融合多级特征的俄语推特文本情感分析
2021-05-24祁瑞华徐琳宏
刘 鑫,祁瑞华,徐琳宏,陈 恒
(大连外国语大学 语言智能研究中心,辽宁 大连 116044)
E-mail:liuxin_szn@dlufl.edu.cn
1 引 言
互联网背景下的大数据已成为推动数字人文研究的重要力量,推特等社交媒体文本的情感倾向分析一直是自然语言处理的研究热点[1].俄语作为联合国官方语言之一、全球第八大语言,在东欧和中亚区域的17个国家被广泛使用,将其作为母语或第二语言的总人数约为2.58亿[2].社交媒体作为民众交流观点和表达情感的主要途径之一,每天产生海量带有主观情感色彩的俄语短文本,归纳、分析和推理其中蕴含的情感信息,有利于相关国家的商业决策制定、政治舆情分析和社会趋势预测[3],对防范精准政治营销,构建和谐稳定国际关系、推进跨国和区域间经贸、开展合作共赢的“一带一路”战略具有重大价值.然而目前针对该领域的研究大多聚焦于地位强势的英语,多数分析工具均面向英语的特点设计和实现,专门针对跨领域俄语情感分析的研究并不多见[4].部分研究试图借助英语相关工具,获取俄语英译文的情感分析结果[5].然而,由于翻译阶段情感乃至语义的损失,分析阶段又忽略了俄语自身特性,所以结果并不理想.
俄语社交媒体文本的情感分析主要存在两大难点:1)俄语自身语言特点使得文中经常存在自由语序、一词多义、复杂形态和非投影关系[6],增加了语义分析和情感提取的复杂性;2)社交媒体文本在传递信息、评价对象或表达观点时具有口语化、俚语多、语言不规范和上下文信息不明显等特点,采用常见的情感分析方法难以获得满意的结果[1].
针对上述困难与俄文网络用语的特点,本文结合传统方法和深度学习方法,完成如下工作:第2节梳理、分析和比较了近些年俄语情感分析的相关研究成果;第3节针对源自规则集、情感词典等多角度提取的词级和句级情感特征进行分析、筛选和处理,从而基于俄语特点和情感常识[7]人工设计并初始化深度模型所需的特征向量;第4节结合卷积神经网络(Convolutional Neural Network,CNN)、循环神经网络(Recurrent Neural Network,RNN)和自注意力机制(Self-attention)等多种深度学习技术,建立基于自注意力机制的CNN-BiLSTM混合模型(Attention-based CNN- BiLSTM mixed Model,ACBM);第5节基于俄语推特文本(后面简称推文)情感分类的实验结果,探讨采用英译文情感分析方案的可行性,对比了多种模型在各类词级、句级特征加入前后的结果,并通过样例分析证明本文模型能有效提升俄语推文的情感分析结果.
2 相关工作
情感分析(Sentiment Analysis,SA)旨在识别非结构化文本的主观态度,主要任务之一是对相关作者观点和倾向性的分类[3].目前,面向俄语的情感分析研究稀少,通常借鉴英语等语种的分析方法[4],结合俄语自身特点的相关研究明显不足.现有对社交媒体文本的情感分析主要采用基于词典、机器学习或深度学习的方法,尤其深度学习方法近年来在许多任务中表现突出[1,8].
2.1 基于词典的俄语情感分析
基于词典方法的核心模式是抽取情感判别规则和构建情感词典,即制定并汇总基于单词、短语和句法结构设计的判断规则,并以情感词典作为判断情感极性的主要依据.2015年,莫斯科国立大学Loukachevich团队[9]针对俄语在电信领域的文本特征,实现了基于规则集合的分类器,其F1高于SVM(support vector machine)和最大熵分类器,但该方法比较依赖语言或领域专家的从业经验与个人能力,不仅规则集合的维护扩展成本较高,而且难以制定适合多语言和跨领域的规则集合.2016年,Loukachevitch团队[10]针对跨领域问题构建了每个词条具有4个情感级别的俄语通用情感词典RuSentiLex,并基于该词典在SentiRuEval-2016的推特信誉监控任务中取得很好的结果.同年,喀山联邦大学Tutubalina团队[11]针对SentiRuEval-2015中面向目标的文本分类任务,基于面向目标的N-gram特征和词汇情感值等统计结果,实现了情感词典的自动扩展,该方法的最大熵分类器在精确率、召回率和F1等方面均高于人工构建的词典.基于词典的情感分析方法虽能体现文本的非结构化特征,但这类方法本质上依赖判定规则和情感词典的质量,其优劣程度基本取决于人工设计和先验知识,很难涵盖互联网层出不穷的新词和俄语复杂多样的形态.
