面向深度学习的弹载图像处理异构加速现状分析
2021-08-23陈栋田宗浩
陈栋 田宗浩

摘 要: 本文分析了深度学习算法向工程应用转化存在的问题,结合陆军智能弹药的特点和发展趋势,分别从深度学习模型压缩、量化,硬件平台加速设计以及异构加速框架设计等方面进行研究,提出了面向深度学习的弹载图像处理异构加速体系,实现从算法开发到硬件异构移植的流程化设计。随后,利用DeePhi Tech的异构加速框架DNNDK对Yolo v3模型进行压缩、量化,权重压缩率90%以上,模型参数压缩率80%以上,实现了Yolo v3的轻量化设计。在DPU硬件加速架构的基础上,实现算法向弹载嵌入式平台的移植,其功耗和识别检测效率满足弹载图像处理的要求。
关键词:弹载图像;深度学习;FPGA;脉动阵列;Winograd卷积
中图分类号:TJ760; TP18 文献标识码: A 文章编号:1673-5048(2021)03-0010-08
0 引 言
万物互联时代的到来为部队装备智能化建设带来了新的机遇,信息和微电子等前沿技术在军事领域的广泛应用催生出大批精良的新式装备,使得传统的作战理念发生翻天覆地的变化。对炮兵来说,弹药的智能化水平主要体现在目标自主识别、跟踪及毁伤,完全依靠弹上的控制系统独立完成作战任务,并且命中精度和抗干扰能力更强。目前,国内外对精确制导弹药的研究主要集中在卫星、激光、雷达以及图像等几种模式。其中,卫星制导精度依赖于目标的定位精度,激光制导需要前沿观察所在弹丸工作末期给予激光指引,与雷达制导同属被动制导,易于被敌发现,而图像制导利用图像传感器采集目标反射或辐射的可见光信息形成图像,抗干扰能力强,不易被目标发现,通过充分挖掘图像中的信息实现目标的自主识别、定位和毁伤[1]。
随着深度学习(Deep Learning, DL)算法被应用到社会的各行各业,卷积神经网络[2](Convolution Neural Network, CNN)突破传统人工挖掘图像特征导致目标识别准确率低的瓶颈,通过多隐层的网络结构、良好的数据集训练、深度挖掘图像的特征信息,大幅度提升了目标识别的准确率。随后,各种基于CNN的改进模型被不断提出,在提升目标识别准确率的同时网络层次逐步加深,这也对计算平台的计算、存储以及功耗提出了更高要求。弹丸内部空间小、作用时间短,嵌入式硬件平台的处理速度成为制约深度学习算法向弹载平台部署的关键因素。为此,需要在深度学习算法和硬件异构平台加速两个方面进行研究,满足弹载图像目标检测实时性的要求,推动图像制导弹药的智能化发展。
1 智能化图像制导弹药关键技术分析
1.1 图像制导弹药智能化需求分析
深度学习未得到广泛应用之前,图像制导弹药主要利用手工特征提取、图像模板匹配等方法对目标进行识别检测,依赖人的先验知识,不能从本质上刻画图像的特征,识别准确率低,检测速度慢;而未来作战样式复杂多变,非接触、突发性战争成为主要特点,战争爆发后指挥员可能并不明确敌目标的主要特征,很难做到制导弹药的准确识别和精确打击,传统意义上的图像制导弹药会更依赖于人的主观判断识别目标,在瞬息万变的战场环境下可能错失最佳攻击时间。深度学习模型具有强大的表征和建模能力,通过监督或非监督的学习方式进行训练,逐层、自动地学习目标的特征表示,通过将底层特征抽象形成高层特征,实现待检测目标本质的描述。利用前期学习到的各种目标特征信息,弹载处理器对采集到的图像进行深度挖掘、推理与融合,判断目标类别、
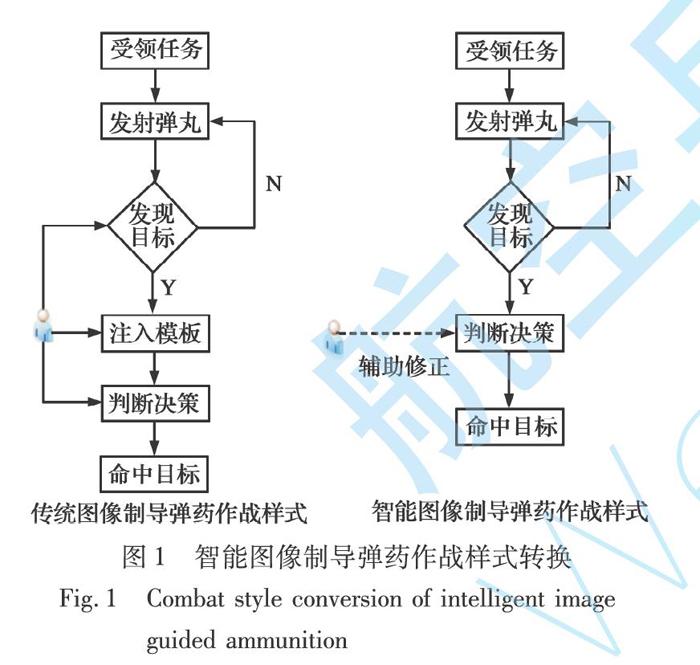
位置,自主控制弹丸命中目标,实现“感知-判断-决策-行动”的新型作战样式,自主完成侦察与打击任务,如图1所示。
由图1看出,传统图像制导弹药将采集的图像信息回传至地面站进行处理,严重依赖于人的先验知识,并且对未知、不确定目标往往做不到首发命中。此外,弹丸作用时间短,任务不可逆,数据量庞大的图像信息回传至地面站处理过程中存在较大时延,满足不了系统实时性要求;而智能图像制导弹药极大释放人的作用,利用学习到的目标特征自主完成识别打击任务,仅需要指挥员对弹药决策信息进行辅助修正,降低误判率。由于整个处理过程在弹载平台自主实现,降低了数据传输对带宽的压力,大大降低系统延迟,增强制导弹药的响应时间。
1.2 智能图像制导弹药目标检测算法分析
弹体在空中运动复杂,弹载图像受弹体姿态的影响产生各种变化,例如图像旋转变化、图像尺度变化以及战场环境因素带来的目标遮挡等非本质性变化,这些影响因素给图像特征提取及目标检测带来严峻的挑战。CNN的最大特点为权值共享和局部连接,相比浅层网络和传统手工特征提取算法能更简洁紧凑地提取特征,具備对特征旋转、平移、缩放等畸变的不变性。随着深度学习技术在图像领域深入研究,出现越来越多的新理论、新方法,基于候选区域的方法和基于回归思想的端到端的方法相互借鉴[3-4],不断融合,取得了很好的效果。
