无线传感器网络的HBase数据存储模型性能分析
2021-03-14陈广柱胡积宝
郑 羽,陈广柱,胡积宝
(1.安庆师范大学经济与管理学院,安徽安庆246133;2.池州交警支队,安徽池州247100;3.安庆师范大学数理学院,安徽安庆246133)
物联网发展快速,它越来越多地渗透到各个领域。作为物联网终端的信息存储,无线传感器网络在更大范围内传播,传输的信息量也越来越大[1-2]。时间的积累和数据存储量的增加会导致数据库性能降低,系统不能在合理的时间内满足用户的需求。因此,根据数据库的实际需求,选择适当的方法来改善用户的存储和检索效率变得非常重要。现有的基于关系和对象模型的数据库可以解决复杂数据的存储问题,但是存储和系统消耗的成本过大[3-4]。无线传感器网络对数据实时分析有很高的需求,需要建立区域存储集群,每个区域都有独立的数据存储集群[5-6]。
在数据存储器中,数据保存在分布式缓存系统中。分布式缓存系统的缓存条目以<键、值>的形式存在。它使用内存缓存查询的缓存技术,以便暂时将数据库内存中第一次获得的结果存储起来。当用户请求相同的内存时,它可以直接读取数据库以便用户重新使用,这样既减少了请求的时间,又提高了系统的效率。Hadoop分布式文件系统适用于大规模数据集,能提供大吞吐量的数据访问和高容错性[7-8]。
Hadoop的分布式文件系统基于HBase数据存储特定的优化技术,包含数据共享和数据分布两个普通的优化策略[9-10]。本文选择后者,因为数据共享统一了所有类型数据的管理存储,当一个队列用于接受数据时,解决了拥塞问题,却忽略了多源数据的不同模式,从而降低了输入和数据流查询的效率。本文在存储优化策略指导下,设计一个有效的实时存储模型:实时的数据流会快速存储到集群数据库中以满足用户的多种需求。以文本形式存储的历史数据流将被迁移到高效、高稳定性的HBase集群数据库中。当存储空间不够、或者集群文本系统的存储空间太大时,HBase数据集群有效且便捷地更新会有助于优化数据空间。
1 无线网络数据实时存储模型
为数据访问预处理区域设计了多源异构、海量、高速的数据存储结构,该架构包含3个部分:数据缓冲区域、数据调度区域和数据存储区域,如图1所示。