2.2 基于机器学习的俄语情感分析
特征工程是基于机器学习算法处理情感分类任务成败的关键,实验中常用的特征有N-gram特征、TF-IDF特征、句法特征和词性特征等.2012年,Yussupova N[12]等针对俄罗斯银行贷款审查文本,对比了多种机器学习模型,最终发现所有模型准确率均高于85%,且SVM算法结果优于NB(NaÏve Bayes)算法.然而,2017年Bobichev等[13]在自行创建语料库(331篇跨领域俄语新闻)上的对比实验却发现,NB算法在经济、社会和体育3个领域情感分类结果的F1均优于SVM算法.可见,特征选取是否合适是影响机器学习分类效果的主要因素,在特定领域表现优秀的特征不一定在其他领域同样表现优秀,面对特征稀疏、内容简短且形态复杂的俄语社交媒体文本,传统的机器学习算法很难挑选出最适合的情感特征.
2.3 基于深度学习的俄语情感分析
深度学习的兴起极大影响了情感分析的研究现状.2016年,Sakenovich 等[14]在3万条俄语新闻语料上对比了多种深度学习模型,其中两层堆叠的长短期记忆网络(Long Short-Term Memory,LSTM)凭借较强的序列记忆能力,成功克服普通RNN梯度爆炸和梯度消失的缺点,获得最佳的准确率86.3%.Galinsky等[15]则针对餐馆和商品俄语评论使用字符级嵌入的CNN提取文本局部特征,并借助替换同义词扩充训练语料的方法,将准确率提高了2.4%.上述研究虽然均试图构建多隐层的深度模型,但由于搭建的网络结构相对简易和单一,不仅未能有效结合文本的局部特征和序列特征全面提取更深层的情感信息,而且受限于深度学习模型的黑盒特性,难以充分利用俄语自身的特点和情感常识.
3 俄语推文多级情感特征
针对俄语社交文本“口语化、不规范、一词多义和形态多样”等特点,本文制定了系统的特征提取规则,能够从多角度抽取俄语推文中不同粒度和种类的情感特征.这种融合了俄语多级情感特征的表示方法,着重分析蕴含局部情感信息的词级特征,以及表达整体情感信息的句级特征.
3.1 词级情感特征
3.1.1 词性特征和形态特征
俄语社交评论趋向使用形容词和动词表达情感[16].针对语序自由、不够规范的俄语推文,为使模型将注意力集中于情感信息更丰富的实词,本文借助词性标注工具自动获取每个单词的词性特征,借以区分不同单词情感信息的权重.本文针对每个单词,先通过谷歌翻译、NLTK、俄语形态分析工具PyMystem(1)https://pypi.org/project/pymystem3和PyMorphy2(2)http://www.github.com/kmike/pymorphy2分别标注词性,再汇总上述4种结果并通过多数表决法获取分类结果为“形容词、副词、动词、名词、感叹词、Emoji或其他”的词性情感特征.
为了探究俄语各种复杂形态对情感表达的影响,本文通过工具PyMystem和PyMorphy2将每个单词标注为分属10大类的28种俄语形态(比如,形态“式”分成命令式和陈述式两类),表1罗列了部分重要的俄文形态.因为PyMystem不仅采用了基于词典和规则的算法,而且充分考虑了语境的上下文信息,与后者相比可信度更高.所以本文优先采用PyMystem获取的结果作为单词的基准形态特征,而将PyMorphy2获取的结果作为补充形态特征.
3.1.2 情感分数特征
与英语相比,针对俄语情感词典的研究较少,且现有工作或只面向固定领域的相关话题[9],或只适用于面向目标的情感分类[11],在分析俄语社交媒体文本时存在一定局限性.词典[10]虽包含16057个通用领域的情感词条,却仍难以涵盖纷繁复杂的俄语形态和层出不穷的网络新词,而且仅依据情感强度粗粒度地将单词分为4级,没有精确地区分词条间细致的情感差别.与已有俄语情感词典相比,业内广泛采用的英语情感词典Sentiwordnet[17]和多语种情感词典Senticnet[18]均具备规模大覆盖广、情感强度细致精确等特点.因此,本文先借助Sentiwordnet依据词性和英文释义获取每个单词的情感分数,再通过Senticnet分别获取每个俄语原词的情感分数及其英文释义的情感分数.上述3个情感分数均为-1至+1的连续型数据,具备更精细地描述单词情感倾向与强度的能力,故将其作为词级的情感分数特征,为模型提供更清晰准确的情感信息.