基于候选区域的目标检测算法(两阶段法)通过Selective Search[5]和Edge Boxes[6]等算法提取图像中的候选区域(Region proposal),在此基础上对候选区域进行分类和位置校准。例如R-CNN算法采用Selective Search方法对图像进行分割划分、整合,得到不同大小的候选区域,利用CNN在候选区域上进行特征提取,显著提升了目标检测的准确率。由于R-CNN算法对输入图像大小要求严格,图像缩放操作损失部分有用信息,并且其在提取候选区域时存在大量的重复运算,严重影响算法的检测速度和效果。为解决R-CNN对输入图像尺寸敏感问题,基于空间金字塔池化层(Spatial Pyramid Pooling, SPP)的SPP-Net算法[7]以及Fast R-CNN算法[8]被提出,利用不同的池化窗口将图像映射到同一维度,保存完整的图像信息,检测精度得到提升。但对于候选区域的操作仍然消耗大量的时间,算法的实时性问题仍未解决。Faster R-CNN算法[9]利用一个全卷积网络RPN(Region Proposal Network)提取图像特征,将候选区域从2 000多个降到300个,提升了算法检测速度。但其网络中的多次下采样操作使图像纹理细节特征损失较多,对小目标的识别检测准确率较低。为此,一些基于高层特征和低层特征融合的算法被用于提升小目标检测精度,如超特征网络HyperNet(Hyper Feature Net)[10]、多尺度特征金字塔网络FPN(Feature Pyramid Networks)[11]等,在降低候选区域数量的同时保证对小目标的检测精度。虽然基于候选区域的目标检测算法精度和速度不断提升,但是由于RPN结构的存在,其检测速度从本质上受到限制,难以满足弹载平台对于检测算法实时性的要求。
基于回归的检测算法(单阶段法)不需要产生候选区域,即给定输入图像,直接在图像的多个位置上回归出这个位置的目标边框以及目标类别,在保证一定准确率的前提下,速度得到极大提升。例如文献[12]提出的Yolo算法,可以通过对图像的直接检测确定目标的边界框和类别,检测速度提高到45 f/s,但其对紧邻目标和小目标的检测效果不佳。近年来,Yolo系列算法通过BN操作、残差网络特征融合等算法改进,使得模型检测精度和速度大幅度提升,并且对小目标的适应性增强,模型的规模也在不断减小,如Yolo v2/v3[13],Tiny-Yolo,SlimYolo[14]等。同样,SSD算法及其改进模型[15-16]在Faster R-CNN算法anchor机制下,针对小目标检测进行了拓展研究,提高了模型的检测精度和速度,如DSSD,DSOD,RSSD等。结合弹载图像的特点以及深度学习在目标检测中的发展趋势,基于Yolo系列的算法在卫星[17]、无人机以及弹载平台[18-19]目标识别检测中得到成功应用。为此,本文拟在弹载平台部署单阶段目标检测算法,实现目标的快速识别和定位,为决策和人工辅助修正过程留出充足的响应时间。
随着网络结构的不断加深和改进,模型的检测精度不断提高,但是随之带来的是庞大的数据量问题,尤其是训练得到的参数信息会随着网络的深度呈指数增加,这给在边缘部署深度学习算法带来了严峻挑战。对于嵌入式设备而言,存储空间、计算资源、能耗以及体积限制了理论模型向工程实现的转换,轻量化模型设计成为解决此问题的重要途径。早在1989年深度学习模型还没有被广泛应用之前,LeCun教授就在文献[20]中提出剔除神经网络中不重要参数信息思想,达到压缩模型尺寸的作用,当前很多深度学习模型剪枝算法都是基于文献[20]提出的OBD方法的改进。深度学习模型压缩技术在于减少参数冗余而不会损失较大的预测精度,关键技术难点为压缩量化指标的确定,其研究主要集中在精细化的模型设计、量化、Low-Rank分解、模型/通道剪枝以及遷移学习等方面,相关研究均在特定模型中取得较好的压缩效果,如图2所示。
