社交媒体大数据的教育应用研究:价值、路径与挑战
2021-08-12李彤彤李坦郭栩宁
李彤彤 李坦 郭栩宁
【摘要】 社交媒体已经成为学生记录生活、表达观点、分享交流等的最主要途径,也是反映学生真实状态可靠、即时的大数据来源之一。真实、准确、及时的社交媒体大数据样本蕴含着巨大的教育价值,为教育研究提供了更丰富的可能。从价值角度看,通过对社交媒体大数据进行情感分析、主题挖掘、社会网络分析等,可以实现学习者画像、学习者危机发现、教学过程优化和教育舆情分析等,从而为利益相关者提供决策参考与支持。从技术角度看,将应用的路径概括为数据采集与预处理、数据存储、数据分析和可视化四个阶段,并总结了每个阶段常用的方法。多源异构数据的整合应用、数据挖掘的合理性与准确性、伦理隐私问题等是社交媒体大数据教育应用所面临的主要挑战,也是未来研究需要重点关注的方面。
【关键词】 社交媒体;大数据;社交媒体大数据;教育大数据;教育数据挖掘;教育数据应用;价值;路径;挑战
【中图分类号】 G434 【文献标识码】 A 【文章编号】 1009-458x(2021)7-0036-09
社交媒体(Social Media)又称为“社会化媒体”或“社会性媒体”,这一术语普遍认为最早出现在Antony Mayfield所著的What Is Social Media一书中,被定义为“包含参与、开放、社交、社区性、联通性等特点的一组新型在线媒体”。社交媒体是Web 2.0时代的产物,其最核心的特征有两个:一是对个体而言,它赋予了每个人创造并传播内容的能力,人人都可以成为信息的生产者;二是对群体而言,它提供了丰富的联结机会,形成了庞大的全民社交网络,每个个体都成为社交网络上的结点。当前,社交媒体平台飞速发展,平台种类、数量、功能繁杂,谭天等(2017)将其分为平台型、社群型、工具型和泛在型四种类型。其中,平台型以微博、微信为代表;社群型以豆瓣、知乎、QQ、论坛、BBS网络社区等为代表;工具型指以教育功能为目的开发的社交媒体软件,如以英语口语交流为目的开发的HELLO TALK、专为大学生社交打造的叽喳校园等;泛在型并非一种单独形态的社交媒体,而是以社交属性的内容和服务“嵌入”各类媒体形态中,指在软件中含有社交功能的应用,如“蓝墨云班课”课程圈、“课程格子”朋友圈等。社交媒体的应用普及率逐年升高,据中国互联网信息中心(China Internet Network Information Center)发布的《2016年中国社交应用用户行为研究报告》显示,微信朋友圈、QQ空间、新浪微博的网民使用率分别是85.8%、67.5%、37.1%。社交媒体的蓬勃发展和广泛应用带来了数据的爆炸式增长,推动了大数据时代的到来。各个领域也开始发掘社交媒体信息的巨大价值,于是有了社交媒体大数据的概念,我们将其界定为社交媒体上产生的具有动态性、实时性、社交网络依赖性的用户数据。
在教育领域,社交媒体大数据的价值也开始日益凸显。安德森等(2017)认为社交媒体是教育技术的三大支柱之一,对教育有着多方面的促进作用,与教育的融合已势不可挡(安德森, 等, 2020)。《2016年中国社交应用用户行为研究报告》显示,在校学生已经成为社交媒体使用人数最多的群体,占比25%。社交媒体已经成为学生记录生活、表达观点、分享、交流等的最主要途径,也是反映学生真实状态的即时、可靠的大数据来源之一。真实、准确、及时的社交媒体大数据样本为教育研究提供了更多的可能性。大数据技术的发展也将这种可能性更多地转化为现实,通过对社交媒体大数据进行深度挖掘以优化教育教学正在成为研究者的关注点。但是,当前教育领域对社交媒体大数据的挖掘应用仍处于初级探索阶段,对于社交媒体大数据的巨大价值、挖掘方法以及面临的挑战还不够系统、清晰。鉴于此,在系统分析与梳理文献的基础上,从功能与价值、方法与路径、挑战与机遇三个方面对社交媒体大数据教育应用的现状进行了总结。在文献筛选过程中,我们以“大数据”“教育”作为一级关键词,进一步选取其中与社交媒体大数据应用相关的文献。在文献梳理过程中,我们主要以“应用社交媒体大数据做了什么”“如何应用的”为线索,逐级归纳得出结论。
一、功能与价值
据统计,国内社交媒体应用于教育教学的研究最早始于2003年(林育曼, 2018),而应用大数据方法来辅助教育教学却是近几年才开始的。当前社交媒体大数据在教育教学上的应用可以概括为学习者画像、学习者危机发现、教学过程优化和教育舆情分析四个方面。
(一)学习者画像
