面向理想性能空间的跨架构编译分析方法
2021-04-01赖庆宽贺春林何先波冯晓兵
赖庆宽 吕 方 贺春林 何先波 冯晓兵,3
1(计算机体系结构国家重点实验室(中国科学院计算技术研究所) 北京 100190) 2(中国科学院计算技术研究所 北京 100190) 3(中国科学院大学 北京 100049) 4(西华师范大学计算机学院 四川南充 637009)
(laiqingkuan@outlook.com)
编译器性能优化是计算机系统结构优势得以充分发挥的基础,是关乎整个系统功能与性能的重要环节.编译器优化的实质是“取众人之长,补己之短”.一款高性能编译器需要汲取其他诸多编译器的长处,它的优化契机和提升空间也往往源于对同期编译器的优势挖掘.但是,面对众多同期编译器设计,选择哪些作为参照物分析才能攫取更多收益是编译器优化分析最为关注的问题.
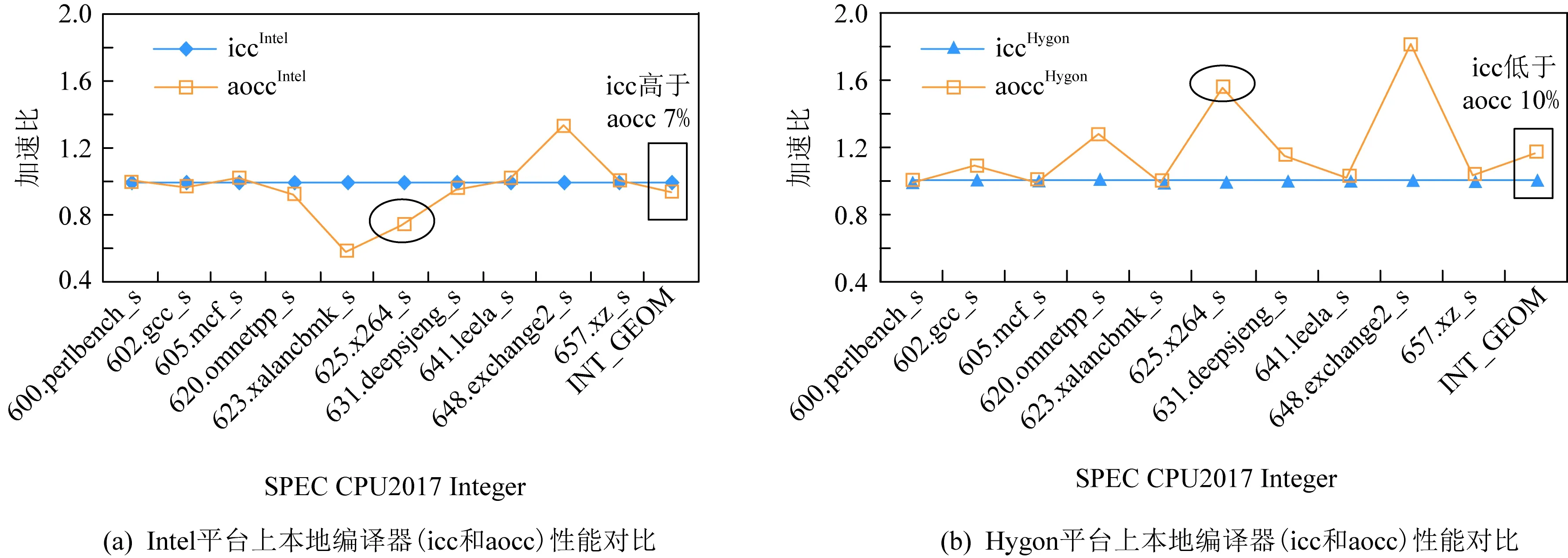
Fig. 1 Interference with compiler performance by different platforms (processors)图1 不同平台(处理器)对编译器性能的干扰作用
编译器性能直接受平台影响,因此,对它们进行性能分析时,不仅需要考虑编译器自身的性能优势,也不能忽视平台所产生的影响.图1展示了同期版本的icc和aocc编译器在Intel平台以及基于海光处理器的验证平台(Hygon)上表现出截然相反的性能表现.以SPEC CPU2017定点测试集为例,图1(a)中的2组曲线分别代表Intel服务器本地安装的2款编译器icc编译器(iccIntel)和aocc编译器(aoccIntel)所产生的SPEC CPU2017定点性能对比数据.标记菱形的曲线所代表的iccIntel在Intel服务器上呈现出明显“主场实力”,在SPEC CPU2017定点几何平均分值(INT_GEOM)上与标记方形的曲线所代表的aoccIntel的差值将近7%;然而在图1(b)中,海光平台上的2款本地编译器的性能与Intel平台上的编译器性能刚好相反,其中aocc编译器的性能相对于icc编译器性能更好,超过icc编译器10%.如图中选定的625.x264_s例子,在Intel平台上icc性能最好,在Hygon平台上aocc性能最好.根据以上的数据分析,不同的平台上相同的编译器优化能力不同,机器平台是影响编译器性能的关键因素.
平台影响从编译器安装伊始就开始了,它决定了平台之上的编译器具有启发式的优化能力.当平台(处理器)不同时,相同的编译器源码在安装过程中会受到不同指引,继而生成具有不同优化能力的本地编译器.例如,对于同一份gcc8.2.0源代码,它在Intel、Hygon和龙芯上所生成的编译器具有不同的优化能力.在编译器安装过程中,机器平台的影响的不可忽略,否则会影响后续的优化方案的确定.因此,跨平台编译器性能分析的基础应该是编译器与机器平台的组合,本文称之为架构组合.
然而,结合平台的编译器分析将产生巨大的数据量.编译器分析又是一个极大依赖于编译专家经验的过程,由于数据过多必定会大大增加人工分析的工作量,所以目前编译器性能分析过程中,会忽略机器平台(处理器特征)的影响,仅仅关注于编译器本身.目前的编译器性能分析方法只选定一款高性能编译器来做分析,以降低分析压力.工业届主流芯片服务器厂商都研发了只适合于自家芯片和服务器的高性能编译器.如icc是Intel公司高性能编译器,aocc是AMD公司的高性能编译器,这些编译器在各自的芯片服务器上拥有着非常显著的性能,所以是编译器性能分析的最佳参照编译器.但是这些编译器并不能一成不变的普适风云万变的领域体系结构.这些编译器脱离自己所定位的芯片结构,是否仍然能够发挥出“主场效应”?显然,当目标编译器所在平台与icc,aocc不同时,这个问题就关系到优势编译器选型是否正确,更关乎目标编译器优化分析的优化方向决策是否正确.对于编译器优化而言,减少分析目标,就会大大削弱了集众长于一身的机会.因此,我们需要一种高效的分析方法,此方法可以快速地选择出性能高的架构组合,精确地预估出最大化的理想性能提升空间.根据这些性能数据指标实行详细的分析,以确定出优势优化选项,并在目标编译器上实现此优化功能.