表1 PyMorphy2和PyMystem标注的俄语形态Table 1 Russian forms marked by PyMorphy2 and PyMystem
3.1.3 脏话俚语特征
社交媒体用户习惯使用不雅词语表达强烈情感、发泄不满情绪、表达贬斥的态度或咒骂其厌恶的对象.在俄语推文中也经常出现各种脏话俚语,加上许多非直接性表达,使得影响句子情感因子的颗粒度加大,单纯依靠传统的情感词典无法满足需求.本文参考文献[19,20],构建了一个包含3类单词或词组的脏话俚语词典,包括把对方比拟成动物或污秽无用物品的词汇(如гавно、мудак),与性行为或性器官相关的脏话(如блять、ебал和пенис),以及各种用于侮辱、咒骂或渎神的词语(如дебил、дура和слабак).本文以单词是否存在于该词典中作为评判标准,把每个俄语单词分成脏词和非脏词两类,并将该结果作为词级的脏话俚语特征.
3.1.4 字母特征
为了表达强烈情感,社交网络上的用户经常有意识违反俄语语言规则[21].比如,将单词的首字母或尾字母、元音或响辅音(л,м,н,р)、暂噪辅音或爆破噪辅音(б,г,д,к,п,т)重复多次,例如"Это суперрррр!"和"Дддуууббб ты трууушный!!!".再比如,用大写字母表示故意错置单词的重音,表达讽刺、愤怒、轻蔑、厌恶等负面情绪,例如 "Скоро-ВСЁ БУДЕТ ХОРОШО ! "和"КрасавЕц! Ничего не скажешь! Лысый,толстый и морда красная!".因此本文将每个单词中大写字母和重复字母的个数作为词级的字母情感特征.
3.2 句级情感特征
3.2.1 英译情感特征
在所有语言中,针对英语情感分析研究占比最大,并衍生出大量专业且便利的分析工具.尽管俄译英阶段会损失部分情感特征并引入些许噪声,但与社交媒体上语序混乱、规范性差的俄语原文相比,翻译引擎能获得相对规范且符合语言模型的英译文.若合理选择英语情感分析工具,其分析结果可以为俄语情感分析提供可靠的参考[5].在众多成熟的英语情感分析工具中,Vader[22]和TextBlob(3)https://textblob.readthedocs.io不仅适用领域广泛,而且尤其擅长分析社交媒体短文本,无需训练即可得到若干个表达情感极性的浮点型数值.因此本文在实验中,先分别使用Google和百度的翻译引擎获取英译文,再针对英译文依次使用Vader和TextBlob获得情感极性值,最后将其作为句级的英译情感特征融入深度模型.
3.2.2 表情符号特征
与其他语言类似,俄语社交媒体用户也常用标点符号的组合来模拟面部表情或与情感相关的事物,进而表达正向或负向的情感,例如,用"^_^"代表笑脸,用"3)"表示心和爱意.本文参考文献[23,24],以表2为极性分类标准统计各类表情符号的数量,并将句中各类极性的表情符号数量作为俄语文本的表情符号特征,以反映俄语文本中正负情感极性的强度.

表2 表情符号的分类Table 2 Classification of emoticons
3.2.3 标点符号特征
俄语社交媒体用户习惯通过叠加叹号、问号等标点符号来表达情感的强烈程度,例如"Я не хочу!!!!!!!"和"Как же плохо????"[21],或在文本的结尾处添加连续多个小括号表达正向或者负向的情感,例如"Очень добрый человек с открытой душой,что редкость в наше время)))"和"О Боже Алина беременна Пойду поллачу((((".因此,本文将叹号、问号和结尾处不同方向的小括号的数目,作为俄语文本的标点符号情感特征,来体现该文本表达的情感极性与强度.
4 俄语情感分析自注意力深度模型
为了能有效结合CNN模型捕捉多维数据局部特征的能力、RNN模型提取序列中长期依赖关系的优势,以及自注意力机制聚焦重要信息的特点,进而提升俄语情感分类效果,本文提出了一种基于自注意力机制的CNN-BiLSTM深度学习混合模型ACBM.如图1所示,该模型共由6个子模块构成.首先,词级特征编码层基于词向量和各种词级情感特征,将每个单词及其对应的情感特征转化成包含语义和情感信息的情感词向量.接着,局部特征提取层负责从相邻的信息中提取每个单词的上下文局部特征.然后,由序列特征提取层和注意力层协同工作,前者负责提取整个文本的序列特征,后者负责生成序列中每个元素的情感权重.最后,情感分类层结合之前生成的注意力序列特征以及句级特征编码层的输出,生成整个模型情感分类的判定结果.