画像技术最先在商业领域得到应用,之后不断向外拓展,教育领域也开始引入,并将学习者画像作为一种描绘学习者特征的方法。学习者画像是通过对学习者群体进行分类描述并标签化的过程(陈海建, 等, 2017; 肖君, 等, 2019),有利于更好地识别学习者,从而帮助教师、管理者及其他利益相关者精准地了解学生的各种特征,为开展个性化教学和管理提供决策支持。
精准的学习者画像通常需要对多源异构数据进行综合分析,因此社交媒体数据通常作为支持学习者画像的一部分。鉴于准确识别学习者的目的,学习者画像一般基于有一定封闭性而非完全开放的社交媒体数据来源,如学校论坛、智慧校园平台等。李光耀等(2018)将用户画像技术应用在智慧校园中, 设计了包含基础属性、性格属性、特长爱好、成绩优劣四类特征的学生画像标签体系,标签的生成借助静态和动态两类数据,静态数据主要来源于智慧校园的管理系统,动态数据主要来源于社交媒体类应用。同时,研究者多从某一个或某几个维度探讨基于社交媒体大数据的学习者画像“标签”体系。周文静(2018)提出一种基于用户兴趣的学生画像方法,主要考虑学生的基本属性维度和兴趣维度,从校园论坛中提取数据,应用基于情感词对的关键字兴趣提取方法以及基于文本情感傾向的概念兴趣提取方法进行学生兴趣维度画像,较准确地反映出学生的兴趣。对于应用社交媒体大数据进行学习者画像的具体方法,也多是模仿商业领域的用户画像方法。Xiao等(2017)基于栈式自编码器(Stacked Autoencoder)和深度信念网络(Deep Belief Network)两种深度学习算法构建了用于识别学生和非学生微博的分类器等。
(二)学习者危机发现
学习者危机一般可以分为学业危机和心理危机两大类。通过社交媒体大数据的分析,可以在一定程度上发现可能存在危机的学生,从而为针对性的干预提供依据和参考。
社交媒体大数据用于学业危机发现最典型的是大规模开放在线课程(MOOC)中辍学和成绩的预测。当前MOOC辍学率极高,据统计,哈佛大学开设的“计算机导论”课程结业率仅为0.923%,麻省理工学院开设的“电路与电子学”课程结业率仅为4.6%(Rai & Deng, 2016),及时识别有辍学倾向的学生并有针对性地进行干预,是确保学生完成学业的重要手段。Wang等(2018)基于MOOC平台大数据提出了一种语义分析模型来跟踪学习者的情感倾向,从而判断学生对课程的接受程度,并进一步通过情感量化机器学习方法构建了学业预警模型,能够及时发现无法正常完成学业的学生,有针对性地进行干预来提升课程的完成率。Wen等(2014)对Coursera论坛帖子进行挖掘,通过布朗聚类算法研究学习者对课程的集体情感态度,同时建立生存模型评估情感对学习者流失的影响,结论表明,学习者的集体情感与退学率存在显著相关。舒莹等(2019)对学生在线学习的过程性结构化外显信息和非结构化内隐信息进行整合,采用朴素贝叶斯网络算法识别学习者学习状态与趋势,从而发现学习危机学生。
目前研究中更多的是社交媒体大数据用于心理危机的识别。社交媒体已经成为人们分享和表达情感的常态化形式,对社交媒体大数据进行情感挖掘和分析有助于发现学生非正常情感。孙婉婷(2016)从新浪微博、人人网和百度贴吧采集文本,依据学生实际建立情感词典,并研究出一种表情符号和文本倾向度加权的情感分析方法,从而建立了学生心理预警系统。唐厚强(2017)提取电子科技大学学生论坛中学生发布的帖子信息,提出一种回归和分类相结合的算法,实现对学生在论坛中发布信息时心理状态的研判和对学生成绩的预测。李鹏宇(2014)通过分析新浪微博中抑郁用户的语言和行为等特征,建立了两种机器学习模型,分别用于预测用户有抑郁倾向和无抑郁倾向,通过对1,502名高校学生微博信息进行实证研究,发现大学生抑郁的概率与性别存在显著相关等规律。张金伟等(2013)构建了基于性格、心情和情感空间的多层心理预警模型,使用情感词典法对高校学生微博文本进行分析,从而识别出可能存在危机的学生并进行预警。
(三)教学过程优化
通过社交媒体大数据可以在一定程度上监测学生的学习进度、学习表现、兴趣点、困难点等状态与需求,从而为教师调整和优化教学过程提供依据。目前基于社交媒体大数据进行教学过程优化主要有教学策略调整和教学资源推荐两个方面。
教学策略调整是指通过挖掘产生的知识有针对性地为每一位学习者提供个性化指导或改进教学方法。Anaya等(2009)为了提升网络教育环境下学习与管理的效果,以论坛中学习者互动的统计指标为依据,使用聚类算法作为推理方法,将学习者协作学习能力呈现给导师和学习者,并据此有针对性地调整和改进协作学习策略。