本文提出了一种与机器平台相关的编译器性能分析技术——基于峰值数据的跨架构组合分析方法(a peak-data based approach for cross-framework compiler analysis, PDCA),此方法可应用于多平台上的多编译器性能分析.首先,以SPEC CPU2017为测试用例,根据业界提供的峰值选项对平台和编译器的架构组合做峰值测试,用最高的性能数据建立理想峰值性能,其与我们的目标编译器性能差距构建出一个理想性能区间(ideal-peak).此性能区间是目标编译器在理想情况下可以达到的性能.其次,选项筛选,直至获得有明显性能优势的优化措施指示,通过人工分析,在目标编译器中实现性能提升,PDCA是使得目标编译器的优化来源于其他多个架构组合,最终性能逼近理想性能.
本文主要贡献有3个方面:
1) 提出一种跨架构分析方法PDCA,该方法是对多平台和多编译器架构组合的编译器优化分析方法.
2) 该方法是针对多个优势峰值架构组合,以理性性能区间为目标的编译器性能分析方法,最高的性能数据和目标编译器性能数据之间的差距构成了理想性能区间,它代表了一个切实可以提升的性能空间.因此,是一种具有实用价值的分析方法.
3) 通过实验验证,PDCA是一种高效使用的编译器性能分析方法,可以以多个架构为参照,为目标编译器挖掘出更多的优化技术方案,使得目标编译器获得巨大的性能提升.
1 研究背景
1.1 问 题
现有编译器性能分析方法通常采用弱化架构组合选型的方式进行,即简化平台与编译器选型,直接锁定某一种优势架构组合.例如安腾处理器平台上的ORC编译器是以同期的商用编译器ecc作为参照编译器而研发的.基于mips架构的龙芯编译器也将同期x86与icc编译器作为自己的参照分析物.在此基础上采用机器模型辅助等自动分析手段对编译器优化进行深度筛选[1],目的是迅速聚集到使性能最大化的优化选项.
如果只对单一的架构组合做性能分析,那么编译器的性能提升控制将受到很大的限制.编译器性能分析通常借助于SPEC CPU2017测试集[2],此测试集包含的领域非常广泛,包括压缩算法、地震模型等,并且对于每个测试用例存在定点和浮点数据集以及条件密集或访存密集等不同特征. 因此,一个架构组合很难使SPEC CPU2017测试集中的所有类型应用百分百受益.
如图2所示,gcc编译器在Intel平台上有极大的性能提升空间.如图2(a)所示,icc有明显的优势,2种编译器之间有84%的性能差,这也是我们参照icc进行优化所能达到的可能最大提升限度.图2(b)中,如果在这个基础上增加aocc,依旧是这5个测试用例具有非常大的性能差距,但它们分别来源于icc和aocc.此时,平均性能若涵盖标记空心方形所示的最好性能数据,它较gcc基准的优势就会提升至107%.由此可见,参照编译器的扩充将带来更大的潜在性能提升空间.如果据此性能区间的指引,目标编译器gcc可获得更多性能提升.
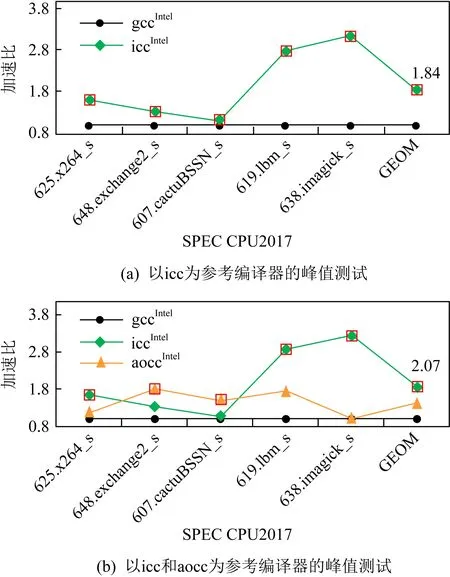
Fig. 2 Performance ratio based on icc and aocc图2 以icc和aocc为参考形成的性能差
然而,弱化架构组合选型的主因之一是无法承受跨架构组合所引发的庞大的人工分析开销.式(1)对跨架构编译器分析的时间成本进行了估算.
overheads=(platforms×compilers×options×
benchmarks×runtime)24.
(1)
结合平台因素的编译器分析需要在平台(platforms)、编译器(compilers)以及性能分析选项(options)、测试集(benchmarks)和测试时间(runtime)之间建立关系.
其中,性能分析选项往往是引爆机器学习搜索空间的主因,因为通用编译器的优化模块多达数百种[4],由此衍生出的性能分析的时间成本和复杂度是难以估量.以图2(a)为例,在Intel平台上对gcc和icc这2种编译器的4种常用优化选项O2、O3、内联、插装profiling分析,至少需要16(即24)组实验,在SPEC CPU2017测试用例上每组实验至少12 h,因此至少需要16 d才能完成实验.如果增加1个待分析的架构aoccHygon,实验会延长至24 d,数据会膨胀至960个,对于人工分析来说基本是很难完成的.因而编译器性能分析会陷入到选择架构组合的困难,那么弱化架构选择成为了现在主流的编译器心梗分析方法.
因此,为适度拓展性能分析覆盖的应用类型,我们需要适度扩张架构组合的选型集合,它在可能接受的人工开销范围内,聚集了更多有价值的优势架构组合,从而有利于我们实施更精准的性能分析,使目标编译器受益.
1.2 挑 战
多种平台、多种编译器所形成的架构组合会带来急剧膨胀的数据量,应用性能表现各异,在现有技术下,基于架构组合的性能分析很难开启.
然而,我们从实验数据中发现了一些契机.如图2所示,对于607.cactuBSSN_s例子,它最好的性能来自于aoccIntel,而对于619.lbm_s例子,它最好的数据形成于iccIntel.对于我们优化的目标gcc而言,理想的性能提升空间是在同一个X86平台上,目标编译器和其他编译器的峰值数据之间的差距,此区间值越大,目标编译器的提升空间就越高.所以可以为目标编译器借鉴其他编译器的优化技术,把目标编译器的性能提升至同一平台上的峰值数据,因此,面向理想性能空间的分析技术是可行的,且可以实施的.
