中文短文本自动关键词提取的改进RAKE算法
2021-05-24陈可嘉黄思翌
陈可嘉,黄思翌
(福州大学 经济与管理学院,福州 350108)
E-mail:kjchen@fzu.edu.cn
1 引 言
互联网快速发展的背景下,微博等短文本数量增长.人们期望快速、准确地掌握短文本的核心内容以便形成对文本的大致判断.关键词是表达一段文本核心内容的最小单元[1],提取关键词能快速地掌握一篇文本的主题.高效、准确、快速地提取关键词,有助于满足人们对信息质量的核心要求.提高关键词自动提取的效果是当前研究的一个重要课题.
主流的文本关键词提取分为有监督提取和无监督提取[2].有监督的关键词提取技术需要事先标注语料,利用模型训练语料,预处理代价较高[3].因此,本文主要讨论无监督的关键词提取方法.无监督式的关键词提取算法又称为自动关键词提取算法,自动地从文本中提取出具有代表性的词或者短语,方便概括文本的主题.传统的自动关键词提取有3种:1)基于主题的方法.基于主题的关键词提取方法从文章的全局出发,该方法认为文章都是由主题和与主题相关的词或短语组成,具有代表性的方法为LDA[4];2)基于词图方法.该种方法通过一定的算法描述词语间的关系并以此来判断词语在文本中的重要程度,例如TextRank[5];3)基于统计的方法.该方法通过计算词语的统计学特征从候选词中选出几个较为重要的词作为关键词,具有代表性的方法为TF-IDF[6].此外,一些研究将这些方法融合取得了较好的成果,如刘啸剑等融合图和LDA主题模型,先用LDA计算词语之间的相似性,以此为权重构建无向图[7].
目前,无监督式的短文本关键词提取算法大都采用上述无监督式关键词提取的3种算法.例如,Kim等利用n-gram LDA,通过分析推特文本,挖掘用户对埃博拉病毒的情绪[8].也有一些学者将这些方法相结合,例如Tu和Huang将TextRank与TF-IDF结合,先通过计算微博的每个词的TF-IDF值,再利用该值作为TextRank的权重提取关键词[9].但这些方法都在固定的短文本语料进行建模[10],关键词提取效果受语料库的量级与质量影响,通常需要较大规模、高质量的语料训练.然而短文本实时性较强、数据更新快、表达随意,且具有稀疏性、不平衡的特点[11],传统的短文本自动关键词提取算法灵活性与适应性较弱,不能较好地抽取短文本关键词.
快速自动关键词提取算法——RAKE算法在英文短文本提取上有较为优异的表现,在单一的短文本中即可提取关键词[12].该算法的核心思想是通过英文的空格进行英文的分词,再通过构建共现矩阵提取关键词短语,并且倾向于较长的英文单词.该方法简单高效,无需大量的语料库支持,可提取出文本关键短语.Haque将RAKE算法应用于孟加拉语[13];Siddiqi和Sharan根据印地语的特征,提出了SD-RAKE方法,有效地将RAKE算法应用于印地语文本的关键词提取中[14].但该算法以统计学为基础,仅以共现频率计算某词的特征值,而中文词语之间的关系较为复杂,句式繁多,若该方法应用于中文短文本关键词提取中,则易忽略了词语之间语义的关系.此外,由于中文中存在较多的歧义词,句子较长,词与词之间不是通过空格分割,而RAKE算法仅以停用词和空格进行分词,若某词未在停用词表中出现则判定为有用词,RAKE算法的分词效果不佳,因此将RAKE算法应用在中文短文本中容易出现提取出的关键词组过长的问题.
针对RAKE算法在中文短文本关键词提取方面的不足,本文基于RAKE算法提出了新的短文本关键词提取方法.本文方法首先根据词语间距与句法关系频次、语境权重计算每个词的特征值,若短语过长,则采用窗口输出方法使短语按语法规则输出.
