关联数据在农村治理档案中的轻量级应用探析
2021-08-04沈红雨绍兴文理学院
沈红雨/绍兴文理学院
农村治理是基层社会治理的重要内容,农村档案管理是事关农村经济建设和平安建设的重要基础工作。然而至今农村档案管理仍然存在许多突出问题,如档案收集不完整、保管不集中、档案工作发展不平衡等,特别是在村组织换届选举、行政村规模调整期间经常出现档案管理脱节、随意处置、档案散失等现象,给农村工作尤其是社会治理工作带来很多隐患。
造成以上问题有村委的实际困难,如村务繁杂、村委人手有限,没有精力去学习档案整理知识;由于归档文件得不到有效管理,工作人员使用归档材料非常不方便,进一步使得归档没有积极性,文件不如自存自用自管,时日一久自然散失了。
解决以上问题,除了需要管理层面上对症下药,在技术层面上设计一个好用好查的农村档案管理系统也是关键。
1 系统设计思想
关联数据技术可以用基于深度学习的模型,对全文进行实体识别、句法分析,将语言特征转化为分布式表示,进行实体与关系抽取,构建语义关联,从而达成信息按主题呈现的功能。农村档案中,运用关联数据技术可以将档案与归档条款作关联,实现档案自动分类;可以将档案信息以村民为核心,以村民生产、生活情况为主题聚类呈现,由此大大提升档案信息的组织能力。
在语义识别中,语义规则和实体变化越丰富,训练语料库所需的数据量就越大,对深度学习算法的要求就越高;反之语义规则和实体越明确,识别成本就越低。因此通过构建语义规则模板,通过模板和字符串匹配来完成识别,人工明确的实体字典和关系规则越多,识别就越容易。村民、地理位置和事由是农村档案关联性呈现的核心点,本文提出了通过将语义模糊的实体明确成相应的数据字典,实现简单的结构化数据关联,到建立本体模型实现语义关联的技术进阶路径。此种轻量化关联技术大大提升了档案信息的聚类能力,系统以面向深度语义识别为开发基础,有良好的升级空间。以此供当下具有不同经济条件和技术条件的乡镇作参考。
1.1 聚类事由,各线归档“傻瓜化”
不少农村尚未实现文档一体化在线管理,纸质档案仍需手动整理录入,农村档案管理系统首要考虑归档操作简易性。
事由是各工作线最熟悉的文件联系性。事由可以指一件具体的事,或一个具体的问题,或一段较紧密的工作过程等[1]。根据事由原则,档案是有关一个“事由”的档案文件的集合。文件以事由为单位进行归档最易被掌握,也符合档案整理的规范。
系统允许用户根据国家档案局《村级文件材料归档范围和档案保管期限表》设置本村立卷目录字典,农村工作由党建、行政、妇女、基建、会计等各条工作线组成,立卷目录按工作线分块,目录内容包括立卷条款类别、条款名称、其相对应的保管期限和档案分类号。归档条款依据作者、主题和文种确定。系统允许设置诸如“纠纷”“山地承包”等事由标签(类似于主题词),在立卷目录字典中将事由标签结合作者和文种置入对应的归档条款。各工作线工作人员将文件按事由整理好后结合国家著录格式逐一录入系统,点击对应的事由标签,完成录入。农村一年的事务由常规事由和新增事由组成,事由标签存入事由字典后可以被反复调取。文件作者和文种由系统根据著录的结构化内容提取判断。

图1 农村档案本体模型(实线:子类;虚线:对象属性)