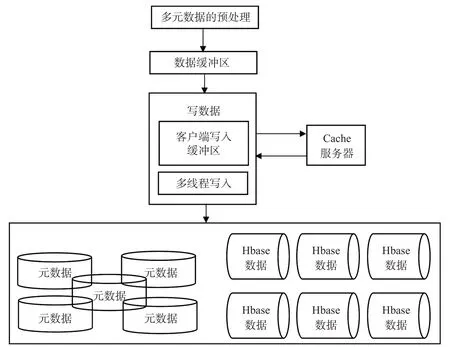
图1 实时系统架构
1.1 多数据存储缓冲器
通过哈希方法将多元数据转换队列传输到缓冲区后,预处理区域就可以访问了。为了提高分区后的数据传输速率,数据队列存储在链表结构中。每个缓冲区中有三个队列等待数据分割。图2显示的是多元缓冲区架构。
面对每秒将近一百万个高速数据,系统的写入缓冲速度被设置为6 MB/s。队列完成后,通过窗口阈值调用HBase多线程,将数据发送到缓冲区,从而使客户端通过远程过程执行请求,并将数据发送到服务器进行永久存储。

图2 多元缓冲架构
1.2 过滤器和处理器
用户可以在多个维度(行、列、数据版本)上过滤HBase特定存储单元上的数据,提高从表中检索数据的效率。当发送大量数据时,HBase提供端点的协处理器,具有复杂代码及不同分销协议的服务器执行计算任务,然后将结果返回到客户端。与从数据服务器检索数据的方法相比,该方法具有减少网络传输压力和客户端计算量的优点。
2 HBase集群配置
2.1 层次路由协议
首先,考虑数据的压缩比、压缩率以及解压速度等参数,平衡I/O和CPU资源性能,群集配置是压缩模式时,选择更优化的算法。其次,为了减少服务器上缓冲区的数据、客户端内存的消耗以及RPC的连接数,设置HTable客户端模式,以减少HBase和I/O频繁的沟通。再次,基于一致性维护功能,如果从服务器端返回的数据量太大或者要访问的数据不在缓存中,集群配置将调整参数时间(HBase.rpc.timeout)。最后,服务器端每次读取远程调用设置的次数都会被调整。调整太少会降低访问效率,太多会导致内存被占用而降低访问速率。
为了将各个无线节点所采集的数据传输回测试终端,集群各节点的组网设计必须科学合理。本文采用层次路由协议,利用多通道数据传输技术,使得在层次路由协议的星型簇中,作为簇头的无线节点读取簇成员时可以同时与多个簇成员节点通信,该网络层次结构如图3所示。与传统的流程相比较,这种结构降低了整个系统的数据传输时延,降低了传输过程中的误码率,增强了利用该技术进行组网的能力。

图3 网络路由层次架构
2.2 系统存储流
