面向虚拟化云数据中心的工作流联合调度算法研究
2021-05-24董明刚闭玉申
董明刚,范 培,闭玉申,敬 超,3
1(桂林理工大学 信息科学与工程学院,广西 桂林 541004)2(嵌入式技术与智能系统重点实验室,广西 桂林 541004)3(可信软件重点实验室,广西 桂林 541004)
E-mail:jingchao@glut.edu.cn
1 引 言
虚拟化技术是云数据中心的核心技术之一,良好的资源及调度方法有利于云数据中心的虚拟资源管理从而提供快速、安全和可靠的服务.随着云计算技术的不断成熟和进步,基于该技术的数据中心也随之发展,其中虚拟化技术是数据中心的关键技术之一,它能够对现有的资源进行整合,提高服务器与存储的利用率,让用户对新硬件设备的增长需求速度放缓,进而提高资源的利用率[1-3].由此可见,设计合理的方法对虚拟化资源进行管理有着重要的意义.
传统的虚拟化资源管理主要是针对虚拟机部署的性能优化问题[4],它主要包括将工作流分配到虚拟机,优化虚拟机部署后工作流的时延问题[5].还有的研究只是关注了数据中心的资源利用率和高能耗问题,如刘宁等人[6]提出了一种新颖的分层框架,通过强化学习进行虚拟机资源分配和有效的动态电源管理策略解决资源调度过程中高功耗的问题,但是这种方法忽略了数据中心费用优化问题.
针对这一问题,Tong等人[7]提出一种基于强化学习的云工作流调度算法,用Q-learning算法对任务进行预处理,获得更加合理的任务序列,对任务进行分配时,使用线性加权法有效的将工作流分配给合适的虚拟机,完成了优化工作流的完成时间和用户的费用,达到了同时优化多目标的问题.Cheng等人[8]提出一种降低资源成本的算法,主要通过深度强化学习算法,从不断变化的环境中学习进而自动生成一个长期决策,使得在保持能源效益的同时运行时间极大的缩短,节省开销.范利利等人[9]为了提高异构云计算系统的处理效率,减少费用开销,在考虑了云环境的异构性、任务的截止时间、传输开销的情况下,提出一种基于自学习策略和近邻启发机制的粒子群任务调度算法,能够有效缩短工作流执行时间,减少开销.
纵观这些研究可以发现目前虚拟机部署问题,主要关注的是以优化费用为目的[10,11],解决工作流到虚拟机的映射问题,而没有考虑映射完成后虚拟机到物理机的调度问题,即工作流联合调度问题.这是因为相比于传统的虚拟机部署问题,联合调度问题更加复杂,因为它涉及到了工作流,虚拟机以及物理机三者的资源协调问题.虽然Guo等人[12]做了联合调度的研究,但是他们主要是利用影子算法指导实际的应用程序到虚拟机到物理机上的分配,提出了在云上的应用程序-虚拟机-物理机在线联合调度算法,并没有进一步考虑到资源调度过程中产生的费用开销优化问题.
鉴于联合调度过程中涉及的资源协调以及成本开销优化等问题,因此,本文的主要工作是以费用最小化为目的,在保证工作流执行效率的前提下,提出了一种以蚁群系统和贪心算法为核心思想的联合调度方法(A joint workflow scheduling algorithm based on improved Ant-colony system and greed algorithm,IAG).与以往的研究相比,该方法不仅考虑了在虚拟化云数据中心的工作流-虚拟机-物理机的联合调度问题,而且还考虑了虚拟机多类型的问题,即同类型虚拟机在部署到同一台物理机时可以免去部署开销(如时间)[13].
本文的工作主要是:首先,通过建立工作流、虚拟机、物理机以及云数据中心的费用模型,对虚拟化云数据中心工作流联合调度问题进行了形式化的描述;接着,针对提出的优化问题,提出了一种二阶段的工作流联合调度算法(IAG).该算法主要分为两步:
1)解决了工作流到虚拟机的映射问题,以缩短工作流执行时间最小化为目的,提出了一种基于蚁群系统思想的算法;
2)利用贪心算法,考虑虚拟机的多类型问题,在保证工作流完成时间的前提下,以费用支出最小化为目的,将虚拟机调度到物理机.