综上所述,本文方法不仅不受语料库量级的影响,也可以较好地解决RAKE算法未考虑词语语义的问题,可控制中文关键词的长度,短文本关键词提取效果较其它的关键词提取算法更优.
2 RAKE算法
RAKE算法共5个步骤,其流程如图1所示.
该算法首先对句子进行分词,分词后去除停用词,根据停用词划分短语;之后计算每一个词在短语的共现词数,并构建词共现矩阵;共现矩阵的每一列的值即为该词的度deg,每个词在文本中出现的次数即为频率freq,得分score为度deg与频率freq的商,deg越大,则该词更重要;最后按照得分的大小值降序输出该词所在的短语.
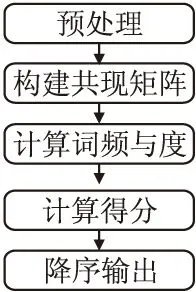
图1 RAKE算法流程Fig.1 Process of RAKE
例如“系统有声音,但系统托盘的音量小喇叭图标不见了”,经过分词、去除停用词处理后得到的词集Wt={系统,声音,托盘,音量,小喇叭,图标,不见},短语集DP={系统,声音,系统托盘,音量小喇叭图标不见},词共现矩阵如表1.

表1 RAKE算法共现矩阵Table1 RAKE algorithm co-occurrence matrix
每一个词的度为deg={“系统”:2 ,“声音”:1,“托盘”:1;“音量”:3;“小喇叭”:3,“图标”:3,“不见”:3},频率freq={“系统”:2,“声音”:1,“托盘”:1;“音量”:1;“小喇叭”:1,“图标”:1,“不见”:1},score={“系统”:1,“声音”:1,“托盘”:1;“音量”:1;“小喇叭”:3,“图标”:3,“不见”:3},输出结果为{音量小喇叭图标不见了,系统托盘,系统,声音}.
3 改进的RAKE算法
本文根据RAKE算法的核心思想,对RAKE算法的文本预处理、共现矩阵构造以及过长关键词过滤进行改进.此方法包含预处理、候选关键词提取、窗口输出3大部分,算法流程如图2所示.
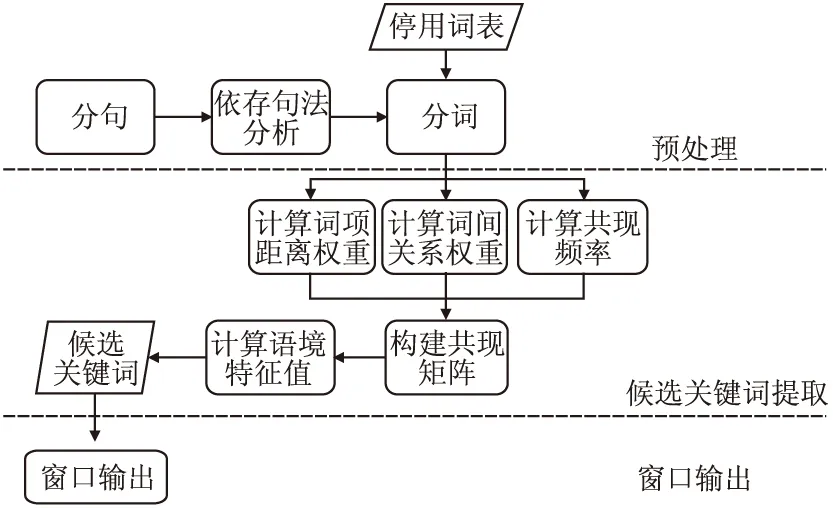
图2 改进RAKE算法流程Fig.2 Process of improved RAKE
3.1 预处理
预处理共包含3步.
第1步.对于给定的短文本Dt,根据标点符号对短文本进行分句,得到分句集Ds;
第2步.利用依存句法分析工具对Ds进行依存句法分析,得每两词之间的依存句法关系集Dr;
第3步.将Ds的每个子集进行分词,引入停用词表,删除词表内的单词去重后得词集Dw.