模型精细化设计将卷积核分解成多个小卷积核组合,优化模型结构的同时大大减少网络参数。量化是通过降低权重参数的比特位数进行模型压缩,例如将32 bit浮点权重转换为8 bit整型以及权重二值化、三值化等,在保证模型精度的同时,极大提高了计算效率,降低了内存占用率。模型训练出的权重矩阵中很多信息是冗余的,Low-Rank分解是用若干小矩阵表达出大矩阵包含的信息,并且不损失模型精度,大大降低模型的计算复杂度和内存开销。模型剪枝分为结构化、非结构化以及中间隐层剪枝,其核心思想是通过判定指标确定模型节点、通道以及参数的重要程度,剔除对模型精度影响不大的部分,并通过再训练对模型进行微调。根据剪枝再训练过程又可分为永久剪枝和动态剪枝,其中永久剪枝完全依赖于训练模型的权重信息,裁剪完成后不再参与训练过程。但是对于网络模型来说,某些权重信息是对后面权重参数的重要补充,永久裁剪后极大降低模型的精度,动态裁剪就是将这些误裁剪的节点重新恢复回来,降低重要参数被裁剪的风险。迁移学习来源于Teacher-Student方法,在结构复杂、泛化性好、精度高的Teacher模型基础上“引导”结构简单、参数量少的Student模型训练,得到和Teacher模型精度相近的结果。
1.3 智能图像制导弹药硬件异构加速研究
对于弹载嵌入式平台而言,硬件是支撑,软件是灵魂,结构复杂的深度学习算法离不开硬件平台强劲的计算能力。考虑到弹载应用环境、作战任务的特殊性,智能图像制导弹药的软硬件系统要满足实时性、低功耗以及体积小等各方面要求。
1.3.1 弹载硬件处理器分析
弹载硬件处理器是智能图像制导弹药的控制中心,完成图像采集、目标检测以及制导控制等功能。国内外鲜有将人工智能技术应用到弹载平台,其根本原因在于高性能处理器和弹载应用环境的适配问题,传统制导弹药大多利用CPU和DSP等处理器完成简单的数据采集、控制等功能,目标检测等复杂算法在PC端实现,存在较高时延,因此高性能硬件处理器成为制约弹药智能化发展的首要因素。
目前,面向AI的高性能硬件处理器可以分为CPU,GPU,FPGA,ASIC以及由其组成的多核结构等。其中,CPU的顺序执行架构决定其在大规模数值计算中存在较大时延,不能满足弹载任务对实时性的要求;GPU包含大量的计算核心,很适合加速并行程度很高的深度学习算法,但GPU的功耗较大,空间狭小的弹载平台不可能提供足够的能耗供GPU工作;与通用处理器CPU和GPU相比,专用处理器ASIC为特定任务定制化的芯片,能获得高效的处理速度和较低的功耗。例如Google的TPU(Tensor Processing Unit, 张量处理器)[39]、国内寒武纪芯片[40]、IBM的TrueNorth以及华为2018年推出的达芬奇架构的昇腾(Ascend 310/910)AI处理器等[41]。由于ASIC针对特定任务量身定做,灵活性差,并且缺少统一的软硬件开发平台,算法移植难度大,无疑提高了智能弹药研发的周期和门槛。现场可编程门阵列(Field Programmable Gate Array, FPGA)是一种计算密集型器件,能够支持各种数据类型精度,例如FP32,INT8及二进制等,芯片上提供许多专用的算术计算单元、逻辑资源模块、片内的存储资源、外围I/O接口等,其可编程特性可以方便地重新配置数据路径,无论是大规模并行、适度并行、流水线连续或者混合形式,都能获得较好的计算能力和效率,更容易满足弹载平台计算、效率、时延和灵活性需求。另外,随着深度学习模型计算复杂度的提高,单一处理器的计算能力远不能满足需求。伴随着各硬件处理器制造工艺水平的发展,多核化、高效能、混合异构等成为高性能处理器的发展趋势,充分利用各自的性能优势进行数据处理,可以更好地提升系统的算力。
考虑到弹载任务的特殊性以及对功耗和硬件体积等限制,基于CPU+FPGA的异构体系逐渐成为智能弹药实现深度学习推理过程的主选方案。例如文献[42]研究了基于FPGA的弹载图像数字采集系统,大大降低图像采集时延;文献[43]将SIFT跟踪算法移植到FPGA平台,实现高于25 f/s的跟踪速度;文献[44]实现了多种深度学习模型在Zynq-7000系列、Zynq UltraScale+MpSoC系列等硬件平台的移植工作,为弹载平台部署提供了理论基础。
在FPGA上实现深度学习算法加速,主要考虑计算模块、控制模块以及数据传输模块的设计,其中,计算模块主要是对卷积运算的硬件加速,是整个硬件加速设计的核心环节;控制模块是整个加速单元的控制系统,负责系统参数同步、初始化以及启动各子模块;数据传输模块主要负责片上缓存和片外内存间的数据调度。各模块之间协调工作,实现各个功能的流水线设计,高效利用硬件资源,满足弹载FPGA异构平台对实时性和功耗的要求。
1.3.2 卷积计算硬件加速
在深度学习模型中,卷积计算量对模型的性能至关重要,对卷积运算进行优化可以从根源上降低模型的计算复杂度,其计算复杂度表示为[45]
O[n, k, p, q]=∑C-1c=0∑R-1r=0∑S-1s=0F[k, c, r, s]·