最后,将提出的IAG算法与传统调度FCFS算法、PSO算法以及IPSO算法[14]进行对比实验分析.实验结果表明:IAG联合调度算法不仅可以保证工作流的执行效率,还降低了费用开销,体现了它的可行性及有效性.
2 问题建模
2.1 云数据中心调度模型
该模型展示了云数据中心在处理用户提交的工作流时所经历的过程.首先用户在线提交工作流到云数据中心,所有的工作流都会被缓存到工作流队列中,通过调度器将工作流调度到数据中心生成的虚拟机中处理,并且随后虚拟机会被以开销最小化为目的部署到相应的物理服务器上,如图1所示.

图1 云数据中心处理工作流示意图Fig.1 Schematic diagram of cloud data center processing workflow
2.2 工作流模型
对于每一种类型的工作流,都有截止时间Dk,将工作流的模型描述为一个有向无环图G=(ν,ε),工作流中的任务集用ν={υ0,υ1,…,υ|Q(k)|-1}表示,表示|Q(k)|工作流K中的总任务数量.其中K∈[0,H(t)-1],H(t)表示工作流的总数量.ε表示任务之间的依赖关系,由于任务Tp和它的子任务Tq的依赖关系,定义为W(Tp,Tq).任务Tq只有在执行完任务Tp后才能进行.Tlength_i表示任务υi的数据量大小.工作流模型如图2所示.

图2 工作流模型Fig.2 Workflow model
2.3 云数据中心虚拟机模型
假设云数据中心里虚拟机的数量为N,用V={V1,V2,…,VN}表示.每个虚拟机资源需求为CPU、内存、带宽,分别用Vcj,Vmj,Vbwj,j∈N表示.每个虚拟机在部署到物理机时会产生的开销表示为PmC,若虚拟机由NT种类型组成,则两个同类型的虚拟机部署到同一物理机时,在资源充足的情况下可以避免部署的开销.虚拟机的处理能力如公式(1)所示:
VMcomp_j=mips×pes
(1)
任务的传输时间暂且不考虑在内,任务在虚拟机上的执行时间如公式(2)所示:
(2)
每个任务在虚拟机上的执行时间就是它的完成时间:
TRTimeij=etij
每个工作流的完成时间:
(3)
虚拟机上前r个工作流执行时间:
(4)
由于虚拟机并行执行的工作特性,工作流最终完成时间是最后一台虚拟机执行完工作流的时间,如公式(5)所示:
WFFTime=max(vmcomptime_j),j∈[1,n]
(5)
2.4 云数据中心物理机模型
假设云数据中心中物理机的数量为M表示为P={1,2,3…M},每个物理机的资源需求为CPU、内存、带宽,分别用Pci,Pmi,Pbwi,i∈P表示,其中物理机中的资源要满足虚拟机中资源的需求.调度策略中的物理机资源需要满足条件如下:其中X表示邻接矩阵,若VMj放置在物理机Pi上,则Xij等于1,否则Xij等于0.
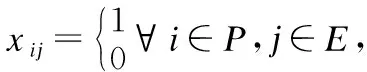
(6)
其中yi表示物理机数量.
(6a)
(6b)
(6c)
(6d)
2.5 云数据中心成本开销模型
2.5.1 时间约束
时间约束分为两部分:第1部分为工作流的执行时间,第2部分为物理机的部署资源时间.其中物理机部署资源的启动、结束时间分别为Tstart、Toff.每个虚拟机部署资源的时间集合为:PT={T1,T2,T3…}.
