基于多任务和卷积神经网络的业务识别算法
2021-04-19赵季红乔琳琳
赵季红,乔琳琳,王 颖
(1.西安邮电大学 通信与信息工程学院,陕西 西安 710121; 2.西安交通大学 电子信息工程学院,陕西 西安 710049;3.北京邮电大学 信息安全中心,北京 100876)
随着无线通信技术的飞速发展,要求未来的网络能够为各种场景提供不同的服务。网络切片作为未来关键技术,可以将物理网络划分为多个虚拟网络切片,从而提高网络资源利用率,降低网络运营商的成本和能耗,提高网络用户的体验质量[1-2]。面向多用户的网络切片在建立的过程中,需要考虑网络场景的复杂多变且新型业务不断出现,而其中关键及难点问题之一是如何识别出各种网络业务的类型。
网络业务分类一直是业界和学术界关注的焦点。目前主要的业务分类方法可以归纳总结为基于端口识别的深度包检测(Deep Packet Inspection,DPI)、基于统计特征和协议的业务分类方法[3]。此外,考虑效率低下和缺乏准确性,基于机器学习算法的方法已经被广泛应用于网络业务分类[4]。这些方法通常依赖于监督学习方法,如支持向量机(Support Vector Machines,SVM),k-近邻(k-Nearest Neighbor,KNN),随机森林(Random Forest,RF) 或依赖于无监督聚类方法,如k-均值。然而,上述相对简单的方法无法捕捉到当今互联网流量中存在的更复杂的模式,因此其准确性不高。
随着深度学习方法在图像分类和语音识别等领域的成功应用,其能够学习复杂的模式和执行自动特征提取,研究人员提出了利用深度学习方法对流量进行分类[5]。文献[6]使用再生内核希尔伯特空间(Reproducing Kernel Hilbert Space,RKHS)将每个流的时间序列特征转换成二维图像,产生的图像被用作卷积神经网络(Convolutional Neural Network,CNN)模型的输入,将CNN模型与经典的机器学习方法进行了比较,包括SVM和决策树,CNN模型的精度达到99%以上,优于经典的机器学习方法。文献[7]同样采用CNN模型进行流量分类,将许多统计特征重新排列成二维图像作为模型的输入,最终以高精度进行分类。但该模型需要观察整个数据流获得统计特征,不能用于在线应用程序。文献[8]提出了使用CNN、长时记忆(Long Short-Time Memory,LSTM)模型对业务进行分类,当“CNN+LSTM”体系结构使用时间序列特征时,其精度能够达到96%左右。虽然上述深度学习方法可以达到高精度,但其缺点主要是需要大量的标记训练数据。在网络业务分类任务中,标记数据是一项耗时及繁琐的任务。