D0[n, c, g(p, u, R, r, pad_h),
g(q, v, S, s, pad_w)](1)
式中:F为卷积核;D为输入数据;R和S为卷积核的行列;u, v为卷积核在行列方向的滑动步长;pad_h和pad_w为输入数据扩张大小,并且n∈[0, N),k∈[0, K),p∈[0, P),q∈[0, Q),N为每个batch的输入图像个数,K为输出特征图的个数,P和Q为输出特征图的行列,与输入图像的行列、滑动步长以及扩张大小有关。
目前,主流的深度学习硬件加速单元通常采用向量内积[46]、二维阵列及Winograd卷积[47]方式实现卷积神经网络中的矩阵和向量操作。向量内积是将输入和权重参数转换成矩阵乘法形式,利用循环展开和循环分片实现数据的并行流水线设计,其计算复杂度为O(n3),数据映射结构如图3所示。
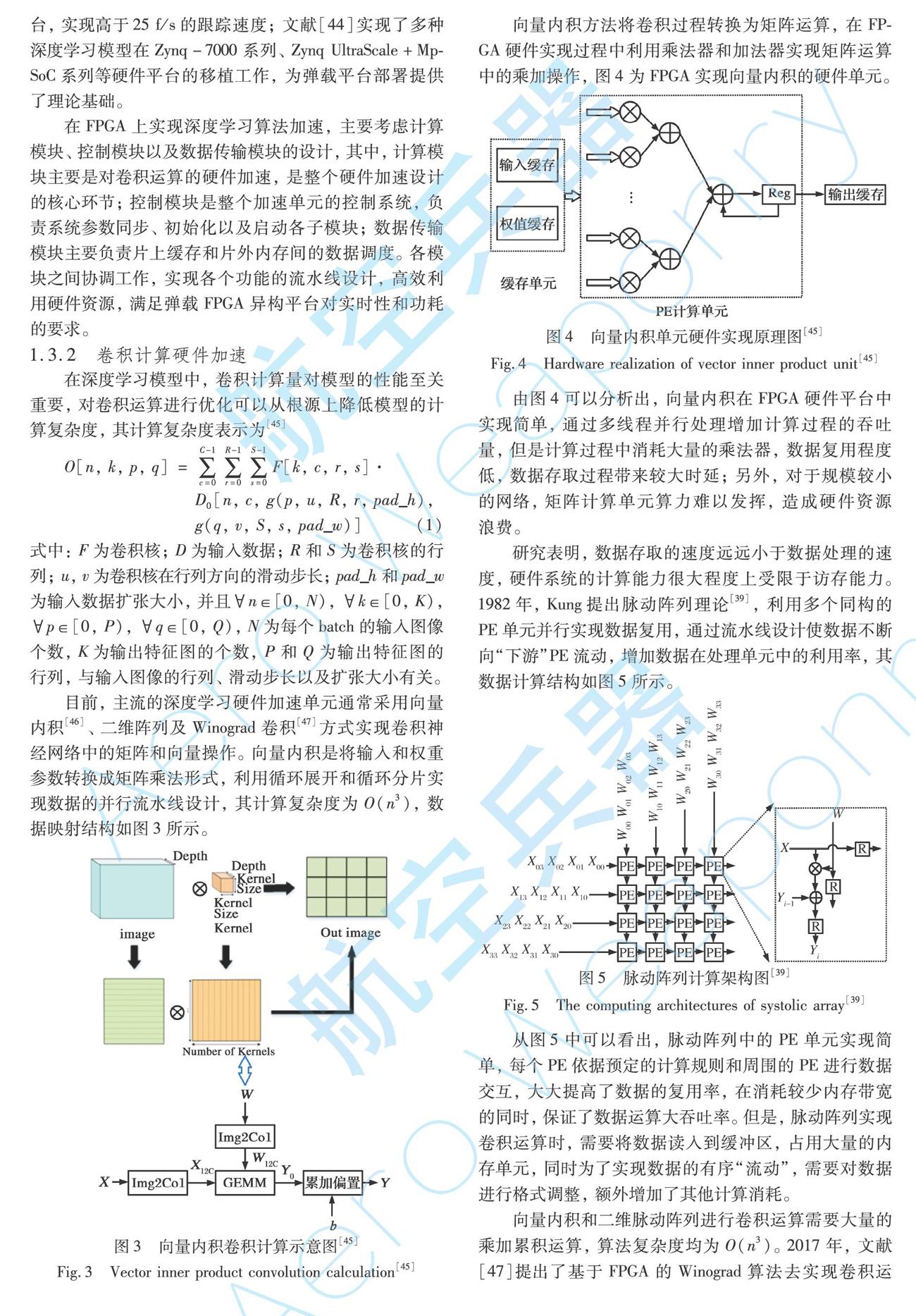
向量内积方法将卷积过程转换为矩阵运算,在FPGA硬件实现过程中利用乘法器和加法器实现矩阵运算中的乘加操作,图4为FPGA实现向量内积的硬件单元。
由图4可以分析出,向量内积在FPGA硬件平台中实现简单,通过多线程并行处理增加计算过程的吞吐量,但是计算过程中消耗大量的乘法器,数据复用程度低,数据存取过程带来较大时延;另外,对于规模较小的网络,矩阵计算单元算力难以发挥,造成硬件资源浪费。
研究表明,数据存取的速度远远小于数据处理的速度,硬件系統的计算能力很大程度上受限于访存能力。1982年,Kung提出脉动阵列理论[39],利用多个同构的PE单元并行实现数据复用,通过流水线设计使数据不断向“下游”PE流动,增加数据在处理单元中的利用率,其数据计算结构如图5所示。
从图5中可以看出,脉动阵列中的PE单元实现简单,每个PE依据预定的计算规则和周围的PE进行数据交互,大大提高了数据的复用率,在消耗较少内存带宽的同时,保证了数据运算大吞吐率。但是,脉动阵列实现卷积运算时,需要将数据读入到缓冲区,占用大量的内存单元,同时为了实现数据的有序“流动”,需要对数据进行格式调整,额外增加了其他计算消耗。
向量内积和二维脉动阵列进行卷积运算需要大量的乘加累积运算,算法复杂度均为O(n3)。2017年,文献[47]提出了基于FPGA的Winograd算法去实现卷积运算,利用加法器代替乘法器减少大量卷积计算中的乘法操作,降低运算复杂度,提高运算速度。对于一维和二维Winograd卷积计算,文献[47]给出了相应的推理证明,如下所示:
Y=AT[(Gg)⊙(BTd)](2)
Y=AT[[GgGT]⊙[BTdB]]A(3)
式(2)和式(3)分别为一维、二维的Winograd卷积计算。其中:g为卷积核;d为输入信号;G为卷积核矩阵;BT为输入转置矩阵;AT为输出转置矩阵;⊙为点乘运算。计算过程如图6所示。
由图6可以看出,Winograd卷积计算充分利用了向量内积和脉动阵列两者的优势,并利用加法器代替传统矩阵计算中大量的乘法操作,实现快速卷积计算,其一维和二维的计算复杂度分别可以表示为O(n)和O(n2),大大降低算法的复杂度。
通过分析可知,任何一个卷积硬件加速架构都有各自的优势,当硬件平台资源充足时,可以采用易于实现、吞吐量大的加速方案,而当资源不足时,要合理划分硬件资源对卷积进行优化设计,实现硬件资源的高效利用。
1.3.3 智能弹药异构加速体系设计
由于弹载嵌入式平台加速深度学习模型主要考虑推理过程,因此,可以在线下利用GPU训练搭建好的网络模型,获得最优的权重参数,再通过模型量化、剪枝等方法实现网络的轻量化设计,最后结合硬件平台资源分布,合理设计硬件加速单元,实现深度学习模型向嵌入式硬件平台的高效移植,其设计流程如图7所示。
其中,模型轻量化设计和硬件加速单元设计是智能弹药异构设计的关键环节。结合深度学习模型卷积层、池化层、激活函数以及全连接层的特征,设计标准化的压缩模型,以适应针对不同弹载任务的深度学习算法。此外,充分分析各处理器在执行深度学习算法中卷积运算、数据共享、指令控制以及任务调度中的性能,设定优先级,让最合适的单元执行相关任务,使得在硬件资源有限条件下获得高效的加速性能。
2 基于DPU的Yolo v3异构加速设计
文中1.1节对智能图像制导弹药任务的特殊性、不可逆性等特点进行了详细分析,为在战争中掌握主动权,基于深度学习的识别检测算法既要准确率高,又要速度快。通过对当前目标检测算法性能分析,Yolo v3在检测速度和识别准确率方面都表现出极佳的性能。为此,本文采用Yolo v3实现战场目标的识别检测。
