大病保险补偿是否有利于低收入群体?
2021-08-28李亚青
罗 耀,李亚青
(1.广东机电职业技术学院,广东 广州510550;2.广东财经大学 金融学院,粤港澳大湾区创新竞争力研究院,广东 广州510320)
一、引言
因为人口老龄化、疾病谱变化及随之而来不断攀升的医疗费用,定位于“保基本”的中国基本医疗保险仅能部分实现降低医疗支出负担和灾难性医疗支出的政策初衷[1-3]。在基本医疗保险已经实现制度性全覆盖之后,不少群体特别是大病患者依然未能走出“看病贵”之痛,因病致贫、因病返贫的现象依然大量存在[4]。为了建立健全多层次医疗保障体系,2012年8月,国务院六部委联合发布《关于开展城乡居民大病保险工作的指导意见》,开始在全国推广大病保险制度,以减轻人民群众的大病医疗费用负担,力争避免城乡居民发生家庭灾难性卫生支出。大病保险是在基本医疗保险基础上为大病患者产生的高额医疗费用提供的“二次补偿”,重点就是为了保障弱势群体的利益,为因罹患大病而陷入经济困境的参保人提供风险保障。
回顾改革开放以来中国医疗保障体系的建设历程①,无论是基本医疗保险、医疗救助,还是大病保险,一直秉承互助共济传统和扶持弱势群体的政策立意。这一点与罗尔斯对社会弱势群体的重视不谋而合。根据罗尔斯“作为公平的正义”理论,一个公平的合作体系应当向“最不利者”倾斜[5]。在分工与合作成为必然要求的社会合作体系中,每一个社会成员在对社会秩序承担责任的同时,社会也有责任帮助处于弱势地位的成员,使其能够共享由社会发展所带来的成果。低收入群体通常是整个社会的弱势群体,更容易发生灾难性医疗支出。已有研究表明,低收入群体的健康状况更差,从而需要更多的医疗服务[6];而贫困老年人通常因为健康贫困与收入贫困的恶性循环,往往成为最为困难的群体[7]。在学界,弱者优先、关注低收入者福祉也普遍成为医疗保障研究的理论出发点。大量研究表明,医疗保险有利于增加低收入者或老年人等群体的医疗服务利用[8-9],从而可以在一定程度上分散灾难性支出风险[10]。但是,因为“亲富人”的医疗服务利用不平等普遍存在②,低收入群体很可能难以在制度中合理受益[11],高收入反而成为受益更多的群体[12]。
作为中国医疗保障体系的重要组成部分之一,大病保险实际上是一种“补缺”机制,应当精准设计并向贫困低收入群体倾斜[13]。实施8年来,大病保险得到迅速推广并取得了突出成就,目前已经覆盖超过11.29 亿城乡居民,使大病保险患者的实际补偿比例在基本医保基础上平均提升了10-15个百分点③。作为旨在扶持弱者的制度安排,大病保险是否实现了制度的初衷?近年来,越来越多的学者开始关注大病保险制度效果[14-17],例如:高广颖等[15]基于北京部分区县的研究发现,尽管大病保险补偿使灾难性支出发生率有所下降,但是患者的疾病经济负担仍然较重;谢卫卫等[16]基于中国家庭追踪调查(CFPS)的研究则发现,大病保险没有降低灾难性支出的发生概率,但显著减轻了中部和东部地区患病农民的经济负担;徐维维等[17]基于宁夏农村地区的入户调查数据研究表明,大病保险补偿使穷人受益更多,改善了自付医疗费用负担的公平性,但也加剧了灾难性支出向贫困家庭集中的趋势。
