校园舆论词频分析
2021-02-18孙睿李波殷晓有
孙睿 李波 殷晓有


摘要:大数据时代,要善于利用大数据,掌握主动,提高网络舆情的管理水平。建立具有网络舆情宣传、评价、报告和处置等功能的网络舆情分析平台,可以依托校园媒体来实现,校园媒体本身既处于学生群体当中,又是区别于学生的信息传播者。网络和手机等校园媒体为师生提供一个良好的與情空间,是相对具有公信力的网络舆情分析平台,在校园媒体平台上,师生的校方可以平等地进行交流沟通。了解师生所关注的社会和校园热点,及时收集信息和跟踪,并有针对性地围绕这些舆情来实施具体措施,第一时间形成舆情事件的研判,开展合理的引导,定期发布舆情报告和反馈信息,对正在发生和舆情事件积极回应,变被动为主动。
关键词:高校网络舆情,大数据,词云,舆论,词频分析
引言
网络舆论引导是高校网络思想政治教育的重要形式,也是高校民主化管理的必然选择。在高校网络舆情中应重视和规避蝴蝶效应,合理运用鲶鱼效应,充分认识信息环境下网络的双面性,通过疏堵相结合的方式,正确合理引导网络舆情,建立高校危机管理及引导机制。并且可以借鉴传播学的理论,以微博,贴吧,知乎等社交平台为载体加强对高校网络舆情的引导,注重思想引领,发挥网络思想政治教育的渗透作用。注重观察研判,加强有效信息的收集与整理;注重深层疏导,让多层次意见及时发声。
我国的网民规模和宽带网民规榄增长迅猛,互联网规模稳居世界第一位。截至2009年6月底,中国网民规模达到3.38亿,较2008年底增长13.4%,半年增长了4000万 。
近年来,我国大学生网民猛增,高校网络舆情活跃,高校网络輿情研究逐渐受到学界的关注和重视,成为网络舆情研究的重要分支。
一、研究目的
一方面,互联网打破了传统校园对舆论的控制和对信息的垄断,使传播过程中的传受双方变得更加自由和平等,在网上人们有了更多自主发表言论的权利和机会,这有利于充分反映来自社会各方面的愿望,意见,要求和呼声;有利于校园舆论监督工作的开展;有利于正确舆论的形成;有利于推进校园发展的进程。
另一方面,校园互联网舆论分析作为一个全开放的几乎没有任何管制的信息和观点的通道,给舆论导向也带来了诸多的负面效应。由于网络传播的个人化和隐蔽性,使人们在网上发表言论无须像在傳统媒体上承担责任,这无疑给某些居心不良者提供了可乘之机;由于传统的把关人作用的削弱和缺乏强有力的监管机制,使诸如暴力、迷信和其它有害信息在网上泛滥成灾;由于网络传播的速度之快、范围之广和极易复制,令虚假新闻在网上滋生蔓延,这些都对我们在网络传播中坚持正确的舆论导向带来不利影响。大数据时代,要善于利用大数据,掌握主动,提高网络舆情的管理水平。
在校大学生日常生活中遇到各种困难时通常会在网络上寻求帮助,在这过程中会产生大量冗余的数据信息,由于数据信息量过于庞大,复杂,导致求助的同学无法有效地获取帮助。因此我们需要设计一个舆情分析系统,通过舆情分析,基于云计算,从网络上抓取这些信息进行分析,再以数据可视化的方式呈现出来,从而使大家可以明确的了解到同学们的具体需求,并提供相应的帮助。
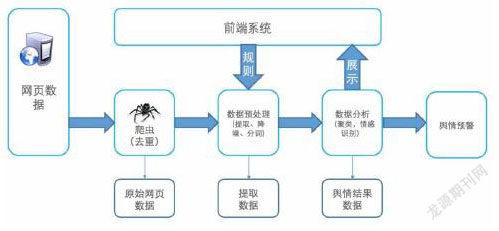
二、舆情分析系统
1.数据获取
通过python设计不同的爬虫获取如微博,贴吧,知乎等社交平台中的舆情信息及评论数据。python庞大的第三方库,如json,urllib,request等可以帮助我们快速爬取网页的数据,并通过Beautiful Soup和Pyquery提取有用信息,剔除无用信息,最后将爬取到的数据存入csv或txt文件中进行后续数据分析。
以知乎网站为例,由于现在网站大多使用的都是异步加载技术用于存储网页数据,所以我们通过ajax来快速获取网页数据,构建正则表达式,复制头文件将我们设计的爬虫进行伪装,并用cookies解决即使没有知乎账号也能爬取我们需要的数据,最后使用json来处理获取到的数据。
2.数据预处理
在对数据进行预处理时,由于爬取到的数据大部分以中文为主,因此我们主要使用的是jieba库对数据进行中文分词处理。
中文分词(Chinese Word Segmentation)指将汉字序列切分成一个个单独的词或词串序列,它能够在没有词边界的中文字符串中建立分隔标志,通常采用空格分隔。中文分词是数据分析预处理、数据挖掘、文本挖掘、搜索引擎、知识图谱、自然语言处理等领域中非常基础的知识点,只有经过中文分词后的语料才能转换为数学向量的形式,继续进行后面的分析。同时,由于中文数据集涉及到语义、歧义等知识,划分难度较大,比英文复杂很多。
Jieba库是一款优秀的 Python 第三方中文分词库,jieba 支持三种分词模式:精确模式、全模式和搜索引擎模式,下面是三种模式的特点。
精确模式:试图将语句最精确的切分,不存在冗余数据,适合做文本分析
全模式:将语句中所有可能是词的词语都切分出来,速度很快,但是存在冗余数据
搜索引擎模式:在精确模式的基础上,对长词再次进行切分。
通过使用jieba库,我们可以快速对数据进行分词处理,使用jieba.cut对获取到的数据进行分词以及通过stop_words停用词过滤(包括标点符号),从而快速过滤掉无用数据更方便后续分析。
2.1部分代码展示
3.数据可视化
在对数据进行预处理之后,我们就可以将处理好的数据以可视化的方式向用户展示。主要用到wordcloud,matplotlib,Seaborn,SnowNLP等第三方库。
Matplotlib库:Matplotlib是接触最多的可视化库,它可以很轻松地画一些或简单或复杂地图形,几行代码即可生成线图、直方图、功率谱、条形图、错误图、散点图等等。