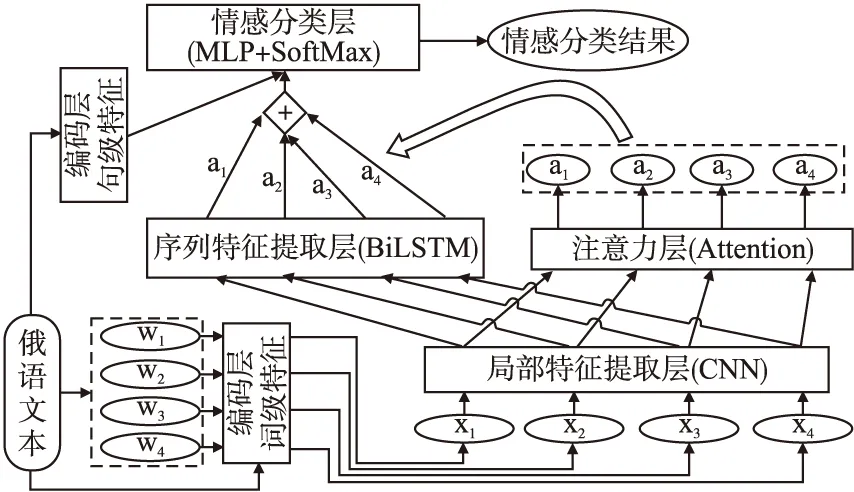
图1 ACBM的结构图Fig.1 Structure diagram of ACBM
4.1 词级特征编码层
为了将文本信息转化成神经网络能够处理的数字向量,本文采用fastText[25]基于维基百科和海量公共网站文本训练得到的预训练词向量,每个单词的词向量wi的维度是300.由于词汇表规模很大,共包含1888423个俄语单词,而且采用了N-gram字符特征生成词向量,所以fastText不但能有效降低OOV(Out of Vocabulary)的概率,而且适用于形态丰富的俄语.

4.2 局部特征提取层
俄语词汇不仅富于形态变化,而且具有很强的多义性.Р.А.Будагов对大型词典调查研究后发现,俄语中多义词占比高达80%,许多单词不仅含义繁多,且各自蕴含的情感信息截然相反[26].例如,俄语中最基本也最活跃的动词之一,"идти"甚至包含20多种含义,而动词"следить"同时具有“注视”、“关心”、“监视”和“跟踪”等多种不同的情感含义,其表达的语义及蕴含的情感信息,不仅由自身决定,还受到语境中上下文其他单词的影响[27].又比如,当形容词"зелёная"后面分别连接"трава"、"молодёжь"和"скука"时,含义依次为“绿色的草”、“幼稚的青年”和“难堪的苦闷”,此时不仅词义各不相同,且表示的情感极性也不一致.
针对俄语“词义多样、语序自由”等特点,为了提取更客观精准的词语局部特征,本文针对词级特征编码层输出的情感词向量矩阵,采用CNN提取每个单词的上下文局部特征,其结构如图2所示.假设文本中包含n个单词,情感词向量xi
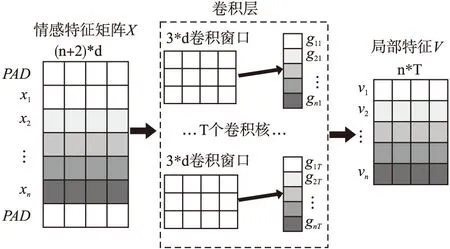
图2 局部特征提取层Fig.2 Local feature extraction layer
的维度是d,则情感特征矩阵X的初始形状为n×d.为了使CNN输入输出的序列长度一致,本文通过填充PAD,使矩阵X形状变为(n+2)×d.卷积层中,共包含T个尺寸为3×d的卷积核W,当第j(1≤j≤T)个卷积核Wj对矩阵X中的xi进行卷积运算后,会获得局部特征值gij(1≤i≤n),计算过程如下:
Leschot (Felsa)也宣布推出一款以ETA2824为基础的机心。起价125瑞士法郎。其购买了Technotime 法国85%的股份,将生产改进到现行水准。如今向Camy这样的品牌供应几千件产品。他毫不遮掩自己的雄心:五年内50万件。
gij=f(Wj⊙Xi:i+2+b)
(1)
vi=[gi1,gi2,gi3,…,giT]
(2)
公式(1)中,Xi:i+2是矩阵X第i行到第i+2行的情感特征向量,⊙代表卷积乘,b是偏置,f是非线性激活函数(本文选择ReLU作为激活函数来加快收敛速度).公式(2)中,vi由卷积层T个卷积核W分别在第i个单词周围提取的3-gram局部特征值组成.与情感词向量xi相比,本层输出的局部情感特征向量vi不仅包含第i个单词本身的特征,还融合了该单词相邻区域的上下文特征,包含的语义和情感信息更加全面准确、客观.