为加快深度学习模型向弹载嵌入式平台移植,利用深鉴科技的DNNDK(Deep Neural Network Development Kit)编译器[48]对深度学习模型进行编译加速。DNNDK面向深度学习异构计算平台DPU(Deep-Learning Processor Unit)[49],涵盖卷积神经网络推理阶段的模型压缩、编译优化和高效运行时支持等各种功能,为深度学习模型在DPU异构平台上的应用提供了全栈式编译环境,如图8所示。
由图8可以看出,DNNDK编译器为线下训练好的模型提供了针对DPU硬件加速架构的全栈式编译环境,可以实现深度学习算法性能分析、压缩以及DPU异构计算等。其中,DECENT工具将训练好的模型实现高效压缩,并且不会带来太大的精度损失;DNNC编译器将深度学习模型和DPU指令一一映射,实现计算负载和内存访问的高效结合;N2Cube为深度学习模型在DPU硬件加速平台实现资源分配、任务调度以及系统驱动等提供了多种轻量级接口函数,以便实现对硬件资源的充分利用。为此,利用DNNDK来实现Yolo v3在嵌入式硬件平台的移植、实现。
首先,实验使用Tensorflow框架,在1块16 GB的Nvidia GTX1080Ti GPU上完成Yolo v3和Tiny-Yolo v3模型的训练[13],数据集采用公开的无人机目标检测VisDrone2018-Det[14]数据集和弹载相机采集的实景沙盘图像。其中,VisDrone2018-Det数据集为无人机俯视视角拍摄的不同光照、环境以及密度条件下的场景图像,包含行人、汽车、摩托车等10类目标,训练集图片6 471张,验证集图像548张,测试集图像1 580张;弹载相机
采集的实景沙盘图像包含火炮、自行火炮、远程火箭炮、坦克和步战车等5类目标,并通过翻转、旋转和亮度增强等手段对数据集进行扩充,目标图像共2 000张,其中训练集1 600张,验证集100张,测试集300张。
模型训练过程中将两种方式收集的数据集整合,共15类目标,10 599张图片,输入图像大小裁剪为416×416,模型参数设置为:学习率0.001,动量0.9,权重衰减率0.000 5,每批次处理图像32张,经过不断迭代训练后,模型的损失函数基本维持不变,得到训练好的权重参数。利用测试集对训练好的Yolo v3和Tiny-Yolo v3模型进行测试,其在Nvidia GTX1080Ti GPU平台上的检测帧率、mAP和功耗如表1所示。随后,在上述模型训练结果的基础上,利用DNNDK编译器对训练模型的权重参数进行量化、壓缩,并将量化后的模型转化为可在FPGA上执行的底层文件,选用zcu104硬件平台[48]实现Yolo v3和Tiny-Yolo v3的目标识别检测。
上述四个模型分别在两种数据集测试样本上的识别检测结果如图9所示。
通过表1和图9的分析发现,深度学习模型经过DNNDK编译器压缩、编译后,参数量和权重大大减少,虽然基于DPU硬件加速后的深度学习模型存在漏检和检测位置偏移问题,但是其精度损失微乎其微,并且这些性能损失可以人工辅助修正,而其在FPGA上的低功耗性能为深度学习模型在边缘设备部署带来更大的优势。
3 结 束 语
本文分析了深度学习算法向智能图像制导弹药目标识别、检测和跟踪等工程实现中存在的突出问题,从深度学习模型压缩、高性能处理器、卷积硬件加速等方面进行研究,提出了面向深度学习的弹载图像处理异构体系模型。针对图像制导弹药的任务需求,选择准确、快速的目标识别检测算法,通过模型轻量化设计减少模型冗余参数,利用合适的卷积加速理论实现深度学习模型在硬件平台的移植。本文利用深鉴科技提出的DNNDK编译器,实现了Yolo v3算法在zcu104硬件平台的移植,模型参数压缩率80%以上,权重数据压缩率90%以上,检测速度满足弹载平台实时检测的要求,为智能图像制导弹药工程实现提供了设计参考。
参考文献:
[1] 钱立志. 电视末制导炮弹武器系统关键技术研究[D]. 合肥: 中国科学技术大学, 2006.
Qian Lizhi. Research on the Key Technology of TV Terminal Guided Artillery Weapon System[D]. Hefei: University of Science and Technology of China, 2006. (in Chinese)
[2] Krizhevsky A, Sutskever I, Hinton G E. ImageNet Classification with Deep Convolutional Neural Networks[C]∥Advances in Neural Information Processing Systems, 2012, 25(2): 1097-1105.