实际上,目标编译器优化的现实目的是尽可能把优势优化技术纳入自身,而不在意这个技术是哪个架构组合产生的.因此,我们将眼光从单一优势编译器选型转移到性能分析用例的峰值数据所产生的架构组合上,重点研究它们的成因.首先,借助于已有峰值研究成果,我们对架构组合的峰值数据进行一次摸底测试,将不同架构组合的峰值汇聚到目标平台上,与目标编译器性能形成可以比较的集合.此时,所有测试用例的最高性能数据形成一个峰值数据集合,它们与目标编译器的性能差就构成了一个理想情况下最大化的性能提升空间,即理想优化空间,这个优化空间通常会超越icc等单一编译器所带来的性能提升空间.此时,性能分析不需要对所有架构进行繁琐的排列组合实验,仅仅需要从单一用例入手,对产生该数据的峰值选项进行细化分析,从而精准定位出决定其性能优势的优化技术,而分析的结论可以推广适用于同类用例中.这种在理想性能提升空间指引下的分析更具实用意义.它大大缩减了机器学习等辅助手段所进行的繁琐的选项分析过程,明确地以峰值性能为目的,其性能分析以及提升收益也更为明确,是具有实际应用价值的分析方法.这是本文所述面向理想性能空间的跨架构编译分析技术的基本思想.
1.3 方 法
面向理想性能空间的跨编译器分析技术PDCA是一种面向跨平台、跨编译器所构成的复杂场景下的编译分析和优化技术.它包括3个核心步骤:理想性能空间构建、细粒度优势优化定位、优化建议与实施.
图3展示了PDCA的主要思路,包括3个主要步骤.
1) 理想性能空间构建.图3中采用了Intel和gcc构成目标架构.选取了Intel和Hygon为待分析的平台,分别选取{gcc,icc,aocc}3种编译器作为参照编译器,在它们形成的架构组合上对SPEC CPU2017测试集进行性能测试与分析.表1中列举了平台、编译器以及SPEC CPU2017的关键信息.在理想性能空间构建过程中,在每个平台上,采用峰值选项对SPEC CPU2017进行动态编译,并将可执行码均汇集到目标平台上,进行性能测试.最终,形成图3①中的性能加速比分析曲线,此时,目标平台上汇集了3个架构组合产生的性能数据曲线.对于607.cactuBSSN_s而言,其最好性能来自aoccIntel,而619.lbm_s的最好性能来自iccIntel,即Intel平台上的icc编译器.如图3①中标记方形的标注,SPEC CPU2017的每一个用例的最好性能共同形成了理想峰值数据集,而它们的平均值与基准的gcc性能构成了一个理想性能空间,它优于单一的icc或者aocc带来的性能差.
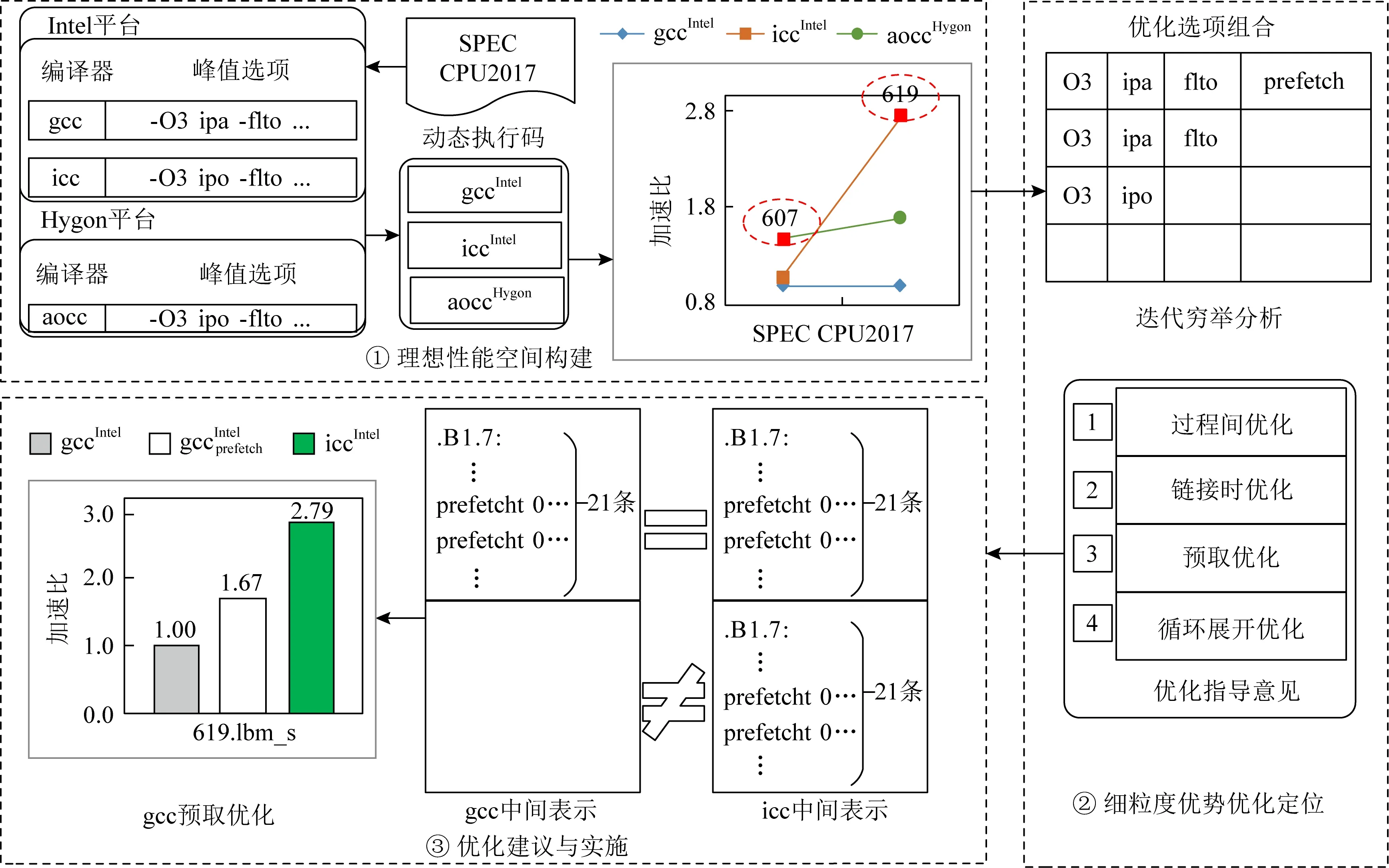
Fig. 3 A example of cross-architectural analysis techniques for the ideal performance space图3 面向理想性能空间的跨架构分析技术例子
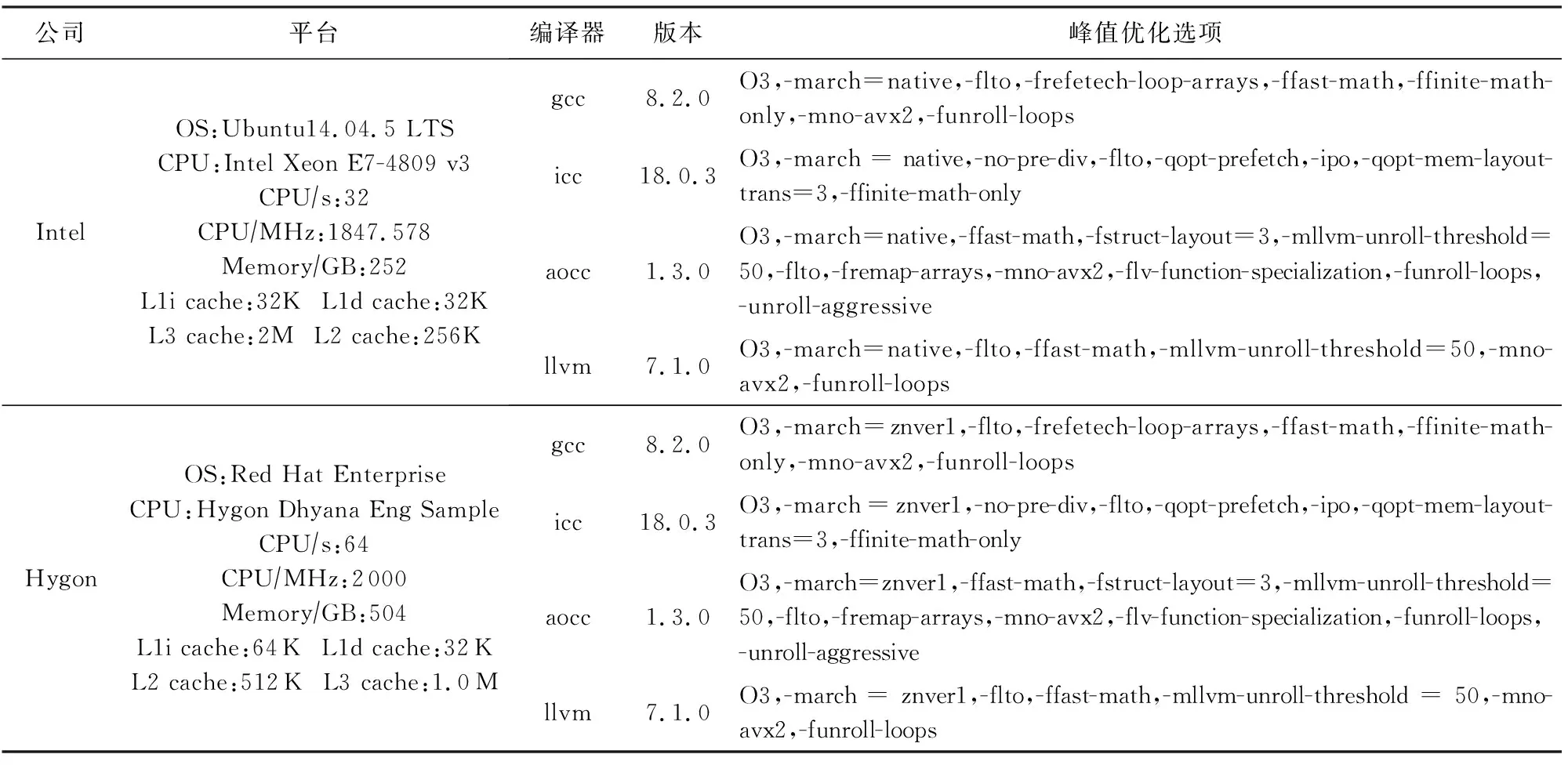