其中工作流执行时间约束函数如公式(7)所示:
(7)
WFFTimemax、WFFTimemin分别表示任务在处理能力最差、最好的虚拟机上的执行时间.即Time_1=T_Time(I).物理机上部署资源时间如公式(8)所示:
Time_2=Tstart+T1+T2+…+Toff
(8)
物理机部署资源时,利用贪心算法先对需求资源大的虚拟机进行资源部署,当后续到达虚拟机与前一个虚拟机类型相同且所需资源小于前一个虚拟机时,则不需要重新为其部署资源,节省了部署虚拟机的开销,同时能够尽可能将资源类型相同的虚拟机优先部署到同一台物理机上.其中物理机启动时间如公式(9)所示:
Tstart(i)=lnPmi
(9)
将Toff设置为启动时间的一半.联合调度的总时间如公式(10)所示:
f(t)=Time_1+Time_2
(10)
2.5.2 成本开销问题
不同类型的虚拟机所需的单位费用与它的CPU、内存、带宽资源相关,记为Vcostj.当所有工作流执行完成后,虚拟机所需费用如公式(11)所示:
(11)
物理机的单位费用同样与其CPU、内存、带宽资源相关,记为Pcosti,物理机的所需的费用开销如公式(12)所示:
(12)
其中Tstart>0,Toff>0,联合调度的总费用表示为:
F(c)=TC+PmC
(13)
2.6 问题定义
本文主要工作是以费用最小化为目的,在保证工作流执行效率的前提下,将虚拟机在物理机上进行资源部署,从而达到了对资源的整体联合调度.优化目标如公式(14)所示:
minsizeF(c)=TC+PmC
(14)
s.t.f(t)≤T
(14a)
3 算法设计
3.1 算法基本思想
一方面,针对工作流-虚拟机的映射问题,在基于蚁群系统的基本思想上,对工作流执行时间和开销成本建立相关函数,缩短了工作流调度时的任务完成时间.另一方面,针对虚拟机-物理机的部署问题,利用贪心算法将多类型的虚拟机部署到物理机上,若同类型的虚拟机部署到同一个物理机上时可以免去部署开销.通过对这两层的资源调度进行优化,即节省了时间,又缩减了整体的费用开销.
3.2 算法设计细节
3.2.1 初始化相关参数
对蚁群系统中的启发函数、信息素、和信息素转移规则进行初始化.
(15)
τ0表示任务到虚拟机路径上信息素的初始化值.其中VMavg_comp表示虚拟机的平均计算能力,如公式(16)所示:
(16)
(17)
ηij是启发函数,表示任务υi在虚拟机VMj上的执行期望强度.其中,LFj是虚拟机负载函数[15],如公式(18)所示:
LFj=1-((Ej-Eavg)/∑j∈VMEj)
(18)
etij表示任务υi在虚拟机VMj上的执行时间.Ej是虚拟机j的执行时间,Eavg是所有虚拟机的执行时间的平均时间.若先不考虑信息素调整因子,任务的执行时间越长,则ηij越大.
3.2.2 虚拟机节点选择
蚂蚁在选择下一个虚拟机节点时,采用了蚁群系统的随机转移概率规则[16];
(19)
(20)
其中q为[0,1]之间的随机数,q0为固定参数,α为信息素的启发因子,β为期望启发因子,allowedk是蚂蚁可以为任务选择的虚拟机集合.τij(t)表示t时刻时,任务υi与虚拟机VMj的映射路径上的信息素的值.
3.2.3 动态信息素更新
当蚂蚁为所有任务进行分配后,对其映射路径上的局部信息素进行更新:
a)局部信息素更新规则
τij(t+1)=(1-ρ)τij(t)+ρΔτij(t)
(21)
公式(21)中ρ表示信息素挥发因子,(1-ρ)表示信息素的残留度,ρ的值范围是(0,1],若ρ越大,则表示信息素挥发的越快,残留度越小.Δτij(t)是在t时刻时,任务υi与虚拟机VMj的映射路径上的信息素增量.
(22)
其中D为蚂蚁完成一轮寻解后的时间与成本函数值,表达式为D=ι1Time_1+ι2TC,ι1、ι2分别为时间函数和成本函数的权重因子,取值范围是[0,1].Uk(t)表示第k只蚂蚁在第t次的迭代寻解.
b)全局信息素更新规则
当所有蚂蚁完成一轮迭代寻解后,得到本次迭代寻解的最佳方案,然后将局部最佳的信息素设置为全局信息素.
(23)
其中Dbest为蚂蚁到目前迭代寻解中的最优解.
3.2.4 算法及时间复杂度分析
在算法1中,首先初始化所需的各项参数(行1-3),为任务匹配最佳的虚拟机并更新局部信息素(行4-10),更新全局信息素,并获得最佳匹配方案(行11-17).