4.3 序列特征提取层
受限于固定大小的卷积核窗口,CNN难以对长距离的序列信息建模.为了能提取距离更长、隐藏更深的情感信息,本文将局部特征向量[v1,v2,…,vn]依次送入序列特征提取层.虽然标准RNN擅长处理序列数据,但却存在两个缺点:1)长序列训练中的梯度消失或爆炸问题使其对较远距离的重要节点信息感知能力下降;2)单向的状态信息传导使其无法获取后文对目标单词处的影响.因此本文采用双向LSTM(Bidirectional LSTM,BiLSTM)[14]提取序列特征,一方面借助LSTM中的门结构控制传输状态,进而限制过滤无效信息、记忆留存长距离情感特征,另一方面通过两个各自独立且方向相反的LSTM同时捕捉当前位置的上下文序列特征,进而全面地考虑每个位置过去和未来方向的情感和语义信息,推导与合并公式如下:
(3)
(4)

4.4 注意力层
大脑在阅读时总会对相对重要的元素分配更多注意力,进而提高获取关键信息的效率.本节的注意力层采用原理类似的Attention机制,在将信息融合且送入情感分类层之前,通过计算每个单词的情感权重,突出文本中包含关键特征的元素、弱化非情感信息或不重要元素,从而获取能够准确反映俄语文本中重要情感信息的注意力序列特征,提升模型的效果.许多研究中基于自注意力机制的深度学习模型[28],都直接采用LSTM的隐含层hi来生成不同元素的注意力权重值ai,计算方法如公式(5)所示.
si=tanh(WThi+b);ai=softmax(siA);
(5)
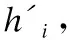

图3 注意力层的结构图Fig.3 Structure diagram of attention layer
(6)
4.5 句级特征编码层与情感分类层
与词级特征编码层功能和原理类似,句级特征编码层负责提取句级情感特征向量SF,该模块先从3.2节中选取l种预留的句级情感特征,再将其第j种句级特征(1≤j≤l)通过多项式扩展,转化成能够在深度模型中自学习的p维情感特征向量sfj,最后通过合并得到蕴含丰富情感信息的句级特征向量SF,计算公式为:SF=sf1⊕…⊕sfj⊕…⊕sfl,向量SF的维度等于p*l.

图4 情感分类层Fig.4 Emotion classification layer
5 实验与结果分析
5.1 实验数据与评价指标
本文实验采用数据集由Araujo[5]提供,共包含带有分类标签的俄语推文3968条,其中正向情感1145条,负向情感1188条,其余均被标记为中性.为提高分类准确性,本文对语料进行了预处理,并通过词干化将同根同源的单词映射为统一形式(例如:去除单复数,人称,阴阳性,名词格,动词多种时、态、体等的干扰).预处理后语料共剩余13943种单词或符号,其中12485种可映射到fastText提供的预训练词向量上,OOV比例由14.78%下降为10.46%.为使模型能够快速找到全局最优解,实验采用Mini-Batch梯度下降法训练模型,并使用5折交叉验证法检验最终模型的性能,同时将F1_macro作为主要评价标准、准确率作为辅助评价标准来平衡精确率和召回率之间的关系,两者在后文中分别简称为F1和Acc.
5.2 对比实验与结果分析
5.2.1 多种基于英译文的分类方案对比
因为目前俄语语料数量较少,且俄语情感分析工具能力有限,所以文献[5]结合翻译引擎与英语情感分析工具来获得分类结果,在其覆盖率Cov超过90%的实验方案中,Google翻译与Sentiment140(www.sentiment140.com)组合获得了最高的F1值61%.本文也对比了3.2.1节中设计的两种翻译引擎与两种分析工具相互组合的结果,基于Cov达到100%的前提,4种组合的F1范围为47.85%~53.64%,其中百度翻译与Vader[21]组合结果最好,如表3所示.实验发现,针对俄语语料[5],在使用同种英语分析工具的情况下,百度翻译的效果略好于Google翻译,这也证明翻译质量会对分析结果造成一定影响.