总体上看,因为样本选择、研究视角等的不同,现有相关研究并未达成一致的结论。特别是,低收入群体是否更多地从大病保险制度中获益?这一问题的回答具有重要的政策价值,但目前的研究还非常缺乏。为此,我们基于样本地区的大规模医疗保险抽样数据,从大病保险补偿环节的公平性视角出发进行了研究。我们发现,大病保险补偿明显向中等及较高收入群体倾斜,与此同时低收入群体的状况并未得到充分改善。大病保险“普惠性”有余而“补缺性”不足,存在一定程度的“逆向再分配”现象。这些发现尽管有些出乎意料,但有着背后深层次的原因,对于进一步完善大病保险制度有着重要的政策参考价值。
二、方法和数据
(一)研究方法
1.集中曲线和集中指数
集中曲线和集中指数(Concentration Index,CI)是在洛伦兹曲线和基尼系数基础上发展起来的用以评价医疗卫生领域公平性的测量指标[18]。集中曲线的绘制原理与洛伦兹曲线相似,以按社会经济水平由低到高排列的人口累计百分比为横轴,以各社会经济阶层人群健康、医疗服务利用等指标的累计百分比为纵轴,在坐标系中连接各点所形成的曲线即集中曲线。如果健康、医疗服务利用等指标在不同社会经济阶层的分布是绝对公平的,集中曲线就会与公平线(45 度对角线)重合,否则就会偏离公平线。集中指数就是用来衡量偏离程度的指标,理论上等于集中曲线与对角线之间围成的面积与对角线下的面积之比,取值范围在-1~1 之间。以医疗服务利用指标为例,当集中曲线处于公平线上方时,集中指数为负值,表明低社会经济阶层的人更多地利用了医疗服务;当集中曲线处于公平线下方时,集中指数为正值,表明医疗服务利用的分布是“亲富人”的。集中指数的绝对值越大,说明不公平程度越高[19]。
集中指数的测量方法,根据数据特征情况而有所不同。对于非分组数据,集中指数的计算公式为[20]:

其中,ri为秩次(Fractional rank),可通过下式计算:
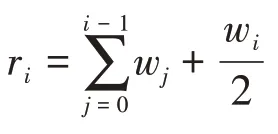
式中,hi为健康或者医疗服务利用的指标值,μ为该指标的均值,wi为样本的权重。
集中指数的符号和大小分别可以直观地反映不公平的方向和程度,便于不同地区和国家之间的比较研究。
2.医疗服务利用的需求标准化
在医疗服务利用相关的研究领域,政策制定者和研究者们普遍关心横向公平(Horizontal Equality),即坚持“具有相同的医疗服务需求者应该获得相同的医疗服务”[21]。根据集中指数原理可知,相同社会经济地位的人应当拥有相同的健康(或享受同等的医疗服务利用),才能体现公平。但如果直接根据某个健康指标或医疗服务利用指标计算集中指数,可能忽略了一个事实:不同社会经济阶层的人因为健康状况不同,对医疗服务需求存在差异。通常情况下,贫困群体健康状态比其他群体的健康状况更差,从而需要更多的医疗服务[6]。因为这种医疗服务需求差异导致的不公平是“合理”的,在测量时应当剔除。这就需要对医疗服务利用进行需求标准化(Need Standardization)。通常有直接和间接两种标准化方法可供选择。在实践中,当采用微观数据时,往往采用间接标准化方法:用年龄、性别等人口统计学指标加上健康指标(自评健康、有无慢性病)作为医疗服务需求的代理变量,采用以下线性或非线性的回归模型来实现。
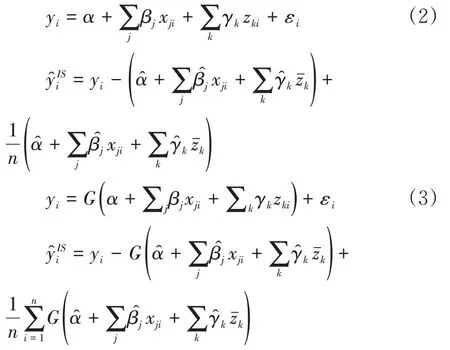