我们使用Matplotlib库可以通过处理好的数据以折线图的方式展示舆情时间变化,更有利于舆情分析。
Seaborn:如果单单使用matplotlib会显示非常简单,不够美观。Seaborn是基于matplotlib产生的一个模块,专攻于统计可视化,可以和pandas进行无缝链接。相对于matplotlib,Seaborn语法更简洁,两者关系类似于numpy和pandas之间的关系。它能够让绘制图像的样式更加丰富。
Wordcloud库:wordcloud可以对文本中出现次数较高的词语进行可视化展示图形,其中的wordcloud.WordCloud方法可以对展示的词云图进行自定义构建。
wordcloud.WordCloud方法:
font_path : string //字体路径,需要展现什么字体就把该字体路径+后缀名写上,如:font_path = '黑体.ttf'
width : int (default=400) //输出的画布宽度,默认为400像素
height : int (default=200) //输出的画布高度,默认为200像素
prefer_horizontal : float (default=0.90) //词语水平方向排版出现的频率,默认 0.9 (所以词语垂直方向排版出现频率为 0.1 )
scale : float (default=1) //按照比例进行放大画布,如设置为1.5,则长和宽都是原来画布的1.5倍。
min_font_size : int (default=4) //显示的最小的字体大小
font_step : int (default=1) //字体步长,如果步长大于1,会加快运算但是可能导致结果出现较大的误差。
max_words : number (default=200) //要显示的词的最大个数
stopwords : set of strings or None //设置需要屏蔽的词,如果为空,则使用内置的STOPWORDS
background_color : color value (default=”black”) //背景颜色,如background_color='white',背景顏色为白色。
max_font_size : int or None (default=None) //显示的最大的字体大小
mode : string (default=”RGB”) //当参数为“RGBA”并且background_color不为空时,背景为透明。
relative_scaling : float (default=.5) //词频和字体大小的关联性
color_func : callable, default=None //生成新颜色的函数,如果为空,则使用 self.color_func
regexp : string or None (optional) //使用正则表达式分隔输入的文本
collocations : bool, default=True //是否包括两个词的搭配
本文也将wordcloud.WordCloud方法进行整理并展示部分制作简单的词云图代码及词云图效果。如图:
SnouNLP库:SnowNLP是一个python写的类库,可以方便的处理中文文本内容,是受到了TextBlob的启发而写的,由于现在大部分的自然语言处理库基本都是针对英文的,于是写了一个方便处理中文的类库。简单地说,snownlp是一个中文的自然语言处理的Python库。
对于舆情分析,我们需要将获取到的数据进行分析再以简单易懂的图片展示方式呈现给用户,因此我们需要借助SnouNLP库对我们从网络上获取到的数据进行情感分析。通过机器训练过后的情感分析,我们可以快速地对获取到的庞大数据量进行分析,以极短的时间完成高效分析任务。
首先使用SnouNLP库训练情感分析的模型,在完成模型训练后通过已经进行预处理后的数据,SnouNLP库会对完成预处理的数据逐条进行情感分析,完成情感分析后再结合调用Matplotlib库,以直方图或其他方式直观向用户展示舆情分析结果,从而完成舆情分析。
3.2 词云图效果展示
三、结论
本项目以校园舆情为研究方向出发进行数据分析以及词云图,直方图的制作,通过python设计不同网页的爬虫对不同社交平台网站的评论数据进行爬取;对获取到的数据进行分词,去除停用词等方式进行预处理;最后结合python的不同第三方库对获取到的数据进行情感分析并以词云图,直方图等直观的图片展示给使用者。同时本文在数据获取等方面也并未使用过难的技术,数据获取采用了主函数调用的方式进行启动,在数据预处理也是采用更为简单易上手的jieba库进行预处理,最后做出词云图等图片进行数据可视化。校园舆情分析系统的设计完成,不仅可以及时应对学校在遇到突发事件时通过舆情分析及时确定解决方案,同时在日常生活中也可以根据同学们的评论解决他们遇到的问题,亦或是根据根据同学们对校园的看法对校园进行改善。
参考文献:
[1]黄源,张扬 《大数据可视化技术》 中国水利水电出版社
[2]宋威龙 《python数据分析与数据化运营》 机械工业出版社
[3]喻梅,于健 《数据分析与数据挖掘》 清华大学出版社
[4]谢乾坤 《python爬虫开发从入门到实战》 人民邮电出版社
作者简介:孙睿(2000.06.13 —— ),男,壮族,籍贯:广西南宁,学历:本科在读,研究方向:数据科学与大数据技术
基金项目:吉林省长春工程学院大学生创新创业项目[S202111437092]