[3] 赵永强, 饶元, 董世鹏, 等. 深度学习目标检测方法综述[J]. 中国图象图形学报, 2020, 25(4): 629-654.
Zhao Yongqiang, Rao Yuan, Dong Shipeng, et al. Survey on Deep Learning Object Detection[J]. Journal of Image and Graphics, 2020, 25(4): 629-654. (in Chinese)
[4] 阮激揚. 基于YOLO的目标检测算法设计与实现[D]. 北京: 北京邮电大学, 2019.
Ruan Jiyang. Design and Implementation of Target Detection Algorithm Based on YOLO[D]. Beijing: Beijing University of Posts and Telecommunications, 2019. (in Chinese)
[5] Uijlings J R R, van de Sande K E A, Gevers T, et al. Selective Search for Object Recognition[J]. International Journal of Compu-ter Vision, 2013, 104(2): 154-171.
[6] Zitnick C L, Dollár P. Edge Boxes: Locating Object Proposals from Edges[C]∥Proceedings of the 13th European Conference on Computer Vision, 2014: 391-405.
[7] He K M, Zhang X Y, Ren S Q, et al. Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2015, 37(9): 1904-1916.
[8] Girshick R. Fast R-CNN[C]∥Proceedings of the 2015 IEEE International Conference on Computer Vision, 2015: 1440-1448.
[9] Ren S Q, He K M, Girshick R, et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[C]∥ Proceedings of the 28th International Conference on Neural Information Processing Systems, 2015: 91-99.
[10] Shrivastava A, Gupta A, Girshick R. Training Region-Based Object Detectors with Online Hard Example Mining[C]∥ Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 761-769.
[11] Lin T Y, Dollar P, Girshick R, et al. Feature Pyramid Networks for Object Detection[C]∥Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition, 2017: 936-944.
[12] Redmon J, Divvala S, Girshick R, et al. You Only Look Once: Unified, Real-Time Object Detection[C]∥ Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, 2016: 779-788.
[13] Redmon J, Farhadi A. YOLOv3: An Incremental Improvement [EB/OL]. (2018-04-08) [2020-06-01]. https: ∥arxiv. xilesou. top/pdf/1804. 02767. pdf.