模型(2)和(3)中,yi和分别为标准化前和标准化之后医疗服务利用等被解释变量;x和z分别代表需求变量和控制变量;n为样本数量;α、β和γ为系数,和为相应系数的估计值,而表示变量z的均值,即标准化后的医疗服务利用。上述标准化程序的内在假设是,如果控制了可观测的需要类指标,“非需要类”因素的影响将集中反映在回归残差中。但当被解释变量为连续变量时,间接标准化采用线性回归模型(2);当被解释变量为二元变量时,为确保回归后的预测值介于0、1 之间,需要选择非线性回归模型(3)。其中的G表示probit、log it等非线性函数形式。
根据研究目的,我们在后文的分析中将对医疗服务利用和补偿金额进行标准化,并根据被解释变量的类型结合运用线性和非线性的标准化方法。需求变量包括年龄、性别和健康状态。根据年龄特征,我们将样本群体分为24 岁及以下、25-34 岁、35-44 岁、45-64 岁、65 岁及以上等6 个年龄组,据以生成6个哑变量ageg1-ageg6。再将6个群组与性别变量结合,生成12 个哑变量fage1-fage6、mage1-mage6,其中当样本观测属于女性和ageg1时,fage1 赋值1,否则为0,其他变量以此类推。而根据“是否有慢性病”可生成反映健康状态的哑变量chro。对于控制变量,我们考虑了户口类型、收入水平(取对数)、住院天数和医疗机构等级等指标。
(二)数据说明
本文的数据源自X市、Y市两地的医疗保险数据库抽样。考虑到数据规模特别庞大,我们采用按年龄分层的“锁定样本跟踪抽样”方法,以2017年12月31日的数据对全体参保人进行年龄组划分后,对各年龄组按30%的抽样比例进行抽样,然后根据个体身份标识,跟踪所抽取的参保个体在2014-2016年的个人基本信息、缴费、医疗费用支出和基金报销情况。抽样数据涉及个人电脑号、年龄、性别、个人身份、户口性质、缴费工资、缴费金额、住院天数、医院级别、出院诊断、医疗总费用、统筹基金报销总额、大病保险报销、自费总额等变量。删除缺失值和异常观测值后,关键指标的描述性统计如表1所示。

表1 样本地区基本医疗保险住院情况的描述性统计
三、初步统计分析
鉴于大病保险实施的初衷就是降低大病患者的疾病经济负担并尽可能避免家庭灾难性卫生支出,我们主要分析大病报销对疾病经济负担和灾难性支出的影响。因此,本节将样本划分为不同收入组和年龄组,主要围绕自费负担和灾难性支出发生率进行统计分析。疾病经济负担可用绝对指标和相对指标两类方法来衡量,绝对指标通常为患者的实际医疗支出[22],相对指标则采用自负医疗费用占家庭可支配收入比例[23]。对于灾难性支出,我们参照世界卫生组织的建议标准[24],用个人自付医疗费用占年工资收入的比重来衡量自费负担,以自费负担超过年工资收入的40%作为发生灾难性支出的衡量标准④。
如果将参保人按收入水平从低到高排序划分为五组,分组的大病保险补偿前后自费负担和灾难性支出发生率变化情况如表2所示⑤。总体上看,补偿效果非常明显,Y市的自费负担和灾难性支出发生率分别降低了24.5%和32%,X市的这两个指标分别降低了77.3%和70.3%。两市相比较,X市的大病补偿效果远超过Y市。分组来看,Y市和X市两市在大病保险补偿前自费负担和灾难性支出发生率最高的均为中等和较高收入群体。大病保险补偿后,Y市的这两个指标依然没有改变原来的收入组分布。相对而言,Y市低收入组更大程度地受益,表现为最低收入和较低收入组的自费负担分别降低了43.4%和61.2%,灾难性支出发生率分别降低了72.1%和83.0%;X市则是中等和较高收入组自费负担和灾难性支出降低幅度最大,均超过了80%,低收入群体则相对受益不足,从而使补偿后的这一群体变成了自费负担和灾难性支出发生率最高的群体。这表明X 市的大病补偿明显偏向高收入群体且可能存在“矫枉过正”现象。