教学资源推荐是指通过挖掘得出的规律有针对性地进行资源或工具的推荐,帮助学习者快速找到所需资源。Yang等(2014)为解决学生在含有大量帖子的课程论坛中找不到合适主题帖子的问题,提出了一种融合学生同伴关系、学生活动整体指标、全局特征和主题特征的自适应矩阵分解方法,实现对帖子的全面分析和有针对性的合理推荐。秦昌博(2017)为了提高教师在课程论坛中答疑的效率,以中文慕课为研究对象,构建了支持向量机分类器对学生课程论坛中帖子所表现出来的情感进行分类,并将“解释”“困惑”两种情感倾向的文本通过TF-IDF和TextRank算法提取出文本中所包含的难点,教师可以对“解释”“困惑”的帖子有针对性地进行解答,节省了教师逐条浏览帖子的大量时间。
(四)教育舆情分析
舆情即舆论情况,亦即民众的情绪、意见和态度(舒刚, 2016)。教育舆情是指在一定的社会空间内,作为主体的民众针对有关教育中介型社会事项所产生和持有的社会政治态度(李昌祖, 等, 2014)。通过教育舆情分析,教育管理者可以清楚地了解和监测公众对教育事件的态度,进而有针对性地进行政策调整和舆论引导。
目前,通过社交媒体大数据进行教育舆情分析的研究和实践可以概括为两个方向:一是通过主题分析发现热点事件;二是针对某一事件进行公众情感的分析。殷红等(2018)基于大数据技术构建了一个教育网络舆情分析系统,从社交媒体、教育网等平台采集教育舆情信息,利用主题模型进行教育舆情事件挖掘,通过聚类将多源数据进行融合,最后通过情感分析技术挖掘大众对某些教育事件的情绪,并通过对比研究发现教育事件的发展规律。于卫红(2017)开发了一款多Agent高校网络舆情监测系统,包含采集、预处理、舆情分析和简报生成四个主要功能,从社交媒体平台提取主题帖,远程调用R语言进行舆情分析并生成简报供学校相关部门参考使用。
二、方法与路径
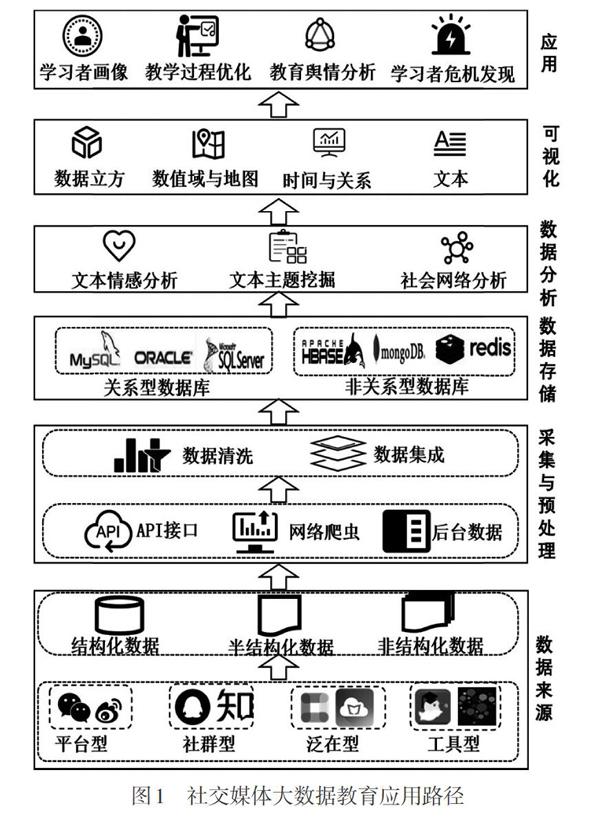
目前,社交媒体大数据分析一般都需要经历数据采集与预处理、数据存储、数据分析和可视化四个阶段(如图1所示)。
(一)数据采集与预处理
1. 数据采集
社交媒体数据采集一般有三种方法:API、网络爬虫和数据库获取。
(1)API(Application Programming Interface,应用程序编程接口)是一组预先定义的函数,外部開发人员不需要了解程序内部的工作机理,仅仅通过简单的调用便可实现相应的功能。如新浪微博提供开放的API接口,允许外部开发者获得用户发表的博文信息,而不需要了解微博内部数据存储和通讯等工作原理。目前主流的社交媒体平台(如新浪微博、百度贴吧、Twitter、Facebook等)均开放了API,只需申请便可根据需求进行调用。
(2)网络爬虫,又称“网络机器人”,是一种自动抓取网络数据的程序。爬虫可以模拟人为登录行为,根据预先制定的规则对网页中符合要求的文本、图片、视频等数据进行自动采集并保存至本地。主流的开源爬虫框架包括Scrapy、Crawley和PySpider等。
(3)服务器数据库记录着学生各项数据,如成绩、学习时长、登录时长、讨论文本、弹幕、图片、视频和上传的文件等;网络日志记录着学生登录操作、页面跳转等重要信息,可以借助Logagent、Filebeat和Logstash等工具进行采集。
2. 数据预处理
数据预处理是比较耗时却至关重要的过程,主要包括数据清理和数据集成(韩家炜, 等, 2012)。
(1)数据清理主要对空值进行处理、对离散值数据进行发现和清除等。最常用的方法是利用回归、贝叶斯和判定树等算法将空缺部分填入概率最大的值,还可以用全局常量替换空缺值、取平均值填补空缺等方法。
(2)数据集成是将相互关联的多源异构数据存储在一起,通常需要解决三个方面的问题:模式集成、数据冗余和数据冲突。模式集成是将采集自不同数据源中的实体进行匹配与集成,将具有相同含义的实体进行识别,是模式集成的重要部分。对于数据冗余,一般通过相关分析(如卡方检测、协方差等)进行检测。数据冲突主要由于多源数据源对同一事物描述不同导致的,目前主要有X-Specs(Lawrence, 2001)和COIN(Goh, 1997)两种处理方法。
(二)数据存储