当数据访问到数据预处理区域时,不同类型的源数据是用唯一的标记创建的,它丢弃不完整的数据对象,或提供格式化的操作确保数据完整而高效地传输到缓冲区进行队列分区。多数据缓冲区接收经过预处理的数据来初始化存储数据的队列,根据时间戳属性计算接收到的数据,并将数据发送到相应的队列。当缓冲区的数据量达到阈值,系统将数据值写入预分配策略,数据存储在相应的数据库服务器中,并更新HBase集群数据库的计数记录表。
2.3 系统存储算法实现
程序执行根据消息的时间属性使用Hash计算初始化数据队列,然后根据相应数据队列的哈希值比较数据大小和阈值。HBase数据库在数据大小超过阈值或接收时间超过1秒时启动。表中记录的总数是基于原始写入数的记录数。
2.4 HBase集群节点的动态更新
当用户数据量增加时,现有的集群数据库不能满足用户对空间和性能的要求,也不能满足系统丢失大量的历史数据时的需求。如果手动修改Hadoop和HBase的配置文件,既浪费时间和人力,也会增加修改配置过程中的错误率,所以在集群节点使用shell脚本的形式进行动态更新。
3 性能分析
集合U={U1,U2,U3,…,Un-1,Un}为研究对象的集合(包括物质、事件和关系等),集合O={O1,O2,O3,…,Om}为研究对象的特征集,值Vaij是对象Ui的属性Oj,i为基元,j是基元维度,i和j的取值范围分别为i=1,2,3,…,n;j=1,2,3,…,m。Vaij为空时表示对象Ui和相关属性Oj之间没有关系。
HBase是面向列的数据库,应用列是主键,数据写入查询的时间复杂度是logN。当查询访问时,客户端首先访问主要节点,然后通过主要节点的引导和区域服务器的协调响应客户机的写请求和读请求。因此,查询访问的时间由主要节点时间Tmaster、主要节点的导引和区域服务器协调时间TAreaServer组成。将查询数据的数量设置为i列,由主要节点协调的区域服务器的数量m作为j列存储在每个区域服务器中,每个主要节点内容的长度是i/j,区域服务器中保存数据的长度是i/(j×m),总的时间是TTotal。各时间变量间的关系如下所示:

为了验证HBase的存储、查询和可扩展性,我们使用300个传感器节点,用于写入和读取时间。