在算法2中,首先将所需资源最大的虚拟机优先部署到物理机上(行1-3),将后续到达的虚拟机与前一个虚拟机进行类型与资源比较,并为其部署资源(行4-12).
算法1.
输入:工作流中的任务总数TASK_NUM,虚拟机数量,物理机数量,蚂蚁数量ANT_NUM,迭代次数I_NUM,挥发因子,启发因子α,启发因子β,伪随机状态转移参数q0.
输出:工作流与虚拟机匹配方案
1.Begin
2. 初始化虚拟机计算能力,虚拟机计算费用,期望执行时间,全局
3. 信息素,蚂蚁列表,全局匹配方案.
4. ForD=1 toI_NUM
5. ForN=1 toANT_NUM
6. ForT=1 toTASK_NUM
7. 蚂蚁根据伪随机状态转移公式,选择最合适的虚拟机.
8.
9. End
10. 更新局部信息素.
11. End
12. 计算并选择最佳的蚂蚁.
13. 用最佳蚂蚁的局部信息素,来更新全局信息素.
14. 选择最佳蚂蚁的匹配方案,来更新全局匹配方案.
15. 初始化蚂蚁列表.
16. End
17.End
输出结果:工作流与虚拟机匹配方案
算法2.
输入:虚拟机数量VM_NUM,虚拟机类型Type,虚拟机内存RAM,物理机现存资源数据
输出:虚拟机与物理机部署方案
1.Begin
2. Fori=1 toVM_NUM
3. 找出现有资源最大的物理机.
4. 获取物理机上最新部署的虚拟机VM_i的类型Type_i,所
5. 需内存大小RAM_i.
6. IfType_i+1不等于Type_i或RAM_i+1大于RAM_i
7. 在该物理机上重新为VM_i+1部署资源.
8. Else
9. 将VM_i+1直接放置到该物理机上.
10. End
11. End
12.End
输出结果:虚拟机与物理机部署方案
假设工作流中的任务数量为T,虚拟机数量为S,且任务的数量T大于虚拟机资源的数量S(T>S),迭代次数为R,蚂蚁数量为N.本文提出的IAG算法的时间复杂度主要分为两部分:1)利用改进的蚁群系统算法解决工作流到虚拟机上的映射问题,即算法1的时间复杂度为O(R·T·N).2)将贪心算法应用到虚拟机到物理机的部署问题上,即算法2的时间复杂度为O(S).
4 实验模拟
4.1 实验设置以及算法参数设置
本文在Cloudsim-3.0.3云计算仿真平台进行仿真实验,验证提出算法的有效性.

表1 实验参数配置Table 1 Experimental parameter configuration
测试中的参数配置如表1所示.本文采用CyberShake、Montage、LIGO、SIPHT等数据集上任务数量为100,200的2组任务进行实验,迭代100次后得出最佳结果,并与FCFS算法、PSO算法、IPSO算法对比,为确保实验结果的有效性,每种算法进行独立实验10次,取其平均值,对比结果如图3所示.

图3 不同任务大小下的实验结果Fig.3 Experimental results under different task sizes
算法1中涉及到一些参数设置,具体如下:α=0.5,β=0.5,ρ=0.2,q0=0.2蚂蚁数量ANT_NUM=20,最大迭代次数为I_NUM=100.
4.2 实验结果分析
由图3可以看出,在不同大小的任务下,IAG算法与IPSO算法、PSO算法、FCFS算法相比较,在联合调度的资源开销方面均有明显的优势.由图3(a)、图3(b)可以看出,当任务数量为100和200时,在数据集CyberShake、Montage、LIGO、SIPHT上,IAG算法在费用这一指标上明显优于其他算法.其中当任务数量为100时,在LIGO这一数据集上,IAG算法的开销为3116,而IPSO算法、PSO算法、FCFS算法的开销分别是3125、3126、3125.当任务数量为200时,IAG算法表现更为显著,IAG算法的开销为5405,而IPSO算法、PSO算法、FCFS算法的开销分别是5442,5443,5443.这是由于提出的IAG算法将蚁群系统进行改进,对工作流执行时间和开销成本建立相关函数,同时采用蚁群算法加快对虚拟机的搜寻,将工作流中的任务匹配给更适合的虚拟机,从而提高任务的完成时间,另一方面,在将虚拟机部署到物理机上时,该算法针对同类型的虚拟机的部署可以免去部署开销,节省部署时间.而IPSO算法、PSO算法相较于FCFS算法能够在执行时间和费用开销方面有明显提升,但是,由于虚拟机在物理机上进行部署时,以上算法是针对同类型的虚拟机没有免去部署时间,增加了部署时间与开销,从而在实验中显示出劣势.