表2 两市分收入组的住院费用及大病保险补偿效果

说明:本表的数据只考虑大病保险对自费负担和灾难性支出的影响。因为大病保险是基本医疗保险基础上的“二次补偿”,表中的“补偿前”是指大病保险报销之前(基本医疗保险报销之后),“补偿后”指大病保险报销之后。以自费负担为例,补偿前和补偿后的自费负担是指大病保险补偿前后自付医疗费用占年收入的比重,降低率是指大病保险补偿前后的自费负担之差除以补偿前的自费负担。灾难性支出发生率的“降低率”指标以此类推。
但上述分析只是统计结果的简单对比。正如前文所指出的,从水平公平的视角出发,因为健康状况不同而产生医疗服务需求差异,理论上本应当获得差别对待。如果将医疗服务需求进行标准化后,结果会如何呢?下一节将提供进一步的分析。
四、大病保险补偿结果的实证分析
(一)大病保险的受益人群分布
大病保险补偿的前提是参保人因病产生了大额医疗费用。因此,有必要先分析医疗服务利用的公平性。根据模型(3)对医疗服务利用进行标准化,得到的医疗服务利用集中曲线如图1上半部分所示。可以看出,在剔除与需求差异相关的“合理的”不公平因素之后,两市的集中曲线均处于公平线的下方。这表明在同等的健康水平下,高收入群体相比低收入者更多地利用了医疗服务。其中,X市的集中指数更大,说明该地区医疗服务利用的“亲富人”程度更高。
根据模型(2)对各个参保人的大病补偿金额进行标准化,得到的大病保险补偿集中曲线如图1的下半部分。可以看出,两市大病保险补偿体现出比医疗服务利用更为明显的“亲富人”分布特征,集中指数均在0.36 以上,明显超过了医疗服务利用集中指数。其中Y 市的医疗服务利用“亲富人”程度尽管较低,但是补偿金额集中指数却与X市相对接近。这意味着即便低收入群体与高收入群体享有同样的医疗服务可及性,高收入群体平均获得的补偿也要高于低收入群体。可见,无论是医疗服务利用还是补偿金额,高收入群体实际上成为大病保险的主要受益人群。

图1 两市医疗服务利用和大病补偿的集中曲线(需求标准化后)
(二)大病保险补偿前后的效果对比
补偿金额的高低虽然是体现受益程度的重要指标,但是这一指标仅仅体现出患者所获得补偿的绝对数。显然,不同收入水平的患者对大病风险的抵御能力不同。通常低收入群体财务状况更为脆弱,同等的补偿金额对于低收入群体可能是“雪中送炭”,但对于高收入群体也许仅仅是“锦上添花”。从大病保险“力争避免城乡居民发生家庭灾难性卫生支出”的制度目标出发,还有必要进一步考察自费负担等相对指标在不同收入群体中的分布情况。为此,我们在基本医疗保险已经给予补偿的基础上,绘出了两市大病保险补偿前后的自费负担和灾难性支出集中曲线如图2所示。其中灾难性支出的界定继续按照前文做法,以个人自付费用超过年收入水平的40%作为阈值。可以看出,补偿前两市的自费负担和灾难性支出集中曲线均在公平线的下方,体现出明显的“亲富人”的特征。这说明高收入群体相对于低收入群体而言,面临更大的医疗自费负担,也更容易发生灾难性支出。这与表2的统计结果(自费负担和灾难性支出发生率最高的均为中等和较高收入群体)是一致的。