不同类型的数据需要分别存储,结构化数据指字段类型和长度得到定义的数据,如学生人口学数据、登录次数、登录时长、论坛参與绩点等,通常存储于关系型数据库中。目前主流关系型数据库有MySQL、SQL Server和Oracle等。非结构化数据没有预先定义数据模型,没有严格的数据格式,如发表的博文、语音、视频、图片、文档等,其存储数据库大致可以分为键值存储数据库、列存储数据库、文档型存储数据库和图形数据库四类。键值存储数据库使用一张哈希表,表中的有键和指针指向特定的数据,代表性的数据库主要有Oracle BDB、Tyrant和Redis。列存储数据模型主要来自Google的Big Table(申德荣, 等, 2013),以HBase、Riak和Cassandra为代表,其最大的优势在于读写速度较快,更适合大数据处理。文档型数据库有CouchDB、MongoDB等,文档一般以特定的格式(如JSON)存储在数据库中,该类型数据库对数据结构要求不严格,表的结构也是可以发生变化的。图形数据库主要用于社交网络和推荐系统,更加专注于构建关系图谱,典型数据库有Neo4J、InfoGrid、Infinite Graph等。
(三)数据分析
社交媒体中最常见的数据形式是文本、表情符号、图片和微视频等,其中包含着复杂的关系网络。当前,教育领域对社交媒体图片和视频进行挖掘分析还相对较少,研究和实践较多的是文本挖掘和关系挖掘,对表情符号的挖掘一般也是转化为文本进行分析。文本挖掘最常见的是文本情感分析和文本主题挖掘,关系挖掘最常用的方法是社会网络分析。
1. 文本情感分析
情感分析,又叫“观点挖掘”,是从文本中发掘人们对某物体、事件等的观点、评价、情感、情绪和态度等(刘兵, 2018)。文本情感分析最常用的方法是情感词典法和机器学习法。
(1)情感词典法
情感词典法一般先建立情感词典,对词典中每个词赋予相对应的权重值,随后对文本进行分词并对其中的情感词进行加权计算,最终计算出整条微博的情感权重值,以此界定该博文的情感倾向。情感词典主要由情感词、情感短语和成语组成。目前比较成熟的中文情感词典主要有知网(HowNet)、大连理工大学情感词汇本体库(徐琳宏, 等, 2008)、台湾大学中文情感极性词典等,英文情感词典有WordNet、General Inquirer和CYC知识库等。研究者大多根据实际需求在这些已有词典的基础上进行完善或重建,继而进行情感分析。Min等(2014)汇总《情感分析词集》《台湾大学中文情感极性词典》《褒贬义词典》中正面和负面词汇组成新的情感词典,对采集自BBS论坛的数据进行情感计算。孙波等(2015)将常用微博表情符号和人工标注出的常用新词与伪词组合成“情感符号表”,以大连理工大学情感本体库为基础,采用逐点互信息(Pointwise Mutual Information,PMI)方法进行计算,构建了符合学生风格和微博特点的学生情感词典,并在此基础上设计了学生微博情感计算方法。情感词典法具有较高的准确率,但也存在召回率低的问题。同时,构建一个符合某项需求的词典往往需要耗费较大的人力和物力,成本较高。
(2)机器学习法
随着语料库、语言知识库的发展,越来越多的研究人员开始采用机器学习方法训练语言模型,用以对文本进行情感分析。基于机器学习的情感分析可以理解为基于文本中表现出的情感进行文本分类的过程,主要算法包括支持向量机、朴素贝叶斯、决策树、K-临近、潜在狄利特雷分布模型(Latent Dirichlet Allocation,LDA)等。帕玛纳等(Permana, Rosmansyah, & Abdullah, 2017)采用贝叶斯分类器建立模型,通过分析学生Twitter文本来预测学生学习的满意度,准确率达84%。针对社交媒体大数据语法不规范难以进行情感分析的问题,刘志斌(2016)提出了一种基于情感词抽取的LDA分类方法,该方法对学校网站留言情感识别准确率为93.1%,对微博学生情感识别准确率为74.2%,BBS识别准确率为79.6%。Wei等(2017)提出了一种基于卷积神经网络和长短时记忆模型的转移学习框架,用于自动识别MOOC论坛中的文本是否存在困惑情绪以及困惑的紧迫性。
2. 文本主题挖掘
文本主题挖掘可以从大量文本中提取出学习者集中关注的话题,以达到提炼主要论点的目的。文本主题挖掘在教育领域的典型应用是对论坛中的帖子进行分类。向量空间模型和N-gram文本特征提取是较为传统的文本主题提取算法。随着技术的发展,一些基于机器学习、深度学习的算法开始引起人们的关注,如LDA主题模型、卷积神经网络、贝叶斯算法等。Lin等(2017)为了对慕课论坛中学生发帖主题进行分类,提出一种基于用户交互行为数据为特征的卷积神经网络(Convolutional Neural Networks,CNN)模型。由于将用户交互行为数据作为特征,该模型可以保证不受教学内容以及语言的限制,因此在慕课论坛主题分类中表现较好。王嘉伦(2015)首先利用LDA主题模型提取Coursera论坛中帖子的主题,随后分别研究不同特征条件下的分类器的分类效果,通过对比实验发现基于混合特征训练的分类器效果明显好于仅使用帖子主题特征训练的分类器。