Table 1 PlatformInformation and Peak Optimization Options表1 平台信息及编译器峰值优化选项
2) 细粒优势优化定位.如图3②所示,在挖掘出产生峰值性能数据的架构后,在每一个峰值架构上,就可以采用成熟的机器学习等方法,仅仅在峰值选项范围内进行优化选项分析,直至分析出具有明显性能优势的优化技术.图3③中,619.lbm_s经过对常用峰值优化选项的有限次迭代测试,最后确定预取优化(prefetch)是非常重要的手段.到此,机器辅助的分析就结束了.
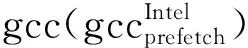
2 面向理想性能空间的跨架构编译分析方法
面向理想性能空间的跨架构编译分析技术是在跨平台、跨编译器的复杂场景下,获得更大性能提升的一种实用型性能分析技术.它将不同架构下用峰值选项形成的动态可执行码汇聚到目标平台上实施性能对比,借此形成一个峰值性能数据集.峰值性能数据与目标编译器之间就形成了一个理想情况下可以达到的最大性能提升空间,以它作为后续性能优化的目标.针对这个有限集合,PDCA对每个用例的峰值架构的选项进行深入分析,准确定位出带明显性能变化的优势优化技术,并指导目标编译器设计实现.
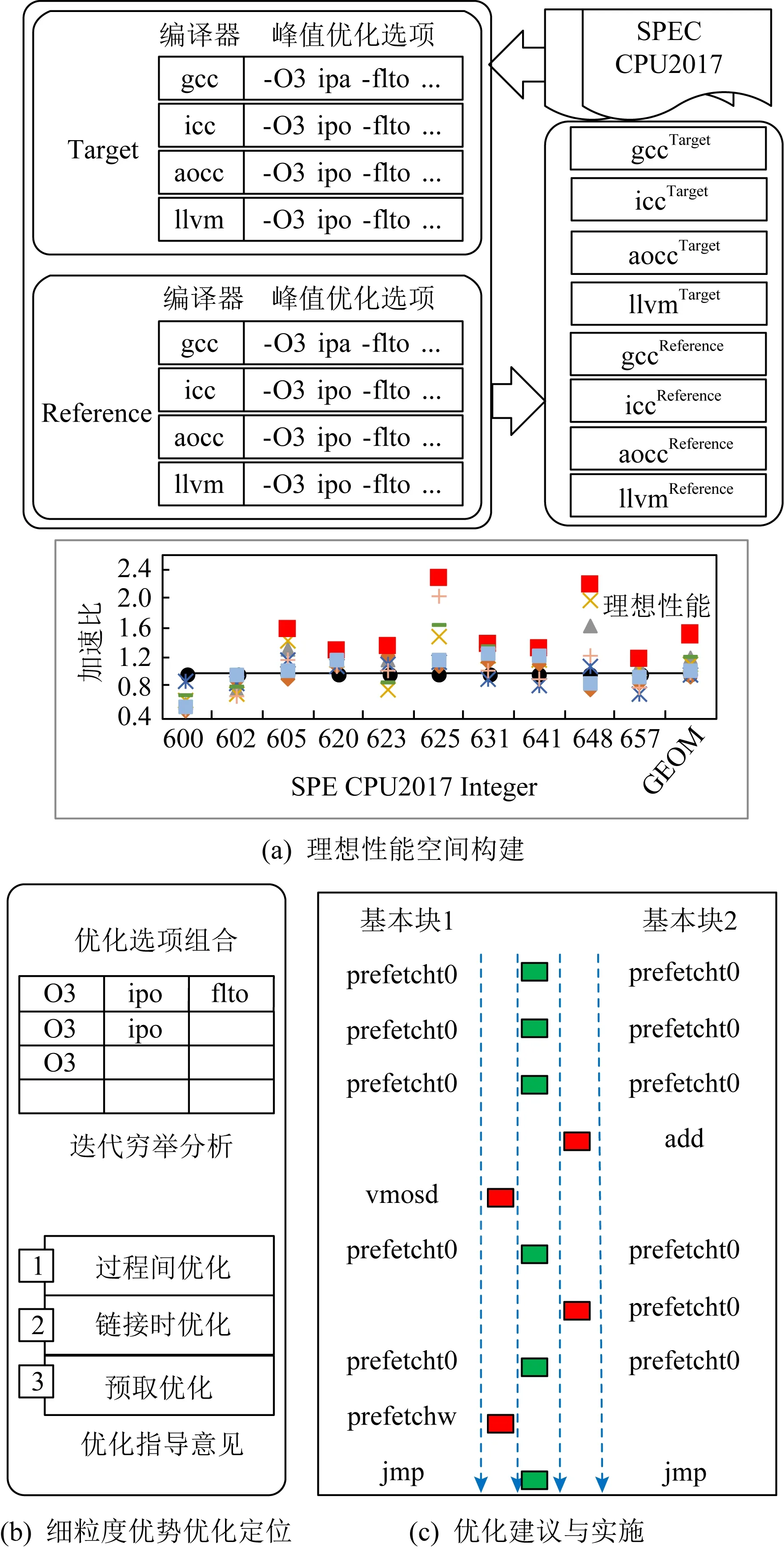
Fig. 4 Cross-architectural analysis techniques for the ideal performance space图4 面向理想性能空间的跨架构分析技术
图4展示了面向理想性能空间的跨架构编译分析技术的主要架构,它包括理想性能空间构建、细粒度优势优化定位、优化建议与实施3个主要模块.首先PDCA构建一个理想情况下,目标编译器能获取的理想性能提升空间.它借鉴业界发布的峰值数据,将候选平台和候选编译器所形成的架构组合形成的用例汇集到目标平台上进行性能测试.在此过程中,由每一个测试用例最好的性能组成了理想峰值数据集,平均的理想峰值数据与目标编译器性能之间的差距形成了理想性能空间,这是后续优化提升的依据.每一个峰值数据对应的架构构成一个峰值架构组合.其次,在细粒度优势优化定位过程中,针对每一种峰值架构,在限定的选项范围内,即峰值选项范围内进行机器学习自动选项分析,辅以VTune等性能分析工具,明确引发性能差异的主要优化手段;最后,经过人工分析,明确优化方式,线性比对热点区域代码的中间表示指令(intermediate representation, IR),并仿照参照编译器的设计实施到目标编译器中.经过上述3个步骤,目标编译器可以获得最终性能提升.
PDCA是一种实用型分析技术,它在一个理想性能空间的指引下,对峰值选项进行分析.这种方式不仅大大减少了分析的工作量,还可以对目标编译器的最终受益效果更加明确.在理想性能空间的指引下,将分析结论和设计方案逐步实施在目标编译器中,使其真正获益,继而缩小目标编译器与峰值性能数据之间的差距.
2.1 理想性能空间构建