图2 两市大病补偿前后的自费负担和灾难性支出集中曲线
在大病保险补偿后,这种“亲富人”倾向不同程度地得到缓解甚至扭转,表现为两市各集中曲线不同程度地向公平线靠拢。其中,Y市补偿后的自费负担和灾难性支出集中指数分别为0.3297 和0.4729,相比补偿前分别降低了0.0964和0.0494;X市则更加明显,自费负担集中指数由补偿前的0.1765转为补偿后的-0.0714,灾难性支出集中指数也由0.1973转为-0.0322,从而使这两个指标在分布上的“亲富人”倾向在补偿之后转变为微“亲穷人”⑥。这表明大病保险补偿基本上瞄准了医疗负担较重和灾难性支出发生率较高的群体,但是对高收入群体补偿过多,反而有可能导致“矫枉过正”,使低收入群体的状况难以得到充分改善。如表2所示,大病保险补偿后,X 市最低收入群体的灾难性支出发生率高达4.43%,远高于其他收入组。这表明X 市大病保险补偿出现了明显不利于低收入群体的后果。
为了进一步考察大病保险补偿的收入再分配效应,表4展示了大病保险补偿前后两市的基尼系数变化情况。
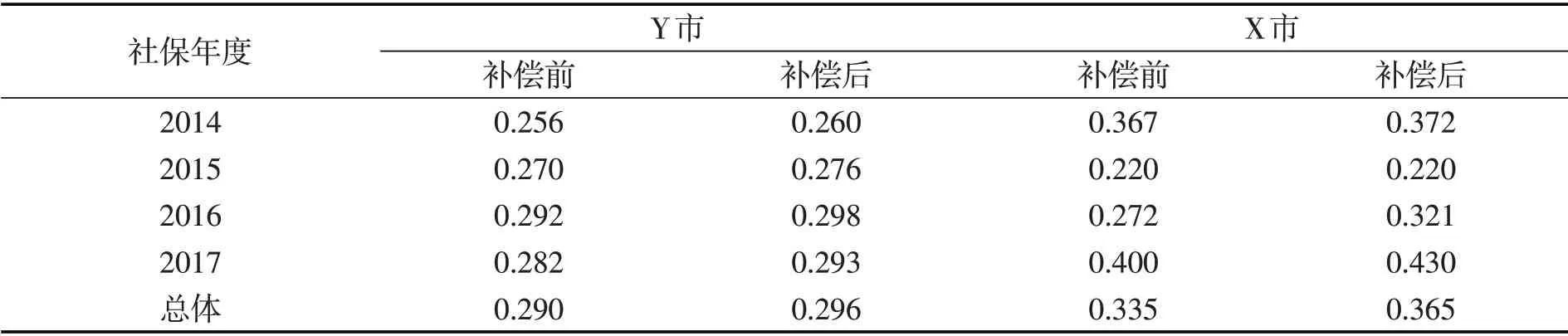
表4 大病医保补偿前后的基尼系数变化
可以看出,因为高收入群体相对于低收入群体更多地在补偿中受益,大病保险不仅未能缩小收入差距,反而进一步扩大了收入差距。其中,Y 市大病保险补偿对基尼系数的影响相对较小,总体上只增加了0.006;X 市的大病保险补偿对基尼系数的影响更大,总体上基尼系数上升了0.03。这进一步验证了大病保险补偿不同程度地存在不利于低收入群体的“逆向再分配”现象。
(三)对分析结果的进一步探讨
为何以扶持弱势群体为宗旨的大病保险反而使高收入群体受益更多?是否与疾病发生规律相关?为此,我们根据两市抽样数据“出院诊断”信息,运用字符抓取程序在海量数据中对特定字段进行搜索,以判断参保人是否患有慢性病或重大疾病,进而可以生成“慢性病”和“大病”的哑变量。“慢性病”的字段界定参考《第五次全国卫生服务调查》15岁以上人口排名前10的慢性病种⑦;“大病”的字段界定根据原保监会所列的恶性肿瘤(癌症)、急性心肌梗塞、脑中风或脑中风后遗症等25 种重大疾病来确定。在此基础上,我们可以统计出样本地区的疾病发生率情况。
两市分收入组的疾病发生率、住院率和住院费用情况如表5上半部分所示。可以看出,两市的慢性病发生率均与收入水平呈现负相关关系,收入水平越低,慢性病发生率就越高。这与前人“社会经济地位较低群体的健康状况更差”的研究结论相一致[25-26]。但为何慢性病高发的低收入群体的住院服务利用反而不如慢性病相对较低的高收入群体?主要原因可能在于高收入群体在医疗利用中占明显的优势地位。Allin 等[27]和叶明华[28]研究指出,具有较高社会经济地位的人能够充分释放其医疗需求,也更有经济条件选择高质量医疗服务。李佳佳等[29]也指出,因为高收入人群在就医偏好上倾向于选择大医院和高质量服务,从而能够比低收入阶层更多地从医保补偿中受益。除此以外,还可能因为高血压、糖尿病等普通慢性病不一定需要住院,即便在应住院的群体中,也可能有部分低收入者因为经济约束放弃住院治疗。根据《2018 第六次国家卫生服务调查》结果,全国因经济困难而未能接受任何治疗的患者占两周患病人数20.59%,城乡居民因经济困难需住院而放弃住院的比例分别为9.0%和10.2%。