3. 社会网络分析
社交媒体最重要的功能之一便是促进了复杂社交关系网络的形成,其中的复杂关系(如学习者之间的人际关系等)可以通过社会网络分析方法进行挖掘。社会网络分析方法是社会学家根据数学方法、图论等发展起来的定量分析方法,它可以对各种关系进行精确的量化分析(斯科特, 2007)。在教育研究中,研究者侧重对学习者所构成社会网络的密度、中心性和凝聚子群等进行分析。密度分析用于研究学习者之间联系的紧密程度;中心性分析用于分析某个学习者在学习团体中的重要性;凝聚子群分析可以发现不同学习者之间构成的小团体。当前教育研究中社会网络分析多借助一些成熟的软件来实现,如UCINET、Pajek、NetDraw、Mage等。黎加厚等(2007)在研究网络时代教育传播规律时,以苏州教育博客“推荐博客”群体为研究对象,采用UCINET软件对该群体中密度、出度、入度和中心性进行研究,发现密度、中心性和对象多元性对创新能力有着显著正向影响。赵红霞等(2016)采用类似方法对新浪微博上“留守儿童”标签用户进行检索,通过社群图分析、中心性分析、凝聚子群分析发现主题微博中存在的问题并给出建议。此外,还有一款专门用于教育的社会网络分析软件——SNAPP,这是基于社交网络分析的实时诊断系统,用于研究论坛中学生实时交互情况、中心性等信息,并根据需要进行干预。SNAPP支持在流行的商业和开源学习管理系统中使用,如Blackboard、Desire2Learn和Moodle平台等,目前2.0版本可视化功能逐渐完善,已具备动态演示社会网络变化的功能。
(四)数据可视化
经过上述分析过程直接产生的数据结果往往需要进行科学解释才能为实际应用提供参考,这对无数据分析基础的教育研究者或实践者是相对困难的,因此需要将数据可视化。可视化技术是指通过计算机和图像处理技术将数据生成直观的图形,通过屏幕呈现,并可以进行交互处理的技术(刘勘, 等, 2002)。可视化技术可以清晰、直观地呈现数据分析产生的“知识”,增强数据结果的可读性,是大数据处理不可或缺的环节。
当前常用的数据可视化方法有数据立方体、数值域、时间与关系和文本文档四种类型(阮彤, 等, 2016)。数据立方体是一种多维矩阵,从多个维度呈现直观结果,常见的形式有折线图、柱状图、散点图、星状图等;数值域是指在某个空间上密集分布的数据场,由分布于全场的网格和网格节点上的属性构成,常见的形式有矩阵、热力图、直方图、地图等;在时间与关系中时间维度通常用于呈现事物随时间序列变化发展的情形,如日历图、甘特图等,关系维度则是表明两个事项之间的关联,如维恩图、旭日图、树图等;文本文档属于一类特殊的可视化方法,一般包括字符云、主题河流和文档散等。研究者一般综合使用这几种方法进行数据可视化,并且大多会开发相应的可视化工具来系统性地呈现数据。加西亚塞兹等(García-Saiz, Palazuelos, & Zorrilla, 2014)为了帮助教师发现学生在论坛中的行为模式和挖掘学生辍学倾向,采用数据立方体、时间与关系可视化方法,基于社会网络分析和数据挖掘技术开发了可视化工具——EIWM,该工具能够实现“学生表现或者辍学倾向的预测(分类任务)”“博客或者论坛的协作分析(社会网络分析)”“论坛和博客中的社区发现(社会网络分析)”等功能。Fu等(2016)采用数据立方体、数值域和时间与关系可視化方法,基于MOOC课程论坛开发了iForm可视化系统,可以多维度显示课程参与指标,包括用户和帖子总体变化趋势、学生交互关系、不同用户随着时间变化的动态模式等。
三、挑战与机遇
在应用社交媒体大数据的过程中主要面临三大挑战:多源异构数据的融合应用问题、数据挖掘的合理性问题和伦理隐私问题。挑战与机遇并存,这也是社交媒体大数据在教育领域被深入挖掘应用所需要进一步探究的问题。
(一)多源异构数据的融合应用问题
独立的数据源获取的信息是有限的,数据源的融合更有利于深度挖掘数据的价值。如在商业领域将销售记录与天气、地理位置、社交媒体等数据结合分析,很容易发现影响销售收入的外在因素;将社区房地产价格与价格历史、近期交易记录、物业动态等结合,可用于预测社区房产价格走势等(桑基韬, 等, 2014)。然而,当前教育大数据可能来自领域数据库、知识库或者Web页面的开放信息等渠道或平台,具有多源异构的特征。而且,这些数据被物理存放在不同的系统中,各个平台关注的用户行为信息不同,提取到的信息类型也不统一,并且存在跨平台用户,这些割裂的多源异构数据造成了各种数据孤岛,给大数据分析带来非常大的挑战。如何将这些割裂的数据进行合理整合应用,从而发现新规律,更全面、精准地利用大数据,是当前社交媒体大数据深入挖掘面临的巨大挑战。