此外,在受控环境中观察到的数据流可能与实际流量有很大的不同,使得标记数据获得的推断不准确。文献[9]解决了需要大量标记数据集的需求。此方法由半监督学习方法组成,利用CNN模型从采样数据包中预测几个统计特征,使用采样数据包的时间序列特征,然后采用新的图层替换最后几层,最后使用少部分标记数据集进行重新训练。其优点是不需要花费人工标记预训练的数据集,当整个流程可用时,可以轻松地计算统计特征。但是此方法需要采用采样数据包,在执行分类之前先观察大部分流量,同样不适合在线应用。
针对上述方法存在的问题,拟提出一种基于多任务学习的卷积神经网络(Multi-Task Learning-Convolutional Neural Network,MTL-CNN)方法,在执行带宽需求、持续时间和业务类别等3个任务的预测时,只有业务类别任务需要人为标记。对于任意的数据流,每个流的带宽需求和持续时间都很容易计算,并不需人为标记。因此,通过在多任务学习框架中制定业务分类问题,就可以用大量的不需要标记的数据在CNN中训练模型的带宽需求和持续时间任务,所有任务共享模型参数,只需要少量的标记样本数据就能进行业务类别预测,以期使不同类别识别效果更加均衡,提高分类准确率。
1 问题描述与系统模型
1.1 网络业务分类问题
网络切片中有诸多的业务类型,如虚拟线上/增强现实、超高清视频、自动驾驶、远程控制和远程医疗手术、智慧城市、远程抄表,等等,这些多样的业务类型对网络性能的要求也有着巨大的区别。如底层网络发生故障时,可能引起失效的网络切片业务类型并不单一,如何选取动态的恢复方法,就要及时在线判断失效的业务类型[10]。根据网络数据流的统计特征对网络业务进行分类与识别,其本质就是根据业务传输的过程中在统计特征上的差异,以区分不同的业务类别。以往方法通过将统计特征作为输入,根据输入特征的不同训练分类器。而带宽需求和持续时间这两个统计特征是需要观察整个数据流计算获得,因此,将其作为输入只适用于离线应用。文中选择带宽需求和持续时间作为单独的辅助任务进行输出,可以在训练的过程中计算获得,同时主任务在训练过程中共享模型参数,能够实现高精度业务分类,从而满足对业务在线分类的要求。
1.2 卷积神经网络
CNN是由使用卷积计算的若干层组成的前馈神经网络(Feedforward Neural Networks,FNN)。其由卷积层、池化层和全连接层组成,如图1所示。卷积层的功能是对输入数据进行特征提取。为了生成输出,卷积层在整个输入上使用相同的卷积核,通过在一层中使用相同的卷积核,可以使学习的参数数量大幅减少。此外,在整个输入中使用这些卷积核也有助于模型更容易地提取平移不变特征,实现具有平移不变特征的网络业务分类任务。在卷积层进行特征提取后,则需要通过池化层负责数据采样,即选取特征以及过滤信息。全连接层位于卷积层和池化层的末端,常用于捕获高级的特征,典型的CNN的具体架构如图1所示。