[14] Zhang P Y, Zhong Y X, Li X Q, et al. SlimYOLOv3: Narrower, Faster and Better for Real-Time UAV Applications[EB/OL]. (2019-07-25) [2020-06-01]. https: ∥arxiv. org/ftp/arxiv/papers/1907/1907. 11093. pdf.
[15] Fu C Y, Liu W, Ranga A, et al. DSSD: Deconvolutional Single Shot Detector[EB/OL]. (2017-01-23) [2020-06-01]. https: ∥arxiv. org/pdf/1701. 06659. pdf.
[16] Shen Z Q, Liu Z, Li J G, et al. DSOD: Learning Deeply Supervised Object Detectors from Scratch[C]∥Proceedings of the 2017 IEEE International Conference on Computer Vision, 2017: 1937-1945.
[17] 喻鈞, 康秦瑀, 陈中伟, 等. 基于全卷积神经网络的遥感图像海面目标检测[J]. 弹箭与制导学报, 2020, 35(6): 24-31.
Yu Jun, Kang Qinyu, Chen Zhongwei, et al. Sea Surface Target Detection in Remote Sensing Images Based on Full Convolution Neural Network[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2020, 35(6): 24-31. (in Chinese)
[18] 侯凯强, 李俊山, 王雪博, 等. 弹载人工智能目标识别算法的嵌入式实现方法研究[J]. 制导与引信, 2019, 40(3): 40-45.
Hou Kaiqiang, Li Junshan, Wang Xuebo, et al. Research on Embedded Implementation Method of Missile-Borne Artifical Intelligence Target Recognition Algorithms[J]. Guidance & Fuze, 2019, 40(3): 40-45. (in Chinese)
[19] 杨传栋, 刘桢, 马翰宇, 等. 一种基于改进YOLOv3的弹载图像多目标检测方法[J]. 弹箭与制导学报, 2020, 22(6): 1-6.
Yang Chuandong, Liu Zhen, Ma Hanyu, et al. A Multi-Target Detection Method for Missile-Borne Images Based on Improved YOLOv3[J]. Journal of Projectiles, Rockets, Missiles and Guidance, 2020, 22(6): 1-6. (in Chinese)
[20] LeCun Y, Denker J S, Sollar S A. Optimal Brain Damage[C]∥Advances in Neural Information Processing Systems, 1990: 598–605.
[21] Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-Level Accuracy with 50× Fewer Parameters and <0.5 MB Model Size[EB/OL]. (2016-11-04)[2020-06-01]. https: ∥arxiv. org/abs/1602. 07360.
[22] Qin Z, Zhang Z N, Chen X T, et al. FD-MobileNet: Improved MobileNet with a Fast Downsampling Strategy[C]∥25th IEEE International Conference on Image Processing, 2018: 1363-1367.
[23] Chollet F. Xception: Deep Learning with Depthwise Separable Convolutions[EB/OL]. (2017-04-04)[2020-06-01]. https: ∥arxiv. org/abs/1610. 02357.
[24] Wang S J, Cai H R, Bilmes J, et al. Training Compressed Fully-Connected Networks with a Density-Diversity Penalty[J]. International Conference on Learning Representations, 2017: 1121-1132.
[25] Dettmers T. 8-Bit Approximations for Parallelism in Deep Learning[EB/OL]. (2016-02-19)[2020-06-01]. https: ∥arxiv. org/abs/1511. 04561.
[26] Li F F, Zhang B, Liu B. Ternary Weight Networks[EB/OL]. (2016-11-19)[2020-06-01]. https: ∥arxiv. org/abs/1605. 04711.
[27] Courbariaux M, Hubara I, Soudry D, et al. Binarized Neural Networks: Training Deep Neural Networks with Weights and Activations Constrained to +1 or -1[EB/OL]. (2016-04-17)[2020-06-01]. https: ∥arxiv. org/abs/1602. 02830.
[28] Lebedev V, Ganin Y, Rakhuba M, et al. Speeding-Up Convolutional Neural Networks Using Fine-Tuned CP-Decomposition[EB/OL]. (2015-04-24)[2020-06-01]. https: ∥arxiv. org/abs/1412. 6553.
[29] Zhang X Y, Zou J H, He K M, et al. Accelerating Very Deep Convolutional Networks for Classification and Detection[J]. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2016, 38(10): 1943-1955.
[30] Kim Y D, Park E, Yoo S, et al. Compression of Deep Convolutional Neural Networks for Fast and Low Power Mobile Applications[EB/OL]. (2015-11-20)[2020-06-01]. https: ∥arxiv. org/abs/1511. 06530.
[31] Novikov A, Podoprikhin D, Osokin A, et al. Tensorizing Neural Networks[EB/OL]. (2015-11-20)[2020-06-01]. https:∥arxiv. org/abs/1509. 06569.
[32] Hu H Y, Peng R, Tai Y W, et al. Network Trimming: A Data-Driven Neuron Pruning Approach towards Efficient Deep Architectures[EB/OL]. (2016-07-12)[2020-06-01]. https: ∥arxiv. org/abs/1607. 03250.
[33] Li H, Kadav A, Durdanovic I, et al. Pruning Filters for Efficient ConvNets[EB/OL]. (2017-03-10) [2020-06-01]. https: ∥arxiv. org/abs/1608. 08710.