通过文献调研可以看到,社交媒体大数据可以用以支持学习者画像、危机发现、教学过程优化和舆情分析等,但这仅仅是教育大数据的一部分,将其作为单一数据源来进行学习者画像等是有其局限性和片面性的。教育是一项复杂的交互活动,通过大数据提供精准的支持和服务,仅仅依靠分析某个社交媒体平台或者只掌握社交媒体大数据是远远不够的,需要对多源异构数据进行综合分析。当前,已有研究者关注大数据的多源异构问题,在研究中假设跨平台的共同用户存在,但并没有真正找到能够提取不同社交媒体平台之间的用户显性对应关系的方法,这为用户跨平台数据的整合分析带来较大的阻碍,未来的研究可以进一步关注如何解决多平台共同用户发现这一问题。同时,不同的社交媒体平台产生的数据有着多模态的特征,数据结构并不一致,如微博的文本信息流数据、视频分享网站的流媒体数据、社交过程中的用户交互数据、地理位置数据等。不同模态数据的处理和整合应用方法也是需要进一步研究的问题。
(二)数据挖掘的合理性与准确率问题
一方面,由于多源异构数据处理所面临的技术挑战,社交媒体大数据的应用仍停留在浅显的挖掘层面,其蕴含的价值并没有得到充分挖掘。如文中提到的学习者危机发现仅通过某个平台的文本进行挖掘,没有考虑到融合用户多平台中的数据以及时间序列特征,分析难免存在片面性和局限性。
另一方面,社交媒体大数据分析通常涉及语义理解,计算机语义理解的准确率较低也是当前面临的困境之一。学习者在社交媒体中发布帖子等具有随意性,语法使用不规范等问题频繁发生,加之汉语本身所具备的一些特性(如反语等),使得学习者真实表达的语义有时并不能从字面进行理解。当前在汉语语义理解层面,基于统计的机器学习算法很难理解其内在的真实含义,而深度学习在此领域的研究也刚刚起步。随着深度学习技术的发展,社交媒体大数据的分析准确率也会随之改进,数据中蕴含的知识也会更有效、更准确地被挖掘出来。
(三)伦理隐私问题
虽然有些学习者在使用社交媒体时有意将个人信息隐藏,但是其在社交媒体中留下的“足迹”(零碎的信息)经过大数据分析,也可以“拼凑”出一个学生的基本面貌。同时,现在越来越多的科研机构和个人为了研究方便,经常公开一些数据集,而数据集大多来自学习者的真实信息,虽然在进行数据公开时做了匿名化处理,但依然可以从匿名数据中挖掘出部分用户特征。如何保护利益相关者的数据隐私也是社交媒体大数据应用面临的一大挑战。
对于隐私数据的保护,已经越来越引起教育研究者的关注。北京师范大学智慧研究院发起编制了《在线学习中的个人数据和隐私保护:面向学生、教师和家长的指导手册》,提出了在线学习中与个人数据和隐私相关的5个阶段、30个安全问题和具体操作建议,对教育领域数据隐私安全水平的提升具有重要的参考价值。本研究认为对社交媒体大数据的隐私保护,未来可以进一步从法律法规、行业自律和大数据技术三个层面推进。
1. 法律法规层面
我国宪法明确规定“公民的通信自由和通信秘密受法律的保护”。同时,私人信息属隐私范畴。据报道,全国人大常委会已将制定个人信息保护法列入立法规划。个人隐私权的保护是国家法律层面一贯重视的,并且正在逐步完善,这些都为个人信息隐私的保护提供了重要法律依据。
2. 行业自律层面
社交媒体运营商存储着大量隐私数据,他们也非常重视对敏感数据的保护、使用和发布等。相关协会和企业通过制定公约的形式对数据的使用和保护方式进行约定。中国互联网协会发布的《博客服务自律公约》规定,“博客服务提供者应尽到保密义务”。《互联网搜索引擎服务自律公约》规定,“搜索引擎服务提供者有义务协助保护用户隐私和个人信息安全”。除此之外,国内不少互联网公司(如百度、腾讯、阿里巴巴、华为等)也出台了相应的自律规范。
3. 大数据技术层面
法律法規和行业自律对于大数据行业观念层面起着引领作用,更为关键的是从技术层面真正做好相关约束,切实做到保护利益相关者的隐私。方滨兴等(2016)提出了大数据隐私保护生命周期模型,指出在大数据发布、存储、分析和使用四个阶段中均面临隐私泄露的风险,并且分析了当前可采用的技术以及未来的发展趋势,为大数据隐私保护提供了思路和技术上的引领。在社交媒体大数据使用阶段,基于位置的隐私信息也是当前研究的热点,如莫克贝尔等(Mokbel, Chow, & Aref, 2015)提出了一种k-anonymity保护方法,周艺华等(2019)提出了一种基于GeoHash的位置保护策略,等等。
四、总结