构建理想性能空间需要扩大待分析的架构组合数量,为目标编译器提供尽可能多的提升机会.如图4(a)所示,首先明确选择出待分析的平台和待分析的编译器组合,在每个平台上根据峰值选项使用每个编译器对SPEC CPU2017测试集编译出动态可执行码.然后将所有的动态可执行码集中于目标平台上运行测试.这样,无须考虑外围库的干扰,不同架构组合下的可执行码的性能差距可以近似地认为是由编译器优化能力所致,在后面的分析过程中,只需仅仅关注编译器本身即可.
跨平台测试完之后,在目标平台上会产生多组性能数据.对于每个测试用例均选取最高的性能,即可构成峰值架构集合,此峰值架构集合最终的性能与目标编译器构成理想性能空间(idea-peak).一般来说,PDCA所关注的编译器越多,理想性能空间就越大,目标编译器多能汲取的优化经验也越为广泛.
需要说明的是,在这个过程中,在某个编译器中的峰值选项可能与其他编译器选项不同,我们会在其他编译器上对该选项做性能测试,将能够呈现优势的选项补充到其他编译器的峰值选项中.但是我们的目标是为目标编译器优化提供最大的优化空间,并不是寻找最佳的优化选项组合,所以峰值选项进一步地改进不在本文讨论范畴中.
2.2 细粒度优势优化定位
编译器性能分析首先需要明确性能差距的原因,即优势优化选项.通常我们对峰值选项做有限次的迭代测试,确定优势优化选项的大致方向;然后分析由诸多优化交叠作用后、历经重重演变的应用程序中间代码,例如llvm的中间表示IR,或者汇编码.这些中间代码有时甚至是经过代码膨胀数倍.人工需要在众多优化选项中进行排除并进行验证.这个过程耗时耗力,并且十分低效.为了降低分析难度,有很多机器学习的相关研究用于分析优化选项的作用[5];一些分析工具还可以帮助定位代码的热点函数、热点区域[6].因此,我们将这些方法结合在PDCA中,使它更加实用.
对于每一个峰值架构,我们可以采用成熟的机器学习的方法继续辅助分析,从而圈定更有分析价值的选项范围(优势选项)以及它所影响的代码范围.这里,由于峰值选项是最直接带来优化效果的组合,因此,具有明显优化效果的技术一定藏于其中.因此,PDCA将分析目标圈定在峰值选项范围内,大大降低了分析的时间开销.在明确出优势选项后,用VTune和gprof等工具辅助,我们最终可以将优势选项以及它所影响的代码范围圈定在很小的区域内,有利于人工分析.
2.3 优化建议与实施
在自动分析结束后,待分析的代码区域相对较小,需要进行人工分析,我们称之为“最后一步”.这个过程高度依赖于编译器设计人员的专业经验,对来自目标编译器以及峰值架构的中间代码区域(IR)进行线性对比,确定区域中存在的差异,依赖经验推测出2个编译器在优化上的不同原因.通过对目标编译器的相关优化模块进行深入了解,仿照峰值架构进行改进优化,从而获得一定性能提升,尽量缩小理想性能空间.现今,研究领域尚欠缺成熟的自动工具来替代这一步,因此,这一步也成为编译器性能分析中难度最大的环节,编译器设计人员的经验决定了优化分析的时间开销.我们接下来的研究将针对“最后一步”问题展开研究.