本文将Bert预训练模型提取的特征向量直接送入全连接层进行情感分类,发现Bert英语预训练模型的F1比多语言预训练模型高7.25.通过对比实验发现ACBM模型结果好于上述所有方案,这说明由于翻译导致的语义、情感、语言特征等方面的信息损失,基于英译文的情感分类效果不如直接对俄语原文进行分析,在机器翻译技术尚未取得进一步突破之前,建议将其作为临时性方案或迁移学习中的辅助性方案.
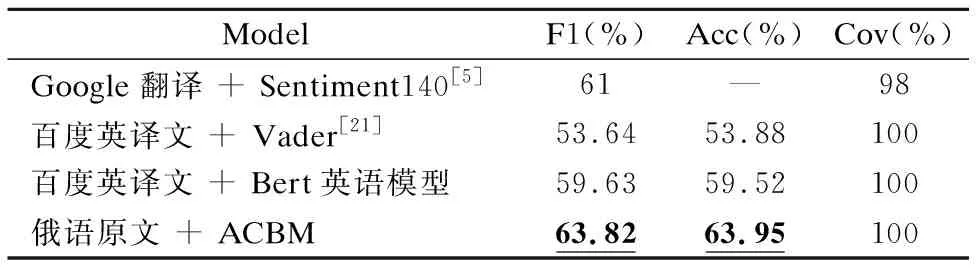
表3 对比各种英译情感特征的效果Table 3 Comparison of the effects of various emotion features in English translation
5.2.2 各种句级特征的对比
为了深入挖掘俄语推文中的情感信息,充分利用相关知识和语言特征,本文分别向模型LSTM和ACBM中逐个加入各种句级情感特征,同时对比这些特征与情感分类标签的3种相关性指数:Kendall,Pearson和Spearman,实验发现该指数的绝对值与加入对应特征后的实验结果之间存在比较明显的正相关,如表4所示.
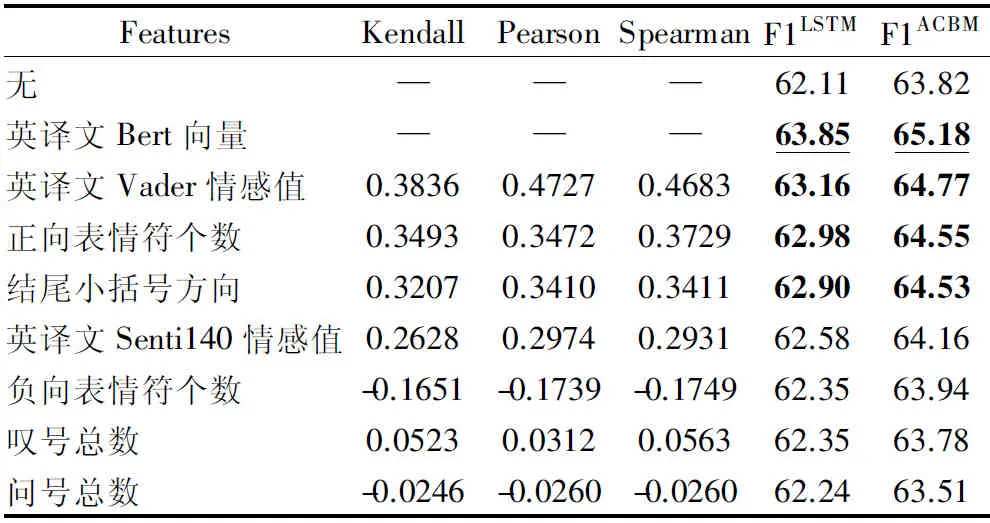
表4 各种句级特征的结果对比Table 4 Comparison of the results of various sentence-level features
在所选句级特征中,英译文Bert向量、英译文Vader情感值、正向表情符个数、结尾括号方向的效果最好,加入特征前后对比,LSTM的F1分别提高1.47%、1.05%、0.87%和0.79%,ACBM的F1分别提高1.36%、0.95%、0.73%、0.71%.相对而言,句级特征对LSTM的提升更明显,这说明ACBM针对原文的情感特征提取能力更强,故而句级特征对其辅助和补充的效果有限.两种英译情感特征的效果最好,说明单纯依靠英译文进行分析的效果虽然不够理想,但可将其作为俄语情感分析中有效的辅助手段.各类表情符也有相对不错的效果(结尾处的小括号也类似于表情符),这说明社交媒体语言喜欢通过鲜明的表情符来表达个人情感倾向.叹号和问号的效果不够理想,原因是这两种符号主要表达的是情感有无,却不包含情感的正负信息.