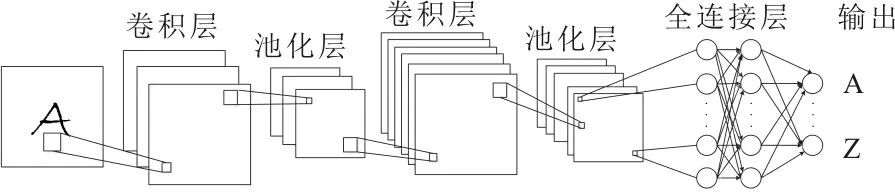
图1 典型的CNN架构
1.3 多任务学习
MTL的目的是在任务非完全独立的假设下同时执行若干个学习任务,是主任务使用相关任务的消息,提升泛化效果的一种机器学习类型。典型的MTL如自主驾驶,其中检测危险物体和对危险距离评估是自主驾驶的两项重要任务,基于这几个任务是相关的并且可以共享参数,需要定义一种多任务学习方法联合学习这些任务[11]。而多任务学习模型比几个单任务学习模型更有效,考虑在MTL数据集中,所有任务都可以互相帮助,使得所有任务都能被更好地学习,因此,可以通过使用多任务学习方法提高业务分类任务的准确性。常规的多任务学习结构如图 2 所示,其中,共享隐层中所有任务共享网络参数,在对多个任务预测或分类时,训练所需要的数据量与模型参数的数量都将减少,使模型更加高效,随后各任务的分类结果在输出层中被分别输出。
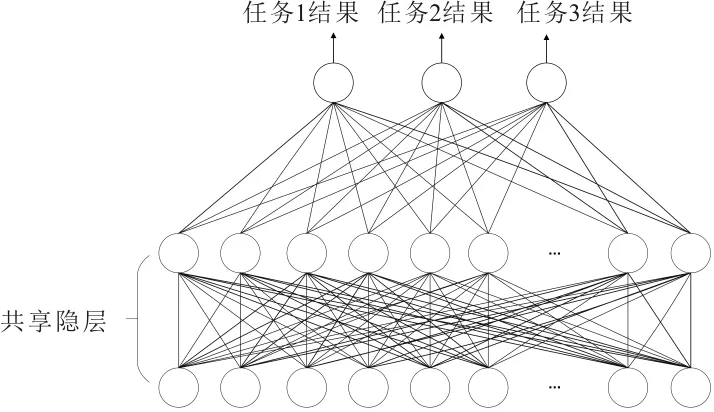
图2 常规多任务学习架构
2 多任务业务分类方案
2.1 数据集
数据集来源采用了Arunan Sivanathan等人[12]公开的数据集,包含多个物联网设备以及非物联网设备获取的数据流量,包括智能开关、智能音响、智能手机、智能医疗设备、打印机、笔记本电脑和摄像头等。每种设备代表着不同的业务类型,并按照文献[13]对数据集进行分类标注。为了评估多任务学习方法,且仅使用少量标签数据提高主任务预测的准确率,实验中只使用了800条标记样本,并且对数据集进行了预处理。当采样短流数据时,没有足够的数据包提供多任务分类器,因此,在预处理过程中删除了所有短流数据。在评估中,短流是指那些在采样前小于100个数据包的流[14]。对于特征的选择和提取,网络流量分类器通常使用一种或四种类别的输入功能组合,如时间序列、标头、有效负载和统计特征,考虑标头信息无法实现高精度,现在已经很少采用;有效负载已被证明对于某些数据集和特殊流量类型以及加密方法比较有用,但是对于新的和更强大的加密协议,其作用有限;统计特征需要从整个流程中获得,而对于取决于预测输出的一些情况,如资源分配、路由决策等,一旦流量出现就必须进行在线预测,根据统计特征预测显然不适用于在线分类。因此,所提算法为满足在线分类的要求,仅观察前k个数据包,使用前k个数据包的3个时间序列特征,即选取数据包长度、到达时间和方向作为特征值。
2.2 方法流程