图2 农村档案项目类及其主要属性
系统根据立卷目录字典和事由的对应关系,对事由下的文件自动分配档案号和保管期限完成预归档。立卷目录字典的设置可以由档案局指导,常规事由基本不变,新增事由作增加,对指导员来说工作量不大。
村兼职档案员在每年归档期检查系统分配的文件分类和顺序,不妥之处进行手工调整,确定归档后锁定档号由系统产生归档目录,各线负责人根据归档目录排放纸质文件,填写相应的归档章信息。系统根据立卷目录对于应归未归文件作出未归档提醒,未归清单可作为干部离任档案工作审计依据。
总之,系统将归档工作人员分成专业和不专业两种,最大量的文件录入整理工作并不需要档案整理知识。档案整理专业规范由专业人员来设置,系统通过将事由和立卷规则相关联,将“不专业”的文件整理结果根据“专业”的设置规则进行智能化整理。
1.2 聚类人事,档案呈现主题化
档案信息好查是激发村民积极移交手中的档案,最终将其汇成“智库”的根本要素。
在以人为本的农村治理中,以村民为主题呈现档案信息是全面精准掌握村民情况的必然要求,为村民提供档案信息和证明也是服务为民的重要内容。国家规定村民档案按“一户一档一袋”的要求进行整理,然而更有大量涉及人的档案分散于各工作线上。通过户籍系统导入建立由姓名、曾用名、身份证号、家庭关系、家庭住址等户籍信息组成的村民字典,此外补充特长、务工情况、留守儿童标注、贫困户标注等信息。预归档文件信息录入过程中涉及某村民有关的文件,通过打入名字或姓名首字母等方式从关联的村民字典中选取此人或此户的信息。从而做到涉人档案件件对准人和户,以村民字典为关联点在系统中形成逻辑上的“一户一档”,档案实体分散在各线“事由”中并不影响档案信息按人按户的全面呈现。
分散在各线的“事由”是同一事由的不同侧面,如一项经济合作项目可能涉及村委会会议记录、扶贫工作和“三资”工作。振兴乡村从了解乡情开始,乡情即是无数“事由”的组合。以事由字典为关联点将关于同一事由的档案相关联,确保乡情记忆呈现的完备性。
村情村务档案走向开放是农村民主的重要部分,档案的机要性要求开放具有限制性。系统建立事由公开清单,村民字典分群,建立事由与村民群的对应开放关系。系统设置村务开放时间,对开放清单中未归档材料提出警告,以此由民众督促档案及时收归。“涉人档案件件对准人”为村民自主获取个人档案提供了信息安全壁垒保障,村民登录系统或凭身份证到出证服务站可自主获得与其本人有关的档案证明。
1.3 聚类地点,综合呈现地图化
由于农村自然资源禀赋、产业特色不同,贫困人口、留守儿童等人口分布情况也不均衡,在农村治理中需要分门别类进行分析、研究、归纳,从而整合资源因“地”制宜。GIS又称为“地学信息系统”,系统运用GIS实现一张图上综合展示和管理档案,赋予档案以地理位置信息。GIS将农村网络化,网格对应产生地理代码形成地理代码字典,从中选择相应的代码录入到村民字典、“三资”、企业、旅游开发点等与地理信息紧密相关的档案著录项中。档案系统将检索结果的正题名推送到GIS地理信息库,将数字件推送到GIS的catalog目录下,GIS通过地理代码与有关档案作关联,呈现整个村或者相应网格里分布的人、产业题名等信息。点击相应的题名,浏览相关档案内容。
2 本体模型设计
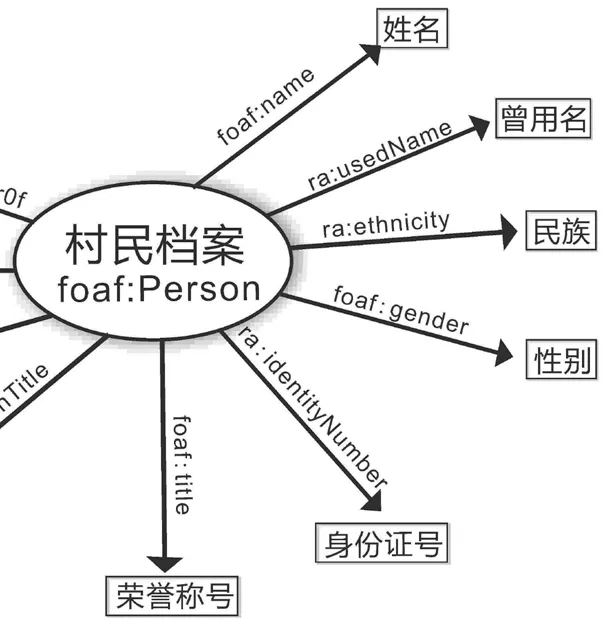
图3 村民字典类及主要属性