3.2 候选关键词提取
候选关键词的提取通过计算词间关系权重,并以计算后的权重为依据构建共现矩阵,计算每个词的度,最后计算每个词的语境特征值,降序输出该候选关键词.
3.2.1 改进的度计算公式
RAKE算法以两词在短语中的共现次数描述词语间的关系,本文认为词语之间的关系除去共现关系之外,还与两词之间的距离和词语之间的句法关系有关.为此,本文引入词项距离公式与词间关系权重公式改变词ti与词tj间度degij的计算方法.
1)词项距离公式
词项间的距离能一定程度地反映出两个词项之间的关系,词项距离越远表示词项与词项之间的联系越不密切.参考文献[15]给出词项距离公式(1).
cords(ti,tj)=e-distds(ti,tj),ti∈ds且tj∈ds
(1)
distds(ti,tj)为词项ti和tj在分句去除停用词后的短句ds中的距离,计算为公式为|j-i|(j>i),即词ti和词tj之间间隔的词数.例如“但系统托盘的音量小喇叭图标不见了”,经过3.1节预处理后得到ds={系统托盘,音量小喇叭图标不见},则“音量”与“图标”之间的距离为2.
2)词间关系权重
词项间的关系不仅需要考虑词项间的距离关系,更需要考虑词项间的语义关系.句法关系可以一定程度反映词项间的语义关系,为体现词项间的语义相关度,参考文献[16]给出词项间的句法权重公式(2).
(2)
参考文献[16]认为两词之间的句法权重与句法分析发生频次与两词项间的距离有关,但由于本文方法经过分句处理,句子较短,两词项之间发生多次句法关系的概率较小,因此,在公式(2)的基础上本文给出改进的句法关系公式(3).

(3)
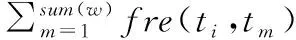
3)共现频率
共现频率表示关键词在短语内的共同出现的频率,用f表示.例如“新型物理方法研究物理”,则“物理”与“研究”的共现次数为2.综合公式(1)、公式(3)和共现频率f的定义,给出词i与词j的共现度degij,如公式(4)所示.
(4)
当词语出现在同一个短语内时,则两词的权重为ti和tj的词项距离、词间关系权重与共现次数f之和;若两词项在同一句子内,但不在同一短语内,则为词项距离权重;若不在一个句子内,度为0.
3.2.2 构建共现矩阵
词共现矩阵是词共现模型的量化,词共现矩阵可以直观地表示两个词之间共同出现的频率[17].而本文所构建的词共现矩阵基于3.2.1节计算得出的两词间度degij,计算每一个词的总的度degi,算法描述如下.
第1步.接收预处理后的分句集Ds和依存句法关系集合Dr、分句集Ds、词集Dw.
第2步.根据词集Dw中词的个数构建共现矩阵,将矩阵的所有值设成0.
第3步.遍历分句集Ds,计算分句集中每一个词出现的概率,对角线的权重即为词ti在Ds中出现的次数.
第4步.计算词ti与tj所有分句集Ds中出现的次频率f.
第5步.计算词ti与tj所有词在Ds中的每一个元素ds中的距离,计算词项距离权重cords(i,j).
第6步.计算词ti、ti与tj在句法关系集合Dr中出现的次数count2和count3,计算两词在Ps中的每一个元素的距离distPSm(i,j),计算cords(i,j).
第7步.根据公式(4)计算degij.
第8步.重复第4步计算下一个词与该词的度degi.
第9步.每一行遍历完进行列相加操作,直至遍历完每一行.
3.2.3 计算语境特征值
依据特征值的大小判断某词语否为关键词,特征值越大,则为关键词的概率更大.本文通过计算每一个词在短语中的语境信息熵计算该词的特征值.