3 实验与分析
PDCA一种面向由多平台、多编译器构成的复杂场景下的编译分析技术.本节,我们将PDCA应用在Intel和Hygon平台上,并围绕2个问题进行探索:
1) 在多平台、多编译器的复杂场景下,PDCA是否可以给目标编译器更大的性能提升空间,即PDCA是否具有实用价值.
2) PDCA是否足够精准,即它所快速定位出的优势优化是否可以带来实际性能提升.
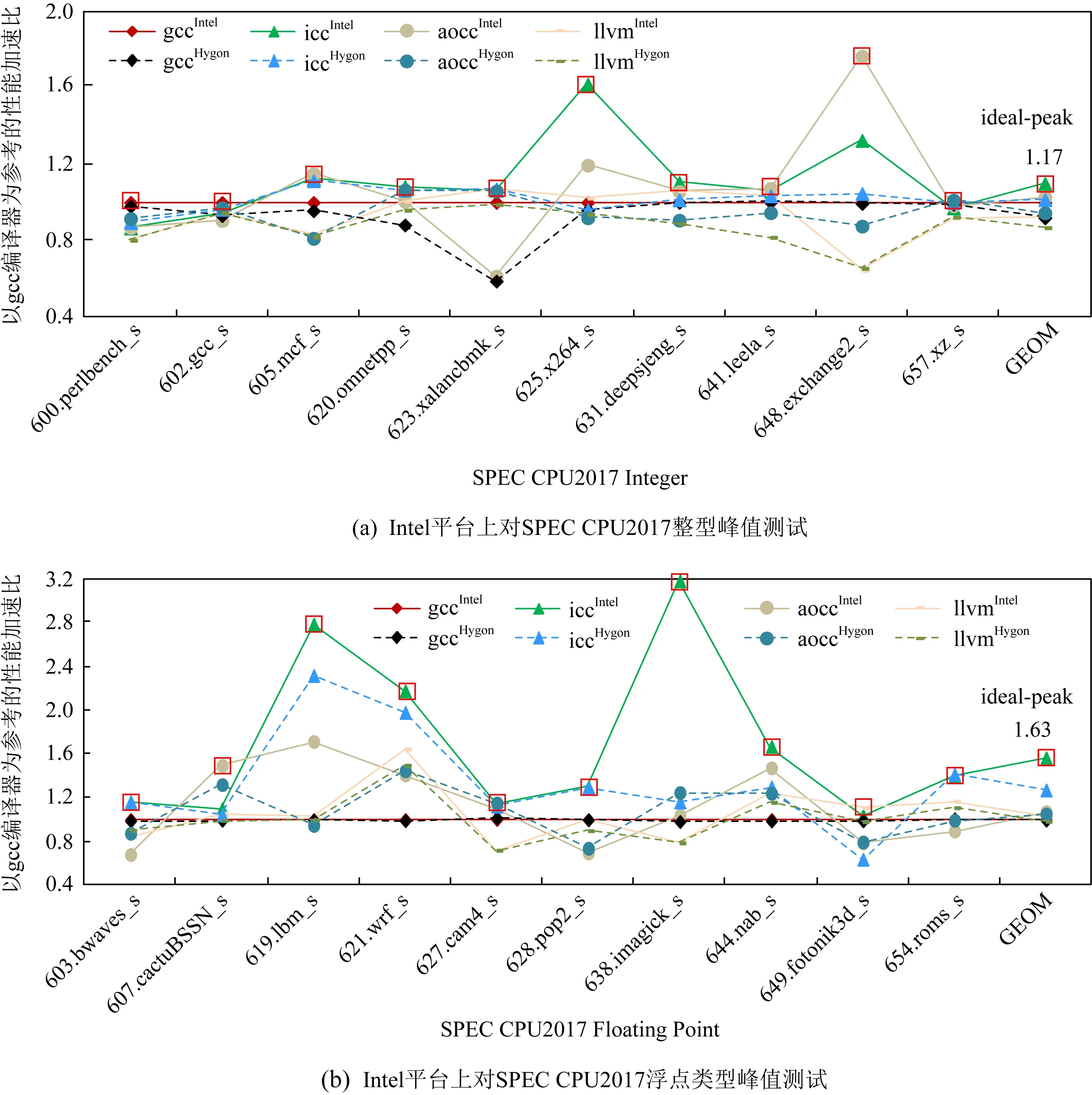
Fig. 5 Peak testing on the Intel platform with gcc as the benchmark图5 Intel平台上以gcc为基准的峰值的测试
针对问题1,我们将PDCA应用在Intel和Hygon两个平台上,并选择4个代表性编译器gcc,icc,aocc,llvm作为候选编译器,它们最终形成表1所列的8个候选架构组合.其中,以Intel平台为例,compilerIntel是指在Intel机器平台上编译并运行,compilerHygon是指在Hygon机器平台上编译后经跨平台汇集到Intel平台上执行的动态可执行码.峰值选项经参考SPEC CPU2017官网和测试用例的基本特征而形成[7].一些编译器的峰值选项具有特有选项,我们会在其他编译器中尝试运行,将会带来性能提升的选项补充到其他编译器中.总的来说,不同峰值选项均包括了O3、内联、循环优化、链接时优化、高效内存管理库等主要优化手段.通过将8组架构的峰值数据汇集在目标平台Intel上,用以判断PDCA技术是否比单一icc带来更大的性能分析空间;同理,我们在Hygon上对来自上述8个候选架构的组合进行对比分析,用以判断PDCA是否具有一定普适效果.针对问题2,我们将PDCA施用于峰值架构上,并完成细粒度分析,生成优化建议.通过优化实施效果来展示PDCA在分析指导方面的精准性.