提出了一种基于MTL-CNN的网络业务识别算法,采用CNN作为共享层,其最重要的特征之一是移位不变性,因此适合于具有时间序列特征的业务分类任务。结合文献[15]中提出的带有属性依赖层的MTL结构,在共享隐藏层之后添加了任务间相互独立的属性依赖层。该层通过对带宽需求和持续时间两个辅助任务,对网络业务进行分类,多个任务之间共享特征和共同学习,同时允许每个子任务在属性依赖层独自优化提升性能。
辅助任务的选取有两个特点。一个是其应该与网络业务分类任务高度相关,另一个是不需要人为的标记大量数据,而且可以较为容易的获取。带宽需求和持续时间往往作为特征输入对业务进行分类,并且可以通过观察整个数据流计算获得。因此,考虑使用带宽需求和持续时间这两项任务作为业务识别的辅助任务。在所提方法中,模型的输入是一个具有两个通道的长度为s的向量。第一个通道包含前k个数据包的到达时间,第二个通道包含数据包的长度和方向,其总体流程如图3所示。
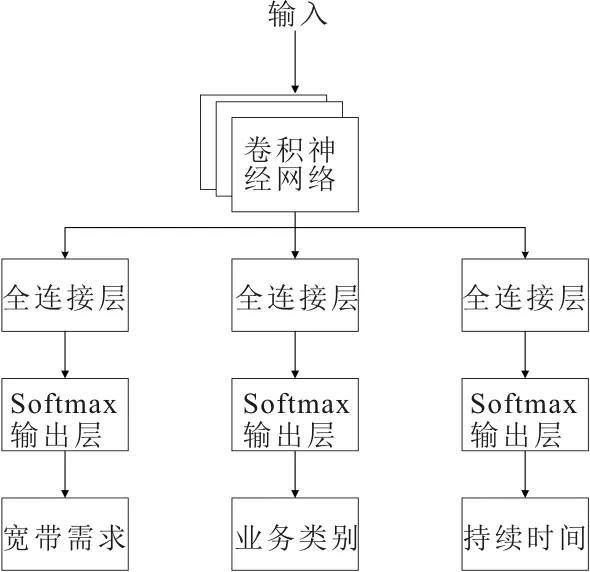
图3 MTL-CNN流程
将3个时间序列特征输入到共享层中,这里使用3层CNN作为共享层,对于该卷积层,使用Relu激活函数增加CNN各层之间的非线性关系,Relu函数实施的稀疏模型可以更好地挖掘相关特征并拟合训练数据。该激活函数表达式为
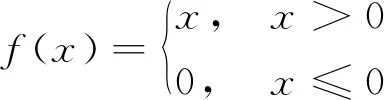
(1)
第三层输出最后一个结果并将其输入到属性依赖层中。属性依赖层由3个单独的全连接层组成,分别将结果输出到3个单独的softmax输出层中,最后输出带宽、持续时间和业务类别3个任务的分类结果。
2.3 目标函数
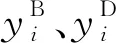
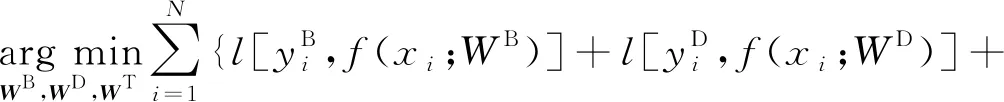
(2)
其中:l表示交叉熵损失函数;λ表示业务分类任务预测的重要性的权重。考虑主任务的训练数据样本比其他两项辅助任务的训练数据样本要少得多,因此,可以增加λ稍微补偿缺乏的标记数据。对于所有训练数据,带宽需求和持续时间标签都是可用的,只有一小部分的数据样本有业务类别标签。在训练过程中,将业务类别softmax层的输入与掩码向量相乘,以防止主任务对没有业务类别标签的数据样本进行反向传播。
3 仿真与性能分析
3.1 实验环境配置
