基于GCC编译器向量化的数据结构布局优化研究
2021-05-28朱广林赖庆宽何先波王博生陈燕生
朱广林,赖庆宽,何先波,王博生,陈燕生
(西华师范大学计算机学院,四川南充 637009)
0 引言
为了充分利用处理器的并行潜力,现代CPU大多已提供向量处理单元(Vector Processing Units,VPUs)以允许在单条指令中对多个数据执行操作.GCC、LLVM、ICC和AOCC等主流编译器中也提供了编译器的自动向量化(Compiler Automatic Vectorization,CAV)支持,它们能够分析应用程序中的循环,自动找到使用SIMD指令的机会[1].通过一个向量指令操作完成对多个数据元素的同时运算[2,3],可以在与标量运算相同的时间内执行更多的操作,是提高程序性能的重要途径之一.利用SIMD指令最常用的方法是编译器的自动向量化,当编译器不能对代码进行向量化时,可嵌入向量化的汇编代码,或调用一些高级的库文件,如Boost.SIMD[4]等.
编译器能否准确高效地进行自动向量化对程序整体的性能至关重要.编译器根据编译时得到的有效信息对程序进行向量化评估,以决定采用何种指令集[5].商业编译器AOCC和ICC在O3及相关优化组合下可以有效地挖掘和使用SIMD指令,做规整的向量化,但GCC编译器的自动向量化优化存在一些保守限制,因此编译器的自动向量化技术仍有重要的研究价值.
本文主要对现代x86多核处理器中, GCC编译器的数据结构布局进行优化,将代码热区域中进行数据结构对齐,亦或是重组,拆分之后的结构体进行数组结构体数组(AoSoA)的布局转换优化,通过改善内存布局方式,提高向量化优化能力.通过分析优化前后代码中向量指令的数量和功能,最后在AMD平台上进行了基准测试,验证了该方法的有效性,以及具有向量化指令宽度扩展能力.
1 研究背景
编译器的优化能力受到诸多因素影响,为使应用程序的向量运算性能最大化的发挥出来,本文基于国产x86处理器平台上的GCC编译器进行性能分析,通过变换数据结构的布局方式,以有效利用全宽度的向量寄存器.
根据优化粒度的不同,自动向量化分为循环向量化(Loop vectorization)和超字级并行向量化(Superword-Level Parallelism vectorization,SLP).循环向量化在基于循环和依赖关系的理论上使用SIMD指令[6],它利用粗粒度的并行性,通过展开循环以减少迭代次数,同时在每个迭代中执行更多操作.超字级并行向量化可利用SIMD基本块中语句之间的并行性[7,8],也可用于优化多重的嵌套循环[9].超字级并行向量化以更精细的粒度使用,可以在循环向量化存在限制的情况下加以利用,它将多个标量操作打包在一起来使用SIMD指令[10].
循环向量化先对循环的最内层进行分析,以检查是否存在数据依赖和函数调用等限制因素,当确定可进行向量化优化之后,变换循环体结构并生成向量化指令代码.如图1所示为循环向量化示例,图1(a)的示例程序中,向量化受限于循环体中存在的循环依赖关系和函数调用,GCC编译器需要在-O3及-ffast-math等优化组合的情况下才能进行循环向量化.如图1(b)所示,为了最大限度地进行向量化,编译器需要执行循环分裂(loop fission)转换,将循环的一部分塑造成可向量化的形式,第一个循环经过分裂和展开之后可进行向量化,如图1(c)所示.
GCC编译器中,向量化主要作用于中端GIMPLE trees表示的循环优化上,且大部分向量化优化选项已在-O3优化中默认开启.如图2所示,当源码经过前端解析进入中端时,生成GIMPLE表示,它是一种与前端语言和目标机器都无关的三地址表示形式,引入了临时变量来保存中间值,GCC中众多的优化在GIMPLE中间表示上进行[11].