3.1 理想性能空间
3.1.1 以Intel平台gcc为目标编译器
gcc是使用范围最广的通用编译器之一,它具有卓越的健壮性,然而在性能上与商用编译器之间存在一定的差距,有很大的优化空间.在Intel平台上以gcc为优化目标编译器,采用常用的性能加速比来进行2款编译器的性能对比.如式(2)所示,以目标编译器架构(gccIntel)为基准,其他编译器架构(compilerplatform)的性能与之对比,即可算得性能加速比(speedup):
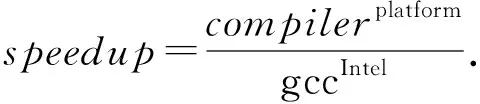
(2)
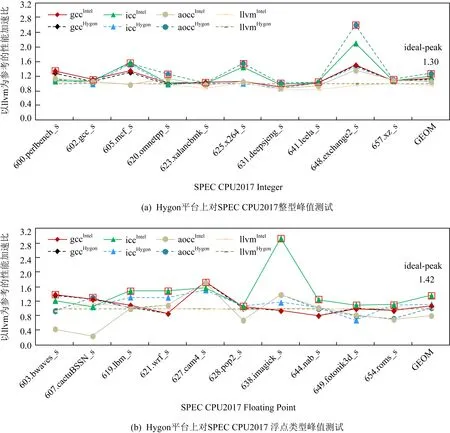
Fig. 6 Peak testing on the Hygon platform with llvm as the benchmark图6 Hygon平台上以llvm为基准的峰值测试
我们在Intel和Hygon上,采用表1所列各个编译器分别对应的峰值选项对SPEC CPU2017定点和浮点20个测试用例分别进行编译,形成8组动态链接可执行码,并将其放入目标平台Intel上执行,依据各个用例最好的性能数据来建立理想性能区间以及峰值架构集合.在这个过程中,由于每组代码都是动态连接,在执行过程中会使用本地编译器相同的库代码,因此,SPEC CPU2017性能差异主要体现在编译器自身优化能力上.图5列举了Intel上定点和浮点集合所产生的8组架构组合的性能曲线.在图5(a)中,iccIntel的性能比基准gccIntel的性能高出10%,在整个定点测试用例中,峰值架构并不是仅仅来源于单一的icc编译器,从图5可以发现在不同应用上其他架构组合也表现不出,如648.exchange2_s的峰值架构是aoccIntel,并不是icc编译器.对以上所有的定点测试用例选择峰值架构,即有17%的理想性能空间.同理,如图5(b)中的浮点数据曲线一样,虽然icc针对浮点用例的优化是具有一定优势,但理想性能空间不仅仅来源于icc,还来源于其他的峰值架构,如607.cactuBSSN_s,它最好的性能来自于aoccIntel.最终对浮点测试用例选择最好的峰值架构,即有63%的理想性能空间.
3.1.2 以Hygon平台llvm为目标编译器
为了说明PDCA跨架构分析的必要性以及可行性,我们将PDCA布局在Hygon上,并选择了另外一款主流编译器llvm(llvmHygon)[8].随着芯片的飞速发展及多元化,llvm所具有的小巧、易组合等特点使它成为研究领域以及AI等芯片设计公司首选的编译器工具之一.本节的实验也有助于评估llvm的性能.同3.1.1节实验一样,我们在Intel和Hygon上采用表1的峰值选项对SPEC CPU2017定点和浮点分别编译,形成8组动态链接执行码,并将其放入到目标平台Hygon上执行.图6是Hygon平台上定点和浮点所产生的8组架构组合的性能数据曲线.图6(a)数据表明,峰值数据不仅仅来源于aoccHygon架构,还来源于gccIntel架构,并且理想性能达到30%.图6(b)中所有的峰值数据均来自于Intel平台上编译的可执行码,多数峰值数据来自于标记三角形的曲线代表iccIntel架构,结合gccHygon架构所产生的峰值数据,理想性能空间高达42%,说明在Intel机器上icc编译器编译的可执行码性能突出,是非常可值得作为目标平台上目标编译器优化的参考.
3.1.3 小结
采用PDCA对Intel和Hygon上编译器进行全面的对比分析.如图7所示,在同一个平台上,理想性能区间很难由一个架构组合覆盖;在不同平台上,同一种编译器的性能优化能力也不尽相同.因此,PDCA提供了一种实用分析技术,可以在扩张的架构组合的基础上进行更大范围的分析,从而使跨平台跨编译器构成的复杂场景下的编译分析成为可能,使得目标编译器有更大的性能提升可能.
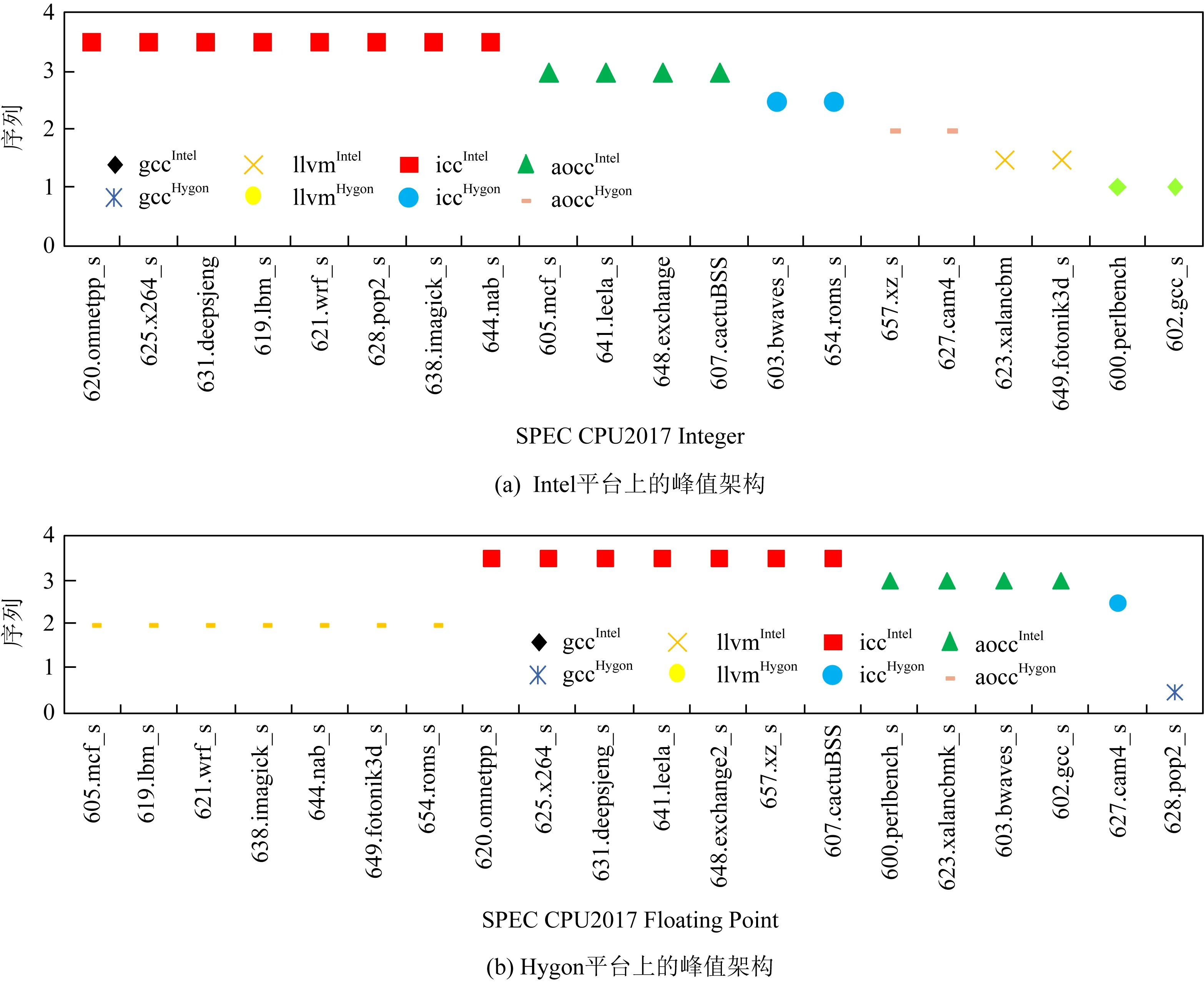
Fig. 7 Peak architecture set on the Intel and Hygon platform图7 Intel和Hygon平台峰值架构集
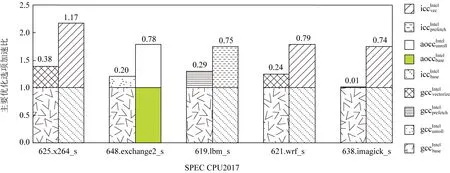
Fig. 8 Advantage optimization options on the Intel platform图8 Intel平台上优势优化选项
3.2 细粒度性能分析以及优化指导
图7展示的是SPEC CPU2017定点和浮点测试用例在Intel和Hygon平台上的峰值架构组合.根据以上的呈现的峰值架构,选定性能差距最大且最有可能优化的测试用例,如Intel平台上的619.lbm_s,625.x264_s和638.imagick_s等用例.然后对以上的具体测试用例根据峰值优化选项做有限次地迭代测试,可以明确出优化方向,即优势优化选项.