1)语境
语境是表示一句话所表示的外部环境特征,包括上下文、时间、空间、情景等.语境在一段文本中,可以是一句话,也可以是一个句法关系、一个短语.本文的语境是一个短语,而语境中的核心词是文本的关键词.
2)语境特征值
参考文献[18]提出的语境模型包含背景、参与者、交际行为及其它行为,认为语境的本质是一个树结构偶,语境中的核心词是独立的,其它词依附于核心词,核心词包含了最多的信息.基于此观点,参考文献[18]中语境熵值的计算方法,提出一种基于短文本的语境核心词算法计算每个词的语境特征值.首先,根据公式(5)计算每一个词在短句中的信息比重;再次,利用公式(6)求出每个词在文章中的平均语境特征值,度越大,其中degi为3.2.2节提出的每个词ti总的度,freqi为词ti在短语中出现的频率,则包含的语境信息越多.按照语境特征值的大小对候选词进行降序排序,形成词集Dw.之后,按序输出Dw每一个词所在的短语,形成短语集Dp.
(5)
H(wordi)=Fwilog(Fwi)
(6)
3.3 窗口输出
由于RAKE算法输出的短文本关键词过长,本文采用设置窗口的方法控制输出的关键词短语的长度,算法描述如下.
第1步.输入词集Dw与短语集Dp.
第2步.对词集Dw中的每一个词进行词性判定.
第3步.遍历词集Dw中的每一个词.对于词集Dw中的名词wordi:
1.在短语集Dp中按照窗口n的大小遍历每一个短语.
2.若窗口内包含词wordi,则该短语为候选关键短语.
3.计算每一个候选关键短语在Dp中出现的词数Count.
4.Count最大的即为wordi所对应的关键词keywordi.
第4步.keywordi中若包含多个名词,则在Dw中删除keywordi中包含的名词.
第5步.逐一输出关键短语集.
4 实验设计与结果
4.1 数据集介绍
本文实验在中文数据集中测试.学术文献摘要作为重要的短文本类别,表达形式更为规范,故本文在知网知识检索(1)http://search.cnki.net输入“计算机”、“医学”、“物理”、“数学”、“文学”、“英语”作为关键词,收集检索结果前1500页学术期刊的相关文献摘要与关键词,去重以及删除空文献资源后共得到11128篇期刊摘要和45907个关键词,摘要的平均字数在200字内,每篇文章设置的关键词为标注关键词,平均每篇数据集的标注关键词为4.1253个词或短语.数据集描述见表2.因本方法需引入中文停用词,本文融合哈工大停用词表、百度停用词表、四川大学机器智能实验室停用词库,去重后应用于文本预处理中.

表2 数据集Table 2 Dataset
4.2 评价指标
本部分采用准确率P、召回率R和F1值对改进的RAKE算法进行性能评估,公式描述如公式(7)-公式(9):
(7)
(8)
(9)
sumright为均在人工提取集和算法提取集中词的总数,summanual为人工提取关键词的总数,sumextract为算法提取关键词的总数,F1为P与R的调和平均值.算法在不同文章中提取出的关键词的个数不同,因此,本文使用F1值作为主要的评价指标.
4.3 参数确定
3.3节窗口输出算法中涉及关键词词长n的判断,由于词长的确定影响算法的性能,因此需先确定最优参数.
图3为在数据集中不同的词长n中F1值的变化情况.可以看出,当n设置为2时,本文方法的F1值达到最高,为19.04%.受分词的效果的影响,在n=5时,F1值略大于n=4时的取值.

图3 n不同取值时的F1值Fig.3 F1 at different values of n
为验证在不同类型短文中n的最优取值使F1值达最高,本文在数据集中不同类别的子数据集中进行实验,实验结果如图4所示.由图4可知,在不同的 数据集中,虽n=1与n=2时F1值的变化不大,n=2时,4个子数据集中F1值最高.同时也说明本文方法在不同的数据集中的效果均无太大差异,具有普适性.