[34] Molchanov P, Tyree S, Karras T, et al. Pruning Convolutional Neural Networks for Resource Efficient Inference[EB/OL]. (2016-11-19)[2020-06-01]. https: ∥arxiv. org/abs/1611. 06440.
[35] Anwar S, Hwang K, Sung W. Structured Pruning of Deep Convolutional Neural Networks[J]. ACM Journal on Emerging Techno-logies in Computing Systems, 2017, 13(3): 1-18.
[36] Moya Rueda F, Grzeszick R, Fink G A. Neuron Pruning for Compressing Deep Networks Using Maxout Architectures[EB/OL]. (2017-07-21)[2020-06-01]. https: ∥arxiv. org/abs/1707. 06838.
[37] Yim J, Joo D, Bae J, et al. A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning [C]∥IEEE Conference on Computer Vision and Pattern Recognition, 2017: 7130-7138.
[38] Hinton G, Vinyals O, Dean J. Distilling the Knowledge in a Neural Network[EB/OL]. (2015-03-09)[2020-06-01]. https: ∥arxiv. org/abs/1503. 02531.
[39] Jouppi N P, Young C, Patil N, et al. In-Datacenter Performance Analysis of a Tensor Processing Unit[EB/OL]. (2017-04-16)[2020-06-01]. https: ∥arxiv. org/abs/1704. 04760.
[40] Chen T S, Du Z D, Wang J, et al. DianNao: A Small-Footprint High-Throughput Accelerator for Ubiquitous Machine-Learning[J]. ACM Sigarch Notices, 2014, 49(4): 269-284.
[41] 梁曉峣. 昇腾AI处理器架构与编程:深入理解CANN技术原理及应用[M]. 北京: 清华大学出版社, 2019.
Liang Xiaoyao. Shengteng AI Processor Architecture and Programming:Deep Understanding the Technology Principle and Application of CANN [M]. Beijing: Tsinghua University Press, 2019. (in Chinese)
[42] 高阳. 弹载数字图像采集系统研究[D]. 太原: 中北大学, 2017.
Gao Yang. Research on Digital Image Acquisition System for Missile[D]. Taiyuan: North University of China, 2017. (in Chinese)
[43] 邱晓冬. 基于FPGA的SIFT图像匹配系统实现与优化[D]. 南京: 东南大学, 2019.
Qiu Xiaodong. Implementation and Optimization of SIFT Algorithm Based on FPGA [D]. Nanjing: Southeast University, 2019. (in Chinese)
[44] XILINX White Paper. Vitis AI Library User Guide [EB/OL]. (2019-10-01)[2020-06-01]. https: ∥www. xilinx. com/support/documentation/ai_inference/v1_6/ug1354-xilinx-ai-sdk. pdf.
[45] Dukhan M. The Indirect Convolution Algorithm[EB/OL]. (2019-07-03)[2020-06-01]. https: ∥arxiv. org/abs/1907. 02129.
[46] Chetlur S, Woolley C, Vandermersch P, et al. CuDNN: Efficient Primitives for Deep Learning[EB/OL]. (2014-11-18)[2020-06-01]. https: ∥arxiv. org/abs/1410. 0759.
[47] Liang Y, Lu L Q, Xiao Q C, et al. Evaluating Fast Algorithms for Convolutional Neural Networks on FPGAs[J]. IEEE Transactions on Computer-Aided Design of Integrated Circuits and Systems, 2020, 39(4): 857-870.
[48] XILINX White Paper. DNNDK User Guide [EB/OL]. (2019-08-13) [2020-06-01]. https: ∥www. xilinx. com/support/documentation/sw_manuals/ai_inference/v1_6/ug1327-dnndk-user-guide. pdf.
[49] XILINX White Paper. Zynq DPU v3.2 Product Guide [EB/OL]. (2020-03-01)[2020-06-01]. https: ∥www. xilinx. com/support/documentation/ip_documentation/dpu/v3_2/pg338-dpu. pdf.
Research on Heterogeneous Acceleration of Deep
Learning Method for Missile-Borne Image Processing
Chen Dong, Tian Zonghao*
(Laboratory of Guidance Control and Information Perception Technology of High Overload Projectiles,
Army Academy of Artillery and Air Defense of PLA, Hefei 230031, China)
Abstract:
The problem existing in the transformation of deep learning algorithm to engineering application is analyzed. Combining with the characteristics and development trends of army intelligent ammunition, the missile-borne image processing heterogeneous accelerate system for deep learning is put forward based on the research of compression, quantitative and hardware heterogeneous acceleration, realizing heterogeneous hardware design. The DNNDK is used to compress and quantify the Yolo v3 model. The weight and parameter compression rate are more than 90% and 80%, realizing the lightweight design of Yolo v3. Based on the DPU hardware acceleration architecture, the algorithm is transplanted to the missile-borne embedded platform, and its power consumption and detection efficiency meet the requirements of missile-borne image processing.
Key words: missile-borne image; deep learning; FPGA; systolic array; Winograd convolution
收稿日期:2020-06-01
基金項目:军队“十三五”预研基金项目 (301070103)
作者简介:陈栋(1983-),男,安徽合肥人,副教授,博士,研究方向为新型弹药技术研究与运用、武器系统运用与保障工程。
通讯作者:田宗浩(1991-),男,河北晋州人,博士研究生,研究方向为智能弹药、图像处理。