如图8所示,我们在Intel平台上选择了峰值架构性能比目标编译器gcc性能差距更大的测试用例,对选定的测试用例做仔细地分析,可以明确出优势优化选项.首先,以峰值选项全部关闭为基准数据,然后只打开某一重要峰值选项,这样即可测试出该优化选项的性能加速比,然后与基准架构在该优化选项的加速比做比较,差值越大表示此优化选项最有可能是优势优化选项.如619.lbm_s测试用例,iccIntel架构中预取优化选项的加速比为75%,但gccIntel架构上的加速比只有29%,所以该测试用例的优势优化选项为预取优化选项,为后面的优化确定了优化方向.
在此基础上,我们借助VTune工具,确定热点区域函数,将分析代码缩减至一定的范围,有助于下一步的分析.接下来进一步线性对比该热点函数优化之后的汇编指令,经发现是代码分支和预取距离的因素导致gcc编译的预取指令少于icc编译的预取指令,为此修改gcc源码,最终相较于优化之前的gcc版本,该测试用例有67%的性能提升.
综上所述,PDCA是一个实用的分析优化方法,在选定峰值架构之后,通过细粒度分析,可以准确定位出优势优化选项和优化意见,并最终达到很好的性能提升效果.
4 相关工作
编译器的选型受机器平台和编译器特征的影响.现今机器平台也越发复杂,通常是处理器与多个加速设备互联组成异构系统[9].高性能计算系统架构基本使用了MIC(many integrated core architec-ture)和GPU[10]等众核处理器作为加速器或协处理器.王淼团队在异构多核处理器上提出了一种代码自动生成框架[11].
随着半导体工艺技术的提升,编译器的发展也是日新月异.华为为解决Android应用程序安装速度慢和运行效率低的问题,开发了方舟编译器.llvm是目前研究最热和发展最快的开源编译器之一.根据它可定制的特性以及遵守伯克利软件发行版(Berkeley software distribution, BSD)的开源协议,许多厂商已经开源出了许多优秀的产品.谷歌基于llvm开发了Gollvm,旨在为Go语言提供更强大的特定编译器.微软基于llvm开发了LLILC,作为跨平台的.net代码生成工具.AMD也基于llvm开发出AOCC编译器,旨在针对AMD系列17 h处理器-Zen架构提高性能.不仅国外企业热衷于llvm,国内许多企业也越来越多地选择了llvm,将其作为它们核心产品的基本框架.AI领域的创业公司,如寒武纪、地平线等,将llvm搭载于自己的智能芯片上.
编译器的优化模块高达数百种,编译器的优化顺序也非常重要.迭代搜索是一种确定优化选项执行顺序的一种重要技术,相对于静态模式有显著的性能体现[12].Ogilvie团队将序列分析的方法和迭代编译的主动学习技术相结合,可以降低迭代编译花费的成本并且能预测特定应用程序的重要优化选项[1].Dubach团队基于机器主动学习的方法在不同平台上自动学习最佳的优化,以适用于任何新的微体系架构[4].Kulkarni团队是使用机器学习的方法将优化顺序构建成Markov模型,以减小编译器优化阶段的排序问题[13].优化之后的测试用例代码大小是决定其性能高低的关键因素,为了减小测试用例代码量,王铮团队采用了序列对比来合并任意函数,以此可以提升过程间优化的性能[5].为了实现高效的预取优化,Timothy团队采用深度优先算法实现了一种新的编译器通道,实现自动生成用于间接访问内存的预取[14].Doerfert团队根据Presburger算法框架来收集、概括程序特征和简化优化先决条件[15].Fursin团队在gcc编译器上使用了机器学习的方法,实现自动提取程序特征以调整程序优化变换[16].
SPEC CPU2017是重要的性能测试集,此测试集包含的程序用例多,复杂度高,代码量大且涉及的算法广泛[17].Panda团队基于主成分分析(PCA)和聚类等统计方法来寻找测试基准程序间的相似性[7].使用测试基准的子集,这可极大减少测试时间.Genesis[18]是一种生成用于机器学习的性能自动调优的合成程序语言.Cummins团队在大量的开源库源码中,使用深度学习方法自动地推测程序片段结构,然后自动生成与此程序片段结构相似的应用测试程序[19].
5 总结与展望
本文阐述了编译器的优化受机器平台和编译器特征的影响.提出了一种基于峰值数据的面向跨平台跨编译器的编译器分析与优化方法.选择峰值架构,构建目标编译器在目标平台上的理想性能提升空间,并为其做最大可能的性能优化与提升.
本文通过实验验证了该方法在多平台与多编译器之间的普适性与实用性.分别在Intel和Hygon平台上为SPEC CPU2017定点和浮点每个测试用例提供可靠实用的峰值架构,并在Intel平台上对突出的峰值架构测试用例做了详尽分析,结合对常用峰值选项的迭代编译与成熟的机器学习优化分析方法为目标编译器总结出优化方向.在“最后一步”的分析中更多地依赖工作者的经验确定待优化方向,还没有成熟的自动化工具,这是我们未来研究的方向与重点.
贡献声明:赖庆宽进行了该论文的实验验证和论文撰写等工作;吕方进行了论文中方法的设计和论文的修改;何先波和贺春林进行了论文的修改和校正;冯晓兵进行了课题的调研、论文的修改和讨论.