使用基于Python的Keras包对Arunan Sivanathan数据集实现多任务学习方法。在所有的实验中,训练阶段仅需要几分钟时间,使用批处理优化和Adam优化器进行训练,Adam参数设置模型学习率为0.001,衰减率为0.9。实验在操作系统Windows 10专业版、CPU为Intel core i7 4790/3.6 GHz/4cores,16 GB内存以及开发环境为Python 3.7.0的环境下进行。为体现多任务学习在性能上的优势,除对所提模型进行实验外,在数据集相同的条件下还设计了3组对比实验。
MTL-CNN仅对数据集中的800条数据进行业务分类标记,将时间序列特征输入CNN共享层,在模型训练后输入到属性依赖层,主任务通过属性依赖层学习和共享辅助任务的参数,最后将3个任务分别输出到3个独立的softmax 输出层。
单任务的卷积神经网络(Single-Task Learning Convoluctional Netural Network,STL-CNN),该模型依然采用CNN模型捕获内部信息进行训练,但只有一个softmax 输出层,即只预测业务类别一种任务。
Only-CNN,该模型将时间序列特征输入CNN共享层,将结果直接输出到3个独立的softmax 输出层,该模型与文中模型不同之处是不包含属性依赖层。
RF[13]模型对8万条样本数据都进行了业务分类标注,以流信息和流头部的数据包信息作为特征向量输入,在RF模型中进行训练以及预测业务类别,该模型的缺点是消耗较大的计算和存储资源。
3.2 评价标准
可以利用准确率、精确率、召回率、虚警率和漏报率等指标从不同角度分析业务的分类效果[13,16]。为了从全局层面评价所提算法将多任务和CNN相结合对业务分类的效果,采用准确率(Accuracy)评估所提算法的整体性能。准确率指正确分类的数据流数量与所有数据流数量的比值,其定义[16]为
(3)
其中:TP与TN分别表示正确归类的数据流,即TP表示属于a类的数据流被正确归为a类,TN表示不属a类的被归为非a类;FP与FN分别表示错误归类,即FP表示不属于a类的被归为a类,FN表示属于a类的归为非a类。
3.3 结果分析
3.3.1 单一任务业务类别预测准确率
将数据集进行分类标注,根据物联网设备和非物联网设备将业务类别划分为13种类型。表1显示了在同一数据集下所有方法的每种业务类别识别的准确性。由表1可以看出,在13种业务类别的准确率中,智能婴儿监视器和网络摄像头识别率相对较低,由于其属于同一物联网设备,设备行为比较相似导致业务区分度不高,所提MTL-CNN算法的准确率平均为95.60%。而对比算法STL-CNN与MTL-CNN,只对800条样本数据进行了分类标记,考虑STL-CNN没有其他的分类器,提取的特征只用于单一的业务分类,因此准确率最低,不包含属性依赖层的Only-CNN的准确率约92.60%。说明MTL-CNN的属性依赖层有助于该模型的学习能力,能够提升该算法的区分业务类别的性能。