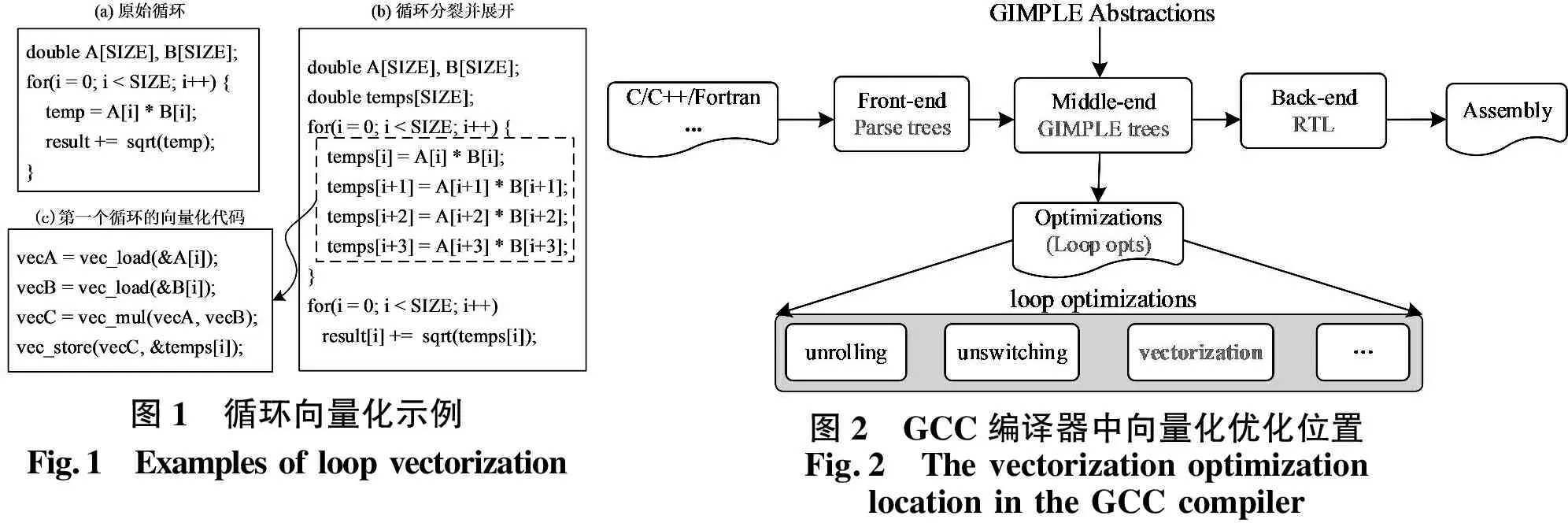
图1 循环向量化示例Fig.1 Examples of loop vectorization图2 GCC编译器中向量化优化位置Fig.2 The vectorization optimization location in the GCC compiler
2 数据结构布局优化设计与实现
本章节结构如下:首先简要介绍向量化优化中指令数据类型及其相关的寄存器内存布局;最后详细说明数据结构布局的向量化优化方法的设计与实现.
2.1 指令集数据类型及其内存布局介绍
不同的SIMD扩展指令集都有其对应的指令集体系结构(Instruction Set Architecture, ISA和向量寄存器宽度[12].如图3展示了英特尔SSE和AVX指令集中的数据类型以及相关向量寄存器的布局结构,图3(a)中的数据类型,在SSE指令集中,128位寄存器可以表示为四个32位的元素或者两个64位的元素,并且SSE中定义了标量和打包两种类型的操作,标量运算对最低位有效数据元素进行运算,打包运算可并行计算所有位元素.在x86处理器上目前支持的最大向量寄存器宽度为512位,在支持多个向量寄存器的机器上,位数较小的寄存器作为较大寄存器的低位,不同大小的寄存器组分别为:ZMM、YMM和XMM[13].如图3(b)所示,512位的ZMM寄存器低256位是YMM寄存器,而YMM寄存器的低128位与128位XMM寄存器复用.