图4 子集中n取不同值时的F1值Fig.4 F1 for different values of n in the subset
4.4 对比实验
为测试本文方法在短文本关键词提取方面的性能,本部分实验首先与基础RAKE算法进行对比:首先验证本文两处改进对RAKE算法的性能提升,进行纵向对比;之后再将本文方法与不同的关键词提取方法进行对比,进行横向对比.
4.4.1 改进性能测评
为验证本文两处对于RAKE算法改进的合理性,本次实验首先测试原始RAKE算法在数据集中的效果;其次测试改进度计算公式后的RAKE算法,即3.2节所述方法的效果;最后测试既改进度计算公式又增加窗口过滤算法后的RAKE算法的结果,实验结果如表3.可知,中文 RAKE算法的提取效果不好,但改进共现矩阵后的RAKE召回率明显提升,这是因为提取的关键词正确度提高,但P值较小的原因是提取的中文关键词结果较多.当加入窗口输出算法后,因符合关键词短语语言特征,算法的召回率有较大的提升,同时准确率也有所提升.
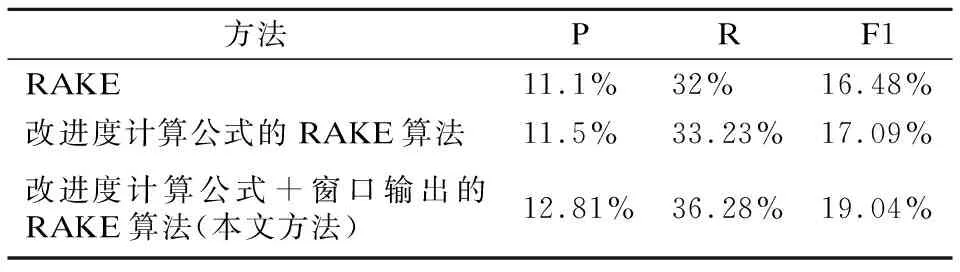
表3 改进RAKE算法的效果Table 3 Effect of the improved RAKE
4.4.2 不同方法对比
自动关键词提取算法有两种典型代表,第1种是基于统计的关键词提取方法TF-IDF,第2种是基于图的关键词提取方法TextRank,本文方法与TF-IDF、TextRank算法和原始的RAKE算法进行对比.
表4为在中文语料库下,当候选关键词长度n设置为2时,本文方法与其它方法P值、R值与F1值的对比结果.较其它方法,准确率P提升了1.55%-8.36%,召回率R提升了4.28%-16.38%,F1值提升了2.56%-11.78%.可见本方法在中文短文本关键词提取的效果优于其它方法.

表4 不同关键词提取算法结果Table 4 Result of different keyword extraction algorithms
本文方法在考虑词间关系与输出长度规则后,对于短文本的提升效果较好.原因在于两点:1)词语之间存在着依存关系,而其它3种方法并未考虑到词语间的依存句法关系;2)现在中文短文本的关键词通常是以短语形式存在的,而RAKE算法输出过长,TF-IDF和TextRank输出的关键词却为单个词语.
5 结 语
本文针对RAKE算法在中文短文本关键词提取中未考虑词间语义关系及关键词过长的特点,提出一种改进的RAKE关键词提取方法提高关键词提取效果.本文方法结合RAKE算法的基本思想,利用词项距离公式、词间关系权重公式、共现频率公式量化每一词项间的关系,后计算语境信息熵得出候选关键词,若候选关键词词长过长,则根据窗口输出算法输出短语.在中文学术摘要短文本数据集中的实验表明,本文方法对中文短文本关键词提取是可行和有效的,提取效果较好.
本文需构建共现矩阵,时间复杂度较高,容易造成数据维度较大的情况.因此,本文的下一步工作是降低时间复杂度,使算法更加的高效.