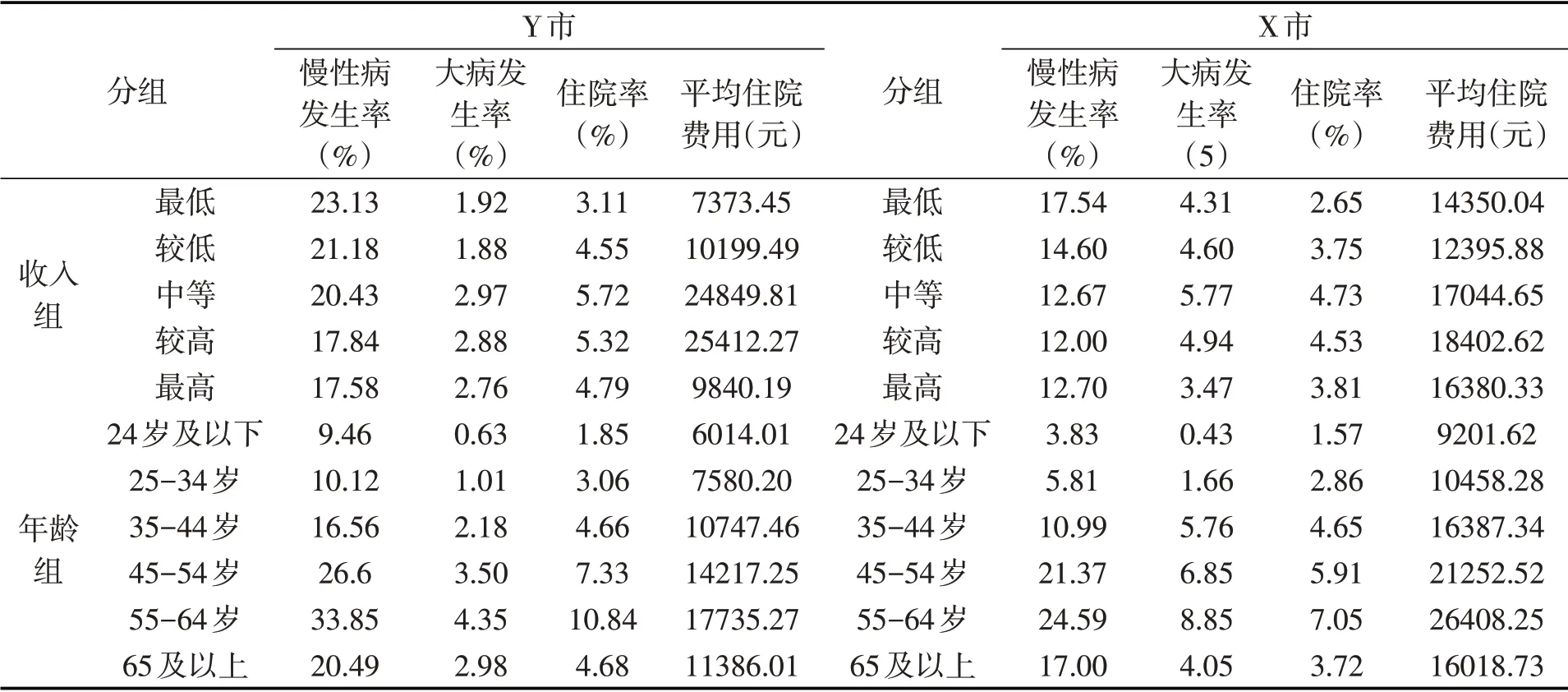
表5 两市疾病发生率和住院情况的分组统计
是否罹患重大疾病(而非普通慢性病)才是更可能导致住院的因素。两市的统计数据也印证了这一点。从表5可以看出,大病发生率较高的群体主要集中体现在中等收入和较高收入组,最低和最高收入组的大病发生率反而相对较低。住院率与平均住院费用、大病发生率的分布规律相对应,出现“中间高,两头低”的现象。大病发生率与收入水平不存在明显的相关关系,但借助集中指数这一工具可以更加清楚地看到大病发生情况的分布倾向。数据表明,X 市和Y 市的大病集中指数分别为0.0681和0.3112,不同程度地体现出“亲富人”的特征,其中以Y市更为明显。这就解释了图1中两市的住院医疗服务利用为何会向高收入群体倾斜。而中等收入和较高收入组不仅住院率最高,平均住院费用也明显超出其他收入组,这说明更多的住院医疗服务利用伴随着更高的医疗费用支出,这应该是图1中大病保险补偿比医疗服务利用体现出更为明显的“亲富人”特征的重要原因。
年龄是另一个与疾病发生规律密切相关的因素。表5下半部分展示的是分年龄组疾病发生率、住院率和住院费用情况。可以看出,无论是X市还是Y 市,65 岁以前的大病发生率和慢性病发生率均与年龄呈正相关关系。年龄越大,疾病发生率就越高,到55-64 岁达到最高值。两市55-64 岁年龄组的慢性病发生率分别达到33.85%和24.59%,大病发生率分别达到4.35%和8.85%,明显高于相邻的年龄组。45-54岁年龄组相比35-44岁年龄组,慢性病发生率急剧增加,差异达到10个百分点以上;35-44岁年龄组相比25-34岁年龄组,大病发生率急剧增加,差异达到2-3 倍。65 岁及以上的年龄组反而不是疾病发生率最高的组。这一结果与现有的文献并不一致[30-31]。可能的原因在于,这些年龄较大的老人中存在有卫生服务“需要”却“未利用”的现象[32]。因为中年和低龄老人成为疾病发生率高度集中的群体,且从财富积累的生命周期规律来看,这些群体往往也是收入稳定甚至处于较高水平的群体⑧,医疗服务利用和大病补偿向高收入群体倾斜,就成为两个样本市共同的趋势。
进一步分析高额医疗费用发生群体的年龄和收入分布,我们发现,在住院医疗费用最高的群体中⑨,有80%左右为中等及更高收入水平群体(X、Y 两市分别为77.5%和87.9%),且有60%-70%为45 岁以上的中老年人(X、Y 两市分别为63.7%和70.7%);在发生了“高额医疗费用”的群体中⑩,中等收入及以上收入群体占据了90%以上的绝对比例(X、Y 两市分别为92.7%和92.3%),45 岁以上的中老年人也占比在60%以上(X、Y 两市分别为61.8%和66.5%)。以上数据充分说明,因为疾病的发生规律,中等及以上收入群体(而非低收入群体)在大病保险中受益最多,而这些群体大部分是45岁以上的中年和低龄老人。
综上所述,大病发生率的“亲富人”的特征,住院和高额医疗费用向中等及更高收入水平群体集中,是高收入群体比低收入群体更多地从大病保险补偿中受益的最为关键的原因。