5.2.3 各种词级特征的对比
为研究各种词级特征对俄语情感分析的影响,本文实验还分别向模型LSTM和ACBM中逐个加入各种词级情感特征,如表5所示.这些特征中情感分数、脏话俚语、情感分数+词性效果最好,加入特征前后对比,LSTM的F1分别提高0.83%、1.31%和0.77%,ACBM的F1则分别提高0.97%、1.56%和1.57%.与句级特征相反,词级特征显然对ACBM的提升更为明显,这说明引入CNN模块和自注意力机制以后,ACBM对单词上下文情感特征和局部信息更敏感.此外,无论是否加入特征、或是加入何种特征,ACBM均比LSTM的F1值高1.46-2.51.值得注意的是,单独加入词性特征的效果相对较差,但若同时加入情感分数和词性特征,F1却比单独加入情感分数特征还高0.6%.这得益于ACBM的自注意力机制能有效地从词性特征中提取每个元素的权重,进而使模型更关注重要元素的情感分数特征.
为了验证俄语形态信息在情感分析中的作用,本文还向两种模型中依次加入各种俄语形态,如表1和表5所示.实验结果表明:有6种形态对原模型有提升作用,其中形态“式”和“人称”提升效果相对明显.这或许因为在俄语表述中,命令式比陈述式、第一人称比其他人称更倾向表达主观强烈的情感,而其余形态在俄语情感表达方面的作用相对不够明显.

表5 各种词级特征的结果对比Table 5 Comparison of the results of various word-level features
5.2.4 多种模型的结果对比
为了验证本文模型ACBM对俄语社交媒体文本的情感分析能力,表6将其与俄语情感分析工具Dostoevsky(4)https://github.com/bureaucratic-labs/dostoevsky、传统机器学习方法(SVM)、常见深度学习模型(CNN,LSTM,BiLSTM)、以及多种深度学习组合模型进行对比,实验共分两组:第1组直接对原文进行分析,未引入任何特征,对应实验结果为F1w/o-f和Accw/o-f;第2组同时加入若干词级特征(情感分数+词性+脏话俚语)和句级特征(表情符号+英译情感),对应实验结果为F1w-f和Accw-f.F1↑和Acc↑则表示除Dostoevsky之外,每个模型的第2组实验结果与第1组实验结果相比,对应的F1和Acc提高的幅度,其计算公式分别为F1↑=F1w-f-F1w/o-f和Acc↑=Accw-f-Accw/o-f.显然,F1↑和Acc↑越高,意味着对应的模型在加入各级情感特征之后,情感分类的效果提高地越明显.针对各模型说明如下:Dostoev-sky是基于RuSentiment[29]数据集训练得到的俄语情感分析深度模型,在其测试集上F1值为0.71;BiLSTM-2layers复现了文献[14]提出的两层堆叠双向LSTM;BiLSTM-ATT和BiLSTM-ATT2分别在BiLSTM基础上加入基于公式(5)和公式(6)的自注意力机制;BiLSTM-CNN是BiLSTM先于CNN的深度学习组合模型;CNN-BiLSTM是CNN先于BiLSTM的深度学习组合模型.