图4 不同数据集下的实验结果Fig.4 Experimental results under different data sets
图4为不同数据集下的任务在由6台物理机,20台类型数为8的虚拟机构成的小型数据中心的测试结果.同样分别采用了CyberShake、Montage、LIGO、SIPHT数据集,任务量分别为100,200进行测试.将由图4可以看出,在图4(a)、图4(b)、图4(c)中,当任务数量为100、200时,在CyberShake、SIPHT、Montage数据集上,IAG算法的费用开销在750左右浮动,而IPSO算法、PSO算法、FCFS算法在3个数据集上的费用在880左右浮动.同时在LIGO数据集上,IAG算法也明显优于其他算法.因此,在构造的小型数据中心中,IAG算法在不同任务大小的数据集上表现优于IPSO算法、PSO算法、FCFS算法.
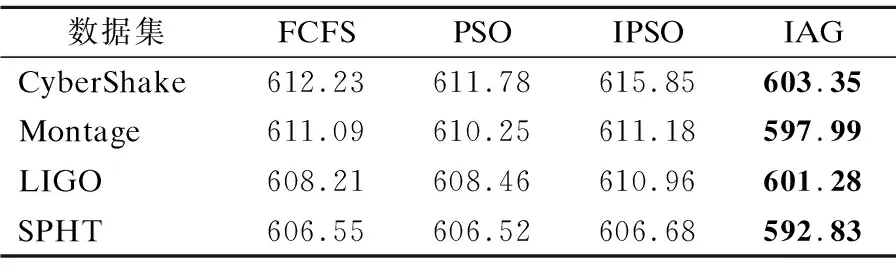
表2 任务为100的完成时间(s)Table 2 Completion time of task 100
各个算法在执行任务为100、200的时间如表2、表3所示,任务数量为100时,IAG算法在CyberShake、Montage、SIPHT上面时间上均优于其他算法,其中在CyberShake上,对比FCFS算法、PSO算法、IPSO算法分别提高了1.45%、1.38%、2.03%;在Montage上,分别提高了2.14%、2.01%、2.16%;在LIGO上,分别提高了1.14%、1.18%、1.58%;在SIPHT上,分别提高了2.26%、2.26%、2.28%.表3可以看出,

表3 任务为200的完成时间(s)Table 3 Completion time of task 200
当任务数量为200时,IAG算法较其他算法在任务完成时间上也有明显提高.随着任务数量的不断增加,IAG算法的优势更加明显,这是因为任务数量的不断增加,相对应的虚拟机、物理机数量也在不断增多,而对于工作流到虚拟机上的映射问题,利用改进的蚁群系统能够为工作流中的任务更加快速需找到合适的虚拟机,节省了时间;同时随着虚拟机数量的增多,虚拟机到物理机上进行部署时,同类型的虚拟机的部署也会节省更多的时间和费用开销.
5 结束语
本文提出一种基于蚁群系统和贪心思想的二阶段工作流联合调度算法(IAG),该算法首先基于现有的蚁群系统算法,以最小化工作流完成时间为目的,设计了启发式函数和信息激素更新规则,将工作流映射到虚拟机.然后,再以最小化费用开销为目的,保证工作流完成的前提下,提出了一种基于贪心思想的虚拟机到物理机的部署方法,该方法主要的特点在于考虑了虚拟机多类型的特点,从而避免了虚拟机部署开销大的问题.最后,通过Cloudsim仿真平台,以及与 FCFS算法、PSO算法、IPSO算法分别比较,验证了提出IAG算法的有效性和优越性.