图4 LodView发布后的档案“土地登记申请”详细页面

图5 通过“ead:personName”属性链接跳转到“村民字典:李三”页面
运用关系数据库技术,以数据字典为关联点,可以实现档案跨分类按主题呈现,但是呈现关系没有语义化,不易被理解。语义化关联组织首先需要明确本体概念。在信息科学与计算机领域,本体可以看作是一种模型,是对客观存在对象或概念及其属性和相关关系形式的表达[2]。
结合农村档案自身特点以及系统的业务需要,分析农村组织的基本结构、家庭结构、事务流程和文件关系,该本体模型以档案标准文件《中国档案分类法》和《中国档案主题词表》为依据,复用了档案编码著录EAD[3]、文献描述参考CIDOC CRM1[4]、“朋友的朋友”FOAF[5]等本体模型。参考都柏林核心(Dublin Core,DC)元数据标准和DBpedia等知识库,以上文数据字典为基础,自定义事由、地点和村民三个核心类,扩展定义部分农村档案属性。每个核心类定义相应的数据属性,实体之间的关系通过对象属性进行描述与揭示。建立规范的档案本体有利于本体拓展和与外部资源建立共享连接。模型见图1,模型定义中的农村档案项目类及其主要属性见图2,村民字典类及主要属性见图3。
3 关联数据集的构建与发布
3.1 实体识别和语义对齐
作为语义网的轻量级解决方案,借助由事由、村民和地点组成的数据字典对文件内容作概括,除了事由字典有些许语义分歧,其余两个字典数据精确、实体明确。
事由的描述各人主观概括不完全一致,如“1号地确权”“1#地确权”“一号地确权”这三个词指向同一事由,如“二工”一指水利工程的劳动积累工和义务工,一指志愿服务的社工和义工。事由字典可以通过人工在字典中将同义词标签标注为同一事由,将一词多意标签标明为不同事由。在前期小规模数据量的农村档案中,事由标签数据量有限,即使通过人工标注也是可行的。
面向深度语义识别可以在机器学习中通过建立事件本体模型,通过CRF、ME、SVM、触发词、模式匹配和聚类算法的对OCR内容进行事件信息抽取,按模型设定抽取出事件类型、时间、地点、人物等信息进行结构化存储。还可以扩展到将全部档案内容OCR成文字,通过Bi-RNN、Bi-LSTM、Bi-LSTM-CRF、BERT等深度学习模型进行自动识别,基于概率的全局算法PARIS自动实现实体消歧或共指消解。全面的语义识别需要大量的语料训练,可以用来满足更加复杂的本体模型。在农村档案数字化到一定的规模,在整个行业档案形成云气候的阶段,面向深度语义识别是必须的。
3.2 RDB2RDF转换及存储
RDF是关联数据采用的数据模型,一般用“实体、属性、值”三元组来描述领域资源。可以通过农村档案本体以及其他外部本体词表,对领域资源中的各类实体对象进行规范化描述。将关系数据库数据转换成RDF三元组的技术中,有直接映射和领域语义驱动映射两种模式。直接映射简单方便、映射速度快,但不能捕捉数据的真正语义。小规模农村档案管理系统应用直接映射技术效率更高。领域语义驱动映射方法在转换过程中较为完整地保留了RDB数据蕴含的语义,可以实现较为复杂的映射,但依赖于专门的领域本体和映射语言,转化过程较为繁琐,耗费时间较长[6]。
这两种映射模式可以互相补充,在前期系统数据简单、语义明确的情况下以前者机器自动转换的初始规则生成RDF图,后期数据和语义变复杂的情况下在默认的RDF图的基础上进行个性化定义和配置[7]。
RDF三元组的存储方式目前有关系型数据库、RDF三元组数据库和图数据库三种。目前绝大部分的农村档案管理系统采用关系型数据库,对于开发条件有限的乡镇,可以通过在原有关系型数据库中建立语义主谓宾三元对应表,在各表明确关联字段,达到简单的语义关联效果。但是此法不适合多对多和多深度关系、多语义应用,对大体量的数据管理所需软硬件成本很大。图数据库结点的存储能力不适合存储档案信息,但是擅长存储和检索复杂的结点关系,直观高效表现档案实体和实体之间的复杂多重关系,适用于土地流转、家庭成员活动轨迹等特定应用。RDF三元组数据库擅长语义推理,具有支持Web扩展和高性能数据管理性能,是专门为存储大规模RDF数据而开发的知识图谱数据库,语义解析能力强,适合于存储数据量大、面向外部资源链接的档案系统。

图6 LodLive发布后的以档案“土地登记申请”为核心的关系图形
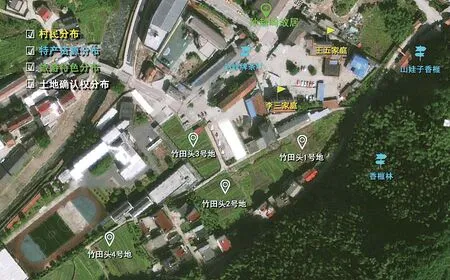
图7 以地理代码为关联点GIS综合呈现档案效果图
3.3 关联数据发布
考虑到农村档案的数据面向未来具有可扩展性,本文以OpenLink Virtuoso这一典型的RDF三元组数据库管理软件为例。采用LodView工具将服务器上的RDF数据转换为HTML网页进行展示,如档案“土地登记申请”经过LodView发布后的详细页面(图4),通过“ead:personName”属性链接跳转到村民字典的“李三”页面(图5)、来源档案“土地登记申请”的详细页面。通过“ra:hasAffair”属性链接跳转到事由字典的“土地确认权”的详细页面。
以事由和相关的时间、地点和人物为核心综合呈现档案,相关档案相互间复杂的关系最适合使用图形化的方式表示。农村档案关联关系的可视化通过LodLive系统实现,以数据字典数据或档案的著录数据为结点,以关系为连接线,直观提供档案浏览图。LodLive可自动查询与该结点(实体)相关的三元组信息,并可与DBpedia、GeoNames等外部数据集进行关联查询(如图6)。图7所示以地理代码为关联点通过GIS综合呈现档案的可视化效果。
4 结语和展望
在大数据时代的农村档案管理中,农村档案管理部门将慢慢变成信息存储和服务中心,伴随着农村经济的迅速变迁,农村治理模式将越来越走向自治模式多样化和村治开放化,服务个性化思维、网络化思维、信息化思维、资源共享性思维四大思维将成为农村档案管理的一个趋势。关联数据技术尤其是结合了语义网技术后,将在未来的农村治理语境下的档案管理中发挥巨大作用。高质量的档案知识开放数据集与知识服务平台的构建,一方面为更深层次的档案知识分析与研究提供了科学的数据集,促使档案知识发挥出更大的价值[8],另一方面精准的语义抽取技术将为档案数据共享关联赋予保密性保障。