五、总结和讨论
大病保险的推出,是为了呼应人民群众对大病医疗费用负担过重的诉求,最大限度地保护普通民众,特别是社会弱势群体的基本权益。作为基本医疗保险基础上的一种“补缺”机制,大病保险补偿到底使哪些群体受益更多?是否重点保障了作为弱势者的低收入群体的利益?我们基于样本地区的大规模医疗保险数据库并引入集中曲线、集中指数、医疗服务需求标准化等工具对上述问题进行了定量研究。我们发现:第一,总体上大病保险补偿效果非常明显,使Y市的自费负担和灾难性支出发生率分别降低了24.5%和32%,使X 市的这两个指标分别降低了77.3%和70.3%。第二,高收入群体比低收入群体更多地从大病保险补偿中受益。相比低收入群体,高收入群体更多地利用了住院医疗服务,获得的大病补偿金额也更多。因此,大病保险补偿不仅未能缩小收入差距,反而进一步扩大了收入差距。第三,高收入群体比低收入群体面临更高的医疗自费负担和灾难性支出发生率。大病保险补偿充分体现了对高收入群体的倾斜,缓解了自费负担和灾难性支出,但补偿过于倾向于高收入者,可能出现“矫枉过正”,导致低收入群体的状况难以得到充分改善。第四,疾病的发生规律可能是解释上述结果的关键理由。分析发现,大病发生率向中等收入和较高收入群体集中,使他们成为自费负担和灾难性支出发生率最高的群体,而这些群体大部分是45 岁以上的中年和65 岁以下的低龄老人。在发生了“高额医疗费用”的群体中,90%以上为中等收入及以上收入群体,60%以上为45 岁以上的中老年人。
上述结论值得决策者和研究者们深思。自1998年中国开始社会医疗保险改革以来,各项制度从无到有,逐步覆盖全体国民,很好地解决了机会公平问题,但是结果公平还未能得到应有的重视,这无疑不利于充分彰显制度效果。大病保险,尽管有着扶持弱者的制度定位,但是制度“补缺性”不足而“普惠性”有余。例如,大病保险补偿的前提是参保人发生了“高额医疗费用”,但对于什么才是“高额”?穷人和富人的标准显然是不一样的。《指导意见》提出以个人年度累计负担的合规医疗费用超过当地上年城镇居民人均可支配收入或农村居民年人均纯收入作为判定标准,这种“一刀切”式的门槛设定,无疑不利于低收入群体。
因此,首先要进一步强化“差别原则”,设计更为精准的补偿方案,包括将起付线的设置与当地经济水平挂钩,分收入等级建立差异化的起付线,对最低生活保障对象等特别贫困者实行共付机制的减免等。其次,应当在医保支付方式上采取有效措施防止高收入群体利用其社会优势地位过度利用医疗服务,例如推广总额预付、按病种付费等支付方式,以促进医疗服务利用公平,保障低收入者的权益。与此同时,我们也要看到,虽然低收入群体是传统意义上的弱势群体,但是随着疾病谱变化,确实有一部分中高收入群体有可能“因病致贫”或陷入灾难性支出泥沼。他们也属于医疗弱势群体,其合理的医疗保障需求也是需要重视的。尽管如此,我们依然需要警惕大病保险补偿出现的“逆向再分配”现象。无论如何低收入群体都是需要重点保护的弱势群体。保护“最少受惠者”的最大利益,是我们不断完善医疗保障制度过程中始终需要坚持的重要原则之一。X市的分析结果表明,大病保险对高收入群体的过度倾斜,使补偿后的自费负担和灾难性支出进一步向低收入群体集中,这种“矫枉过正”无疑违背了大病保险制度的初衷。因为大病保险资金通常来源于基本医疗保险基金划拔,这意味着参保人共同缴纳形成的医保基金,可能通过大病保险补偿向更多的“富人”分流,从而直接影响整个医疗保障体系的收入再分配效果。