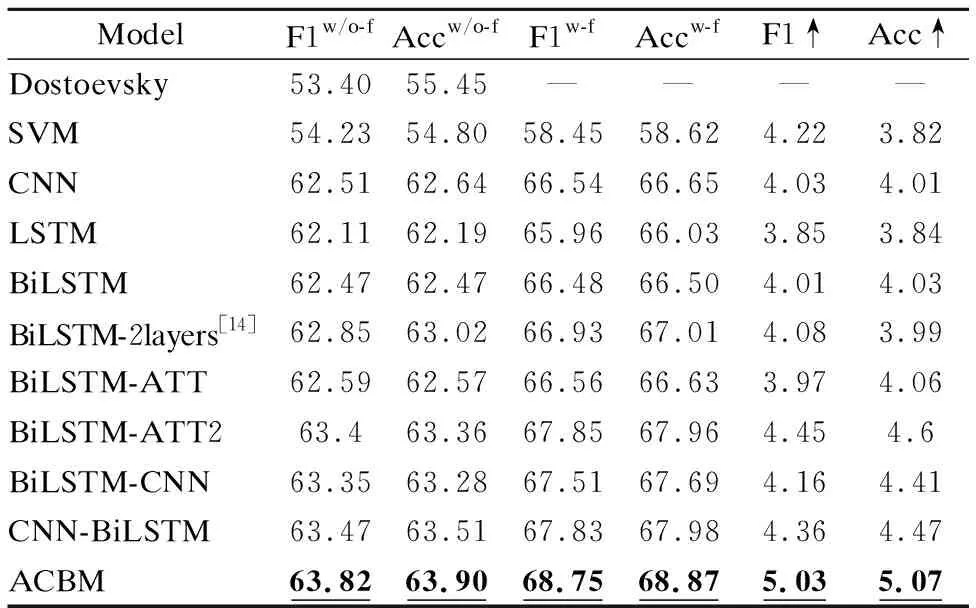
表6 不同方法分类结果对比Table 6 Comparison of classification results of different methods
对比实验的结果说明,引入各级情感特征后,所有模型的性能提升明显,其中ACBM提升效果最为突出,F1和Acc分别提高5.03和5.07.由于未在语料[5]上再次训练,Dostoevsky表现不佳,与未加入特征的SVM性能接近,而无论是否添加特征,所有深度模型均优于SVM.在加入各级特征后,CNN与BiLSTM效果差别不大,但二者结果均明显优于LSTM,这证明了CNN高效提取文本局部特征的能力与BiLSTM捕捉序列历史前后特征的敏感性.如果对BiLSTM添加模型层数、或添加基于公式(5)、公式(6)的自注意力模块,F1会分别提升0.51、0.13和1.46,这证明增加网络层数或自注意力模块能有效提升BiLSTM的性能,且改进后的自注意力机制更有效.CNN-BiLSTM效果略强于BiLSTM-CNN,说明针对俄语推文先用CNN提取局部特征、再通过BiLSTM提取全局序列特征的方案更为合理.无论是否加入特征,本文的ABCM效果均好于所有模型,这说明通过优化组合CNN与BiLSTM,同时辅以分工明确的自注意力机制,能更细致地捕捉局部特征、汇总全局信息和提升情感分析效果.
5.3 注意力分析
ACBM模型能够基于自注意力机制和文本的各种多级情感特征,为重要元素赋予更高的情感权重,进而提升对情感信息的提取和分析能力,图5展示了ACBM为不同Token生成权重值对应的热力图.例如:无论是类似:":D"和":("的正向或负向表情符,还是诸如"веселый"(愉快的)、"люблю"(喜欢)、"молодец"(好样的)、"грубая"(粗野的)、"злая"(邪恶的)、"тратьте"(白费)、"фигню'(废话)和"плачут"(哭泣)等具有明显情感倾向的实词,都被赋予较高的情感权重.而类似"Я"(我)、"того"(这个)、"и"(和)、"что"(什么)、"у"(在)、"на"(上)等与情感关系不大的代词、连词、介词和标点符号情感权重都很低.例句1-5中,最高权重是其余权重均值的3.1-5.7倍.例句6和7中,最高的两个权重均值是其余权重均值的10.9倍和15.3倍.分析例句8还可发现,当句子中出现多个极性相反的表情符时,ACBM会依据文本含义和各Token所处位置,为相对重要的表情符":("赋予更高的权重值.

图5 ACBM自注意力层生成的Token权重热力图Fig.5 Token weight thermograph generated by the attention layer of ACBM
6 结 语
本文在融合俚语、俄语形态、情感分数和词性等词级特征,以及表情符号和英译情感值等句级特征的基础上,构建基于自注意力机制的深度学习模型,在俄语推文情感分析方面取得了较好的结果.研究表明虽然直接分析英译文的效果不够理想,但可将其作为深度学习模型重要的辅助手段;融合多级特征有利于提升各类模型效果,其中句级特征对于简单模型效果提升更明显,词级特征对于复杂模型效果提升更明显;与单一的深度模型和常见的组合深度模型相比,在融合CNN和LSTM等模型优点并辅以改进的自注意机制之后,本文设计的ACBM能够针对俄语社交媒体文本的特点,明显提升对其情感分类的结果.
本文工作仍有如下不足和改进空间:限于俄语语料库的有限性,对比实验仅在俄语推文语料库[5]进行,如何构建规模更大,类型更丰富的俄语情感语料库是下阶段的研究重点;在融合字母、标点和部分形态特征后,模型未能取得预期效果,如何更合理的将这些特征融入到深度学习模型中,探究这些特征在不同语料上的作用,也值得进一步研究.