当前,随着大数据技术的不断发展,社交媒体大数据蕴藏的巨大教育价值已经逐渐被挖掘并应用。社交媒体大数据教育应用国内研究侧重高等教育领域,面向中小学阶段的研究较少,这与我国目前的教育环境有关,大多数中小学校限制使用移动设备,这也限制了中小学生社交媒体的应用。同时,目前大数据与教育相关的论文较多,但是大多数偏向理论构建,实证研究偏少。
社交媒体大数据挖掘可以为教师、管理者、学生、家长等利益相关者提供相应的决策支持,但目前的学习者画像、学习者危机发现、教学过程优化和教育舆情分析都普遍存在由于数据源不全面而导致的数据价值未被充分挖掘的问题。社交媒体大数据可以作为对学习者进行分析的补充性数据源,但必须跟学习者其他数据(如学生管理系统数据等)进行综合分析,才能有助于更全面、精准地发现问题,也才能更好地体现其价值。同时,社交媒体大数据的应用有赖于自然语言理解等技术的支持,当前由于语法不规范等问题导致的数据分析准确率还比较低,需要进一步建立和完善面向青少年学生的语料库,随着技术的发展和语料的累积,数据的分析率也会逐步提高。而且,当前研究和实践对教育隐私数据保护还未引起足够的重视。总之,教育技术领域的研究者与实践者需要从大数据技术和教育实践的角度深度挖掘需求,探寻技术与教育无缝整合的方式,使大数据真正融入教育,影响教育,变革教育。
[参考文献]
陈海建,戴永辉,韩冬梅,等. 2017. 开放式教学下的学习者画像及个性化教学探讨[J]. 开放教育研究,23(3):105-112.
方滨兴,贾焰,李爱平,等. 2016. 大数据隐私保护技术综述[J]. 大数据,2(1):1-18.
韩家炜,米舍莱恩·坎伯,等. 2012. 数据挖掘:概念与技术[M]. 范明,孟小峰,译. 北京:机械工业出版社.
刘兵. 2018. 情绪分析挖掘观点、情感和情绪[M]. 刘康,赵军,译. 北京:机械工业出版社.
李昌祖,杨延圣. 2014. 教育舆情的概念解析[J]. 浙江工业大学学报(社会科学版),13(3):241-246.
李光耀,宋文广,谢艳晴. 2018. 智慧校园学生画像方法研究[J]. 现代电子技术,41(12):161-163.
黎加厚,趙怡,王珏. 2007. 网络时代教育传播学研究的新方法:社会网络分析——以苏州教育博客学习发展共同体为例[J]. 电化教育研究(8):13-17.
刘勘,周晓峥,周洞汝. 2002. 数据可视化的研究与发展[J]. 计算机工程(8):1-2.
李鹏宇. 2014. 微博社交网络中的学生用户抑郁症识别方法研究[D]. 哈尔滨:哈尔滨工业大学高等教育研究所.
林育曼. 2018. 国内社交媒体教育应用的研究趋势分析[J]. 传媒(21):79-83.
刘志斌. 2016. 短文本情感倾向分析研究及应用[D]. 哈尔滨:哈尔滨工程大学计算机科学与技术学院.
秦昌博. 2017. 中文MOOC论坛课程中情绪分析及知识难点的挖掘研究[D]. 北京:北京邮电大学信息与通信工程学院.
阮彤,王昊奋,陈为,等. 2016. 大数据技术前言[M]. 北京:中国工信出版集团.
孙波,陈玖冰,刘永娜. 2015. 大数据背景下的学生情感词典构建方法[J]. 北京师范大学学报(自然科学版),51(4):358-361.
舒刚. 2016. 我国教育舆情研究的热点议题及趋势展望——基于CNKI(2009-2015)的数据分析[J]. 国家教育行政学院学报(10):40-46.
舒莹,姜强,赵蔚. 2019. 在线学习危机精准预警及干预:模型与实证研究[J]. 中国远程教育(8):27-34.
桑基韬,路冬媛,徐常胜. 2014. 基于共同用户的跨网络分析:社交媒体大数据中的多源问题[J]. 科学通报,59(36):3554-3560.
孙婉婷. 2016. 面向学生社交平台的情感倾向分析技术的研究[D]. 大连:大连理工大学软件学院.
唐厚强. 2017. 基于高校论坛数据的成绩预测和学生心理状况分析[D]. 成都:电子科技大学计算机科学与工程学院.
申德荣,于戈,王习特,等. 2013. 支持大数据管理的NoSQL系统研究综述[J]. 软件学报,24(8):1786-1803.
特里·安德森,王志军,张永胜,等. 2017. 教育技术三大支柱:学习管理系统、社交媒体和个人学习环境[J]. 中国远程教育(11):5-15,79.
特里·安德森,肖俊洪. 2020. 社交媒体在高等教育中的应用:挑战与机会[J]. 中国远程教育(2):21-31.
谭天,张子俊. 2017. 我国社交媒体的现状、发展与趋势[J]. 编辑之友(1):20-25.
