英矿、磷矿等矿山开采程度高,一系列人类工程活动破坏地质环境、改变地形地貌所造成。中低山东侧地势高差较大,历史滑坡主要沿河谷分布,地层岩性为震旦系千枚岩夹灰岩,软弱夹层多,较破碎、易风化,在降雨充沛条件下易发生滑坡。研究区滑坡低-极低易发区主要分布于南侧平原区,该区域为广阔的一、二级阶地区域,地势平坦,地层岩性以第四系黏土为主,极少有滑坡发育。
5 模型比较
进行模型精度验证与比较是分类结果对滑坡易发性分区可靠程度验证的重要步骤。本文采用接受者工作特性曲线(receiver operating characteristic curve,ROC)与其线下面积(area under curve,AUC),以及滑坡频率比对LMT模型和ROF模型进行评估。ROC曲线于20世纪90年代起开始广泛应用于数据挖掘、机器学习等分类模型的评估,它以敏感度(即实际为滑坡,预测为滑坡)为纵坐标、1-特异性(即实际为非滑坡,预测为滑坡)为横坐标,通过动态分类阈值避免界限值对结果的影响[21]。AUC取值范围为0~1,值越大代表模型分类效果越好,通常认为AUC>0.7时,表明分类预测能力较强。图4和图5表明,ROF模型在训练集的正确率(77.4%)较LMT模型(75.5%)相比更高,同时验证集的预测率结果表明ROF模型(93.1%)优于LMT模型(84.0%)。图6表明两者模型各易发性等级下,区内滑坡集中分布在高-极高易发区,而低-极低易发区很少或无滑坡分布,证明分区结果符合历史滑坡分布规律。其中ROF模型高-极高易发区分布有37处历史滑坡,多于LMT模型(31处);并且ROF模型低易发区的滑坡数量为0,少于LMT模型(4处)。将历史滑坡密度与分区等级面积占比的比值作为频率比,用来对比不同模型预测滑坡发生的敏感性。由图7可看出,两种模型频率比总体呈上升趋势,ROF模型极高易发区的频率比(6.52)高于LMT模型(2.07),说明ROF模型对滑坡分布更为敏感,预测结果更可靠。
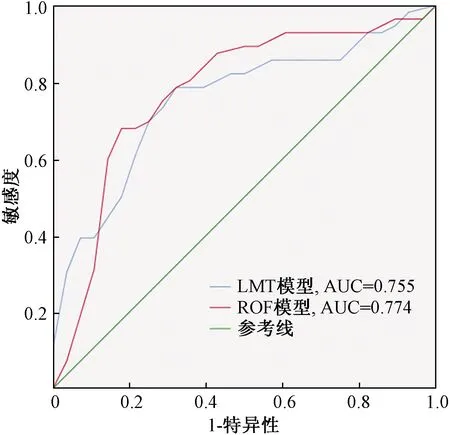
图4 训练集ROC曲线

图5 验证集ROC曲线
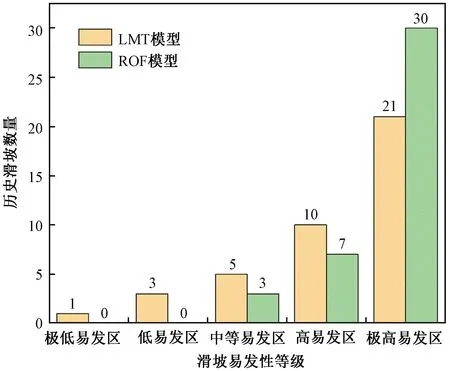
图6 分区结果与历史滑坡数量对比

图7 各易发性等级频率比
机器学习模型的发展使得滑坡易发性评价更加快捷与高效,但仍存在如下不足。
(1)研究结果主要为对比LMT与ROF模型在中国滑坡易发性评价的适用性,后期宜展开模型参数调整对评价结果变化的动态研究。
(2)本次研究两者模型验证集AUC值均高于训练集,这可能由于样本数量因素以及样本数据划分的随机性导致,后期宜探讨滑坡样本规模与评价模型适应性的关系。
(3)由于滑坡发生机理复杂,滑坡易发性评价的因子选择仍存在一定片面性或主观性,后期宜对滑坡影响因子的选取与优化进行补充研究。
6 结论
通过对汉台区进行基于LMT和ROF模型的滑坡易发性评价,得到以下结论。
(1)通过相关资料与野外调查,选取研究区高程、坡度、坡向、年均降雨量、地形地貌、岩土体类型、TWI、NDVI、距水系距离、距道路距离、平面曲率和剖面曲率共12类因子进行评价,并通过CAE和VIF表明,因子属性适合分类模型的构建,并且各类因子对滑坡发育均有影响,其中关系最密切的是地形地貌、平面曲率、岩土体类型、NDVI和距道路距离。根据滑坡易发性分区图,研究区滑坡主要为分布于中低山区和丘陵区黏性土滑坡。
(2)将数据代入Weka3.8软件中构建LMT和ROF模型,生成基于两种模型的滑坡易发性分区图。结果显示两种模型预测分布趋势基本一致,且符合历史滑坡分布规律。
(3)通过ROC曲线、AUC值以及频率比进行模型精度验证与比较,结果显示两种模型均适用于研究区滑坡易发性评价。ROF模型的训练集与验证集AUC分别为0.774和0.931,均高于LMT模型的0.755和0.840;滑坡频率比显示,ROF模型较LMT模型对研究区滑坡易发性更敏感,分区结果更为精确。
