基于朴素贝叶斯的机器学习实验教学设计
2021-07-01王敏罗婧雯刘军刘沛泽
王敏 罗婧雯 刘军 刘沛泽


【摘要】 贝叶斯学习是机器学习理论中的重要研究方向。本文主要实现基于朴素贝叶斯的机器学习实验教学设计,贝叶斯学习以贝叶斯法则为基础,通过已了解的数据分布的先验知识,结合样本训练数据来估算出整体数据的数学模型。贝叶斯学习的结果是获得一组变量的联合概率分布。贝叶斯学习由于其用概率的形式来表示不确定知识,故对不确定形式的问题它有独特的描述和计算优势。而朴素贝叶斯是在属性独立性假设的条件下进行计算,可以大大减小计算的复杂程度。实验设计目的是根据朴素贝叶斯公式实现对文档的分类,给学生提供一种实验教学案例。
【关键词】 朴素贝叶斯 实验教学设计 文本分类
一、实验研究背景与目的
本实验设计主要基于朴素贝叶斯理论,目前是为学生提供基于贝叶斯理论的实验项目,让学生更好地理解该理论解决实际问题。 随着互联网的飞速发展, 海量数据注入到通讯设备中。如此大量的信息就让信息检索和数据挖掘的重要性更加突出。文本分类作为数据挖掘的一部分也逐渐被人们重视起来。其中文本分类的主要内容是在预先给定的类标签的集下, 根据文章内容, 确定它的类别。我们接下来将要通过三个方面来介绍:文本表示, 分类器构造和分类器评估。
二、实验设计思路
本实验的思路是把一部分含有女性、体育、文学出版、校园的话题用网络爬虫爬下来存在特定的文档中,然后通过朴素贝叶斯分类算法实现贝叶斯分类。
三、方案设计
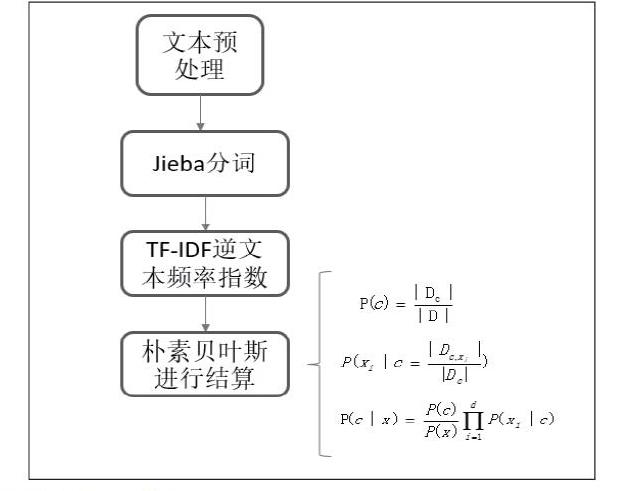
系统设计流程框图如下。
四、具体算法描述
除去噪声,如格式转换,去掉符号,整体规范化;遍历的读取一个文件下的每个文本。操作如下。
def readFile(path):
with open(path, 'r', errors='ignore') as file:
content = file.read()
return content
def saveFile(path, result):
with open(path, 'w', errors='ignore') as file:
file.write(result)
4.1 jieba分词
1)首先利用import调用jieba模块、TF-IDF分词模块、朴素贝叶斯算法模块;
import jieba
2)jieba分词算法的基本原理是:1.基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG); 2.采用动态规划查找最大概率路径,找出基于词频的最大切分组合; 3.对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法;
代码如下:
def segText(inputPath, resultPath):
fatherLists = os.listdir(inputPath)
for eachDir in fatherLists:
eachPath = inputPath + eachDir + "/" each_resultPath = resultPath + eachDir + "/"
if not os.path.exists(each_resultPath):
os.makedirs(each_resultPath)
childLists = os.listdir(eachPath)
for eachFile in childLists:
eachPathFile = eachPath + eachFile
# print(eachFile)
content = readFile(eachPathFile)
# content = str(content)
result = (str(content)).replace("\r\n", "").strip()
# result = content.replace("\r\n","").strip()
cutResult = jieba.cut(result)
saveFile(each_resultPath + eachFile, " ".join(cutResult))
4.2 TF-IDF逆文本頻率指数
1)首先调用TF-IDF向量转换类和向量生成类。
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import TfidfVectorizer
2)TF-IDF逆文本频率指数是一种用于信息检索与数据挖掘的常用加权技术。是一种统计方法,用以评估一个词对于一个语料库中一份文件的重要程度。词的重要性随着在文件中出现的次数正比增加,同时随着它在语料库其他文件中出现的频率反比下降。