王嘉伦. 2015. 面向大型开放在线课程的主题挖掘技术研究[D]. 武汉:华中科技大学计算机科学与技术学院.
肖君,乔惠,李雪娇. 2019. 基于xAPI的在线学习者画像的构建与实证研究[J]. 中国电化教育(1):123-129.
徐琳宏,林鸿飞,潘宇,等. 2008. 情感词汇本体的构造[J]. 情报学报,27(2):180-185.
殷红,孙凯,王长波. 2018. 基于多源数据的教育网络舆情分析[J]. 东华大学学报(自然科学版),44(4):586-589.
约翰·斯科特. 2007. 社会网络分析法[M]. 刘军,译. 重庆:重庆大学出版社.
于卫红. 2017. 基于多Agent的高校网络舆情监测与分析系统[J]. 现代情报,37(10):53-57.
赵红霞,程敏. 2016. “留守儿童”微博圈的实证研究——基于社会网络分析视角[J]. 上海教育科研(3):18-21.
张金伟,刘晓平. 2013. 基于心理预警模型的微博情感识别研究[J]. 合肥工业大学学报(自然科学版),36(11):1318-1322.
周文静. 2018. 面向校园论坛用户兴趣的用户画像构建方法研究[D]. 北京:北京邮电大学网络技术研究院.
周艺华,李广辉,杨宇光,等. 2019. 基于GeoHash的近邻查询位置隐私保护方法[J]. 计算机科学,46(8):212-216.
Anaya, A. R., & Boticario, J. G. (2009). A Data Mining Approach to Reveal Representative Collaboration Indicators in Open Collaboration Frameworks. International Working Group on Educational Data Mining, (1): 210-219.
Fu, S. W., Zhao, J., Cui, W. W., & Qu, H. M. (2017). Visual Analysis of MOOC Forums with iForum. IEEE Transactions on Visualization and Computer Graphics, 23(1): 201-210.
Goh, C. H. (1997). Representing and reasoning about semantic conflicts in heterogeneous information systems. Cambridge USA: Massachusetts Institute of Technology.
García-Saiz, Palazuelos, C., & Zorrilla, M. (2014). Data Mining and Social Network Analysis in the Educational Field: An Application for Non-Expert Users. Berlin Germany: Springer International Publishing.
Lawrence, R. (2001). Automatic Conflict Resolution to Integrate Schema. Canada: University of Manitoba.
Lin, F., Wang, L., Liu, S. L., & Liu, G. C. (2017). Classification of Discussion Threads in MOOC Forums Based on Deep Learning. In Proceedings of 2017 2nd International Conference on Wireless Communication and Network Engineering: DEStech Transactions on Computer Science and Engineering (pp. 506-511). USA: DEStech Publications.
Min, S. D., & Zhu, B. J. (2014). Collection and Analysis of Emotional Data in Bulletin Board System Forum of University. Applied Mechanics and Materials, 513-517:2099-2102.
Mokbel, M. F., Chow, C. Y., & Aref, W. G. (2015). The New Casper: A Privacy-Aware Location-Based Database Server. In IEEE International Conference on Data Engineering (pp. 1499-1500). Istanbul: Institute of Electrical and Electronics Engineers.
Permana, F. C., Rosmansyah, Y., & Abdullah, A. S. (2017). Naive Bayes as opinion classifier to evaluate students satisfaction based on student sentiment in Twitter Social Media. Journal of Physics Conference Series, 893(1): 012-051.
Rai, L., & Deng, C. R. (2016). Influencing factors of success and failure in MOOC and general analysis of learner behavior. International Journal of Information and Education Technology, 6(4): 262-268.
Wei, X. C., Lin, H. F., Yang, L., & Yu, H. Y. (2017). A convolution-LSTM-based deep neural network for cross-domain MOOC forum post classification. Information, 8(3): 92.
Wen, M. M., Yang, D. Y., & Rose, C. P. (2014). Sentiment Analysis in MOOC Discussion Forums: What does it tell us. In John, C. S., Zachary, A. P., Manolis, M., & Bruce, M. M. (Eds.), Proceedings of the 7th International Conference on Educational Data Mining (pp. 130-137). UK: International Educational Data Mining Society.
Wang, L., Hu, G. L., & Zhou, T. H. (2018). Semantic analysis of learners emotional tendencies on online MOOC education. Sustainability, 10(6): 1-19.
Yang, D., Piergallini, M., Howley, I., & Rosé, C. P. (2014). Forum thread recommendation for massive open online courses. In John, C. S., Zachary, A. P., Manolis, M., & Bruce, M. M. (Eds.), Proceedings of the 7th International Conference on Educational Data Mining (pp. 257-260). UK: International Educational Data Mining Society.
Yu, X., Yu, H., Tian, X. Y., Yu, G., Li, X. M., Zhang, X., et al. (2017). Recognition of college students from Weibo with deep neural networks. International Journal of Machine Learning and Cybernetics, 8(5): 1447-1455.
收稿日期:2020-02-05
定稿日期:2020-09-21
作者簡介:李彤彤,博士,副教授,硕士生导师;李坦,硕士研究生;郭栩宁,硕士研究生。天津师范大学教育学部教育技术系(300387)。