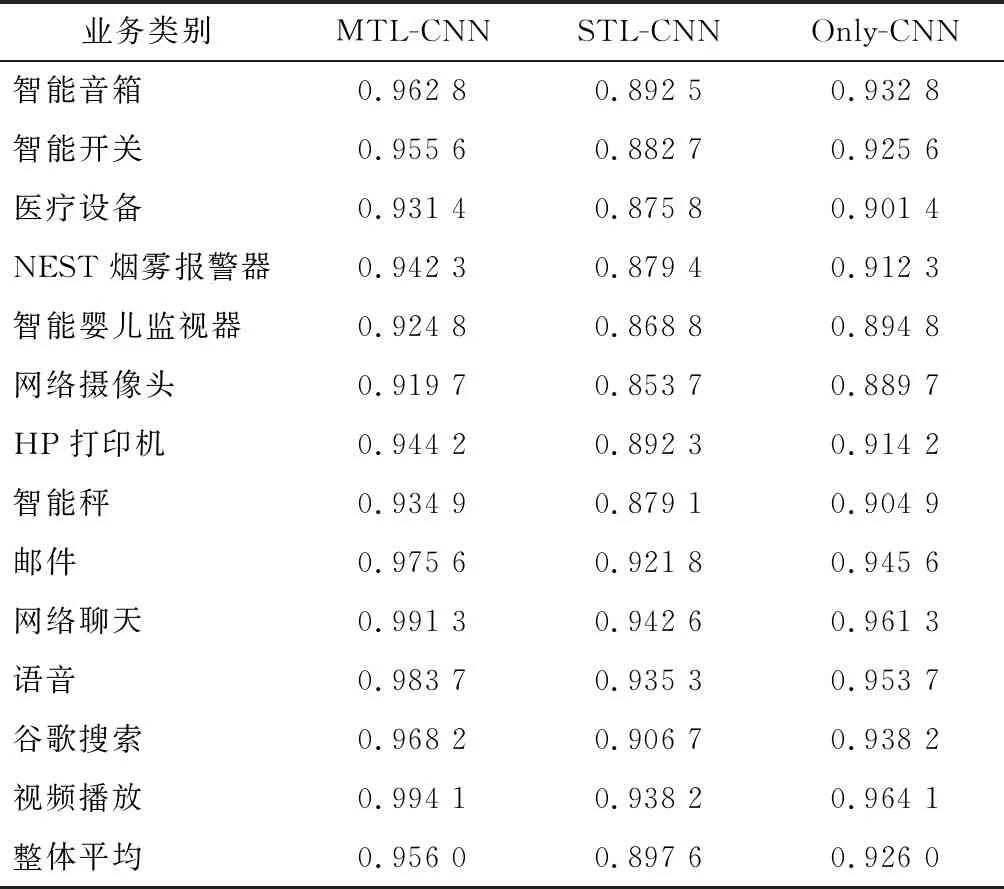
表1 业务类别识别准确率
3.3.2 每项任务识别率
为了测试每项任务的识别率,先将权重λ值设置为1,强调3个任务平等。该参数设置一方面是为了与单任务实验做对比,另一方面是为了验证使用少量标签的主任务在训练过程中确实受到了具有丰富数据的辅助任务的影响。每项任务识别准确率的测试结果如表2所示,关于辅助任务即带宽和持续时间的准确率,MTL-CNN算法和不含共享层的Only-CNN算法差别较小,说明使用相同的数据集进行训练是否有共享属性层对预测辅助任务影响不大。而对于主任务预测,MTL-CNN算法明显高于其他算法,与使用所有标记的数据集的RF算法相比,MTL-CNN算法仅用800条标记的数据预测业务类别,准确率仍高于RF算法。考虑采用带宽和持续时间任务的大量数据改善了训练过程,利用此数据训练模型参数,通过共享参数加强了预测业务类别的准确率。因此,所提算法可以减少标记的数据量,且提高预测的准确率。
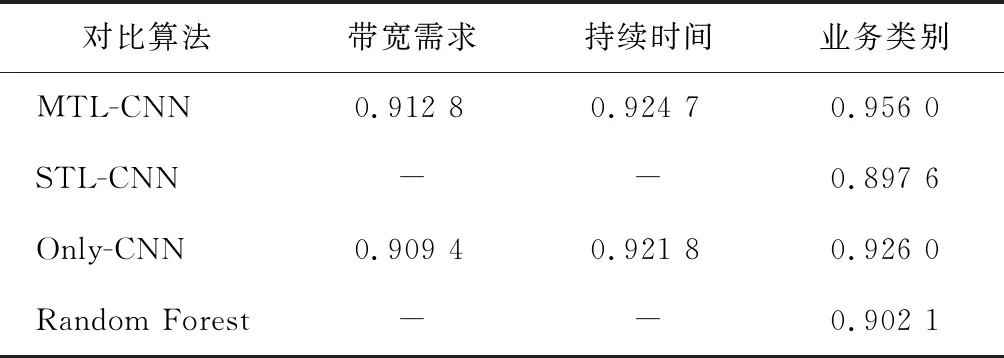
表2 每项任务识别准确率
3.3.3 不同λ取值的任务的准确率
不同λ取值的3个任务识别准确率如图4所示。当在多任务学习中一项任务的训练样本数量明显少于其他任务时,深度学习模型的共享参数在训练过程中会受到具有大量数据的辅助任务的影响。增加主任务损失函数的权重,可以弥补训练过程中主任务数据的不足,并增加主任务对训练过程的影响。从图4可以看出,增加λ有助于模型适应主任务即业务类别识别任务,当λ取10时,带宽任务识别准确率达94.85%,持续时间任务识别准确率达92.58%,业务类别识别准确率97.65%,此时主任务达到最大准确率。同时,也可以观察到,如果进一步增加λ值将降低所有任务的准确性。因此,对于多任务学习方法,合适的λ值有助于提高任务的准确率。
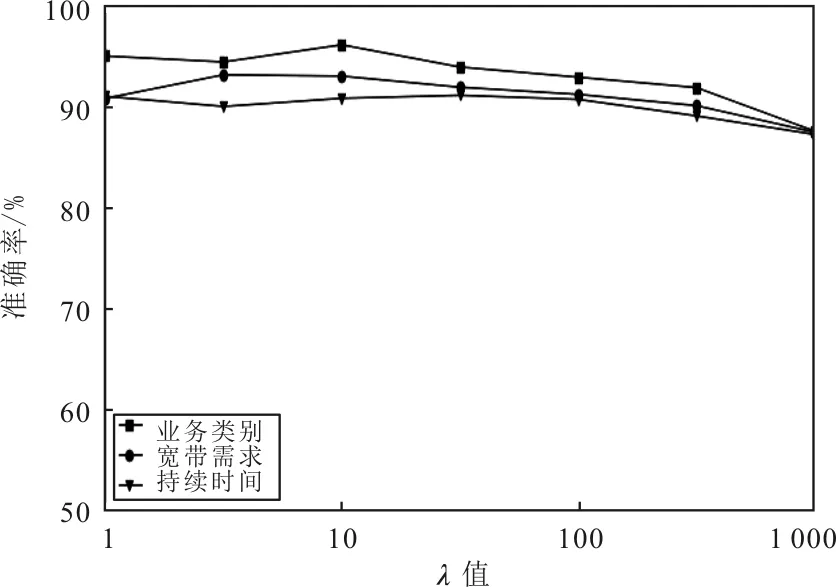
图4 λ与准确率的关系
4 结语
提出了一种多任务学习和CNN的业务识别方法,用于预测业务类别以及流量的带宽需求和持续时间。通过为带宽需求和持续时间辅助任务提供足够大的数据集,可以仅用少量标记样本训练业务类别预测任务。实验结果表明,采用相同的数据集,所提算法显著优于STL-CNN、Only-CNN和RF方法,其避免了大量标记数据样本,并且有较高的识别准确率。但是要为辅助任务提供大量的数据,整个训练时长仍有待改进,考虑数据样本的限制,所提系统的模型仍然较为简单,在未来的工作中,希望找到更适合的模型进行特征提取,以获得更高的识别准确率。