3)TF-IDF词频算法实现。一个词在某一文档中出现次数比较多,其他文档没有出现,说明该词对该文档分类很重要。然而如果其他文档也出现比较多,说明该词的区分性不大,就用IDF来降低该词的权重。
TF-IDF=TF×IDF
其中,词频:TF=词在文档中出现的次数/文档中总词数;
逆文本频率:IDF=log(语料库中文档总数/包含该词的文档数+1)。
def getTFIDFMat(inputPath, stopWordList, outputPath):
bunch = readBunch(inputPath)
tfidfspace = Bunch(target_name=bunch.target_name,label=bunch.label, filenames=bunch.filenames, tdm=[],
vocabulary={})
vectorizer = TfidfVectorizer(stop_words=stopWordList, sublinear_tf=True, max_df=0.5)
transformer = TfidfTransformer()
tfidfspace.tdm = vectorizer.fit_transform(bunch.contents)
tfidfspace.vocabulary = vectorizer.vocabulary_
writeBunch(outputPath, tfidfspace)
4.3朴素贝叶斯分类法
1)首先调用贝叶斯分类法算法模块,这个模块是调用已有的别人写好的算法,下面会详细介绍原理过程。
from sklearn.naive_bayes import MultinomialNB
2)朴素贝叶斯原理
朴素贝叶斯分类器采用了“属性条件独立性假设” 对已知类别假设所有属性相互独立。换言之,假设每个属性独立地对分类结果发生影响。故贝叶斯公式可以重写为
因为给定样本P(x)为已知的,故贝叶斯准则就可以转化为
显然,朴素贝叶斯分类器的训练过程就是基于训练集 D 来估计类先验概率P(c),并为每个属性估计条件概率。
令Dc表示訓练集D中第c类样本组成的集合,若有充足的独立同分布样本则可容易地估计出类先验概率。
对离散属性而言,令表示Dc中在第i个属性上取值为的样本组成的集合,则条件概率可估计为
程序如下:
def bayesAlgorithm(trainPath, testPath):
trainSet = readBunch(trainPath)
testSet = readBunch(testPath)
clf = MultinomialNB(alpha=0.001).fit(trainSet.tdm, trainSet.label)
#alpha:0.001 alpha 越小,迭代次数越多,精度越高
#print(shape(trainSet.tdm)) #输出单词矩阵的类型
#print(shape(testSet.tdm))
predicted = clf.predict(testSet.tdm)
total = len(predicted)
rate = 0
for flabel, fileName, expct_cate in zip(testSet.label, testSet.filenames, predicted):
if flabel != expct_cate:
rate += 1
print(fileName, ":实际类别:", flabel, "-->预测类别:", expct_cate)
print("erroe rate:", float(rate) * 100 / float(total), "%")
五、系统测试情况
下图中data文件夹中是原始数据,result文件夹是jieba分词结果,stop是文本预处理筛掉的的停用词。test是测试数据,test_segResult是测试结果。
其中测试数据集:女性话题有38个,体育话题115个,文学出版话题31个,校园话题16个,以下是测试出错的结果。其中校园话题出错的概率最大。
六、小结
此程序简单易懂,是在贝叶斯的基础上进一步了解了朴素贝叶斯公式的原理及其运用,介绍了jieba分词和TF-IDF逆文本频率指数及其应用,在实际案例中错误率仅为0.570,准确率较高,可以在实验课程教学中使用。
参 考 文 献
[1]苏金树, 张博锋, 徐昕.基于机器学习的文本分类技术研究进展[J].软件学报, 2006, 17 (09) :1848-1859.
[2]李学明, 李海瑞, 薛亮, 何光军.基于信息增益与信息熵的TFIDF算法[J].计算机工程, 2012, 38 (08) :37-40.
[3]Tom M.Mitchell著;曾华军等译,机器学习[M]. 机械工业出版社,2003.
[4]陈叶旺,余金山. 一种改进的朴素贝叶斯文本分类方法[J]. 华侨大学学报(自然科学版). 2011(04).