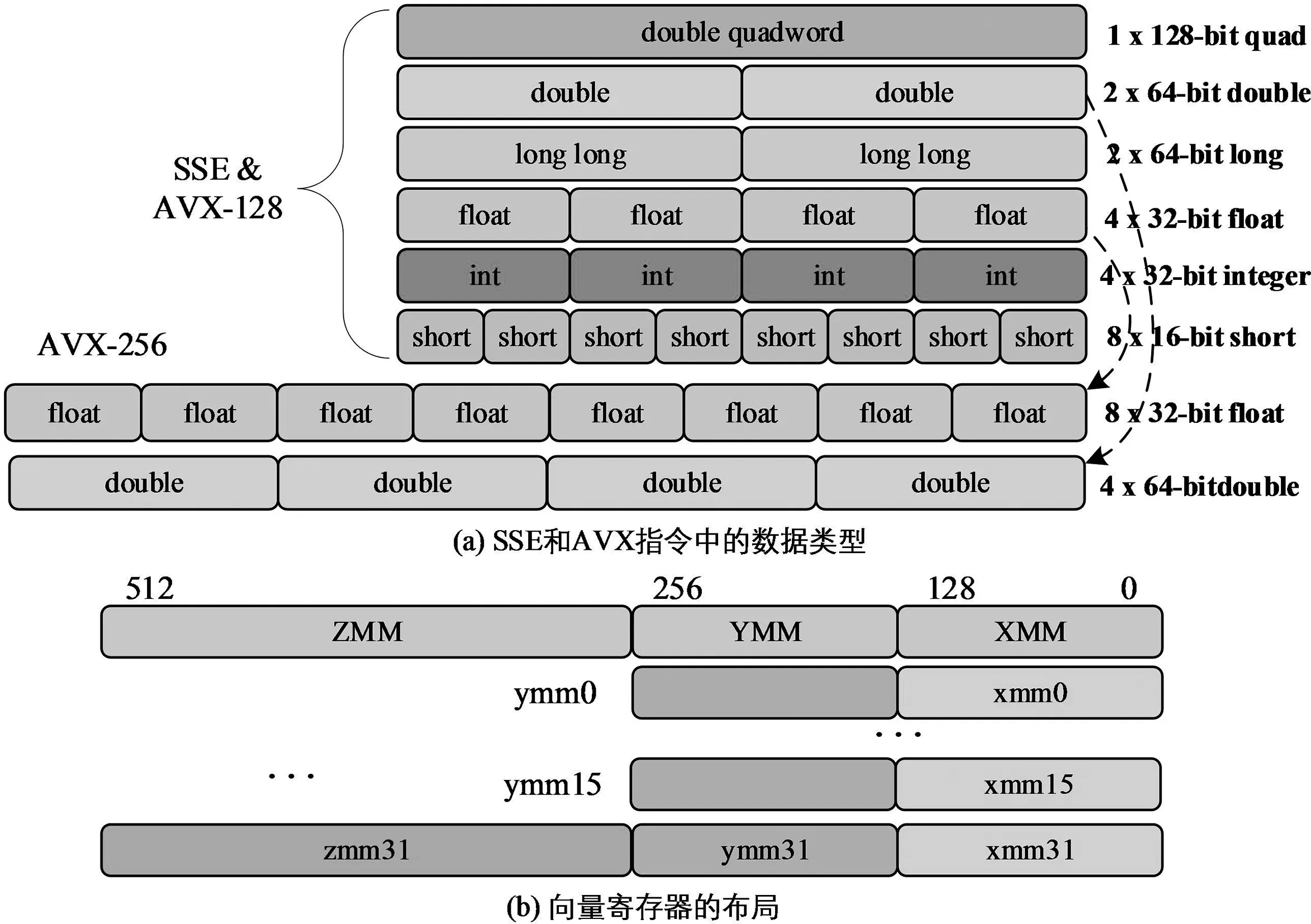
图3 SSE和AVX指令中的数据类型和相关寄存器布局Fig.3 The data types in SSE and AVX instructions and related register layout
C/C++中的基本类型__m512、__m256d、__m128等可与编译器的内部函数一起使用,以促进向量寄存器的每一位元素都能有效利用,减少指令数量.
2.2数据结构布局方法设计
数据布局是向量化中最重要的因素之一,数据根据组织方式的不同可以分为:结构体数组(Array of Structures,AoS)、数组结构体(Structure of Arrays,SoA)或数组结构体数组(Array of Structures of Arrays,AoSoA).本文的设计方法是通过将数据结构对齐,亦或是重组(reorder),拆分(split,peeling)之后的结构体进行内存布局转换,变换为AoSoA组织方式.