实时存储方法是基于Oracle的数据存储,数据存储测试单独进行。本文设计的系统对数据写入区内的操作采用单线程和多线程写入。具体设置如下:写入客户机缓冲区宽度设置成6 M,缓冲区大小设置为2,4,6,8,单位是MB,数据传输速率是1,2,3,…,30,单位是该窗口时间阈值,设为2 s。
图4是用分布式实时存储方法存储Oracle的流数据。当数据传输速率为12 000 bit/s,随着数据传输速率的增加,存储的数据延迟和延迟时间不断增加。当系统使用单机测试时,延迟点是25 000 bit/s。当使用集群技术时,数据库吞吐量显著增加,传输速率为55 000 bit/s,并且没有延迟。
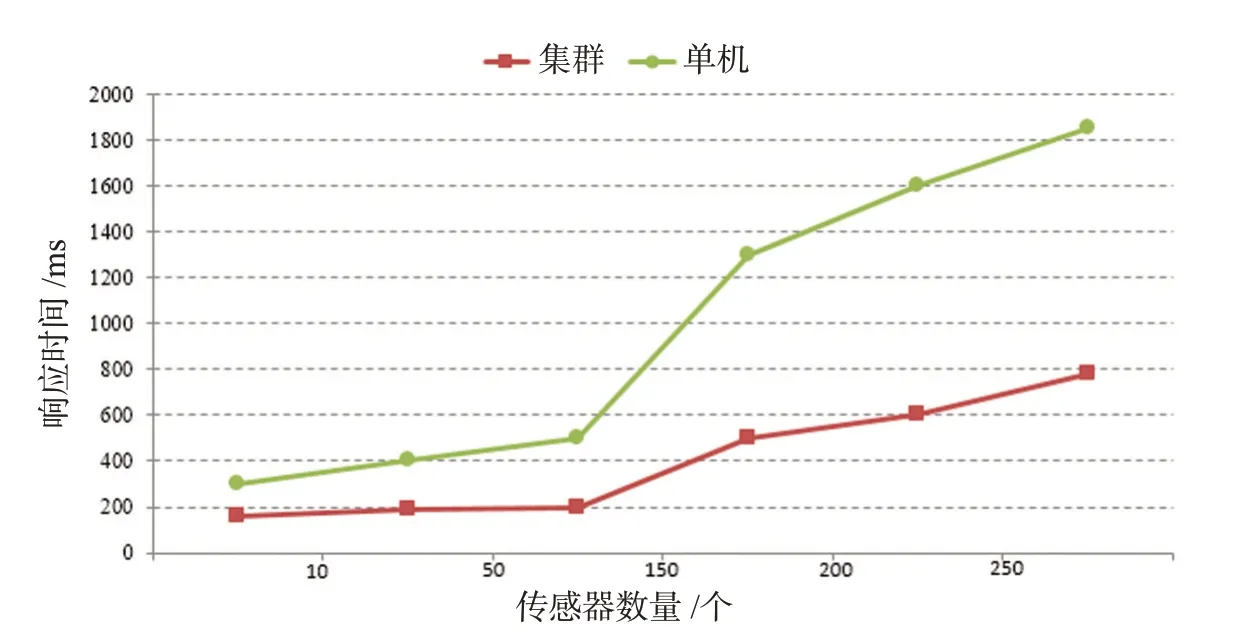
图4 传感器数量与等待时间及读取时间的对比
图5的水平轴是每秒发送的数据,竖直轴是HBase集群数据库实时存储流数据的延迟时间,单位是ms。
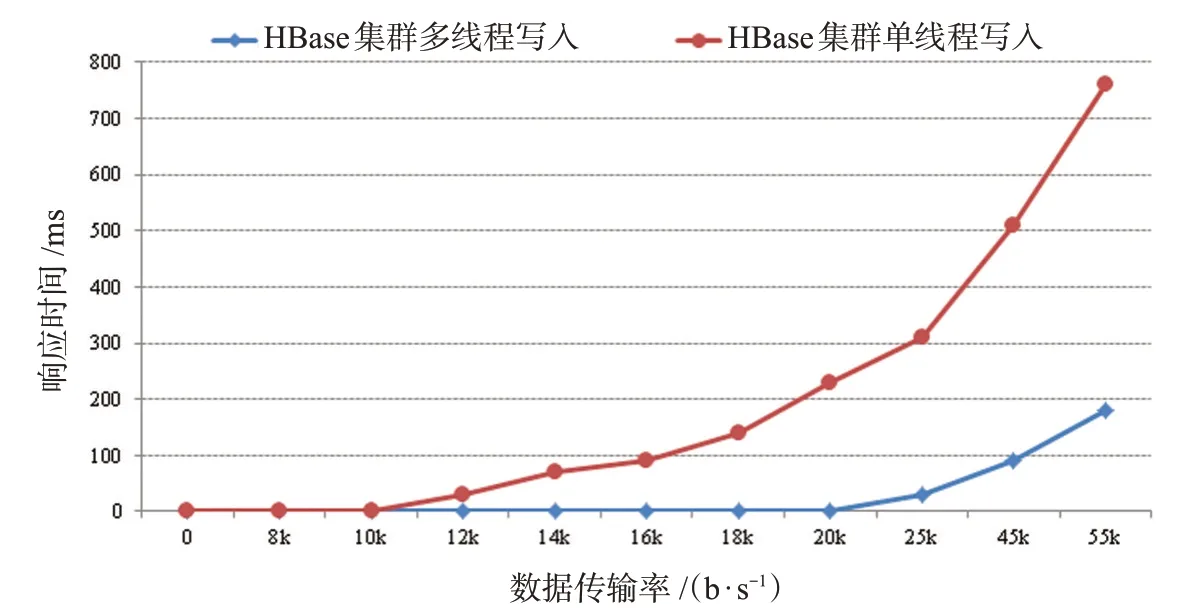
图5 延迟模拟测试
如图6所示,吞吐量效率是25 000次/s,1次延迟,随着数据传输速率的增加,延迟将更长。当阈值设为6 MB时,不同缓冲区阈值的模拟测试结果是最优的,增加或减少缓冲阈值将增加实时数据的内存延迟时间,在无线传感器网络运行的初始阶段,因为节点还没有开始产生数据或者产生的数据比较少,所以也没有产生重复的数据,此时的空间利用率为1。然而,随着网络中数据量的不断增长,重复的冗余数据量也逐渐变大,空间利用率会逐渐变小,节省了网络的存储空间。在能够容忍一定错误的前提下,该方法能够很好地处理传感器网络中的数据冗余问题,并进一步提高了网络的存储能力[11]。
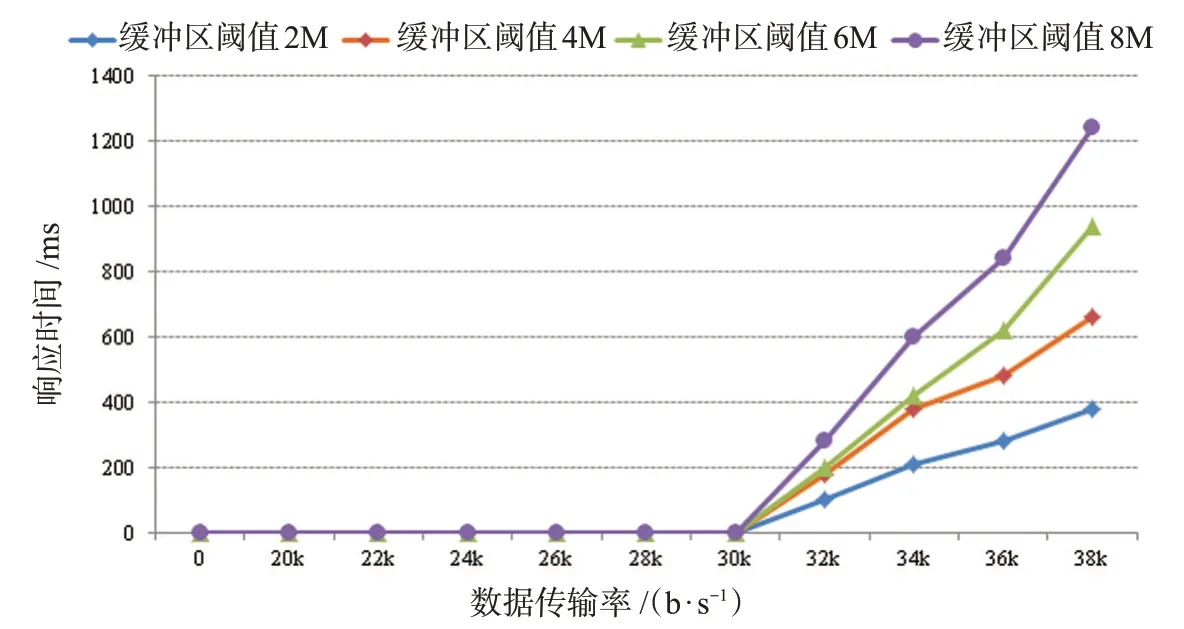
图6 缓冲阈值模拟测试
4 结论
本文设计了一种高效的实时存储模型以满足高效存储数据的需求。数据流实时存储在Hadoop集群数据库中,在多种复杂环境下满足用户对数据的存储及读写。此外,以文本形式存储的历史数据流将被迁移到高效、高稳定性的HBase集群数据库,简单的动态更新HBase数据库集群及其效率将有助于优化数据库空间的使用。