[注 释]
①中国自1998年实施城镇职工基本医疗保险,2003年开始试点新型农村合作医疗,2005年、2007年先后在全国推广医疗救助和城镇居民基本医疗保险。目前已经初步形成覆盖全国的“三险一助”的医疗保障体系。
②医疗服务利用不平等现象有很多文献研究,Allin et al(2011)基于英国、Watanabe & Hashimoto(2012)基于日本、Carrieri & Wuebker(2013) 基于欧洲国家、Channon等(2012)和Brinda 等(2016)基于印度、解垩(2009)和刘柏惠等(2012)基于中国的研究均发现存在着亲富人的医疗服务利用不平等。
③新浪财经:《梁涛:大病保险已覆盖11.29 亿城乡居民》,https://finance.sina.com.cn/money/insurance/bxyx/2019-07-04/doc-ihytcitk9671014.shtml,2019年07月04日。
④朱铭来等(2017)认为应当区别不同收入阶层建立不同的阈值。他们基于国务院城镇居民基本医疗保险评估入户调查数据构建了面板门槛模型研究发现,中国总体标准应为家庭自付医疗费用占收入的44.13%。低收入、中低收入和中收入组的标准分别为14.2%、32.2%和56.1%。中高收入的应当更高。请见:于新亮、朱铭来和熊先军.中国医疗保险保障公平性与精准化改进研究——基于灾难性医疗支出界定、细分与福利评价,保险研究2017(3):114-127.
⑤表2和表列示的灾难性支出相关指标值是40%阈值下的结果。我们在测算中也曾参考朱铭来等(2017)的研究结论,将五个收入组的阈值标准分别设为15%、30%、60%、70%和80%,得出的自费负担和灾难性支出发生率的年龄组、收入组分布与单一40%阈值下的结果基本相近。鉴于篇幅,我们没有在文中列出。
⑥我们在测算中还按照分级设定的方式(将五个收入组的阈值标准分别设为15%、30%、60%、70%和80%)确定灾难性支出的阈值,得出结果略有区别,但变动趋势一致。D市的灾难性支出“亲富人”程度更强,补偿后集中指数为0.4120,相比补偿前降低了0.1063;X 市的灾难性支出则一开始就体现为“亲穷人”的分布特征并在大病保险补偿后进一步加剧,补偿前集中指数为-0.0466,补偿后的则大幅度变化为-0.4742。
⑦根据《第五次全国卫生服务调查》结果,排名前10的慢性病种包括:高血压、糖尿病、椎间盘疾病、缺血性心脏病、脑血管病、胃肠炎、类风湿性关节炎、慢阻性肺部疾病、胆结石和胆囊炎、泌尿系统结石。
⑧统计数据显示,45 岁以上各年龄组的人中,X 市和D市分别有69.2%和70.1%的比例处于中等及以上收入组。
⑨我们发现,两市的医疗费用呈明显的右偏分布,X市有99%人群的住院医疗费用在63907元以内,D市有99%人群的住院医疗费用在86581元以内。此处的结果是根据医疗费用最高的1%群体进行的统计。
⑩参照国务院等六部委颁发的《关于开展城乡居民大病保险工作的指导意见》,我们在此处以个人年度承担的自付医疗费用超过当地统计部门公布的上一年度居民年人均可支配收入作为“高额医疗费用”的判定标准。