数据结构对齐包含数据对齐、数据填充和打包.结构体数据对齐能提高访存效率,根据对齐规则会对结构中未使用的空间进行填充,如图4所示,图4(a)中的示例代码,根据结构体总大小为所有成员中最大对齐数的整数倍的规则,进行对齐和填充之后如图4(b)所示,填充后的内存布局如图4(c)所示,而通过将结构体中数据打包,可以减少应用程序所需的内存空间,如图4(d)所示,对结构体进行打包之后编译器便不会进行填充,但某些编译器可能不允许未对齐的内存访问.
AoS、SoA和AoSoA优化示例如图5所示,使用AoS数据结构时,在访问下一组数据之前需要先获取结构体的所有元素,但可能许多元素都未被使用,使用SoA结构时,结构体的每个元素分为一个数组,具有更好的布局方式.图5(d)所示为三种结构的内存使用布局方式.AoSoA是AoS和SoA两种布局的一种组合方法,它通过vpshufb等指令将按AoS组合的数据进行混洗到适当向量寄存器中,以有效利用寄存器宽度,不仅保持了良好的数据布局和代码的直观性,同时对现代处理器的缓存体系也更加友好,使用AoSoA可对大多数运算进行高效地向量化.

图4 结构体的数据结构对齐及其内存布局示意图Fig.4 Schematic diagram of structure data structure alignment and memory layout图5 AoS、SoA和AoSoA优化示例和内存布局Fig.5 AoS, SoA and AoSoA optimized examples and memory layout
在GCC编译过程中通过插桩(profiling)的反馈数据收集到热区域中的结构体信息,然后在GCC中端GIMPLE IR(Intermediate Representation)上新建优化pass,对热区域中的结构体进行数组结构体数组的布局转换优化.对优化前后的汇编码对比分析发现,优化后采用了vbroadcast、vpshufb、vpermilpd等数据混洗,转置操作指令.
3 实验设计与分析
3.1 实验平台与测试用例
为了对本文提出的方法的有效性进行评估,将优化方法应用到GCC8.2.0编译器,其中GCC8.2.0版本发布时间为2018年7月26日.在AMD平台上,对优化前后的编译器进行实验,可以评估本文方法的有效性,以及编译器的向量化能力.
表1列出了实验中所使用平台的基础架构特征以及支持的向量化指令集.表2给出了编译器所使用的主要优化选项组合.

表1 实验平台主要信息Tab.1 Main information of the experimental platform

表2 编译器信息Tab.2 Compiler information
表1中进行实验的AMD平台支持所有Intel SIMD ISA扩展,表2中列出的编译器的peak性能主要优化选项组合,常规优化-O3,链接时优化-flto和数学函数优化等.
本文实验采用的是国际标准测试套件SPEC CPU 2017,其包含43个基准测试用例,涵盖区域海洋模拟、天气预报、图像和视频压缩等众多领域,是一套广泛用于评估编译器性能的测试集[14-16].采用ref数据集,将优化前后的编译器编译测试用例得到的ratio值,分别作为baseratio和optimizedratio,根据公式1计算出优化后的编译器的性能加速比.
(1)
3.2 实验结果与分析
为评估本文方法的有效性以及不同版本编译器的向量化能力,在此对GCC8.2.0编译器进行基准测试,并计算出性能加速比.以ref为输入数据集进行编译器优化前后的测试,根据公式1对实验的ratio值进行计算得到性能加速比.
对SPEC 2017中浮点测试集进行测试,得到实验结果如图6所示,GCC8.2.0编译器在进行数据结构布局优化后625.x264_s、628.pop2_s和638.imagick_s 三个benchmark分别取得1.04x、1.05x和1.07x的性能加速比,验证了该方法的有效性,并且优化后的汇编码中出现预期的数据转换操作相关的向量化指令.实验数据表明该方法具有在进行向量化指令宽度扩展的能力.

图6 AMD平台上优化前后的性能加速比Fig.6 Performance speedup before and after optimization on AMD platform
4 结束语
本文提出的数据结构布局优化方法对热区域中,进行数据结构对齐,亦或是重组,拆分之后的结构体进行数组结构体数组(AoSoA)的布局转换优化,通过改善内存布局方式,提高向量化优化能力.通过在AMD上进行的实验分析,验证了该方法的有效性,以及具有向量化指令宽度扩展能力.
